道长的算法笔记:二分图匹配
(一) 二分图的概念
二分图又称作二部图,是图论中的一种特殊模型。假设 是一个无向图,如果顶点 能够分割为两个互不相交的子集 ,并且图中的每条边 所关联的两个顶点 和 ,分别属于这两个不同的顶点集 ,则称图 为一个二分图。
(二) 如何判定二分图
通过BFS染色法,我们能够快速判定一个图是不是二分图。我们随便选择一个顶点出发,将其染为白色,从这个顶点出发将其邻接的顶点全部染成黑色,然后再从黑色的顶点出发,将其邻接未访问的顶点染为白色,如此反复即可。上述的过程出现了三种状态,「未访问」、「白色」与「黑色」,我们可以使用一个数组 记录每个顶点的状态 ,然后分别使用 三字数字表示三种不同的状态,查询状态的时候只需要访问 ,此处提到的算法也能使用 DFS 实现,而且更加简洁。
(三) 最大二分图匹配算法
(3.1) HA算法
二分图最大匹配是指,给定一个分为左右两个部分的二分图,两个部分内部的顶点连边,现在要求选出跨两个部分的连边(没有公共顶点的连边),并且连边的数量最大。简单来说,我们可以想象这样一个相亲模型,左边是男孩,右边是女孩,我们的身份就是月老,我们要做的事情是令左右两边的男生与女生凑出对数最大。
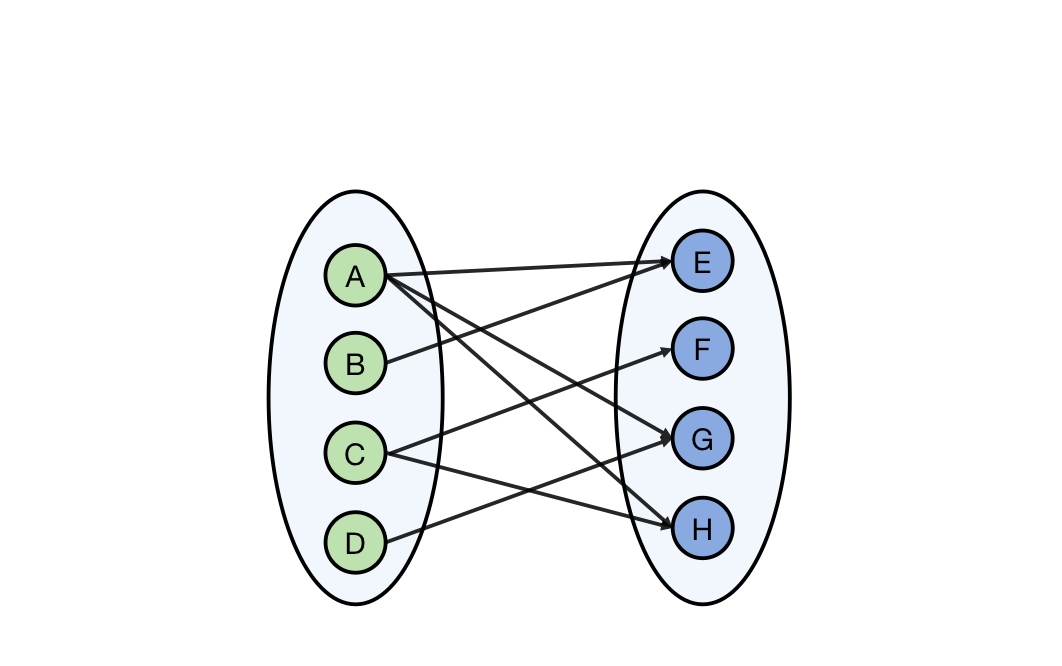
匈牙利算法 (HA算法) 主要用于无权图,匈牙利算法是由Kuhn-Munkras提出的,其命名算法的时候使用了自己国家的名字,不过由于Kuhn-Munkras提出了无权图,以及有权图两种场景的二分图最大匹配算法,因而为了加以区分两种情况,人们会把无权图的最大匹配算法称为 HA 算法,并把有权图的情况称为 KM 算法,本文也将沿用这种称谓。其实不难看出,KM 其实是作者名字的缩写,KM算法是在HA算法基础之上改进得到的。匈牙利算法的运行流程非常简单,我们首先遍历集合 或 任意一个,我们不妨先从左边的、代表男生的集合出发,然后枚举这个男生感兴趣的所有女生。
例如 感兴趣的女生包括了 ,我们规定访枚举的顺序是自上而下的,那么访问女生 ,如果女生 也未匹配,那么我们则令 构成一个配对,然后更新匹配数量。我们可以使用一个数组 记录当前的配对情况的。然后轮男生 ,其感兴趣的女生的只有 ,但是 已经匹配了,于是我们尝试令与 匹配的 更换匹配对象。显然,由于 感兴趣的女生除了 之外仍有 ,那么如果 不选 改选 ,便可君子成人之美的腾出 使得 构成一个匹配。当前拥有的匹配包括 ,然后轮到了男生 ,其感兴趣的女生 未被匹配,因而非常顺利的构成匹配 ,然后轮到了男生 ,很不巧,其喜欢的女生 已与 匹配,因而我们再一次令 更换对象, 除了 之外仍对 感兴趣,因而 最终让给 , 选择 ,那么最终我们得到了四对匹配。
int find(int u){
for (int v: edges[u]){
if(!vist[v]){
vist[v] = 1;
if(!match[v] || find(match[v])){
match[v] = u;
return true;
}
}
}
return false;
}
基于DFS实现的匈牙利算法,其实非常简洁,选择 或 其中一个集合开始的遍历。我们不妨选择 ,进入一个未访问的顶点,如果没有匹配,令其匹配,如果已经匹配,尝试令其已匹配的对象更换对象,腾出空位。需要注意, 数组描述的 当中某个顶点的访问记录。也就是说「每个男生访问女生的记录」,当遍历下一个男生的时候,我们需要清空这些访问记录。
此外一个细节就是,尽管二分图逻辑上是无向图,但是我们存图的时候是按照有向图的方式来存图,如果我们枚举集合 ,那么我们存图的方向就是,如果我们枚举集合 ,那么我们存图的方向就是 ,这样空间开销会少,而且清空访问状态 数组的时候会更容易一些。
int ans = 0;
for (int i = 0; i <= S; i++){
memset(vist, 0, sizeof(vist));
if(find(i)){
ans++;
}
}
然而基于深度优先搜索的实现会有潜在的风险。如果二分图较大,尝试「更换匹配,腾出空位」这个过程的递归深度有可能会非常之深,寻找替代对象的搜索路径会在 、 两个集合之间反复交错。当递归深度较大的时候会有爆栈的风险。因而尝试使用不那么简洁的 BFS 实现匈牙利算法是很有必要的。
其实现的基本思路是一样,我们使用选择的 或 集合,枚举这个其顶点 感兴趣的且未访问的邻接顶点 ,如果这个顶点 未有匹配我们则为其寻找一个可行的匹配,此时分为两种情况:
- 如果 恰好也没有匹配,则令 构成一对匹配
- 如果 已有匹配,但其邻接顶点 没有匹配,此时通过增广路算法为其寻找可行匹配
情况 1 这一步的逻辑与基于深搜的方法基本是一样的,情况 2 这一步的逻辑与深搜方法不大相同。由于情况 1 同样可以使用增广路算法实现,所以为了减少分类讨论,我们不区分情况,都使用增广路算法,以此减少代码量。其中 增广路 这个概念来自于网络流算法,所谓增广路的意思是说,如果一个存在一条路径使得我们能从 走到 ,则称 存在一条增广路。简单来说就是,存不存一条路径,允许我们从某个起点走到某个终点。
提纲要领的来说,如果一个顶点没有匹配,为其寻找增广路,如果已有匹配,我们将其加入「尝试更换对象的等候队列」,至此我们已从全局描述了整个算法的流程。下面是代码的核心框架,接下来我们再深入探究增广路算法。
bool bfs(int x){
memset(vist, 0, sizeof(vist));
memset(prec, 0, sizeof(prec));
queue<int> q;
q.push(x);
while(!q.empty()){
int u = q.front(); q.pop();
for(int v: edges[u]){
if(!vist[v]){
vist[v] = 1;
prec[v] = u;
if(!pt[v]){
aug(v);
return true;
}else{
q.push(pt[v]);
}
}
}
}
return false;
}
由于二分图的性质不难得知,如果 ,那么 增广路的长度一定是一个奇数,简单画图会发现,二分图中寻找增广路的过程中一定是在 两个集合之中交替进行的,如果长度等于偶数,那么 必然属于一个集合,但这一点与 与 交集为空是矛盾的。
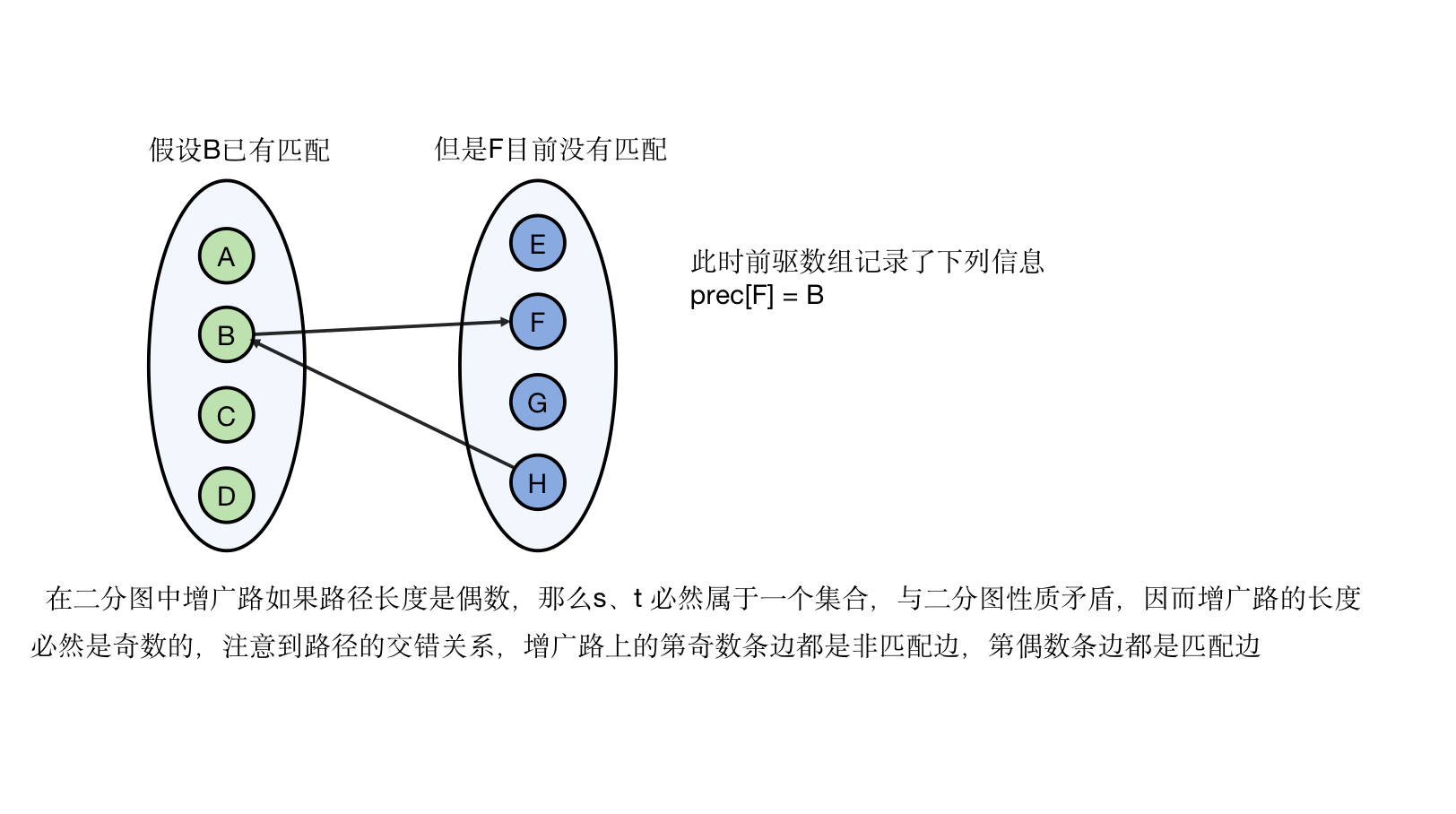
由于情况 1 能被规约于情况 2,我们只分析情况 2,我们使用 记录 两个集合的匹配情况,此时问题转换成,有向图中从给定起点找一条简单路径走到某个未匹配顶点。这个部分代码非常简单,但是不好理解,具体解释详见图例。
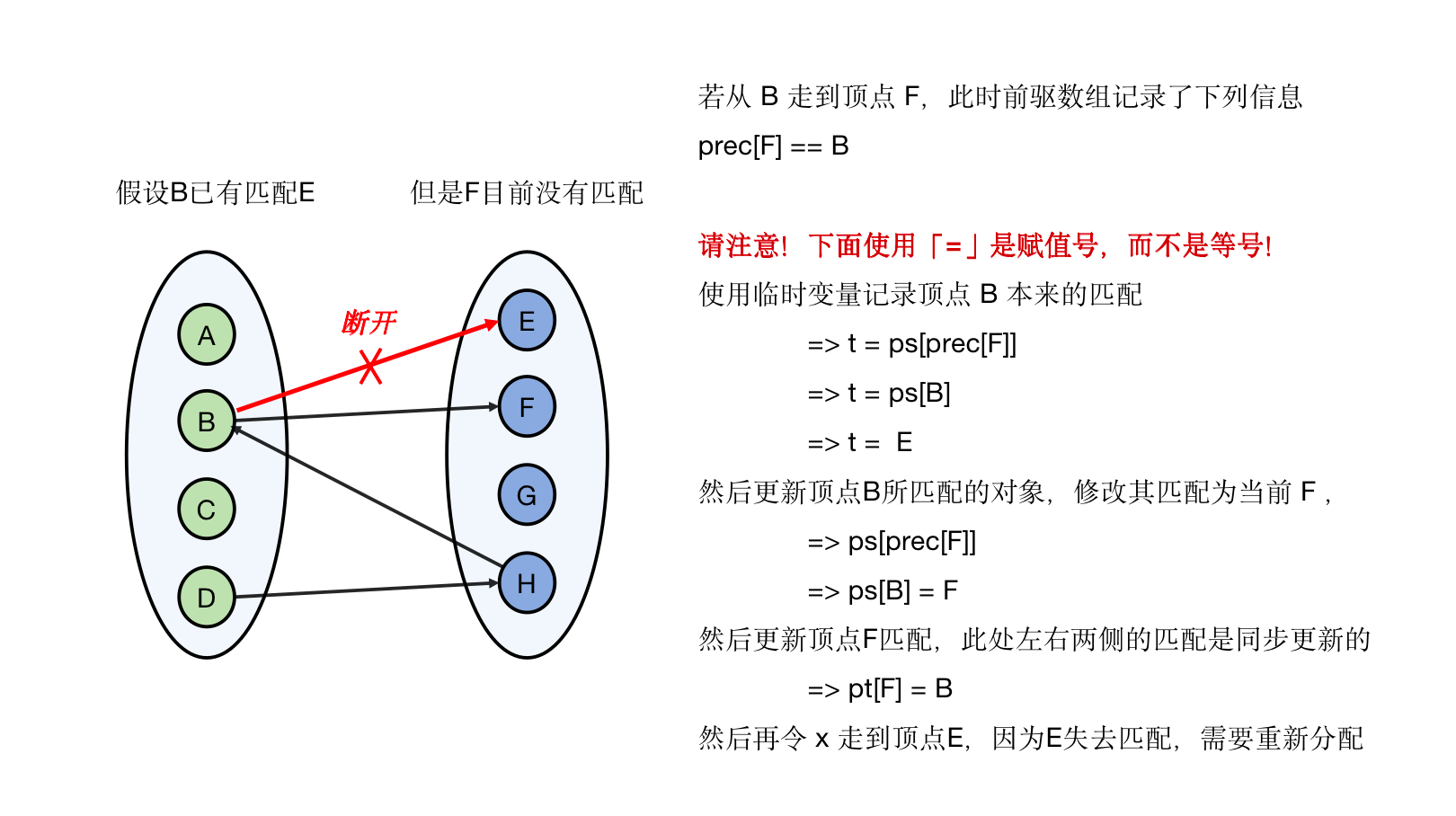
void aug(int x){
while(x){
int t = ps[prec[x]];
ps[prec[x]] = x;
pt[x] = prec[x];
x = t;
}
}
出现了增广路,很自然的我们能将这个问题转为最大流模型。二分图最大匹配可以转换成网络流模型。构建一个超级源点连上左边集合的所有顶点,构建一个超级汇点连上右边所有定名,每条连边容量设为 1,最大流即最大匹配。如果使用 Dinic 算法 求该网络的最大流,可在 时间之内求出最大匹配,比起匈牙利算法的 快得多。
(3.2) KM算法
然而二分图的匹配通常是不唯一的,不同人使用匈牙利算法求得的最大匹配是不一样的,而且现实中,即使一个男生对多个女生感兴趣,但其对于每个女生的感兴趣程度也是不一样的,因而无权图的最大匹配往往无法满足我们的需要,因而带权图的最大匹配算法,KM 算法才是最常使用的,不过这个算法的复杂度达到了 级别。
先说 KM 算法的一般思路,我们先考虑左部顶点个数与右部顶点个数相同的简单情况。通常解决未知问题的一般思路是将其转为一个已知的问题。对于带权图,一个贪心的想法是只保留最大权重的连边生成一个子图,然后再在这个子图上面不考虑权重的去跑匈牙利算法即可。
然而根据这种贪心策略得到的匹配未必是最大的。我们继续沿用上面男生女生找对象的例子,权重也就是幸福感,作为月老我们只满足了一部分人的需求,但是整体的幸福感并没有达到最大。我们不妨说的残酷一点,正如现实中我们看到的一样,很多人没有自知之明,总是拿着极高的择偶标准,如果达不到标准宁可一直单着,可是这些人并不知道自己在婚恋市场中并没有选择权,这些人只有降低标准才能找到对象。言归正传,为了更好的说明问题,接下来我们需要引入两个新概念,以及些许数学证明。
两条新概念:
- 可行顶标,可行顶标是一个可行的顶标分配方案,是针对于一组顶点而非单个顶点
- 相等子图,在一组可行顶标之下原图的生成子图,包含所有顶点但只包含满足 约束的连边
所谓生成子图其实就是原图抠掉一些顶点或连边之后生成的一个子图。现在,我们给每个顶点分配一个数值 ,如果对于所有连边满足 ,那么我们分配的顶标是一个可行方案,称为可行顶标。对于某一组可行顶标,如果其相等子图存在完美匹配,那么这个匹配就是原二分图的最大权完美匹配。所谓完全匹配是说每个顶点都可以找到对应的配对顶点,也就是说,无人单身。
原二分图的任意一组完美匹配 ,其边权之和记作 ,则有:
任意一组的可行顶标的相等子图任意一组完美匹配 ,其边权之和记作 ,则有:
观察上面两条式子,我们不难发现,
也就是说,原二分图任意一组完美匹配的边权和 能够达到的最大值是其相等子图的完美匹配边权和 ,现在问题变成了「如何算出相等子图的完美匹配」,我们需要找出某组可行顶标,使得相等子图是完美匹配。完美不妨使用 两个数组分别存储左右集合 当中的可行顶标。我们首先初始化一组可行顶标,例如:
意思是说,把左边集合每个顶点的顶标初始化为所有邻边中权重的最大值,右边集合所有顶点的顶标统统初始化为零。
然后我们遍历 ,选择一个未匹配顶点 ,去找 增广路径,如果能够找到增广路径则更新 两个顶点的匹配记录 ,否则,当找不到增广路径的时候,我们会得到一个交错路径。
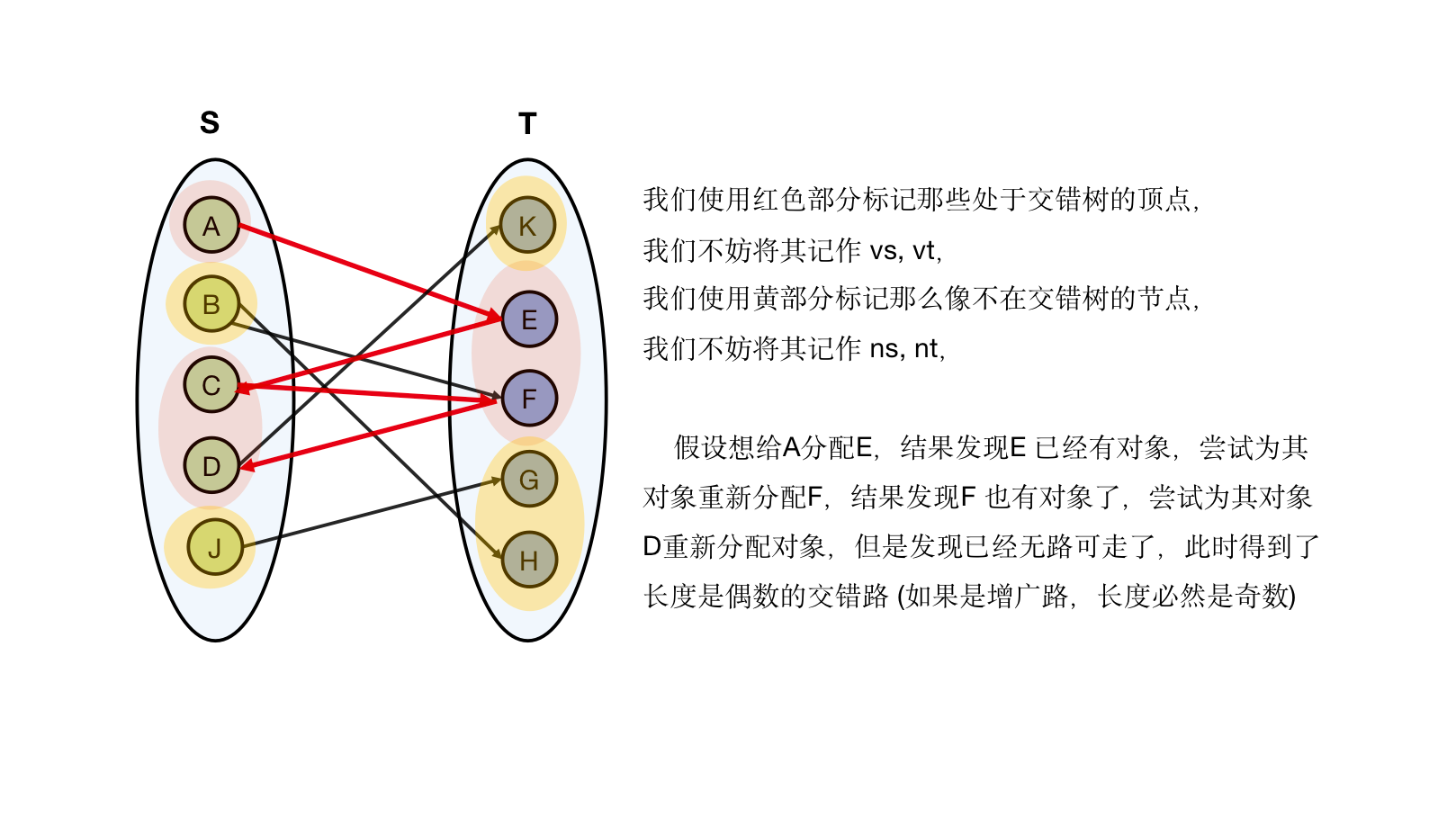
使用红色标记那些在交错路径之中的顶点,黄色标记那些不在标错路径的顶点,那么我们会有以下结论:
- 不存在 且 使得
- 不存在 且 使得 是一条匹配边
也就是说,对于相等子图,左边的红色集合到右边的黄色集合不存在连边,否则交错路径会继续生长,而且左边的黄色集合到右边的红色集合的连边,肯定不是匹配边,否则这条边属于红色部分 而非黄色部分 ,我们不妨把上面图模型整理抽象一番,得到下列图例,
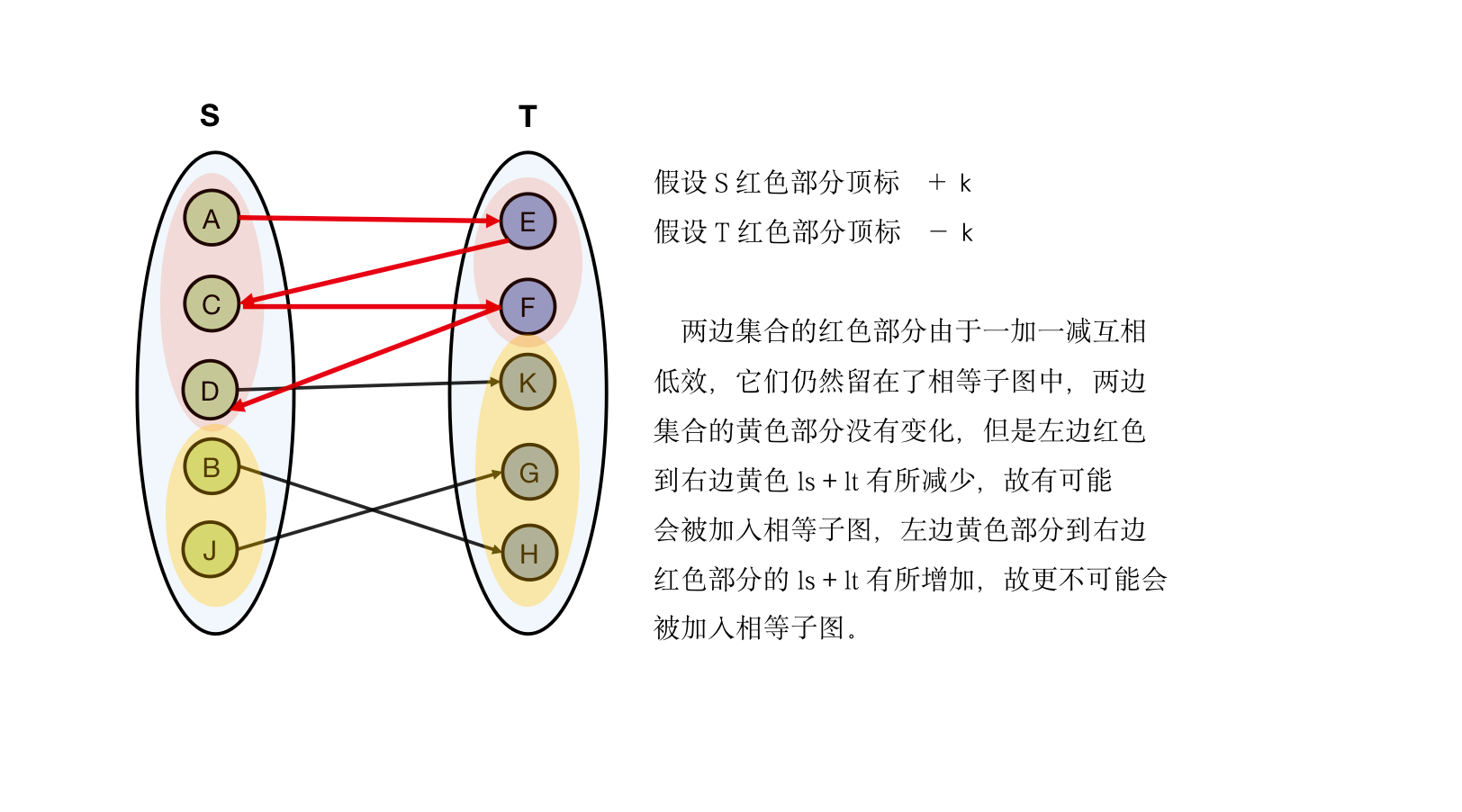
交错路径上面的顶点其实就是想换对象的男生 (因为我们枚举 ,如果你枚举 则为女生),然而他们(红色区域标记的部分)要求太高了,这些人找不到可以替换的对象,因而他们降低了自己的择偶标准(降低顶标,从这个角度来说,「顶标」一词听起来倒是挺像顶配标准的缩写哈哈),那么降低标准之后,左边红色的区域的顶点与右边黄色区域的顶点二者的顶标之和 有所下降,下降之后有可能满足 ,使其被加入相当子图之中。为使权重尽可能高的连边能被加入相同子图。我们希望每次的降低标准的变化量 尽可能小,因而我们取下列式子作为 更新量,
当一条新边 ,其中 位于左侧红色部分,位于右侧黄色部分,当其加入相等子图会有两种情况,
- 是一个未匹配的顶点,意味着我们找到了一条增广路
- 是一个已匹配的顶点,其匹配对象维护左侧集合的黄色部分(黄配黄)
那么至多 轮次的修改之后,即可找到增广路,每次修改顶标,由于两侧红色部分一侧增加一侧减少,二者顶标总和不变,故其交错路径的连边都不离开相等子图(两侧红色部分当中已有的匹配保持不变),我们直接维护交错路径上面的、位于右侧集合的顶点,分析每个顶点需要降低的标准是多少,
然后再扫描每个不在交错路径的 取最小值即可得到最小的标准降低量 ,
当交错路径新增一个顶点进入左侧集合 红色部分,要以 复杂度更新,然后计算 修改顶标的时候又以 复杂度更新左右交错路径之中每个 ,随着左侧红色部分顶点的「择偶标准」逐渐降低,交错路径总是可以找到一个未匹配点,也即找到一个增广路。我们要以 枚举左侧或右侧顶点,对其所有顶点进行上述操作。因而最终算法复杂度 级别。 回归最开始的问题,我们最初假设左右两个集合顶点个数是相等的,也就是每个人只要不停降低标准总有办法找到与之匹配的对象,然而大多时间左右集合的顶点个数是不相等的,此时我们需要对其补点,虚设顶点使得二者顶点数量相当于,对于虚设的顶点,我们只要假定它们与其它顶点的连边权重为零即可。
void bfs(int x){
fill(slack + 1, slack + n2 + 1, 0x3f3f3f3f);
memset(prec, 0, sizeof(prec));
memset(vs, 0, sizeof(vs));
memset(vt, 0, sizeof(vt));
queue<int> q;
q.push(x);
while(1){
while(q.size()){
// 取出候选队列(可能是要寻找对象,或者是要更换对象的顶点)然后将其纳入交错路径之中
int u = q.front(); q.pop();
vs[u] = 1;
for (int v = 1; v <= n2; v++){
if(!vt[v]){ // 枚举右部不在交错树中的顶点(黄色部分)
if(ls[u] + lt[v] - e[u][v] < slack[v]){ // 寻找降低标准的最低限度
slack[v] = ls[u] + lt[v] - e[u][v];
prec[v] = u;
} // 同时更新前驱顶点
if(!slack[v]){ // 如果需要降低标准限度为零说明恰好找到了能够加入相等子图的连边
vt[v] = 1; // 先将这个顶点加入交错路径之中(放入右侧红色部分)
if(!pt[v]){ // 如果这个顶点尚未匹配,为其寻找一个可行的匹配方案(寻找一条增广路径)
aug(v);
return;
} else {
q.push(pt[v]); // 否则将其已匹配的对象放入等待更换对象的候选队列
}
}
}
}
}
// 增广失败的时候扩大子图(大家的标准都太高了,实在找不到任何合适的对象,也即找不到增广路径)
int delta = 2e9;
for (int v = 1; v <= n2; v++) {
if(!vt[v]){ // 扫描slack, 根据右侧集合黄色部分顶点需要降低最低限度再挑一个最小的
delta = min(delta, slack[v]); // 矮子里面再挑矮个子
}
}
if(delta == 2e9) break;
for (int i = 1; i <= n1; i++) if(vs[i]) ls[i] -= delta;
for (int i = 1; i <= n2; i++) if(vt[i]) lt[i] += delta; else slack[i] -= delta;
// 然后再看降低标准之后,右侧集合不在交错路径中的那些顶点是否有符合标准的顶点
for (int v = 1; v <= n2; v++) {
if (!vt[v] && !slack[v]){
vt[v] = 1;
if(!pt[v]){ // 若是找到符合等式约束且未匹配的,为其找增广路
aug(v);
return;
}else{
q.push(pt[v]); // 否则进队,这个部分逻辑与上面是一样的
}
}
}
}
}
最终通过我们一直维护的交错路径,我们不难得知带权的最大匹配权值和即为下列 ,
for (int i = 1; i <= n1; i++) ans += ls[i];
for (int j = 1; j <= n2; j++) ans += lt[j];
printf("%lld\n", ans);
虽然带权图的最大二分图匹配通常会被转为最大费用最大流问题,但是很少会这么做,因为KM算法的复杂度已经足够优秀了。
支持作者



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」