

卷积神经网络CNN-学习1
卷积神经网络CNN-学习1
十年磨一剑,霜刃未曾试。
简介:卷积神经网络CNN学习。
CNN中文视频学习链接:卷积神经网络工作原理视频-中文版
CNN英语原文学习链接:卷积神经网络工作原理视频-英文版
一、定义
二、CNN灵感来源?
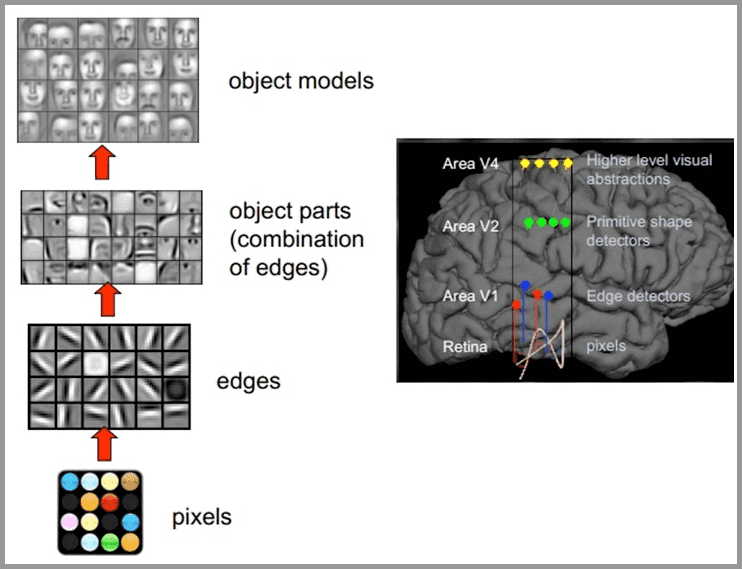
对于不同的物体,人类视觉也是通过这样逐层分级,来进行如下认知的。
人类视觉识别示例
在最底层特征基本上是类似的,就是各种边缘,越往上,越能提取出此类物体的一些特征(轮子、眼睛、躯干等),到最上层,不同的高级特征最终组合成相应的图像,从而能够让人类准确的区分不同的物体。于是便模仿人类大脑的这个特点,构造多层的神经网络,较低层的识别初级的图像特征,若干底层特征组成更上一层特征,最终通过多个层级的组合,最终在顶层做出分类。
三、卷积神经网络解决了什么?
概括来说就是保留图像特征,参数降维,复杂参数简单化。
图像像素RGB

众所周知,图像是由像素构成的,每个像素又是由颜色构成的。现在随随便便一张图片都是 1000×1000 像素以上的, 每个像素都有RGB 3个参数来表示颜色信息。
假如我们处理一张 1000×1000 像素的图片,我们就需要处理3百万个参数!1000×1000×3=3,000,000
这么大量的数据处理起来是非常消耗资源的,卷积神经网络 – CNN 解决的第一个问题就是「将复杂问题简化」,把大量参数降维成少量参数,再做处理。
更重要的是:我们在大部分场景下,降维并不会影响结果。比如1000像素的图片缩小成200像素,并不影响肉眼认出来图片中是一只猫还是一只狗,机器也是如此。
图片数字化的传统方式
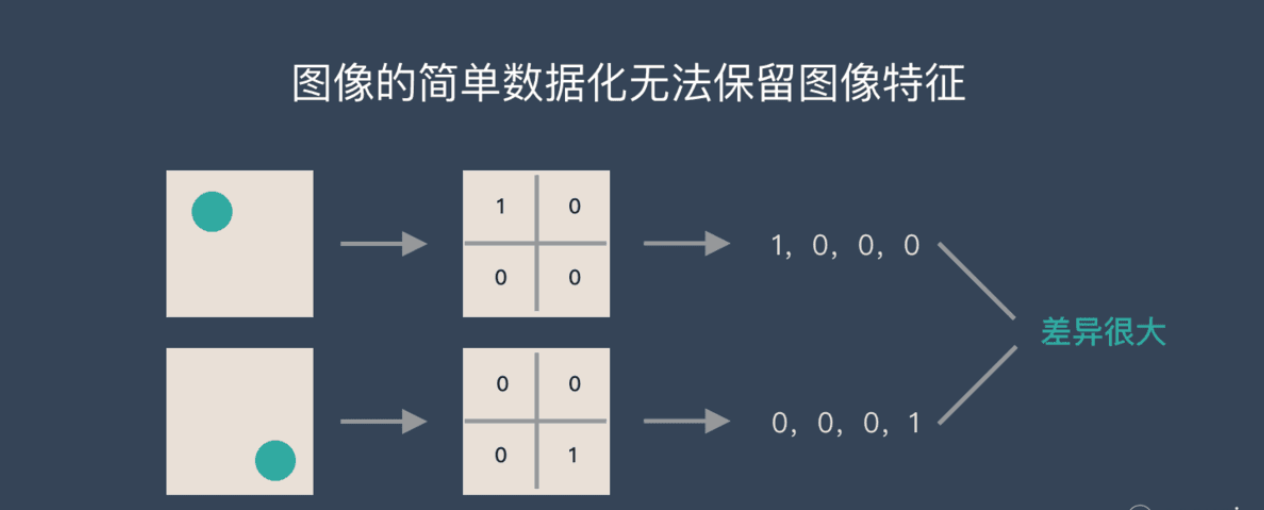
图像简单数字化无法保留图像特征,如上图假如有圆形是1,没有圆形是0,那么圆形的位置不同就会产生完全不同的数据表达。但是从视觉的角度来看,图像的内容(本质)并没有发生变化,只是位置发生了变化。所以当我们移动图像中的物体,用传统的方式的得出来的参数会差异很大!这是不符合图像处理的要求的。而 CNN 解决了这个问题,他用类似视觉的方式【模仿人类大脑视觉原理,构造多层的神经网络,较低层的识别初级的图像特征,若干底层特征组成更上一层特征,最终通过多个层级的组合,最终在顶层做出分类】保留了图像的特征,当图像做翻转,旋转或者变换位置时,它也能有效的识别出来是类似的图像。
四、卷积神经网络的架构
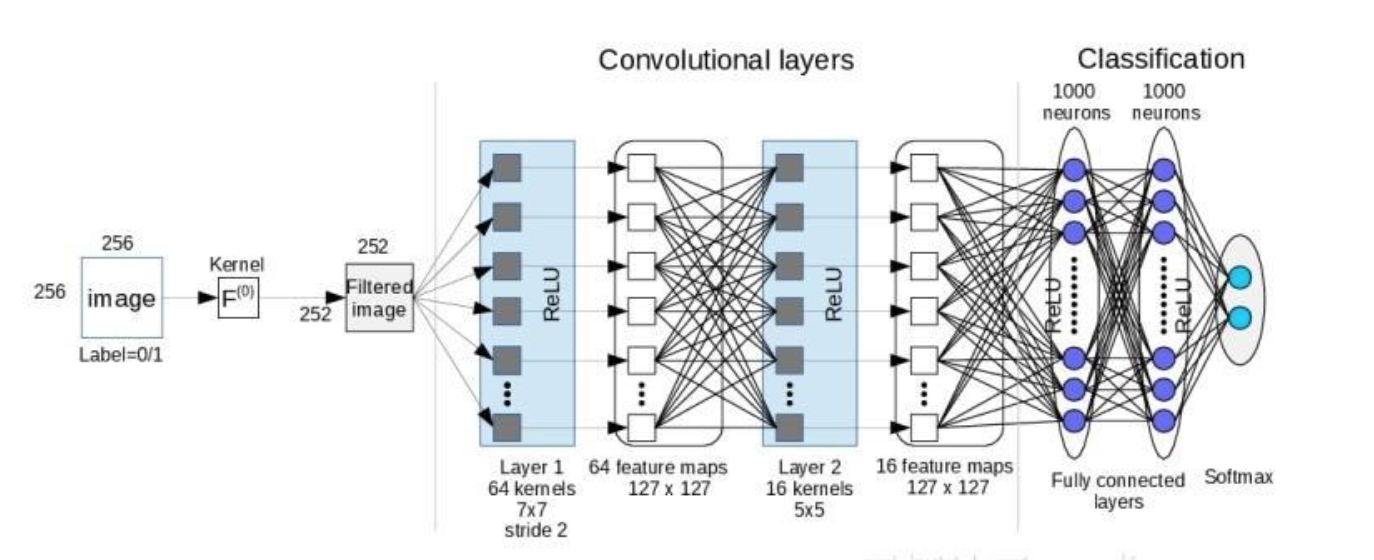
典型的 CNN 由卷积层、池化层、全连接层3个部分构成:
典型CNN组成部分

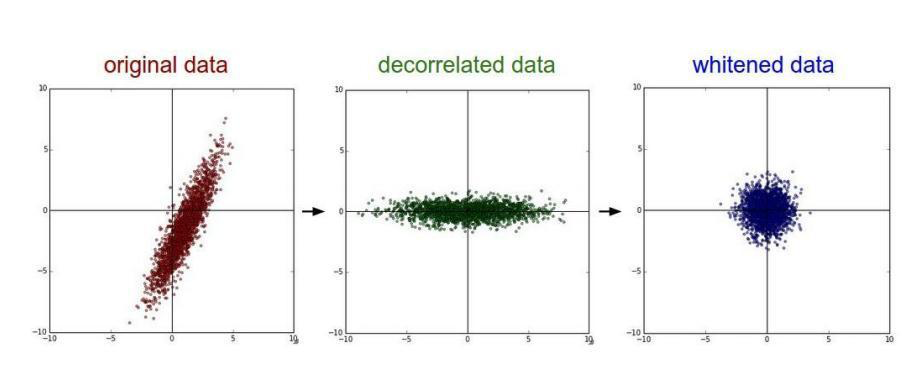
五、数据输入层

去相关与白化效果图
六、卷积计算层
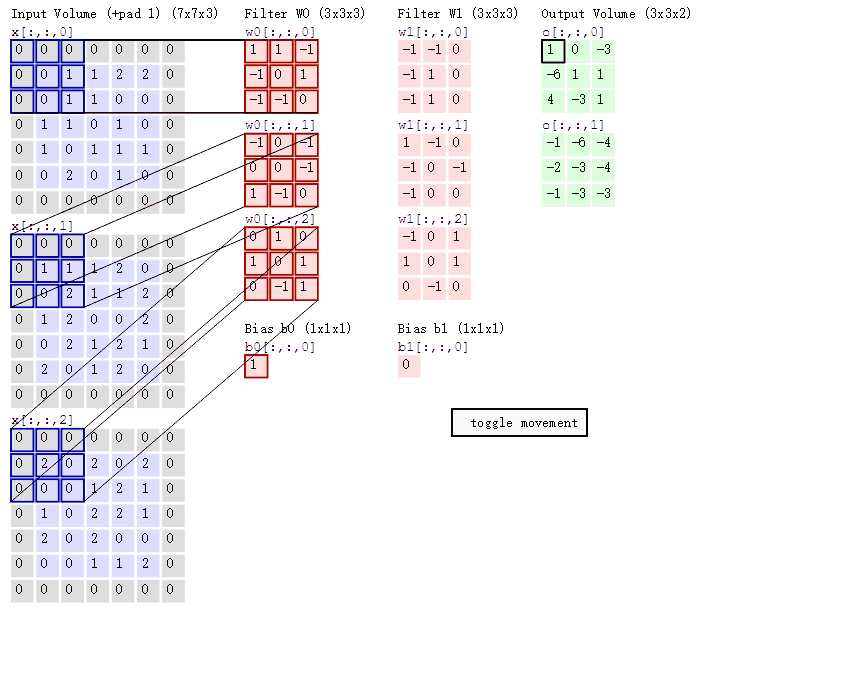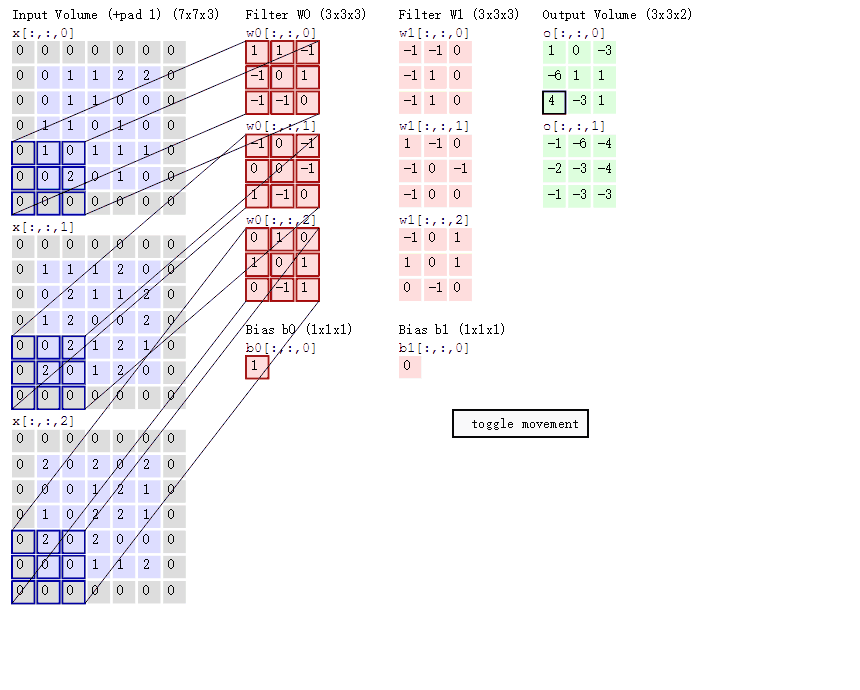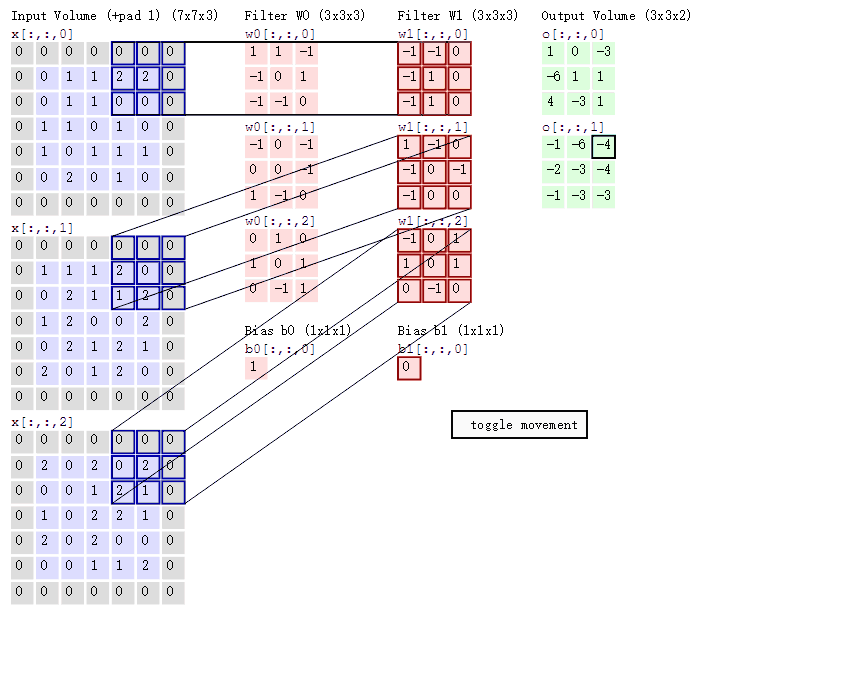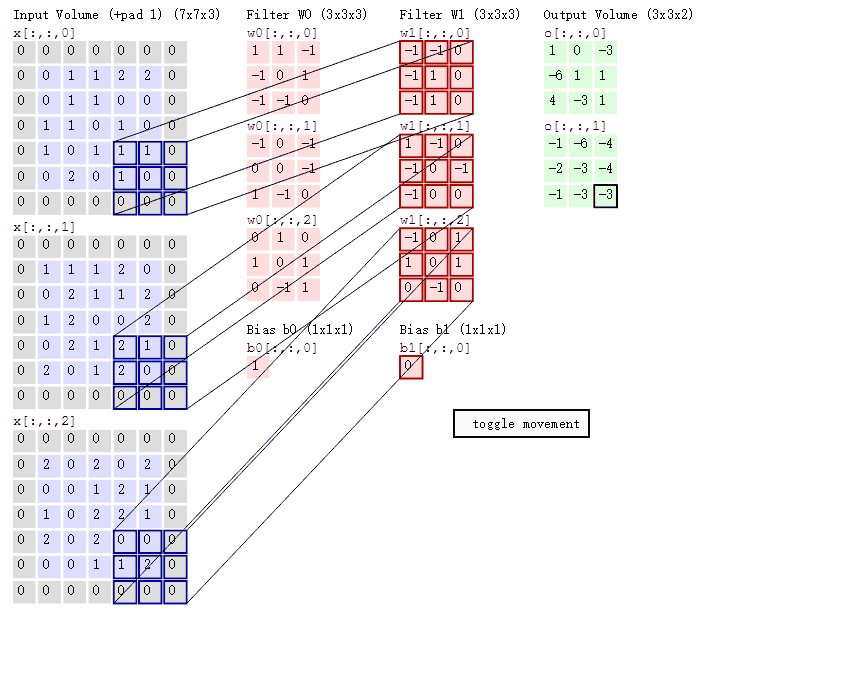
卷积层有两个重要的操作,一个是局部关联,每个神经元看做一个滤波器filter;另一个是窗口滑动,filter对局部数据计算。
卷积层的运算过程如下图,用一个卷积核扫完整张图片:
卷积层动态运算图
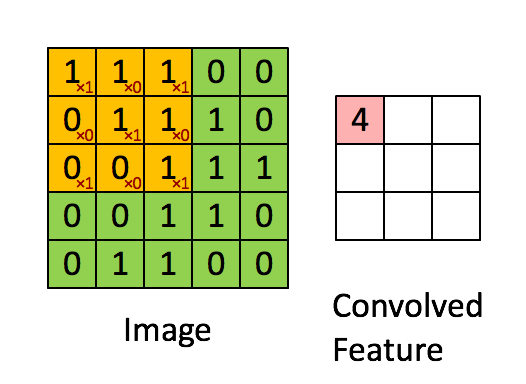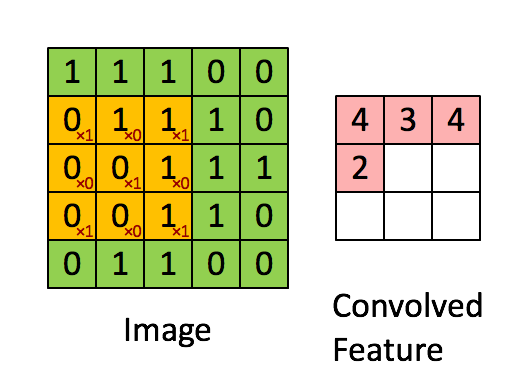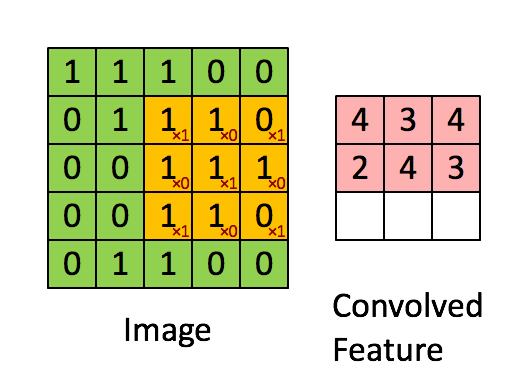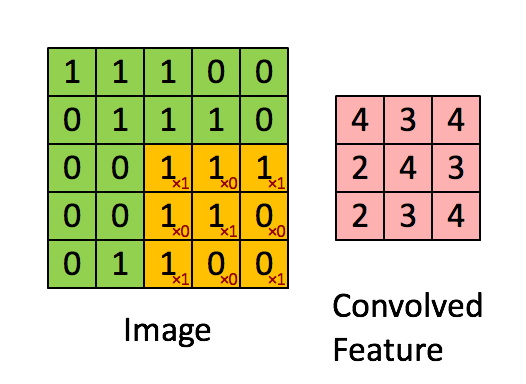
卷积层的运算过程,可以当做使用一个过滤器(卷积核)来过滤图像的各个小区域,从而得到这些小区域的特征值,即卷积层通过卷积核的过滤提取出图片中局部的特征。
卷积层运算图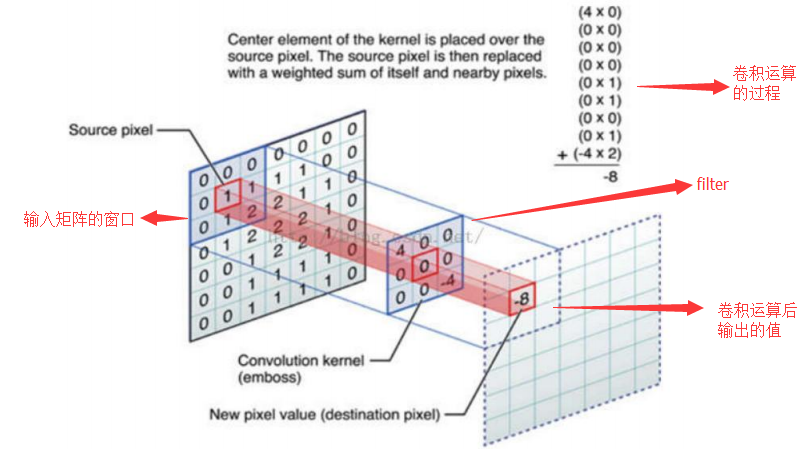
卷积层计算过程动图
七、激励层
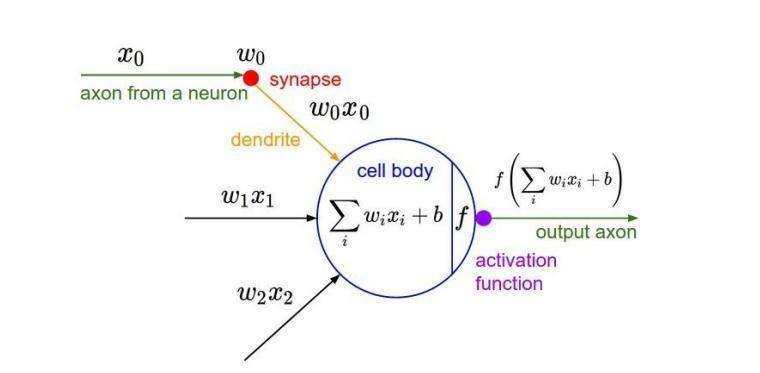
激励层是把卷积层输出结果做非线性映射。CNN采用的激励函数一般为ReLU(The Rectified Linear Unit/修正线性单元)。
八、池化层
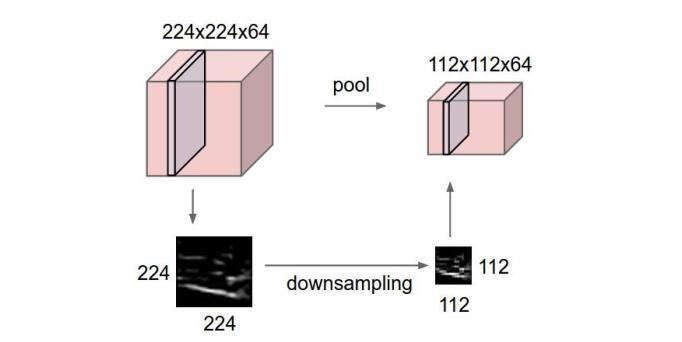
池化层在连续的卷积层中间,其用于压缩数据和参数的量,减少过拟合。最重要的作用就是保持特性不变,压缩图像,降低数据维度。
池化层用的方法有Max pooling 和 average pooling,而实际用的较多的是Max pooling。Max pooling思想:对于每个2 * 2的窗口选出最大的数作为输出矩阵的相应元素的值,比如输入矩阵第一个2 * 2窗口中最大的数是6,那么输出矩阵的第一个元素就是6,如此类推,保持特征不变地降低维度。
Max pooling图

动态池化图
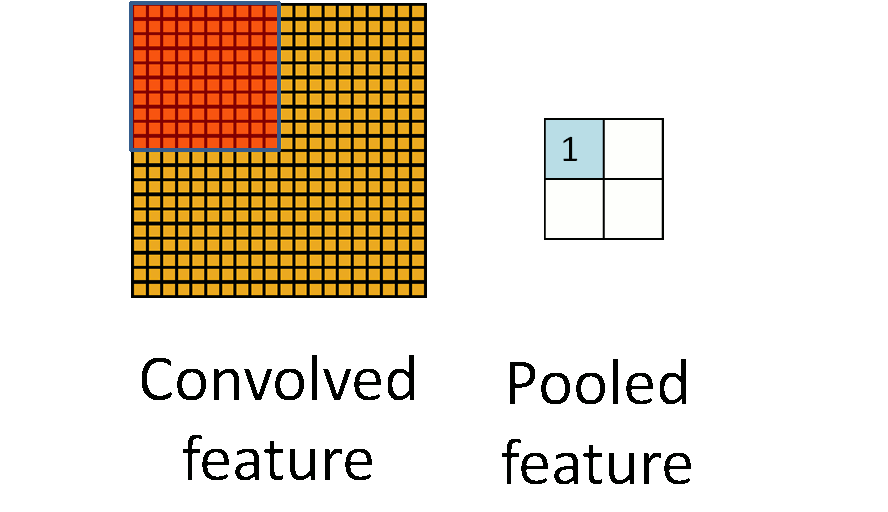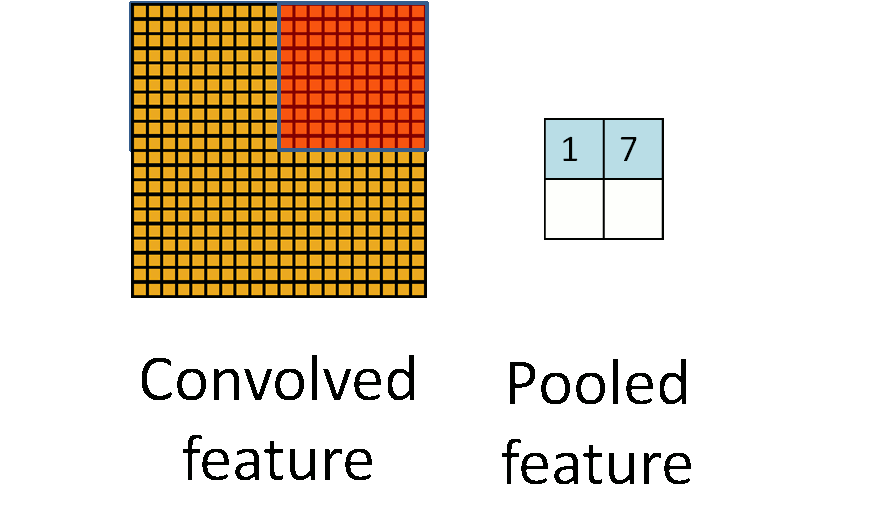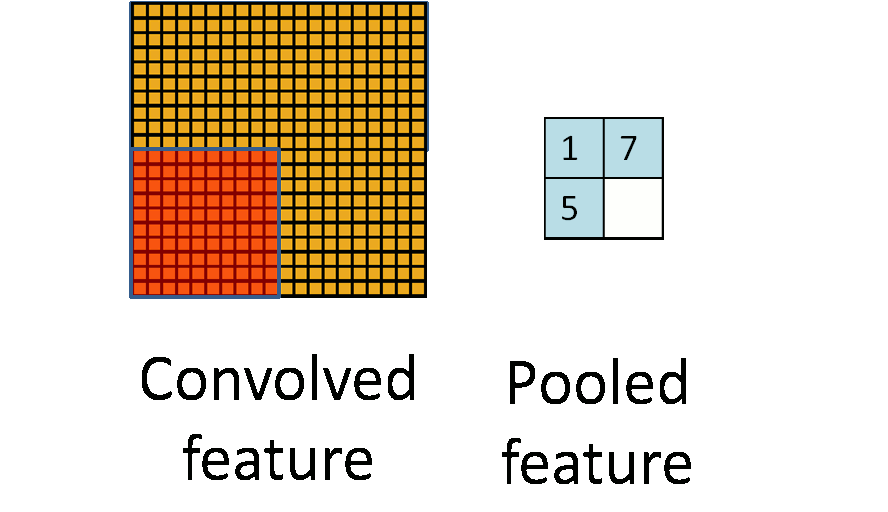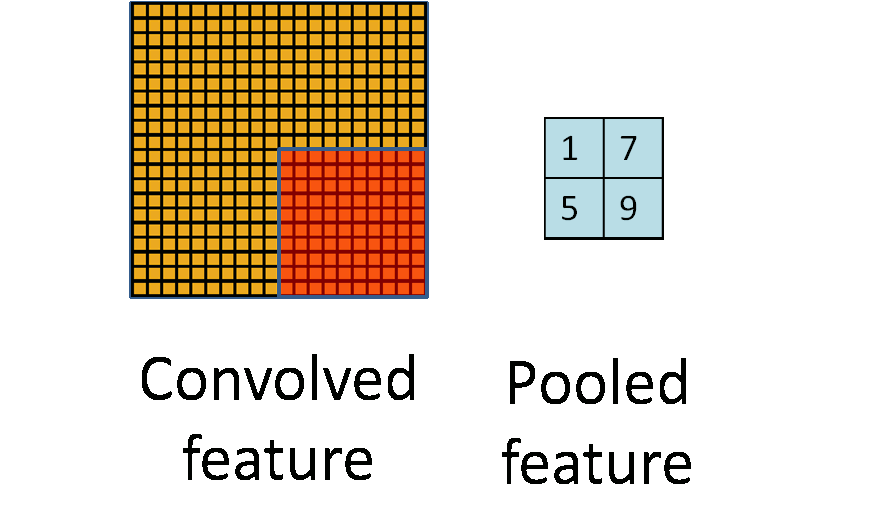
我们可以看到动态池化图中,原始图片是20×20的,我们对其进行下采样,采样窗口为10×10,最终将其下采样成为一个2×2大小的特征图。
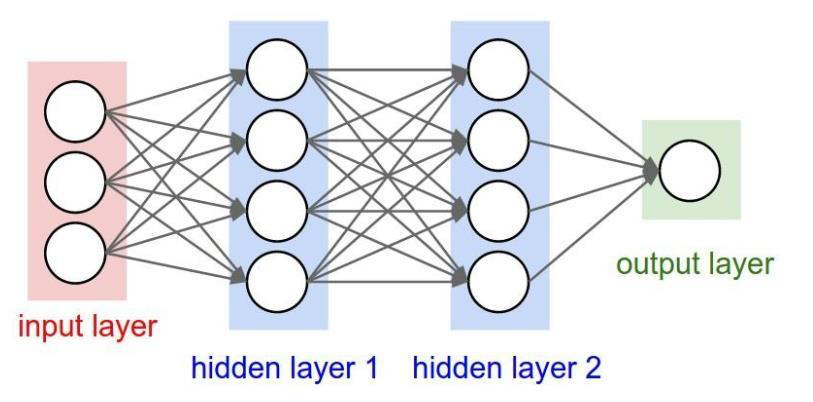
九、全连接层
十、CNN实际应用场景
图像分类/检索、目标定位检测、目标分割、人脸识别、骨骼识别等。
CNN人脸识别

CNN中文视频学习链接:卷积神经网络工作原理视频-中文版
CNN英语原文学习链接:卷积神经网络工作原理视频-英文版
十年磨一剑
霜刃未曾试


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?