

2021-常见问题收集整理-1
2021-常见问题收集整理-篇章1
一往情深深几许?深山夕照深秋雨。
简介:2021-常见问题收集整理-篇章1,完善自身技能树,有备无患。
一、顺序查找和二分查找法的时间复杂度分别为多少?
二分查找VS顺序查找图
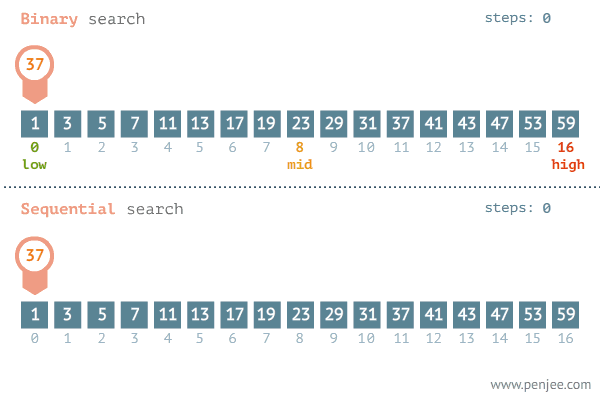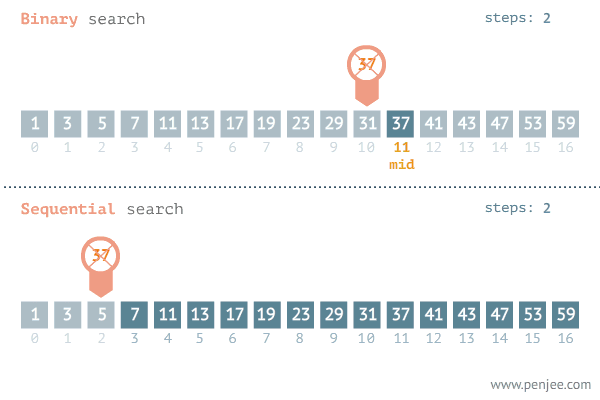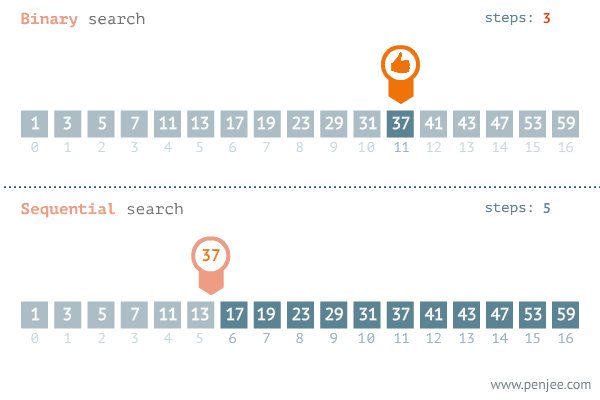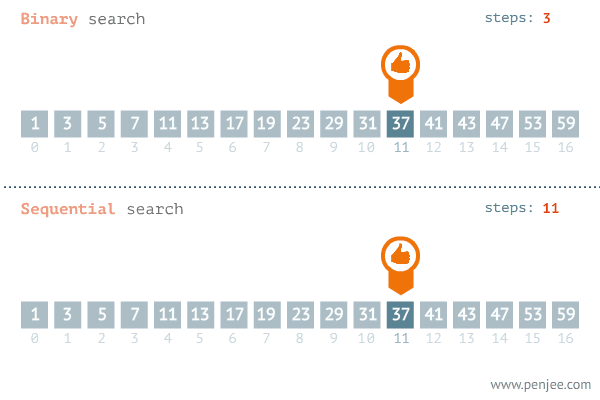
1、顺序查找
顺序查找的平均时间复杂度为O(logn),n 是待查数列的长度,因为顺序查找是从头到尾查找,而且是查找了整个数组。当然最好的情况是数组的第 1 个元素就是我们要找的元素,这样可以直接找到,最坏的情况是到最后一个元素时才找到或者没有找到要找的元素。
顺序查找代码:



1 /** 2 * 顺序查找 3 */ 4 public class SequentialSearch { 5 private int[] array; 6 public SequentialSearch(int[] array) { 7 this.array = array; 8 } 9 10 /** 11 * 直接顺序查找 12 * @param key 13 * @return 14 */ 15 public int search(int key) { 16 for (int i = 0; i < array.length; i++) { 17 if (array[i] == key) { 18 // 找到了的话返回数组下标 19 return i; 20 } 21 } 22 return -1; 23 } 24 }
2、二分查找
二分查找的时间复杂度为O(logn),利用折半查找大大降低了比较次数,它是一种效率较高的查找方法(redis、kafka、B+树的底层都采用了二分查找法 )。
二分查找的使用前提是线性表已经按照大小排好了序。这种方法充分利用了元素间的次序关系,采用分治策略。基本原理是:首先在有序的线性表中找到中值,将要查找的目标与中值进行比较,如果目标小于中值,则在前半部分找,如果目标小于中值,则在后半部分找;假设在前半部分找,则再与前半部分的中值相比较,如果小于中值,则在中值的前半部分找,如果大于中值,则在后半部分找。以此类推,直到找到目标为止。
二分查找代码:
1 package com.bebird.pms.controller.test; 2 3 /** 4 * 二分查找 5 * 假设在 2,6,11,13,16,17,22,30中查找22 6 */ 7 public class BinarySearch { 8 9 /** 10 * 1、首先找到中值:中值为13(下标:int middle = (0+7)/2),将22与13进行比较,发现22比13大,则在13的后半部分找; 11 * 2、然后在后半部分 16,17,22,30中查找22,首先找到中值,中值为17(下标:int middle=(0+3)/2),将22与17进行比较,发现22比17大,则继续在17的后半部分查找; 12 * 3、然后在17的后半部分 22,30查找22,首先找到中值,中值为22(下标:int middle=(0+1)/2),将22与22进行比较,查找到结果。 13 * @param args 14 */ 15 public static void main(String[] args) { 16 int arr[] = {2, 6, 11, 13, 16, 17, 22, 30}; 17 System.out.println("非递归结果,22的位置为:" + binarySearch(arr, 22)); 18 System.out.println("递归结果,22的位置为:" + binarySearch(arr, 22, 0, 7)); 19 } 20 21 /** 22 * 非递归 23 * @param arr 24 * @param res 25 * @return 26 */ 27 static int binarySearch(int[] arr, int res) { 28 int low = 0; 29 int high = arr.length - 1; 30 while (low <= high) { 31 int middle = (low + high) / 2; 32 if (res == arr[middle]) { 33 return middle; 34 } else if (res < arr[middle]) { 35 high = middle - 1; 36 } else { 37 low = middle + 1; 38 } 39 } 40 return -1; 41 } 42 43 /** 44 * 递归 45 * @param arr 46 * @param res 47 * @param low 48 * @param high 49 * @return 50 */ 51 static int binarySearch(int[] arr, int res, int low, int high) { 52 53 if (res < arr[low] || res > arr[high] || low > high) { 54 return -1; 55 } 56 int middle = (low + high) / 2; 57 if (res < arr[middle]) { 58 return binarySearch(arr, res, low, middle - 1); 59 } else if (res > arr[middle]) { 60 return binarySearch(arr, res, middle + 1, high); 61 } else { 62 return middle; 63 } 64 } 65 }
二、举例常见排序算法并说下快速排序法的过程,时间复杂度?
1、常见排序算法
八种常见排序算法:直接插入排序、希尔排序、简单选择排序、堆排序、冒泡排序、快速排序、归并排序和基数排序。
算法详情链接:https://www.cnblogs.com/taojietaoge/p/13599081.html
2、快排
快速排序使用分治的思想,从待排序序列中选取一个记录的关键字为key,通过一趟排序将待排序列分割成两部分,其中一部分记录的关键字不大于key,另一部分记录的关键字不小于key,之后分别对这两部分记录继续进行排序,以达到整个序列有序的目的。
快速排序算法的基本步骤为(从小到大):
选择关键字:从待排序序列中,按照某种方式选出一个元素作为 key 作为关键字(也叫基准)。
置 key 分割序列:通过某种方式将关键字置于一个特殊的位置,把序列分成两个子序列。此时,在关键字 key 左侧的元素小于或等于 key,右侧的元素大于 key(这个过程称为一趟快速排序)。
对分割后的子序列按上述原则进行分割,直到所有子序列为空或者只有一个元素。此时,整个快速排序完成。
三、如何实现关键词输入提示功能?
使用字典树实现或HashMap。
1、Trie Tree简介
Trie Tree,又称单词字典树、查找树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。时间复杂度 : O(n),空间复杂度 : O(1)。
Trie Tree结构图
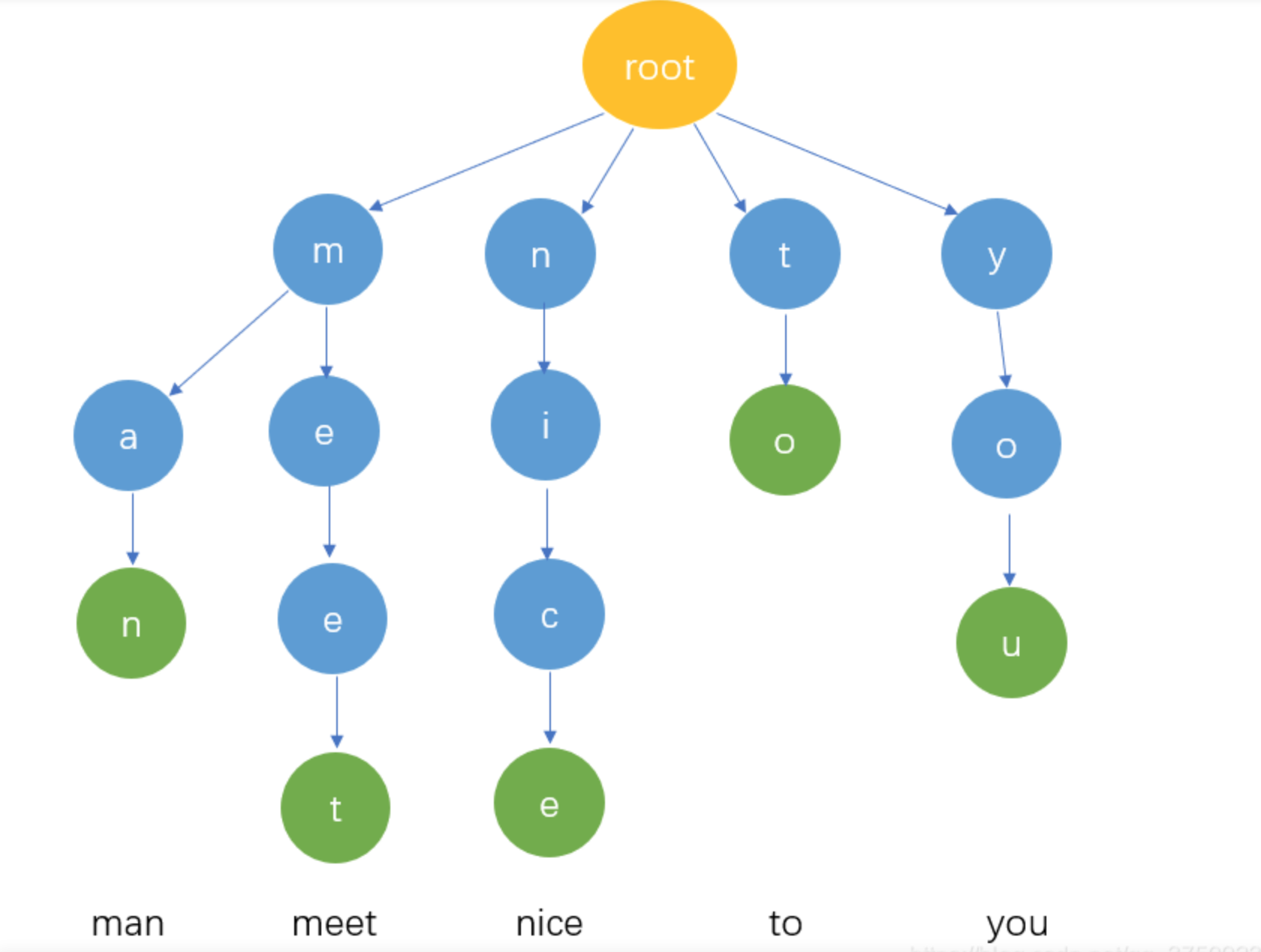
2、Trie Tree 性质
a. 根节点不包含字符,除根节点外每一个节点都只包含一个字符。
b. 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
c. 每个节点的所有子节点包含的字符都不相同。
3、Trie Tree 分词原理
(1) 从根结点开始一次搜索,比如搜索【北京】;
(2) 取得要查找关键词的第一个字符【北】,并根据该字符选择对应的子树并转到该子树继续进行检索;
(3) 在相应的子树上,取得要查找关键词的第二个字符【京】,并进一步选择对应的子树进行检索。
(4) 迭代过程……
(5) 在直到判断树节点的isEnd节点为true则查找结束(最小匹配原则),然后发现【京】isEnd=true,则结束查找。
java 简单实现代码:
1 import java.util.HashMap; 2 import java.util.LinkedList; 3 import java.util.List; 4 import java.util.Map; 5 import java.util.Map.Entry; 6 7 /** 8 * trie tree 9 * 正向最大匹配 10 */ 11 public class TrieTreeDemo { 12 static class Node { 13 //记录当前节点的字 14 char c; 15 //判断该字是否词语的末尾,如果是则为false 16 boolean isEnd; 17 //子节点 18 List<Node> childList; 19 20 public Node(char c) { 21 super(); 22 this.c = c; 23 isEnd = false; 24 childList = new LinkedList<Node>(); 25 } 26 27 //查找当前子节点中是否保护c的节点 28 public Node findNode(char c){ 29 for(Node node : childList){ 30 if(node.c == c){ 31 return node; 32 } 33 } 34 35 return null; 36 } 37 } 38 39 static class TrieTree{ 40 Node root = new Node(' '); 41 42 //构建Trie Tree 43 public void insert(String words){ 44 char[] arr = words.toCharArray(); 45 Node currentNode = root; 46 for (char c : arr) { 47 Node node = currentNode.findNode(c); 48 //如果不存在该节点则添加 49 if(node == null){ 50 Node n = new Node(c); 51 currentNode.childList.add(n); 52 currentNode = n; 53 }else{ 54 currentNode = node; 55 } 56 } 57 //在词的最后一个字节点标记为true 58 currentNode.isEnd = true; 59 } 60 61 //判断Trie Tree中是否包含该词 62 public boolean search(String word){ 63 char[] arr = word.toCharArray(); 64 Node currentNode = root; 65 for (int i=0; i<arr.length; i++) { 66 Node n = currentNode.findNode(arr[i]); 67 if(n != null){ 68 currentNode = n; 69 //判断是否为词的尾节点节点 70 if(n.isEnd){ 71 if(n.c == arr[arr.length-1]){ 72 return true; 73 } 74 } 75 } 76 } 77 return false; 78 } 79 80 //最大匹配优先原则 81 public Map<String, Integer> tokenizer(String words){ 82 char[] arr = words.toCharArray(); 83 Node currentNode = root; 84 Map<String, Integer> map = new HashMap<String, Integer>(); 85 //记录Trie Tree 从root开始匹配的所有字 86 StringBuilder sb = new StringBuilder();; 87 //最后一次匹配到的词,最大匹配原则,可能会匹配到多个字,以最长的那个为准 88 String word=""; 89 //记录记录最后一次匹配坐标 90 int idx = 0; 91 for (int i=0; i<arr.length; i++) { 92 Node n = currentNode.findNode(arr[i]); 93 if(n != null){ 94 sb.append(n.c); 95 currentNode = n; 96 //匹配到词 97 if(n.isEnd){ 98 //记录最后一次匹配的词 99 word = sb.toString(); 100 //记录最后一次匹配坐标 101 idx = i; 102 } 103 }else{ 104 //判断word是否有值 105 if(word!=null && word.length()>0){ 106 Integer num = map.get(word); 107 if(num==null){ 108 map.put(word, 1); 109 }else{ 110 map.put(word, num+1); 111 } 112 //i回退到最后匹配的坐标 113 i=idx; 114 //从root的开始匹配 115 currentNode = root; 116 //清空匹配到的词 117 word = null; 118 //清空当前路径匹配到的所有字 119 sb = new StringBuilder(); 120 } 121 } 122 if(i==arr.length-2){ 123 if(word!=null && word.length()>0){ 124 Integer num = map.get(word); 125 if(num==null){ 126 map.put(word, 1); 127 }else{ 128 map.put(word, num+1); 129 } 130 } 131 } 132 } 133 134 return map; 135 } 136 } 137 138 public static void main(String[] args) { 139 TrieTree tree = new TrieTree(); 140 tree.insert("北京"); 141 tree.insert("海淀区"); 142 tree.insert("中国"); 143 tree.insert("中国人民"); 144 tree.insert("中关村"); 145 146 String word = "中国"; 147 //查找该词是否存在 Trid Tree 中 148 boolean flag = tree.search(word); 149 if(flag){ 150 System.out.println("Trie Tree 中已经存在【"+word+"】"); 151 }else{ 152 System.out.println("Trie Tree 不包含【"+word+"】"); 153 } 154 155 //分词 156 Map<String, Integer> map = tree.tokenizer("中国人民,中国首都是北京,中关村在海淀区,中国北京天安门。中国人"); 157 for (Entry<String, Integer> entry : map.entrySet()) { 158 System.out.println(entry.getKey()+":"+entry.getValue()); 159 } 160 161 } 162 }
四、HashMap 的实现原理?红黑树的结构?
1、从整体结构上看HashMap是由数组+链表+红黑树(JDK1.8后增加了红黑树部分)实现的。
HashMap 实现原理链接: https://www.cnblogs.com/taojietaoge/p/11359542.html
2、红黑树结构以平衡、高效的随机访问著称。
简单了解二叉树、平衡树、红黑树、B树和B+树之间的特点和差异链接: https://www.cnblogs.com/taojietaoge/p/12070094.html
五、Java垃圾回收机制如何实现?
JVM会自动回收没有被引用的对象来释放空间,当没有任何对象的引用指向该对象时 + 在下次垃圾回收周期来到时,对象才会被回收,从而解决内存不足问题。
常用的回收算法策略:标记-清除算法、标记整理算法、复制算法。(https://www.cnblogs.com/taojietaoge/p/11286014.html)
六、什么是死锁,产生死锁的原因及必要条件?
1、什么是死锁
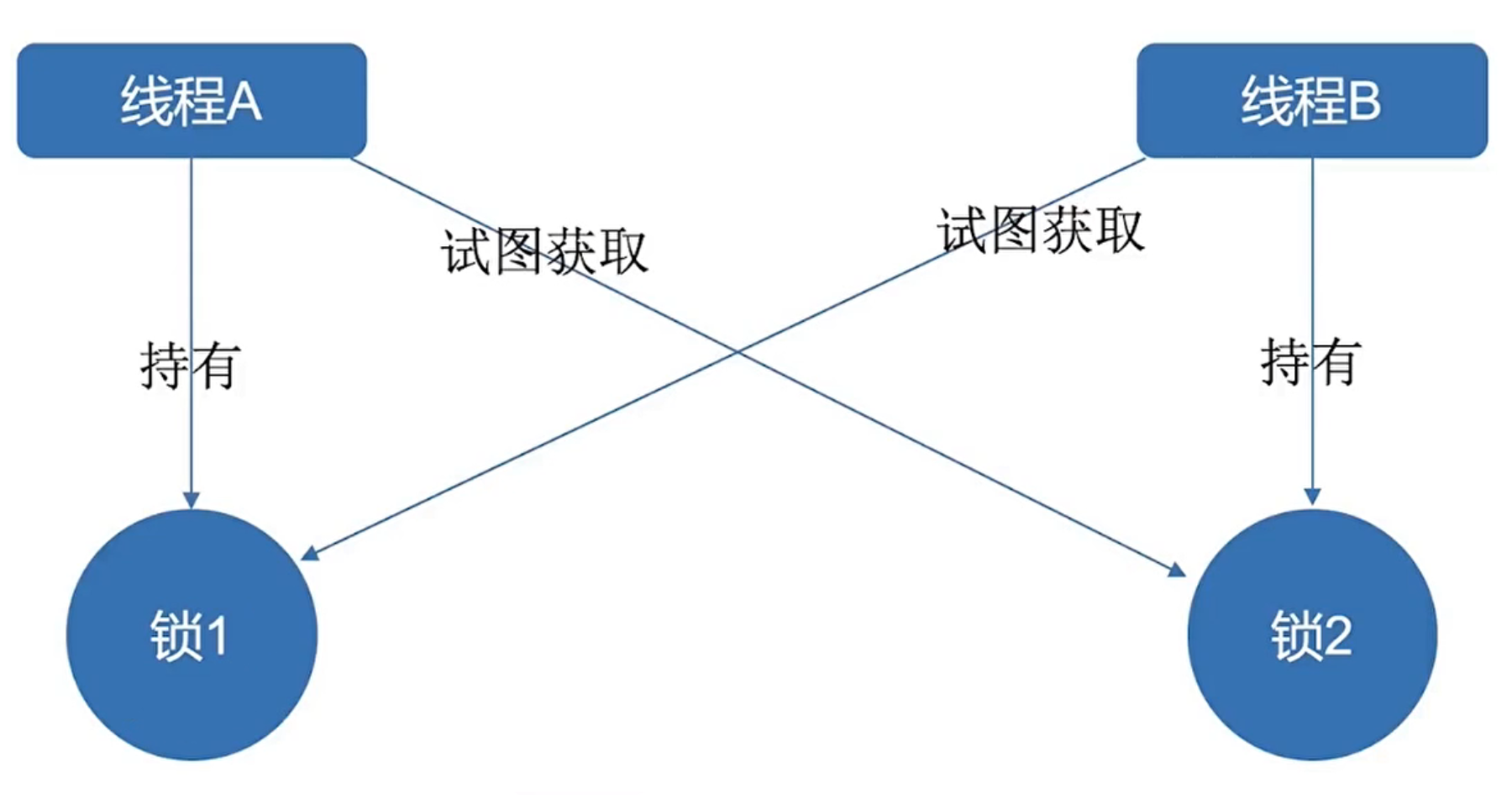
死锁是指多个进程在运行过程中因争夺资源而造成的一种僵局,当进程处于这种僵持状态时,若无外力作用,它们都将无法再向前推进。如下图有一个线程A,持有锁1再试图获得锁2的顺序获得锁,而在此同时又有另外一个线程B,持有锁2再试图获取锁1的顺序获得锁。
2、产生死锁的原因
a、竞争资源。
b、进程间推进顺序非法。
3、产生死锁的必要条件
a、互斥条件:进程要求对所分配的资源进行排它性控制,即在一段时间内某资源仅为一进程所占用。
b、请求和保持条件:当进程因请求资源而阻塞时,对已获得的资源保持不放。
c、不剥夺条件:进程已获得的资源在未使用完之前,不能剥夺,只能在使用完时由自己释放。
d、环路等待条件:在发生死锁时,必然存在一个进程--资源的环形链。
4、预防死锁
a、以确定的顺序获得锁。
b、超时放弃。
5、解除死锁
- 剥夺资源:从其它进程剥夺足够数量的资源给死锁进程,以解除死锁状态;
- 撤消进程:可以直接撤消死锁进程或撤消代价最小的进程,直至有足够的资源可用,死锁状态.消除为止;所谓代价是指优先级、运行代价、进程的重要性和价值等。
七、线程和进程的区别?进程的通信方式?
1、进程
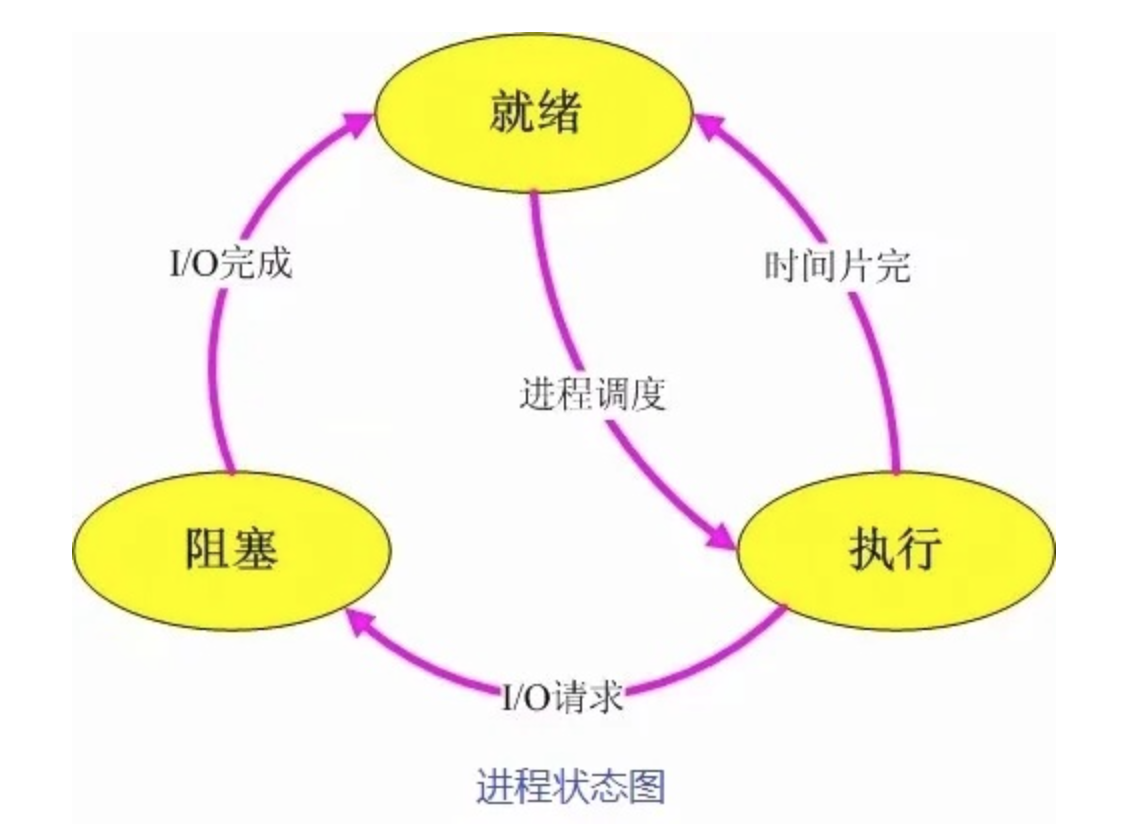
进程,直观点说,保存在硬盘上的程序运行以后,会在内存空间里形成一个独立的内存体,这个内存体有自己独立的地址空间,有自己的堆,上级挂靠单位是操作系统。操作系统会以进程为单位,分配系统资源(CPU时间片、内存等资源),进程是资源分配的最小单位。
2、线程
线程,有时被称为轻量级进程(Lightweight Process,LWP),是操作系统调度(CPU调度)执行的最小单位。
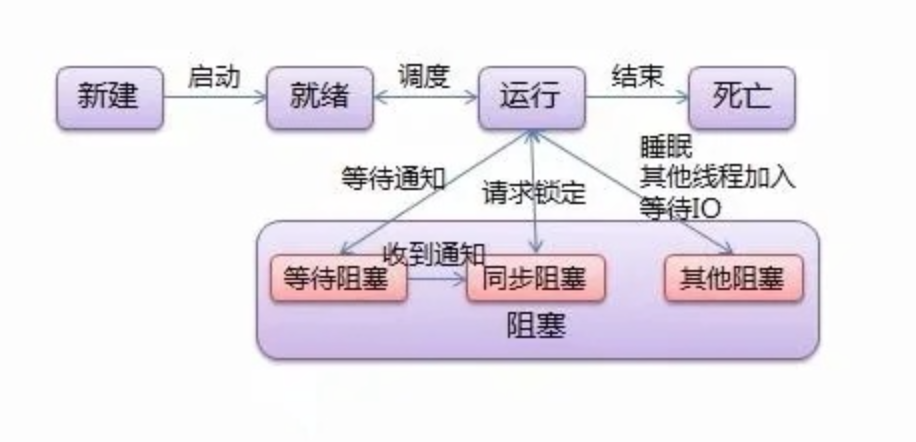
3、区别与联系
a、并发性:不仅进程之间可以并发执行,同一个进程的多个线程之间也可并发执行。
b、拥有资源:进程是拥有资源的一个独立单位,线程不拥有系统资源,但可以访问隶属于进程的资源。
c、系统开销:多进程的程序要比多线程的程序健壮,但在进程切换时,耗费资源较大,效率要差一些。
d、一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程;
e、资源分配给进程,同一进程的所有线程共享该进程的所有资源;
f、处理机分给线程,即真正在处理机上运行的是线程;
g、线程在执行过程中,需要协作同步。不同进程的线程间要利用消息通信的办法实现同步。
4、进程的通信方式?
Volatile
等待/通知机制
Join 方式
threadlocal。
进程通信方式知乎参考链接:https://zhuanlan.zhihu.com/p/129374075
八、Linux系统中如何查看进程、CPU状态、端口占用情况?
1、查看进程
Linux:建议使用 ps -elf 查询,输出的信息更详细些,包括 PPID (对应的父进程 的PID 号)。
Window:tasklist
Mac:ps -ef
2、CPU状态
top 命令,运行 top 命令后,CPU 使用状态会以全屏的方式显示,并且会处在对话的模式 。
3、端口暂用情况
lsof -i
lsof -i:端口号
九、Linux系统中大型文件比如10G以上文件如何查找文件中指定字符串的位置?
sed -ie '/指定字符串/d' 文件名.log
一往情深深几许?
深山夕照深秋雨。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?