道长的算法笔记:最短路模型
(一) 正权图最短路引理
以下三条引理适用于正权图:
- 任意两个顶点之间的路径不存在重复顶点与重复边
- 任意两个顶点之间顶点数不超过 ,边数不超过
- 最短路径具有最优子结构性,也即 节选得到的 即是 最短路径
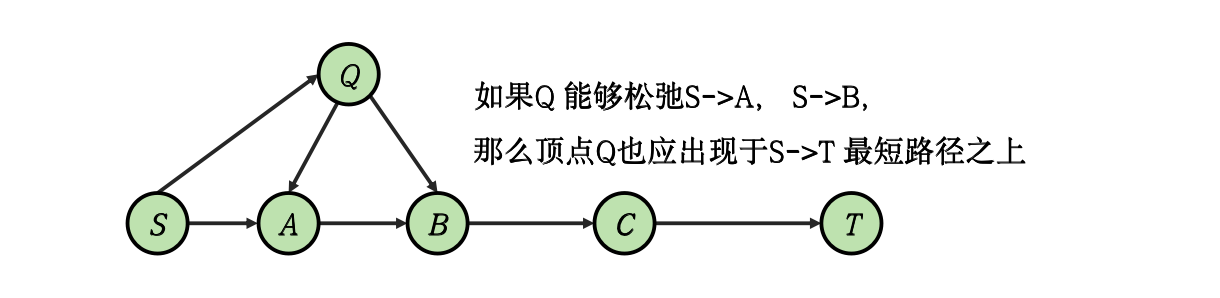
对于一个正权图,如果存在一条经过若干顶点的 最短路,例如 ,不妨将其记作 ,那么对于 路径节选出来的 、、 必然也是最短路。使用反证法很容易证明这一点,假设 路径并非最短路径,那么必然可以找到另外一条比其更短的路径,比如 ,这里的 代表一个或多个能够用于松弛 路径的顶点,如果存在这样的路径,那么 路径当中的 部分必然能被 替换,从而变得更短,故与 是最短路径矛盾,证毕。最短路问题的最优子结构性保证了几种经典最短路模型的正确性。
(二) 经典最短路模型
(2.1) BFS寻找无权图最短路
对于无权图,BFS搜索的路径会生成一棵树,通常将其称为「最短路径生成树」,我们知道根节点走到某个树节点的路径是最短的,也是唯一的。因而使用 BFS 寻找最短路非常符合我们的感性认知,如果需要提供算法正确性证明,又该如何证明呢?
我们假设已经访问的顶点记作 ,仍未访问的顶点记作 ,起点与终点分别记作、,我们使用 记录起点 走到 顶点的最短距离。 BFS算法会逐层向外扩散访问当前列首顶点的邻接顶点。
- 对于起点 显然会有
- 对于起点的所有邻接顶点 ,显然会有
假设扩散走到第 层顶点能够算出这一层所有顶点的最短路径,那么第 层顶点也能如法炮制的算出的最短路径。
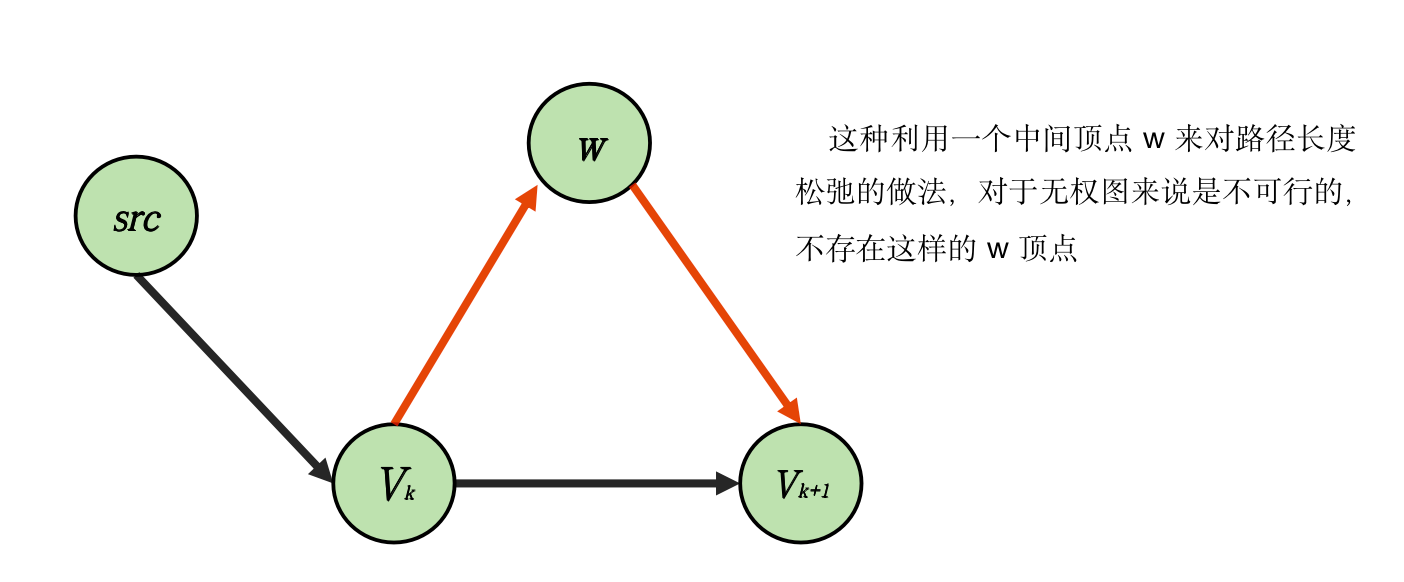
我们使用反证法,假设 第 层的某个顶点 无法算出最短路,也就是说,存在某个顶点 ,能够松弛 ,使得 比起 更短,然而无权图的每条边的长度均为,根据三角不等式关系可知 ,不可能存在这样的 ,也就是说, 第 层的不存在顶点 无法算出最短路。
现在给定一个经典的问题,本题来自于AcWing提高班 抓住那头牛, 假设农夫知道一头牛的位置,想要抓住它。农夫和牛都位于数轴上,农夫起始位于点 N,牛位于点 ,农夫有两种移动方式:
- 从 移动到 或 ,每次移动花费一分钟
- 从 移动到 ,每次移动花费一分钟
假设牛没有意识到农夫的行动,站在原地不动,请问最少需要花费多少时间才能抓到这头牛。其实这个问题其实就是一个经典的无权图最短路径问题,此处给出一种简化代码的技巧,如果按照题目的含义去做模拟,我们需要分类讨论,但若使用向量化的表示,农夫下一次移动的距离能被写成:
我们把移动轨迹向量化之后,简化的代码如下所示:
#include<bits/stdc++.h>
#include<limits.h>
using namespace std;
typedef pair<int,int> ii;
// 移动轨迹向量化
int add[3] = {+1, -1, 0};
int mul[3] = { 0, 0, 1};
int vist[100005];
int n, k, N = 1e5;
int bfs(){
if(n >= k){
return n - k;
}
queue<ii> q; q.push({n, 0});
while(q.size()){
auto [x, s] = q.front();q.pop();
for(int i = 0; i < 3; i++){
int nx = add[i] + mul[i] * x + x;
if(nx < 0 || nx > N || vist[nx]){
continue;
}
vist[nx] = 1;
q.push({nx, s + 1});
if(nx == k){
return s + 1;
}
}
}
return 0;
}
int main(){
scanf("%d %d", &n, &k);
printf("%d\n", bfs());
return 0;
}
(2.2) Dijstra 算法
(2.2.1) Naive-Dijstra
Dijstra 算法,读作「戴克斯戳」,音译过来「迪杰斯特拉」其实是由于译者一知半解导致的,荷兰语里「ij」是一个双元音,并没有「杰」这么个音。言归正传,说回算法,Dijstra 是一个基于贪心策略的单源最短路算法,其正确性是由正权图最短路的最优子结构保证的,也即是说,Dijstra 无法处理带有负权边的图结构。
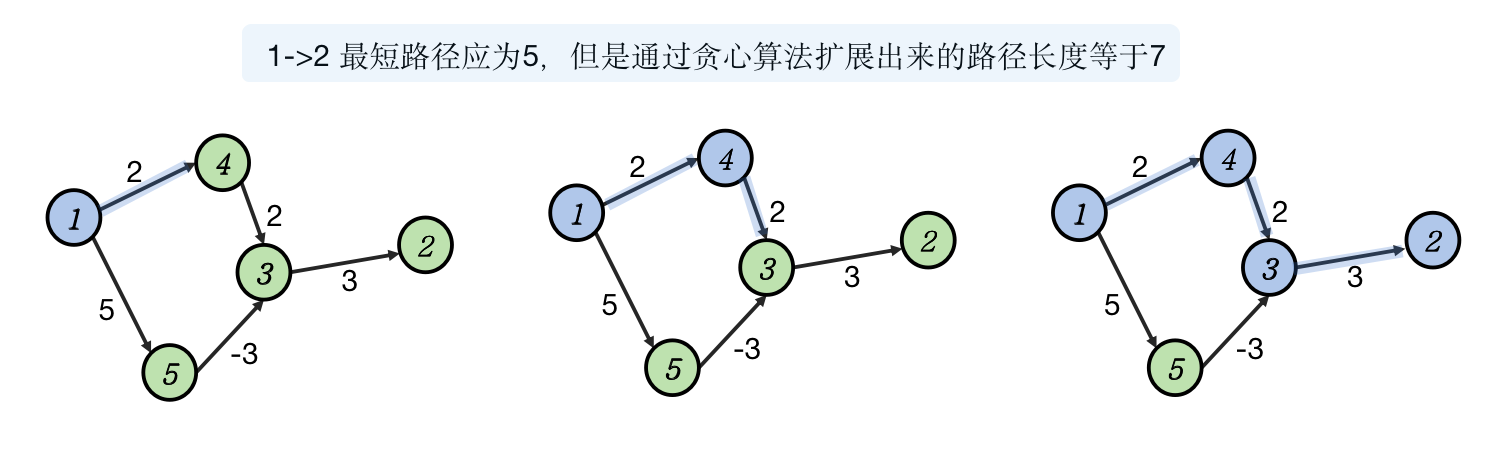
Dijstra 算法的思想是将顶点分成两个集合 、,其中 代表已经找到最短路径的集合, 代表未找到最短路径的集合。我们使用一个数组 维护 最短路径长度。 初始状态中只有源点 位于,此时 ,其余所有顶点 全部设为无穷大。
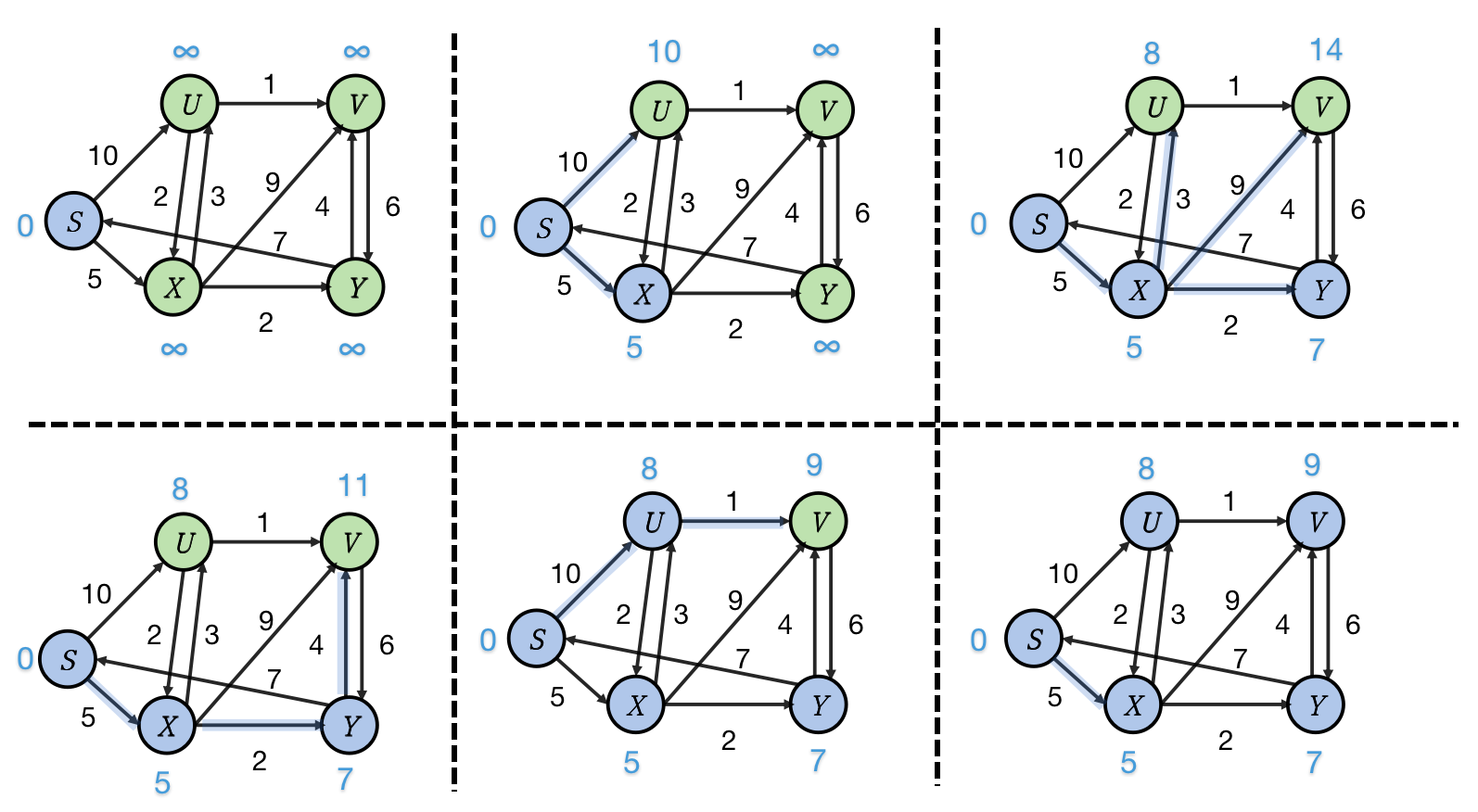
先从 出发,松弛其所有可到达的顶点。不严谨的来说,这个过程其实是用长度等于 路径更新得到长度等于 路径,因为如果引入某个顶点 之后能够松弛 ,那么路径长度会增加 ,然后再从所有已经找到最短路径的顶点中,挑选最短的一个,这一步挑出的路径长度可能等于 ,也可能等于 ,我们不在乎长度只在乎是否最短,挑出最短路径的更新 集合中所有未找到最短路径的顶点。以此类推,循环若干次之后我们能够找到从源点出发走到汇点的 路径的长度。根据正权图最短路径长度不大于 可知,循环次数 即可。 不难看出算法的复杂度达到 级别。
vector<ii> edges[MAXN];
int vist[MAXN], dist[MAXN];
void dijstra(int s){
memset(dist, 0x3f, sizeof(dist));
dist[s] = 0;
for (int i = 1; i < n; i++) {
int t = 0;
for (int j = 1; j <= n; j++){
if(!vist[j] && dist[j] < dist[t]){
t = j;
}
}
vist[t] = 1;
for(auto[w, v]: edges[t]){
if(dist[v] > dist[t] + w){
dist[v] = dist[t] + w;
}
}
}
}
通常我们使用 Dijstra 计算某一个顶点 到达另外一个顶点 之间的距离,或者某一个顶点 到达其它所有顶点的距离,但是如果我们希望求解其它所有顶点到达某个顶点 之间距离,此时我们可以反向建图,然后再对反向图的起点跑一次 Dijstra 即可。
(2.2.2) Heap-Dijstra
对于稠密图来说,i.e. 连边数量级大于顶点的图结构,朴素Dijsttra算法的时间复杂度 其实是比较合适的,但是对于稀疏图来说,i.e. 连边数量级等于顶点的图结构,显然很多内层循环的很多枚举是不必要。我们使用边表这种数据结构已经算好了,如果使用邻接矩阵复杂度会更高,而且空间占用也将非常大,顶点个数上万的时候,很容易出现 MLE,因而会有堆优化的 Dijstra 算法,我们通常记作 Heap-Dijstra,其复杂度 ,其中 代表连边的条数。
同样的,我们划分 、 两个集合,最初只有源点位于,将其出列松弛所有与其连接的邻接顶点,然后再把松弛之后获得的最短路径取出用以下一轮松弛。这种写法的代码非常类似于SPFA,但是又有本质不同。此处 数组用于记录是否已经找到最短路,也即是说,是否已经位于 ,如果已在 ,那么跳过当前顶点,否则使用顶点的 信息松弛其邻接顶点。

之所以要这样是因为堆结构,或说优先队列结构,无法快速修改或删除任意元素。一旦发生松弛则要入列,然而发生松弛不代表已经找到最短路,一个顶点的 可能会被松弛多次,因而优先队列之中会有多个重复顶点,但是携带最短路径信息顶点一定位于最上层,使用其松弛了邻接顶点信息之后,将其纳入集合,也即使用 标记一下,说明已经找到最短路,随后再次访问这个顶点的时候直接跳过。如果不想使用 数组也是可以的,只要修改代码判定条件,改成「如果 ,跳过当前出列顶点」即可。
vector<ii> edges[MAXN];
int vist[MAXN], dist[MAXN];
void dijstra(int s){
priority_queue<ii, vector<ii>, greater<ii>> q;
memset(dist, 0x3f, sizeof(dist));
dist[s] = 0;
q.emplace(0, s);
while (q.size()) {
auto [d, u] = q.top(); q.pop();
if(vist[u]){
continue; // 改成 dist[u] < d 也是可以的!
}
vist[u] = 1; // 如果出列顶点未访问且距离源点最短则将其纳入集合 S
for(auto [w, v]: edges[u]){
if(dist[v] > dist[u] + w){
dist[v] = dist[u] + w;
q.emplace(dist[v], v);
}
}
}
}
(2.3) Bellman-Ford 算法
(2.3.1) Naive-Bellman-Ford
Bellman-Ford 是在相近的几年里被三个人分别独立发明,但是不知道是什么原因算法名称后来定型成了 Bellman-Ford,这个算法能够判断图中是否存在负环。Dijstra 算法的松弛操作是从 集合之中选出最短的一条路径用于松弛其它路径,Bellman-Ford 算法与之不同的地方在于每一轮循环,对图上所有的边都尝试进行一次松弛操作,而且循环次数 而非 ,当在一次循环中没有成功的松弛操作时,算法停止。
之所以要多循环一次自然是为了判别图中是否存在负环,我们知道正权图中任意两个顶点的连边数量不超过 ,所以循环次数 即可,但若存在负环,那么第 次循环仍然会发生更新。
vector<ii> edges[MAXN];
int vist[MAXN], dist[MAXN];
bool bellman_ford(int s) {
bool is_updated;
memset(dist, 0x3f, sizeof(dist));
dist[s] = 0;
for (int i = 1; i <= n; i++) {
is_updated = false;
for (int u = 1; u <= n; u++) {
if (dist[u] == 0x3f3f3f3f)
continue;
for (auto [w, v] : edges[u]) {
if(dist[v] > dist[u] + w){
dist[v] = dist[u] + w;
is_updated = true;
}
}
}
if(!is_updated) break;
}
return is_updated; //如果第N次循环仍被更新说明存在负环
}
(2.3.2) Queue-Bellman-Ford
使用队列优化的 Bellman-Ford 算法也称 SPFA,通常会被用于判断图中是否存在负环,或者用于作为费用流算法的构件。相较于朴素的 Bellman-Ford 算法,使用了额外的空间 存储从起点 到顶点 最短路径的边数,如果边数超过了 ,说明存在负环,直接返回,因而图中存在负环的时候,讨论最短路的是没有意义的。
由于 Queue不同于优先队列具有自排序的机制,为了避免对图上所有的边都尝试进行松弛操作的过程中出现重复更新,我们使用 那些已在列中的顶点,如果已在列中则无需重复入列。
vector<ii> edges[MAXN];
int dist[MAXN], inq[MAXN], cot[MAXN];
bool bellman_ford(int s){
memset(dist, 0x3f, sizeof(dist));
dist[s] = 0, inq[s] = 1;
queue<int> q;
q.push(s);
while(q.size()){
int u = q.front(); q.pop(); inq[u] = 0;
for (auto [w, v] : edges[u]) {
if(dist[v] > dist[u] + w){
dist[v] = dist[u] + w; // 更新最短路径的长度
cot[v] = cot[u] + 1; // 更新最短路径的顶点个数,发生松弛则顶点+1
if (cot[v] >= n){
return true;
}
if(!inq[v])q.push(v);
}
}
}
return false;
}
基于队列优化的 Bellman-Ford 算法(SPFA)最坏复杂度与朴素 Bellman-Ford 算法是一样,都是 ,但在随机图上面 SPFA 跑得飞快,但是链式菊花图、网格图等结构若是存在大量次短路,是会卡掉 SPFA,使其复杂度退化的,所以如果给定数据是确保是一个正权图则如果能写 Dijstra 千万别用 SPFA 来写。
(2.4) Floyd 算法
Floyd 算法是一个正权图全源最短路(APSP,All Pair Shortest Path)算法,能在 复杂度之内算出所有顶点对之间的最短路径,适用于顶点数不多的情况。其本质是一个动态规划算法。最外层循环的意思是说,允许经过前 个顶点的时候,顶点对 之间的最短路径是多少。因而,正确的循环顺序是kij,不可更换,但是实际上做3次 ikj或者ijk也能得到正确的结果。
int g[MAXN][MAXN], n, m, k, a, b, w;
void floyd(){
for(int k = 1; k <= n; k++){
g[k][k] = 0;
for(int i = 1; i <= n; i++){
for(int j = 1; j<= n; j++){
g[i][j] = min(g[i][j], g[i][k] + g[k][j]);
}
}
}
}
(2.5) Johnson 算法
国内的教材很少提及 Johnson 算法,Johnson是一个适用于带有负权边的全源最短路算法,其做法其实相当于是跑若干次 Heap-Dijstra算法,时间复杂度 ,不同的地方在于,其对独特的预处理方式,解决了 Heap-Dijstra 算法无法应对负边权的问题。
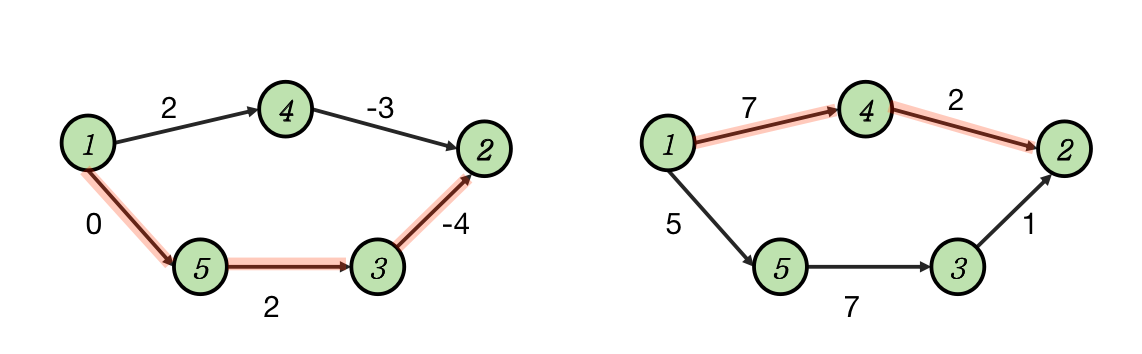
由于 Heap-Dijstra 算法无法用于带有负权边的图结构,一个朴素的想法是对图中每条便都加上一个偏移量 ,然后计算最短路的过程中维护路径的边数 ,算得最短路径之后再将其减掉 ,然后这种做法是不正确的。因为添加偏移量之后最短路的路径可能会发生改变。如图所示,原先的最短路 ,偏移之后的最短路的变成了 ,行经的路径发生了根本性的改变。
Jonhson 算法巧妙的地方在于,引入了势能的概念。首先虚设一个虚拟顶点连接所有顶点,然后使用 Bellman-Ford 算出虚拟顶点到任意顶点 最短路径 ,然后再将所有边权 改造变成 ,假设原图上面最短路径,将其权重展开之后,路径长度等于:
化简之后得到:
只要起点与终点确定,中间路径无论如何都不影响势能的结果,利用这个式子与原始路径的映射关系,不难算出负权图的全源最短路径。
(三) 最短路模型总结
(3.1) 算法功能性与复杂度
| Dijstra | Naive-BF | Queue-BF(SPFA) | Floyd | Johnson | |
|---|---|---|---|---|---|
| 类型 | SSSP | SSSP | SSSP | APSP | APSP |
| 维护信息 | edges/dist/vist | edges/dist | edges/dist/inq | g | edges/dist/h |
| 算法 | 贪心,松弛 | 松弛所有边 | 出列队列松弛 | 动态规划 | 重新建图 |
| 负权边 | × | + | + | + | + |
| 负环 | × | + | + | - | + |
| 时间复杂度 | Naive: Heap: |
||||
| 适合图规模 |
(3.1) 算法练习题单
👇🏻下面给出一个练习题单,做完之后有助于加深对于最短路径问题的理解
| 题目 | 思路描述 |
|---|---|
| LG3371. 单源最短路弱化版 LG4779. 单源最短路标准版 |
最短路径模板题,弱化版能够用于练习Dijstra、Bellman-Ford及其各种花里胡哨的优化,标准版用于联系Heap-Dijstra |
| LG3385. 负环 | 使用SPFA 判断负环,开辟数组存储起点走到顶点的最短路径长度,如果大于等于n,说明存在负环 |
| LG1119.灾后重建 | 强化对于 Floyd 算法的动态规划部本质的理解,由于所有顶点是按修复完成时间排序的,因而按照修复时间顺序遍历走到第 k 个村庄,即意味着使用前k个村庄进行松弛。 |
| LG1629.邮递员送信 | 正向跑一次 Dijstra 即可(一对多),然后反向建图跑一次Dijstra(多对一),然后两次之和即为最短路径和 |
| LG1462.通往奥格瑞玛的道路 | 使用二分搜索去猜最小过路费,然后再用 Dijstra 算法来做验证即可 |
| LG1807.最长路 | 权值取负号转为最短路径问题,同时需要注意可能存在负权边、负环,不可以使用Dijstra 算法,同时除了判环之后也要判断是否可达终点,如果不可达与有环都要特判。大部分的 DAG 图上 DP 都可以转为最长路径或最短路径问题。 |
(四) 图上动态规划 DAG-DP
图上动态规划模型通常是在 DAG 上面来跑的,所谓 DAG(Directed Acyclic Graph) 是指有向无环图,如果给定的图结构并非 DAG 通常需要使用拓扑排序的方法,消环或者判环,或将问题抽象变为能够使用 Bellman-Ford 算法解决的最短或最长路径问题来做,这样需要考虑的条件会少一点,但是一般来说,前者的效率会更好一些。
(4.1) 拓扑排序
拓扑排序算法先将所有入度等于零的顶点入列,然后开始宽度优先搜索,对于出列的顶点,将其在图上抹去,这个过程等价于将其指向的所有顶点的入度减少 1,如果这些顶点的入度也变成了零,则将其入列,继续遍历,如此反复直至退出循环,比较出列的顶点个数是否等于总顶点个数。
int ideg[MAXN];
vector<ii> edges[MAXN];
bool top_sort(){
queue<int> q;
for (int i = 1; i <= n; i++) {
if (!ideg[i]) {
q.push(i); // 先将所有入度为零的顶点全部入列
}
}
int vcnt = 0;
while (q.size()) {
int u = q.front(); q.pop();
for (auto [w, v]: edges[u]){
ideg[v]--; // 抹去顶点 u 等价于将其所有邻接顶点入度减少 1
if (ideg[v] == 0) {
q.push(v);
}
}
vcnt++; // 统计出列的顶点个数
}
return vcnt == n; // 如果成果出列的顶点个数等于总顶点数,说明没有环
}
(4.2) 图上动态规划
图上动态规划的经典问题可以参考,洛谷上面的 LG1807.最长路、LG1113.杂物 这两道题能够很好的加深对于拓扑排序、 DAG 动态规划的理解。下面以最长路一题为例,本题坑点极多。首先题目要求我们找出一条 最长路径,边权有正有负,甚至可能有环,有可能是正环也有可能是负环。顶点个数大于 1500,边权为负,我们可以考虑对权值取负号,然后转为最短路模型来跑 Bellman-Ford 算法,但要注意需要特判是否能够走到顶点 ,如果无法走到顶点,显然是无解的。
#include <bits/stdc++.h>
#include <limits.h>
using namespace std;
typedef long long ill;
typedef pair<int, int> ii;
#define MAXN 100005
int n, m, a, b, c, is_cycle, reachable;
int vist[MAXN], dist[MAXN], cot[MAXN], inq[MAXN];
vector<ii> edges[MAXN];
void bellman_ford(int s = 1){
memset(dist, 0x7f, sizeof(dist));
dist[1] = 0;
queue<int> q; q.push(s); inq[s] = 1;
while (q.size()) {
int u = q.front(); q.pop(); inq[u] = 0;
for (auto [w, v] : edges[u]) {
if(dist[v] > dist[u] + w){
dist[v] = dist[u] + w;
cot[v] = cot[u] + 1;
if(cot[v] >= n){
is_cycle = 1;
return;
}
if(v == n){
reachable = 1;
}
if(!inq[v]) q.push(v);
}
}
}
}
int main(){
scanf("%d %d", &n, &m);
for (int i = 1; i <= m; i++){
scanf("%d %d %d", &a, &b, &c);
edges[a].emplace_back(-c, b);
}
// 需要考虑两种情况,一种存在负环,另外一种是不可到达的情况
bellman_ford(1);
if(is_cycle || !reachable){
printf("%d\n", -1);
}else{
printf("%d\n", -dist[n]);
}
return 0;
}
下面分析基于拓扑排序的做法,如果存在一个正环,显然是不存在最长路的,如果存在一个负环仍然是有可能存在最长路径的,所以检测到图上有环也不可以立刻断定答案就是 ,这是第一个坑点。
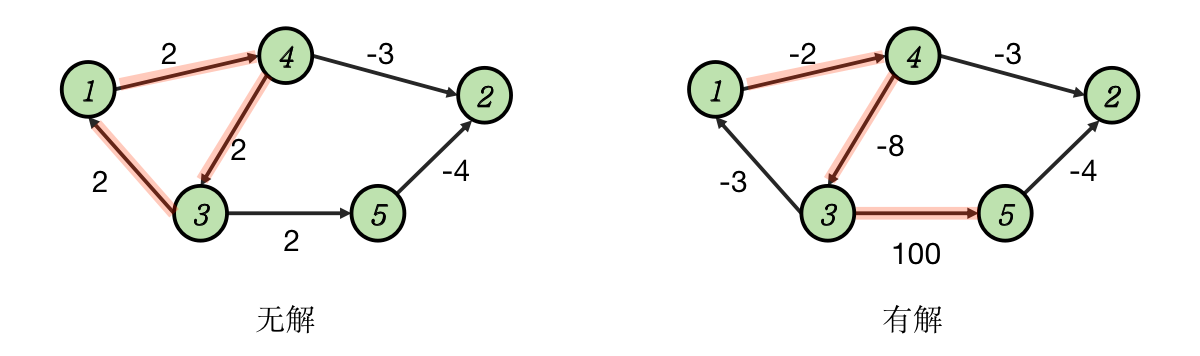
此外本题要求 ,入度等于零且编号不等于一的顶点入列之后,也有可能走到顶点 $N,这是第二个坑点,因而我们要对顶点 以外的所有顶点预处理,将其距离设为负无穷,一次代表非法状态,然后入列所有度数为零的顶点,然后将其抹去。然后再对顶点 入列,并在拓扑排序过程中维护最长路径信息。
#include <bits/stdc++.h>
#include <limits.h>
using namespace std;
typedef long long ill;
typedef pair<int, int> ii;
#define MAXN 1000005
int n, m, a, b, w;
int ideg[MAXN], dist[MAXN];
vector<ii> edges[MAXN];
void top_sort(){
queue<int> q;
for (int i = 2; i <= n; i++){
dist[i] = -1e9;
if(!ideg[i]){
q.push(i);
}
}
// 先把 1 以外的入度为零的顶点去掉
while(q.size()){
int u = q.front(); q.pop();
for(auto [w, v]: edges[u]){
ideg[v]--;
if(!--ideg[v]){
q.push(v);
}
}
}
q.push(1);
while (q.size()) {
int u = q.front(); q.pop();
for (auto [w, v]: edges[u]){
dist[v] = max(dist[v], dist[u] + w);
if (!--ideg[v]) {
q.push(v);
}
}
}
}
int main(){
scanf("%d %d", &n, &m);
for (int i = 0; i < m; i++){
scanf("%d %d %d", &a, &b, &w);
edges[a].emplace_back(w, b);
ideg[b]++;
}
top_sort();
printf("%d\n", dist[n] == -1e9 ? -1 : dist[n]);
return 0;
}
支持作者



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具