道长的算法笔记:树结构递归模型
推荐练习题单: LeetBook 树专题、洛谷二叉树树结构专题、洛谷树上问题
(一) 线性结构的递归模型
正式学习树结构模型之前不妨先回忆一下线性结构的递归写法。众所周知,链表是一种天然带有递归性质的结构,当我们想要处理 为首的链表,我们尝试处理 为首的链表,然后再单独处理节点 ,类似的,对以 为首的链表我们可以尝试处理 为首的链表,然后再单独处理节点 ,以此类推,不再赘述。当走到末尾空节点的时候,我们跳出递归,逐层的弹出函数的栈帧。

只不过链表是一种线性结构,通常使用循环的方式也可以很容易地实现相关的算法,然而若能在链表一节中打下坚实的基础,在学习树结构的递归模型的会变得非常顺手。 回忆一下线性递归模型在链表结构中的几个场景应用,例如打印一个链表、反转一个链表等操作。我们以打印链表为例,下面给出两段非常基础的代码。出于简便,代码中我们使用-1代表空节点,数字 1/2/3/4 分别代表 A/B/C/D,对于链表 ,函数 、 会分别打印 ABCD 与 DCBA。
int list[5] = {1, 2, 3, 4, -1}; // 使用数组模拟链表结构
void f1(int *list){
if (*list == -1)
return;
printf("%c ", *list + 'A' - 1); // 代码主体逻辑写在递归函数之前
f1(list + 1); // 递归函数
}//最终打印:A B C D
void f2(int *list){
if (*list == -1)
return;
f2(list + 1); // 递归函数
printf("%c ", *list + 'A' - 1); // 代码主体逻辑写在递归函数之后
}//最终打印:D C B A

其中 采用的方式称为前序遍历,是指函数递归之前就执行代码的主体逻辑, 采用的方式称为后序遍历,是指函数递归之后才执行代码的主体逻辑。前序与后序两种遍历方式,不仅适用于线性结构,其同样适用于树结构。
由于线性结构只有一个指针域,所以递归的时候,只需要写一个递归函数,那么只有放在递归函数前面或后面两种情况,但较线性结构来说,二叉树结构具有两个指针域,那么一般情况都要写两个递归函数。因而主体代码逻辑可以写在前面、后面,或者夹在递归函数之间,正因如此,树结构的递归又多出了中序遍历。类似的如果具有三个指针域,我们会有四种遍历方式,四个指针域会有五种遍历方式,以此类推。虽然说这些冷知识不怎么有用,因为多叉树的实现方式往往是令树节点存储指针数组的形式实现的。
class Node {
public:
int val;
vector<Node*> children;
Node(int _val) {
this.val = _val;
}
Node(int _val, vector<Node*> _children) {
this.val = _val;
this.children = _children;
}
};
此外除去上述的三种递归模型,层序遍历也是十分常见的,所谓层序遍历是指,逐层的遍历,对于线性结构来说,无论前序或后序其实都是按层遍历,因为一层只有一个节点,但是对于二叉树来说,层序遍历不同于前序、中序、后序,其实现方式是基于宽度优先搜索的,比较特殊,详见下一节的图例。
(二) 二叉树带根树模型
(2.1) 基于深搜的前中后序遍历
(2.1.1) 递归写法
二叉树带根树,是指每个节点只有不大于两个孩子且给定一个指定的根节点的树结构,LeetCode 平台上面绝大部分的树型结构问题均是给定二叉树带根树。一般入门二叉树都会先从前中后序三个基础遍历入手,下面递归框架很容易记住,但若不加以理解,很难运用于变体问题之上。对于给定样例,入门之初最大的问题在于如何借助画图,辅助理解树结构的递归,因为的仅仅是一个简单的三层的二叉树都很容易绕晕。
void xorder_Traversal(TreeNode* root,vector<int>& ans){
if(root==nullptr){
return;
}
// 代码主体逻辑写在这里是前序遍历
xorder_Traversal(root->left,ans);
// 代码主体逻辑写在这里是中序遍历
xorder_Traversal(root->right,ans);
// 代码主体逻辑写在这里是后序遍历
}
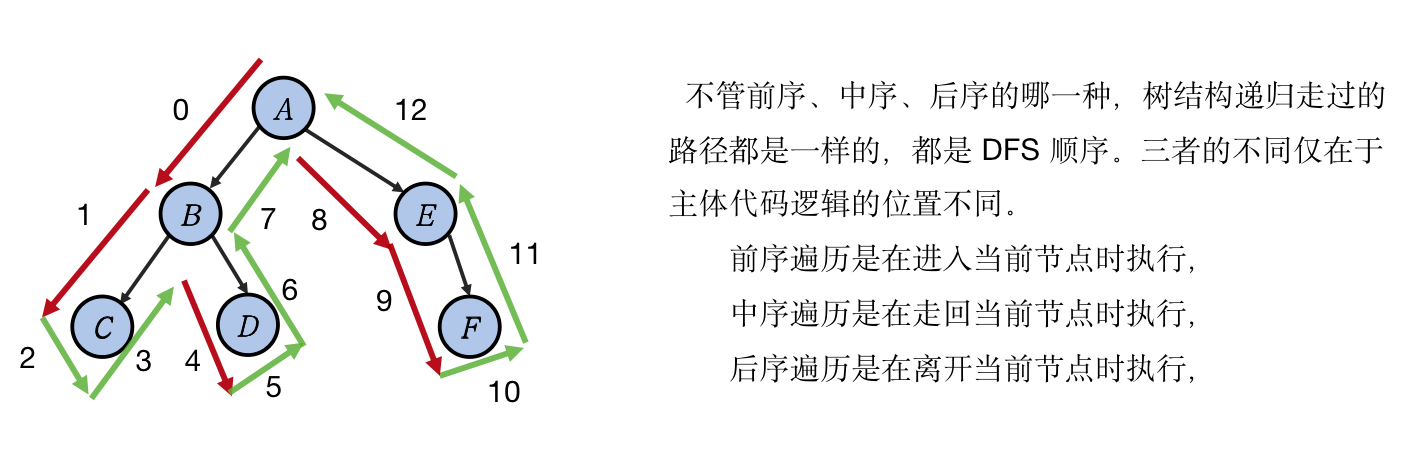
如图所示,无论何种遍历,其走过的路径都是一样的。我们使用红色标记向下递归的路径,使用绿色标记递归返回的路径。走入空节点的时候我们跳出递归直接往回走,这个步骤我图中省略不画。
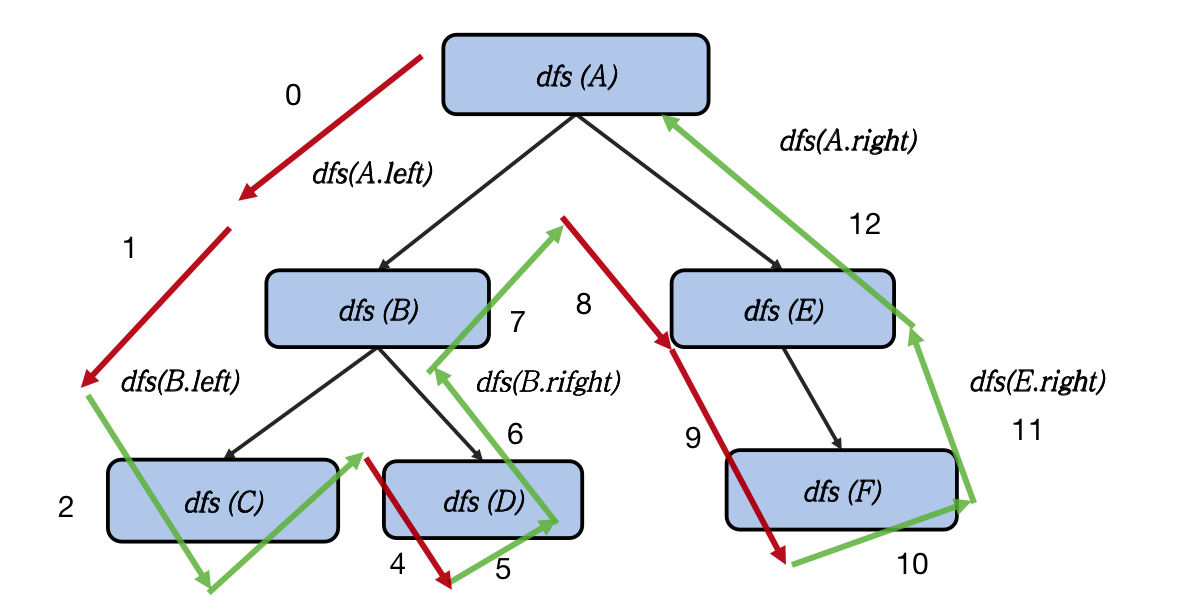
整个遍历过程,先是 A 走到 B,然后 B 走到 C,然后 C 走回 B,再从 B 走到 D,D 走完之后左侧子树已经走完,走回 B,再从 B 走回 A 节点,然后再从 A 去走右子树,A 走到 E,E 走到 F,右侧子树走完,于是往回走经过 E,E 往回走经过 A。
| 遍历方式 | 总结 |
|---|---|
| 前序遍历 | 当自上往下走的时候,能够通过 传参 形式把当前节点的信息传给下一层,如果当前函数的参数无法满足传参的需求,又无法修改当前函数的参数列表,则要另开一个辅助函数。其特点是先执行某个动作再遍历左右子树 |
| 中序遍历 | 当树节点按照左子树比起当前树节点值更小、右子树比当前树节点值更大,那么此时中序遍历会得到一个升序的序列。一般中序遍历会用于BST,需要注意当前节点的前驱并非左节点而是左子树的最右侧节点,后继也非右节点而是右子树最左节点 |
| 后序遍历 | 当自下往上走的时候,能够通过 返回值(推荐做法),或者引用变量(可考虑)、全局变量(不推荐)等形式把当前节点的信息传给上一层。其特点是在执行操作时,已经遍历了当前节点的左右子节点 |
| 层序遍历 | 相较于以上三种基于深搜实现的遍历方式来说比较特殊,因为树结构属于 DAG 模型,层序遍历可以结合拓扑排序来考察动态规划,但是这种问题往往需要自己建模构造一棵树 |
下面给出几道经典的练习,
| 题目 | 思路描述 |
|---|---|
| LC0669. 修剪二叉树搜索树 | 对于不在指定区间 之间的树节点,如果是叶子节点直接删除,如果左树为空,返回对右树修剪之后的结果,如果右树为空返回对左树修剪的结果,如果左右均不可为空,借助 BST 性质可以排除一侧,只需要返回另一侧修剪之后的结果 |
| LC0110. 平衡二叉树 | 分析左右两侧高度是否平衡,如果平衡需要分别判断左右子树是否也都平衡,因而使用先序遍历模型,走到空节点的时候退出递归 |
| LC0257. 二叉树的所有路径 LC0112. 路径总和 LC0113. 路径总和II |
本题要求找到根节点走到叶子节点的路径,叶子节点左右孩子均为空节点,我们令走到空节点退出递归,由于存储的路径是顺序的,当前树节点值纳入路径之后,可以沿着左子树或右子树往下走,因而使用前序遍历模型 |
| LC0501. 二叉搜索树的众数 | 看到 BST 马上想到中序遍历,一个朴素的想法是将其转为有序的序列再用哈希表统计,但是这样空间复杂度,不符合要求,注意到二叉搜索中相同的数值在遍历过程中,是连续存在的,因而使用全局变量对其计数即可 |
(2.1.1) 非递归写法
使用空节点来做标记,每次压入一个树节点的同时也压入一个空节点。这种写法能够统一前中后三种顺序的遍历,使其与递归写法一样,具有相似的框架的。
// 使用栈模拟递归的过程,由于LIFO特点,压入节点的时候记得顺序要反转一下
vector<int> xxx_orderTraversal(TreeNode* root) {
vector<int> ans;
stack<TreeNode*> stk;
if(root != NULL)
stk.push(root);
while(!stk.empty()){
auto curr = stk.top(); stk.pop();
if(curr != NULL){
// 后序遍历...
if(curr->right) stk.push(curr->right);
// 中序遍历...例如下面这样,每次压入树节点之后也要压入空节点
// stk.push(curr);
// stk.push(NULL);
if(curr->left) stk.push(curr->left);
// 前序遍历...
}else{
curr = stk.top(); stk.pop();
ans.push_back(curr->val);
}
}
return ans;
}
(2.2) 维护递归中树节点前驱
一种维护前序的粗暴的方法是直接是把树转为序列,然后再对序列维护,但是这样会有额外的转化开销,不够优雅,一种比较好的做法是在辅助函数中传入一个引用类型的参数(或者使用全局遍历)维护当前树节点的前驱,这种方法对于前中后三种遍历顺序均是适用的,但是一般只用于中序遍历模型。
| 题目 | 思路描述 |
|---|---|
| LC0530. 二叉搜索树的最小绝对差 | 我们可以在遍历的过程中维护一个前驱变量 prec 如果前驱不为空,更新树节点的最小差值,如果为空,则以当前树节点更新前驱节点。具体可见下列代码,这一段维护前驱的主体逻辑同样可以用于前序和后序遍历 |
| LC0538. 把二叉搜索树转换为累加树 | 由于要把大于等于元素的元素累加到当前树节点上,所以我们需要先遍历BST 右子树,再遍历左子树,然后在两个递归入口之间维护前驱信息,基本方法与LC0530一模一样。 |
class Solution {
public:
void dfs(TreeNode *root, int &prec, int &ans){ // 注意 prec 要用引用类型,否则调用者的 prec 无法更新
if(root == NULL)
return;
dfs(root->left, prec, ans);
if(prec != -1){ // 如果前驱节点不为空,使用当前节点与其前驱之间的差值更新最小绝对差值
ans = min(ans, root->val - prec);
}
prec = root->val; // 更新前驱值
dfs(root->right, prec, ans);
}
int getMinimumDifference(TreeNode* root) {
int ans = INT_MAX, prec = -1;
dfs(root, prec, ans);
return ans;
}
};
其实上述的方法亦可使用指针实现,但若使用树节点指针实现,函数内部修改指针的指向是无法改变调用dfs 函数的 getMinimumDifference 函数内部的 prec 指针的,指针也像基本变量变量那样,会在传参的时候发生拷贝,因而能够通过大部分的测试用例,但当 root 为空,直接返回,不进入递归,此时没有发生参数拷贝,代码会出错,例如样例 [5,4,7] 便会遇到这种问题。因而必须使用引用类型,或者使用二级指针,原理方面与上面的实现方案其实是一样的。

void dfs(TreeNode *root, TreeNode* &prec, int &ans){
if(root == NULL)
return;
dfs(root->left, prec, ans);
if(prec != NULL){
ans = min(ans, root->val - prec->val);
}
prec = root;
dfs(root->right, prec, ans);
}
下面代码来自于 LC0538. 把二叉搜索树转换为累加树,传入树节点指针的方法其实是更有通用性的,当然也可以只传入树节点的存储的数值,如果题目给出了树节点存储数据的取值范围,我们只要挑选一个范围之外的数值作为空节点即可。
class Solution {
public:
void dfs(TreeNode *root, TreeNode * &prec){
if(root == NULL)
return;
dfs(root->right, prec);
if(prec != NULL){
root->val += prec->val;
}
prec = root;
dfs(root->left, prec);
}
TreeNode* bstToGst(TreeNode* root) {
TreeNode* prec = NULL;
dfs(root, prec);
return root;
}
};
(2.3) 基于宽搜的层序遍历
由于层序遍历的性质比较特殊,将其与上述三种分开讨论。由于层序遍历的模版非常单一,熟练掌握之后几乎不需要思考即可写出,这类题目的套路也都固定,参考下列题单,稍加联系即可。少数情况之下,由于树结构是典型的有向无环图,所以较难的题目一般都是考察 DAG 图上动态规划,或是某种贪心策略。
| 题目描述 | 思路描述 |
|---|---|
| LC0103. 二叉树的锯齿形层序遍历 | 层序遍历之后根据奇偶性反转个别层数 |
| L0199. 二叉树的右视图 | 使用一个变量记录本层的元素值,后来的数值会覆盖签名的数值,完成层序遍历之后,变量记录的即为每一层的末尾元素 |
| LC0515. 在每个树行中找最大值 | 遍历遍历的过程中寻找最大值即可 |
| LC0637. 二叉树的层平均值 | 层序遍历之后计算平均值即可,需要注意数据类型转化 |
(三) 双树问题-树上双指针
大部分树结构的题目均可通过递归方法间接的解出,这些递归解法之中蕴含了一种强大的递归思维,也即对称性递归(Symmetric Recursion),对于二叉树这种逻辑对称的数据结构,从其整体的对称性思考,把大问题分解成子问题进行递归,而不单独思考形如树的左子树或右子树这样的局部,而是同时考虑对称的左右子树两个部分,从而写出对称性的递归代码。例如,二叉树最小或最大树深度、树直径等问题是经典的「单树问题」「双树问题」通常是要访问两棵二叉树的问题,比如合并两棵二叉树、判断两棵树是否相同,判断一棵树 左右是否平衡,以及判断一颗树 是不是另外一棵树 子树等问题。
其中(2.1.1)提到的问题,只要选择合适的遍历模型即可很快解决,但对下面给出的几道例题,想要写出一个只传入一个树节点作为参数的递归函数可就不那么容易了,这些问题统称「双树问题」,如果题目的函数签名只传入一个树节点,我们可以尝试去把「单树问题」转为「双树问题」。
所谓双树问题,我们回忆一下双指针。对于两个线性表,使用双指针维护信息是十分常见的,在树结构场景之中,我们同样可以使用双指针的技巧的遍历树结构。例如 LC0101. 对称二叉树,这道题就是一个经典的双树问题,检查一颗二叉树是否对称,根节点作为对称轴,显然是不用判断的,我们只要判断左右两棵子树是否对称即可,于是这个问题变成了两个二叉树是否对称。因而我们可以设计一个辅助函数 dfs,其参数是两个树的根节点,如果两棵树同时为空,显然对称,如果一侧为空一侧不空,显然不对称。然后两棵树的根节点一定要相等,不然肯定不对称,左侧子树的右侧要等于右侧子树的左侧,右侧子树的左侧要等于左侧子树的右侧。
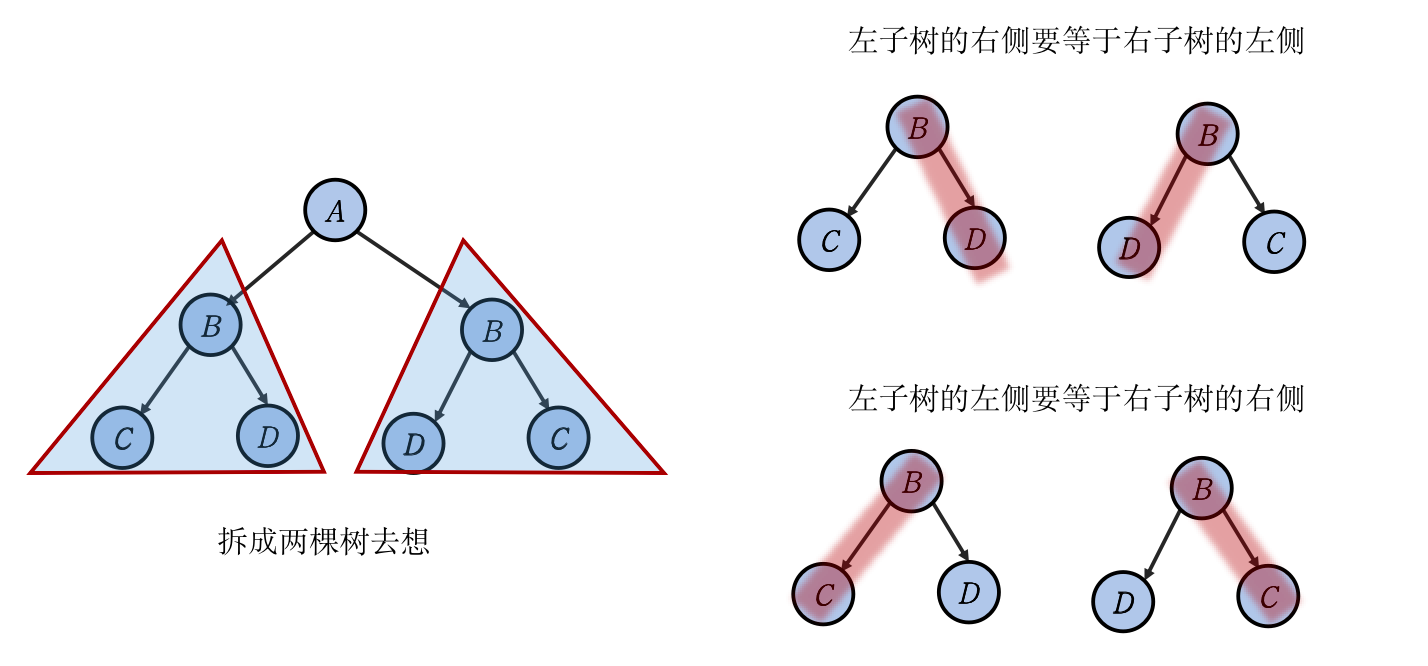
bool dfs(TreeNode* p ,TreeNode *q){
if(!p && !q) return true; // 如果两边同时是空节点返回 true
if(!p || !q) return false; // 如果两边不同时为空,一侧为空一侧非空返回 false
if(p->val != q->val){
return false; // 如果两棵树根节点不相等则一定不对称
}
bool L_is_symmetric = dfs(p->right, q->left); // 左侧是否对称
bool R_is_symmetric = dfs(p->left, q->right); // 右侧是否对称
return L_is_symmetric && R_is_symmetric;
}
上述代码是一个很难说是前序遍历或是后序遍历,因为判断两棵子树的逻辑位于递归函数之前,然而左右子树递归返回的结果也会在递归之后用到。你说这是前序也行,说是后序也性。至此我们会发现,在解决实际问题中,我们通常需要结合多种顺序的遍历模型。上面的代码其实是仍然可以优化,如果左树不对称,那么右树自然也就不必继续判断的,我们可以提前返回,又因为函数的返回值是一个布尔值,我们可以利用条件语句的「短路机制」将其合并于同一行,如下所示,这样的代码是一个「纯粹的前序遍历」模型,先做主题逻辑判断,然后递归处理左侧与右侧。这种优化能使的运行效率会快一大截,而且使用的栈空间也更少。
// 显然空子树是对称的,如果树节点非空,将其拆成左右两棵子树进行判断。
bool dfs(TreeNode* p ,TreeNode *q){
if(!p && !q) return true; // 如果两边同时是空节点返回 true
if(!p || !q) return false; // 如果两边不同时为空,一侧为空一侧非空返回 false
return p->val == q->val && dfs(p->right, q->left) && dfs(p->left, q->right);
}
bool isSymmetric(TreeNode* root) {
if(root == NULL){
return true;
}
return dfs(root->left, root->right); // 拆成左右两棵子树去做分析
}
另外一道类似的问题来自于 LC0572. 另外一棵树的子树,这道题传输的参数是两个根节点,其实已经向我们透露了一个重要的信息,这是一个双树问题。我们可以先将问题拆成两个子问题,
- 如何比较两棵二叉树是否相等?
- 如何枚举一颗二叉树的所有子树?
对于第一个问题,显然我们只要对比两个二叉树的根节点是否相等,再递归对比其两棵树的左子树、右子树是否相等即可。对于第二个问题,如果给定了一个二叉树 ,其每个节点及其往下的所有树节点都可以构成一棵「子树」,我们枚举所有子树其实就是枚举所有这棵树的所有节点。
然后我们再合并两个问题,如何判断一个树 是不是另外一个树 子树呢,首先枚举 所有子树,然后比较其每个子树与当前指定的子树 是否相等即可,如果存在一个子树与之相等,说明 ,
class Solution {
public:
bool dfs(TreeNode *p ,TreeNode *q){
if(!p && !q) return true; // 同时为空说明相等
if(!p || !q) return false; // 一侧为空一侧不空说明不相等
return p->val == q->val && dfs(p->left, q->left) && dfs(p->right, q->right);
}
bool isSubtree(TreeNode* root, TreeNode* subRoot) {
if(root == NULL)
return false;
return dfs(root, subRoot) || isSubtree(root->left, subRoot) || isSubtree(root->right, subRoot);
}
};
下面是本小节提到的题目思路总结,
| 题目 | 思路描述 |
|---|---|
| LC0101. 对称二叉树 LC0572. 另外一棵树的子树 |
单树问题转为双树问题,然后枚举两棵树对应的节点做比较,如果符合条件再继续判断两棵树的子树,故采用先序遍历模型,走到空节点的时候退出递归 |
| LC0236. 二叉树的最近公共祖先 | 公共祖先问题是一个经典的双树问题,需要分析三种情况,给定节点 、,位于树两侧子树,那么当前节点就是公共祖先,如果同时位于左侧或右侧,较高的一个就是公共祖先。不管哪种情况,都要先搜索左右子树,要先得知左右子树的信息才能判断当前节点是不是公共祖先,所以采用后序遍历模型,向两棵子树中去搜索 |
其中「公共祖先」问题是一个非常经典的模型,深入理解 LCA 模型请看此篇博客
(四) 二叉树的树上路径问题
二叉树的树上路径问题,如果仅仅是单次问询,即在短时间之内不需要大量重复的询问树上的路径,我们通常只需要套用二叉树递归模型遍历一次即可。寻找路径通常会以前序,或者后序遍历两种形式来实现,前序更加符合常人的直觉,所以我们采用前序遍历模型来实现。接下来,我们需要构造一个辅助函数dfs,为什么我们直接在原函数基础上面实现呢,这是因为树递归模型的返回值通常是树节点,如果我们的求解目标,也即给出的函数返回值,并非一个树节点,我们通常另开一个辅助函数会使编码更容易一些。
class Solution {
public:
void dfs(TreeNode *root, string tmp, vector<string> &ans){
if(root && root->left == NULL && root->right == NULL){
tmp += to_string(root->val); // 如果走到了叶子结点,说明已经走到了路径的尽头,无需再添加箭头
ans.push_back(tmp); // 存储答案并跳出递归
return;
}
tmp += to_string(root->val);
if(root->left) dfs(root->left, tmp + "->", ans); // 如果左子树非空枚举左子树
if(root->right) dfs(root->right, tmp + "->", ans); // 如果右子树非空枚举右子树
}
vector<string> binaryTreePaths(TreeNode* root) {
vector<string> ans;
dfs(root, string(), ans); // 构建一个辅助函数来简化编码实现
return ans;
}
};
上面的代码已经是正确解法了,其实主要思想是走到叶子节点的时候做一次特判,通常我们编码都是走到空节点才返回,如果本题也遵循空节点返回这个逻辑,那么本题代码可以写成下列形式。如此以来,代码看上去更像一个前序遍历模型,进入递归之前的两次 if 判断也被归于进入函数之后的判空操作。
void dfs(TreeNode * root, string tmp, vector<string> &ans){
if(root == NULL)
return;
tmp += to_string(root->val);
if(!root->left && !root->right){ // 如果当前树节点是一个叶子节点,说明路径已经走到尽头,纳入答案
ans.push_back(tmp);
return; // 这句返回其实也是可以省略的,不影响正确性
}
dfs(root->left, tmp + "->", ans);
dfs(root->right, tmp + "->", ans);
}
对于 路径总和II 来说,解法也是基本相同的,只不过需要多增加一个变量 sumv,然后前序遍历往下传递信息,走到叶子节点的时候再比较 sumv 与 target 即可,具体代码,如下所示,由于传递的 tmp 变量是一个引用类型 vector<int> &,所以要在函数主体与递归结束之后,向上返回之前,弹出末尾元素。不然得到的 ans 数组里面的内容,除了第一个之外几乎都是错误的。如果觉得引用类型不好理解,可以改用普通的向量类型 vector<int>,这样每次传参的时候都对 tmp 进行一次复制,必不出错,但是运行效率会下降很多。
class Solution {
public:
void dfs(TreeNode *root, int sumv, int targetSum, vector<int> &tmp, vector<vector<int>>&ans){
if(root == NULL){
return;
}
sumv += root->val;
tmp.push_back(root->val);
if(root->left == NULL && root->right == NULL && sumv == targetSum){
ans.push_back(tmp); // 如果当前节点是一个叶子节点,纳入答案但不返回
}
dfs(root->left, sumv, targetSum, tmp, ans);
dfs(root->right, sumv, targetSum, tmp, ans);
tmp.pop_back();// 如果上面返回退出那么下面tmp无法正常弹出尾部元素
}
vector<vector<int>> pathSum(TreeNode* root, int targetSum) {
vector<vector<int>> ans;
vector<int> tmp;
dfs(root, 0, targetSum, tmp, ans);
return ans;
}
};
(五) 多叉无根树模型
多叉无根树首先要解决的一个问题就是树要如何存储,通常我们会用整数来对树节点编号,然后再用二维数组存储树节点之间的连边。这类问题与我们常见的二叉树问题不太一样,但其逻辑上仍然是一颗二叉树。比如下面的例题 LC2477,这道题有一个简化的,没有 seats 约束,而且是在线性结构之上模拟的版本,LC1769,在做下面一题之前可以先行试试。
| 题目 | 思路描述 |
|---|---|
| LC2477. 到达首都的最少油耗 | 通常这类问题都要转为树上信息维护,但其难点恰恰在于如何转为一般的树上信息维护问题,注意到车辆其实是可以丢弃的(使用的车辆越少油耗越少),所以我们需要解决经过某个树节点的时候,至少要用几辆车,其实也就是各个子节点汇聚的人流数量,然后再算这些人流数量所需的车辆数量。 |
支持作者



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现