linux--shell
1. 正则
正则表达式基本元素包括:普通字符、元字符(如*、^、[]等)
shell命令如grep、sed、awk使用正则表达式
1.1 基本的正则表达式
元字符:
(1)*
0个或多个在*字符之前的一个普通字符
例子:
hel*o 表示匹配前面的'l'字符0次或多次
(2).
匹配任意一个字符
(3)^
匹配行首,或其后字符的非
例子:
^ab 表示以ab开头的
^[0-9] 表示以任意一个数字开头的
[^0-9] 表示不再范围内的所有字符
(4)$
匹配行尾
例子:
^$ 表示空行
^.$ 表示只含一个任意字符的行
^a[a-z]*c$ 表示以a开头,以c结尾,中间是任意个小写字母字符的字符串
(5)[ ]
匹配字符集合
例子:数字集合、字母集合
[0123456789]、[0-9] 表示0~9中任意一个数字字符
[a-z] 表示小写a到z之间任意一个字符
(6) \
转义符,屏蔽一个元字符的特殊意义
(7) \<\>
精确匹配符号
例子:
\<abc\> 只匹配abc这个单词,不匹配包含abc字符的其它串,如不匹配 mabcn
类似单词边界: \babc\b 也是只匹配abc这个单词
(8) \{n\}
匹配前面一个字符出现n次
(9)\{n,\}
匹配前面字符至少出现n次
(10)\{n,m\}
匹配前面字符出现n~m次
1.2 扩展的元字符
(1)?
匹配0个或1个在其之前的一个普通字符
例子:
a?b 匹配ab、aab
(2)+
匹配1个或多个在其之前的一个普通字符
(3) ()和 |
表示一个字符集合或用在expr中,结合使用表示一组可选的字符
| 可表示多个正则表达式的或关系
例子:
re(a|e|o)d 匹配read、reed、reod
等同 re[aeo]d
1.3 通配
shell使用正则表达式中的一些元字符实现通配功能
(1)*
任意个的任意字符
例子:
*.cpp 表示以任意字符开头,结尾是 .cpp的文件
(2)?
表示一个任意字符
例子:
a?.cpp 表示以a开头,后面跟一个任意字符,结尾是 .cpp 的文件
(3)^
表示取反
(4)[]
表示范围内的一个字符
例子:
[a-z]*.cpp 表示以a到z开头,后面是任意字符,结尾是 .cpp的文件
(5){}
表示一组表达式的集合 或的关系
例子:
{*.cpp , *.py} 表示所有的cpp文件或py文件
1.4 grep命令
全面搜索正则表达式,并打印(文本搜索工具)
grep [选项] [模式] [文件...]
选项:
-c :只输出匹配字符串的数量
-i:搜索时忽略大小写
-h:查询多文件时不显示文件名
-l:只列出符合匹配的文件名,不列出具体的匹配行
-n;列出所有的匹配行,并显示行号
-s:不显示不存在或无匹配文本的错误信息
-v:显示不包含匹配文本的所有行
-w:匹配整个单词
-x:匹配正行
-r:递归搜索(搜索当前目录和子目录)
-q:禁止输出任何结果,以退出状态表示搜索是否成功(0:搜索成功; 1:未搜索到满足模式的文本行; 2:命令或程序出错)
打印状态: echo $?
-b:打印匹配行 距文件头部的偏移量,单位 字节
-o:与-b结合使用,打印匹配的词距文件头部的偏移量,单位字节
-E:支持扩展的正则表达式
-F:不支持正则表达式,按字符串的字面意思进行匹配
模式:用双引号或单引号括起来,表示要搜索的字符串或用正则表达式
搜索正则的元字符如搜索 *、. 要转义
- 也要转义
例子:
(1)在当前目录下的所有.c和.h文件里面搜索以'#'开头的行,并显示行号
grep -n '^#' *.c *.h
(2)在当前目录的*.c文件里搜索以5个 - 符号开头的文本行 (- 符号也要转义)
grep -n '^\-\{5\}' *.c
POSIX增加的字符类:
[:upper:] 表示[A-Z]
[:lower:] 表示[a-z]
[:digit:] 表示[0-9]
[:alnum:] 表示[0-9a-zA-Z]
[:space:] 表示空格或Tab
[:alpha:] 表示[a-zA-Z]
[:cntrl:] 表示ctrl键
[:graph:]或[:print:] 表示ASCII码33~126之间的字符
[:xdigit:] 表示16进制数字[0-9A-Fa-f]
2. sed命令
2.1 sed命令使用
(1)sed是一个非交互式文本编辑器,可对文本文件、标准输入进行编辑(标准输入可以是来自键盘输入、文件重定向、字符串、变量、管道的文本)。
从其中读取数据复制到缓冲区,然后读取命令行或脚本的第一个命令,对此命令要求的行号进行编辑并重复执行,直到命令行或脚本中所有命令执行完毕
使用场景:①编辑相对交互式文本编辑器而言很大的文件
②编辑命令太复杂,在交互式文本编辑器中难以输入
③对文件扫描一遍,但是需要执行多个编辑函数
效果:sed是对缓存区中复制来的文件副本进行操作,不影响原文件,要保存修改的内容,需要将输出重定向到另一个文件
sed 'sed命令' file1 > file2 将file1中文件执行sed命令,并保存到file2
(2)
①在shell中输入命令调用sed
sed [选项] 'sed命令' 操作文件
②在脚本中写sed命令,通过sed命令调用
sed [选项] -f sed脚本文件 操作文件
③脚本中写sed命令,直接执行该脚本文件
./sed 脚本文件 操作文件
操作文件如果没有指定,则默认是标准输入
选项:
-n:不打印所有的行到标准输出
-e:将下一个字符串解析为sed编辑命令,如果只传递一个编辑命令给sed则-e可省略(每一个编辑命令前都要加-e)
-f:正在调用sed脚本文件
(3)定位文本、编辑命令
定位文本:指定行号或通过正则匹配
x:第x行
x,y:从x到y行
/pattern/:查询包含模式的行
/pattern/pattern/:查询包含两个模式的行
/pattern/,x:从与模式匹配的行到x行之间的行
x,/pattern/:从x行到匹配行之间的行
x,y!:查询不包括x和y行的行
编辑命令:即具体做什么操作(前面没有-)
p:打印匹配行
=:打印文件行号
a\:在定位行号之后追加文本信息
i\:在定位行号之前插入文本信息
d:删除定位行
c\:用新文本替换定位文本行,是替换整个行
s:使用替换模式替换相应模式,替换字符串,而不是整个行
r:从另一个文件中读文本
w:将文本写入到另一个文件,后面要跟新文件名
y:变换字符
q:第一个模式匹配完成后退出
l:显示与八进制ASCII码等价的控制字符
{}:在定位行执行的命令组
n:读取下一个输入行,用下一个命令处理新的行
h:将模式缓冲区的文本复制到保持缓冲区
H:将模式缓冲区的文本追加到保持缓冲区
x:互换模式缓冲区和保持缓冲区的内容
g:将保持缓冲区的内容复制到模式缓冲区
G:将保持缓冲区的内容追加到模式缓冲区
2.2 sed命令使用例子
(1)打印某文件的第一行到标准输出
只打印第一行,则编辑命令为 '1p' ,不打印其他行,要加上sed命令的选项 -n
sed -n '1p' a.sb
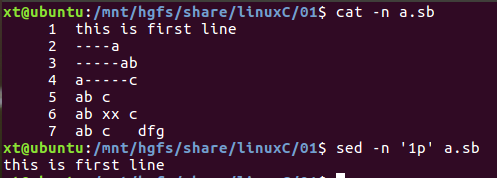
如果不加-n选项呢,则先打印第一行,再打印整个文件内容
(2)多个编辑命令
匹配以a开头,中间是其他小写字母或空格,以c结尾的行,先打印行号,再打印行的内容(第5行、6行)
sed -n -e '/^a[a-z ]*c$/=' -e '/^a[a-z ]*c$/p' a.sb

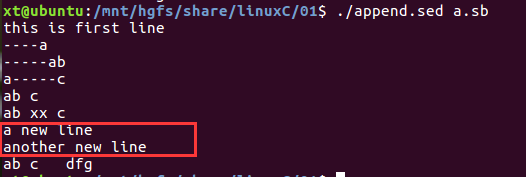
(3)用脚本形式
在行6后面追加一些内容
#!/bin/sed -f 6a\ a new line \ #在行6下一行添加此行内容 \ 换行 another new line #又添加一行
执行脚本:添加可执行权限,再对该文件执行此脚本
chmod u+x append.sed ./append.sed a.sb
(4)匹配元字符
如果要查找 * . $ - 等字符,要转义 \*
如:查找打印含 - 字符的行
sed -n '/\-/p' a.sb

(5)通过元字符/正则匹配
$ 字符在正则中表示行结尾,在sed命令中表示 最后一行
如:打印最后一行
sed -n '$p' a.sb #打印最后一行 sed -n '$'p a.sb #打印最后一行

打印行5到结尾行:
sed -n '5,$p' a.sb

(6)整行替换与字符串替换
c\新文本 和 s/匹配串/新串/[替换选项]
原内容:
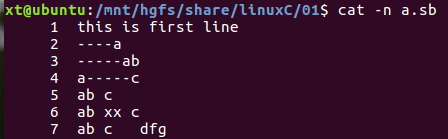
对ab进行两种替换:
sed '/ab/c\hahahaha' a.sb #含 ab的行被替换为hahahaha
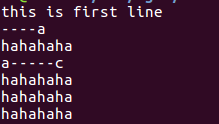
sed 's/ab/hahahaha/' a.sb #将ab字符串替换为hahahaha
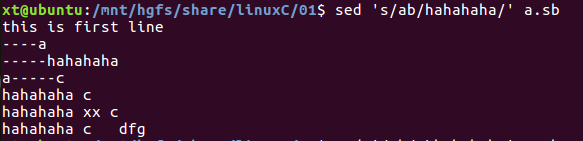
串s替换的选项:s/被替换串/新串/[替换选项] 前面没有-
g:替换文本行中所有出现被替换字符串的地方,而不是该行首先出现匹配的地方
p:与-n选项结合,只打印替换行
w 文件名:将输出定向到一个文件
替换时特殊字符:& 表示被替换字符串
例,要给串123前后假设*号 s/123/*&*/g
(7)变换字符
sed 'y/被变换的字符序列/变换后的字符序列/' 输入文件
将被变换字符序列中字符逐个用变换字符序列中字符替代
例:将某文件中a变成A,b变成B,c变成C
sed 'y/abc/ABC/' a.sb
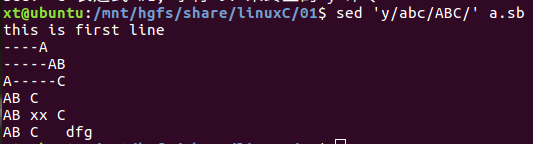
(8)其他用法
①处理匹配行的下一行
②sed缓冲区处理
3. awk编程
3.1 awk编程模型
awk程序由一个主输入循环维持(此循环由awk框架实现),主输入循环自动一次读取输入文件行以供处理,我们再添加处理文件行的动作(即不需要我们写main、不需要打开文件、读取文件、关闭文件,只需要写处理文件行的内容就行了)
特殊字段:
BEGIN:在主输入循环之前执行
END:在主输入循环之后执行
3.2 awk调用
①shell
awk [-F 域分隔符] 'awk程序段' 输入文件
②awk调用脚本文件
awk -f awk脚本文件 输入文件
③直接执行可执行文件
./awk脚本文件 输入文件
3.3
awk语句由模式和动作组成。模式是一组用于测试输入行是否需要执行动作的规则,动作是包含语句、函数、表达式的执行过程
awk支持?、+两个扩展元字符
awk视输入文件是格式化的文件
(1)awk记录和域
awk将每个输入文件的行定义为记录,行中每个字符串定义为域(域之间用空格、tab、其他符号间隔)
用 $ 指定执行动作的域,每条记录域从 $1 开始(而$0表示所有的域,即整行)
①域操作符 $ 后可以跟数字、也可是是变量、变量表达式
awk 'BEGIN{a=1;b=2} {print $(a+b)}' a.sb //即print $3
②改变域间隔符
空格是默认间隔,tab视作连续空格
awk -F"," 'print $2' a.sb #一种是通过-F选项修改
awk 'BEGIN {FS=","} {print $1,$2}' a.sb #通过环境变量FS指定域分隔符
awk -v FS="," 'print $2' a.sb
FS可通过正则表达式设置域分隔符
(2)关系和布尔运算符
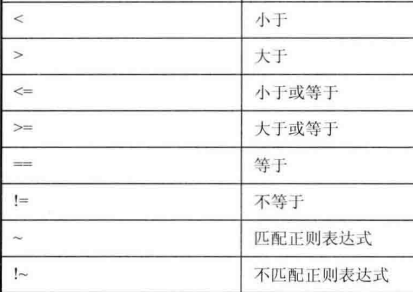
布尔:
逻辑或: ||
逻辑与:&&
逻辑非:!
(3)条件和循环语句
条件里面可以写正则,语句和C类似
if if/else if/else else
while(条件表达式) {动作}
do {动作} while(条件)
for(设置计数器初值;测试计数器;计数器变化) {动作}
(4)表达式
表达式由数值、字符常量、变量、操作符、函数、正则表达式组合而成
变量:字符串值、数值类型
算术运算符:
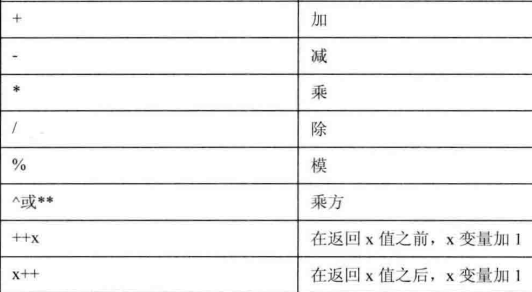
(5)系统变量
一种用于改变awk的默认值,如FS修改域分隔符;一种用于定义系统值,处理文本时可读取,如域数量、记录数、文件名,是动态的。
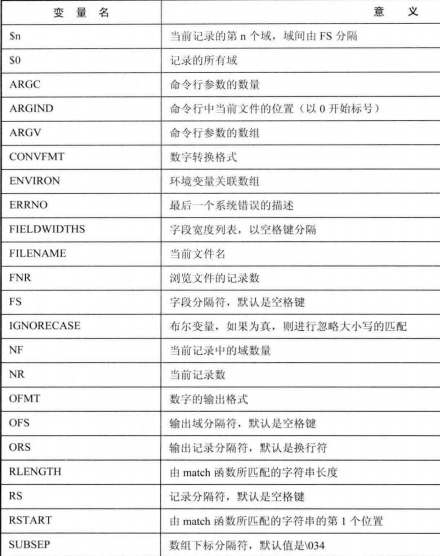
RS:记录分隔符,如果设为空,则将空白行作为记录分隔符
(6)格式化输出
printf (格式控制符,参数)
格式控制符:修饰符、格式符


(7)内置字符串函数

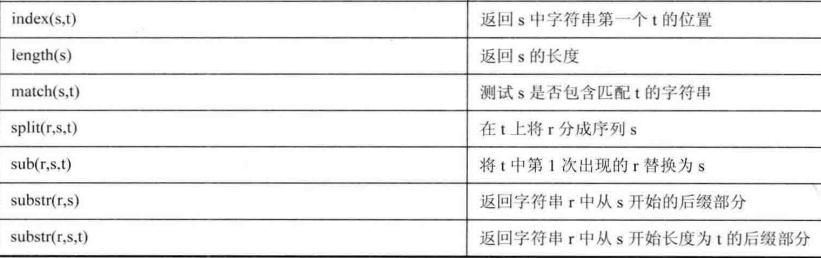
如替换gsub,不带第三个参数时,作用于整个行(行中所有域);第三个参数指定作用的域
(8)向awk脚本传递参数
./awk NUM=3 FS="," a.sb # = 号两边不能有空格
(9)数组
格式类似C,但awk数组不需要定义数组类型和大小,可直接赋值后使用
数组是关联数组
数组的索引可以是数字,但该数值与数组存储地址无关
访问数组:for (variable in array) {对array[variable]的动作}
in的用法:判断array[index]是否在数组中(返回1或0) index in array
两个数组形式的系统变量:
ARGV:命令行参数 个数是ARGC,参数从ARGV[0]到ARGV[ARGC-1]
ENVIRON:环境变量
两个打印命令行参数和系统变量的示例脚本:
脚本1:
#!/usr/bin/awk -f BEGIN { for (x=0;x<ARGC;x++) print "arg" x ":" ARGV[x] }
执行: 并传入数个参数

脚本2:
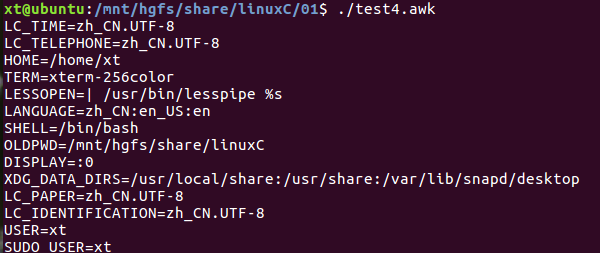
#!/usr/bin/awk -f BEGIN { for (i in ENVIRON) print i "=" ENVIRON[i] }
执行效果:
3.4 例子

(1)判断空行
awk '/^$/{print "a blank line"}' a.sb
输入文件有一个空行,就打印一行字符串

(2)查看 /etc/passwd文件中注册名为root的用户信息
awk 'BEGIN {FS=":"} $1~/root/' /etc/passwd
$1后面, ~ 匹配正则

(3)if条件判断
如果域2大于等于56,就打印正行
awk '{if($2>=56) print $0}' a.sb

(4)判断某文件有多少空行
在遍历行时,如果匹配到空行,变量加1,在所有行结束后(END),打印此变量的值
awk '/^$/{n++} END{print n}' a.sb

注意: /^$/{n++;} 条件和执行语句之间不能是换行,见(7)
(4)计算此文件第三列数字的平均值
注意本文件有一个空行,因此是第三列数字相加除以3;也要注意如果为空文件或全是空行的情况,打印 empty
awk '!/^$/{total += $3;n++} END{if(n>0) print total/n;else {prin"empty"}}' a.sb

awk '!/^$/{total += $3;n++} END{if(n>0) print total/n;else {prin"empty"}}' b.sb

(5)计算第三列数字的平均值
如果有一些行数据不合法,比如不是空行但没有第三个域,或者第三个域不是数字,则要加上条件:
写法1:在表达式里面加if条件
awk '!/^$/{if(!(NF<3) && ($3~/[0-9]+$/)){total += $3;n++}} END{if(n>0) print total/n;else {print "empty"}}' a.sb
注意,if后面要执行的语句要用{}括起来
写法2:在遍历行时就判断,在内部表达式内只要toal和n的操作,这样更清晰
awk '(!/^$/)&&(NF>=3 && $3~/[0-9]+$/){total += $3;n++} END{if(n>0) print total/n;else {print "empty"}}' a.sb

(6)向awk脚本传递参数
test.awk脚本文件内容:打印域的数量不是传入参数个数的行
#!/usr/bin/awk -f NF !=NUM {print $0}
执行:
./test.awk NUM=3 FS=" " a.sb

(7)一个注意的地方【计算空行数量】
文件改为有两个空行,如下图:
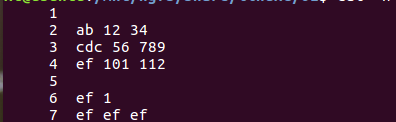
脚本1:
#!/usr/bin/awk -f /^$/ { n++; } END { print n; }
执行效果:

脚本2:
#!/usr/bin/awk -f /^$/{ n++; } END { print n; }
执行效果:

awk是每调入文件的一行,就对其执行一遍脚本文件,而脚本文件估计是以换行符和{} 区分语句块。对于脚本1, /^$/ 表示打印空行,而后面的 n++ 则对每一行都调用一次,因此结果为7;
--------
grep:用于搜索
sed:用于修改、编辑文本文件中某些行,也可用于搜索
awk:访问文本文件,操作某些数据,用于搜索和统计计算
---------
4. 文件操作的一些命令
4.1 sort
类似awk,sort将文本看作多条记录,每条记录有多个域
sort [选项] [输入文件]

关于-t、-k:
sort命令排序时,先按域1比较排序,如果域1相同则比较域2,域之间默认是空格,如果记录域之间不是空格,则要用-t指定域分隔符,便于区分域
默认先比较域1,可通过-k3这样指定首先比较的域
需要比较数值时,通过-k指定域,再加上n选项即可。 -k3n
(2)sort与awk联合使用
例子:有一个有三条记录的文本,需要排序
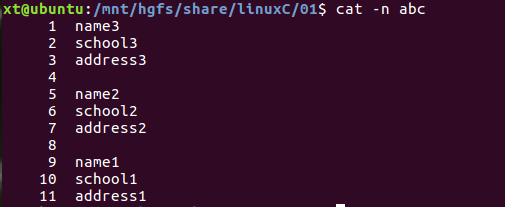
三条记录,首先需要将各个记录合并到一行------指定记录分隔符RS="" ,然后将域分隔符的"\n"替换为一个指定的字符,如空格或其它字符(比如name中间有空格,则不能指定空格为域分隔符了)
awk -v RS="" '{gsub("\n","*");print}' abc

记录之间以换行为分隔,则可以交给sort去排序了(管道传过去即可)
排序完成后,输出还要是原来的格式,则指定输出记录分隔符ORS="\n\n",再将各记录中的"*"符号换为换行符即可
awk -v ORS="\n\n" '{gsub("*","\n");print}'
完整的:
cat abc | awk -v RS="" '{gsub("\n","*");print}' | sort | awk -v ORS="\n\n" '{gsub("\*","\n");print}' #gsub第一个参数可为正则因此*要转义
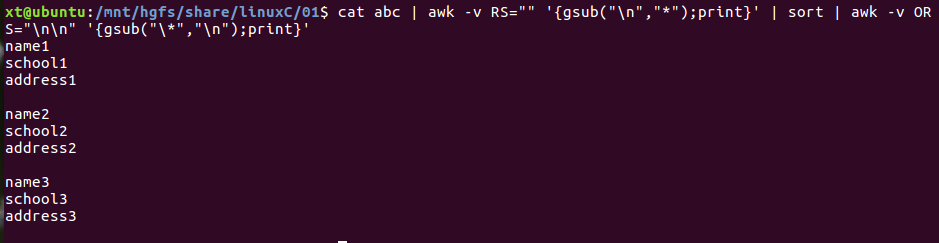
4.2 uniq
去除连续重复的行,保留一个(sort -u是去除所有重复的行,不管是否连续,只保留一个)

(2)统计单词出现次数
一个单词文本,单词之间以空格、换行、tab、逗号、冒号、点分隔,统计单词出现次数
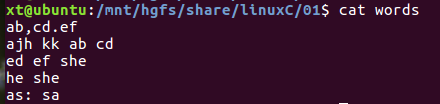
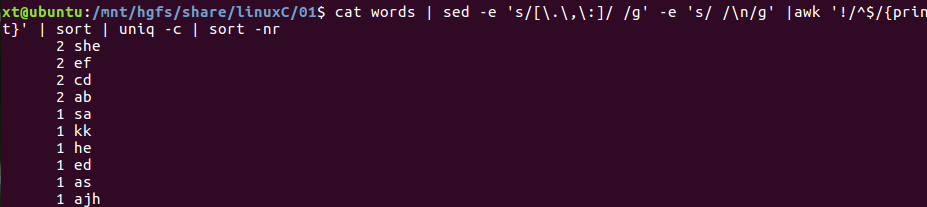
实现:sed读入,并用空格替换分隔符,再用换行替换空格,然后去掉空行,交给sort排序后给uniq -c 统计
cat words | sed -e 's/[\.\,\:]/ /g' -e 's/ /\n/g' | sed -e '/^$/d' | sort | uniq- c | sort -nr
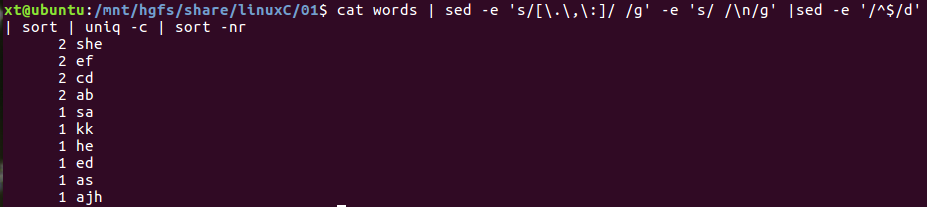
去掉空行也可以用awk:
cat words | sed -e 's/[\.\,\:]/ /g' -e 's/ /\n/g' | awk '!/^$/{print}' | sort | uniq- c | sort -nr
4.3 join
join [选项] file1 file2
将两文件中有相同域的记录选择出来,再将这个记录所有域放到一行
两个文件需要按比较域排好序才能进行连接
选项:
-t:后面跟域分隔符
-i:比较域内容时,忽略大小写差异
-o:设置结果显示的格式
-a1或-a2:除了显示用共同域连接的结果外,还显示文件1或文件2没有共同域的内容
-v1或-v2:显示文件1或文件2中没有共同域的内容
-1和-2:-1用来设置文件1用于连接的域 -2设置文件2用来连接的域(默认是比较两个文件第一域)
(2)两个文件
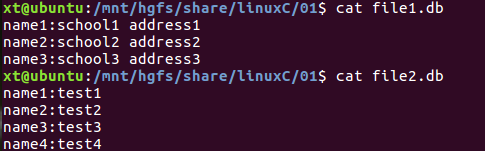
比较域1进行连接:join -t: file1.db file2.db

设置输出格式:文件1的域1 文件2的域2 文件1的域2

4.4 cut
从标准输入或文本文件中按域或行提取文本
格式:cut [选项] 文件

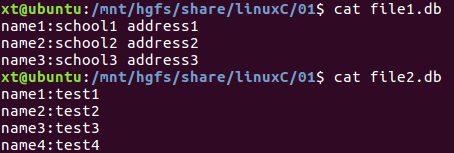
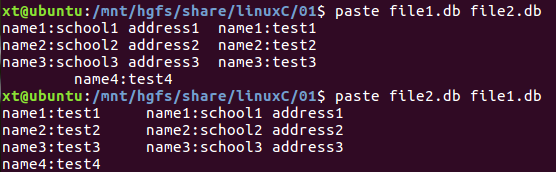
4.5 paste
将文本文件或标准输出中内容粘贴到新文件(将来自不同文件的数据粘贴到一起,形成新的文件)
格式:paste [选项] file1 file2
将file2每个记录粘贴到file1后面

4.6 split
将大文件分割成小文件(按文件行数、字节数切割文件) ,并能在输出的多个小文件中自动加上编号
格式:split [选项] 待切割的大文件 输出的小文件

例子:将有三行数据的file1分割成2份

split -2 file1.db file3 #生成两个文件 file3aa file3ab

4.7 tr
字符转换(sed也有字符替换和字符串替换)
格式: tr [选项] 字符串1 字符串2 < 输入文件
tr需要将输入文件重定向到标准输入(tr只能从标准输入、管道读取数据)

(2)例子
4.8 tar
归档命令,即文件的压缩、解压缩
tar [选项] 文件名或目录名
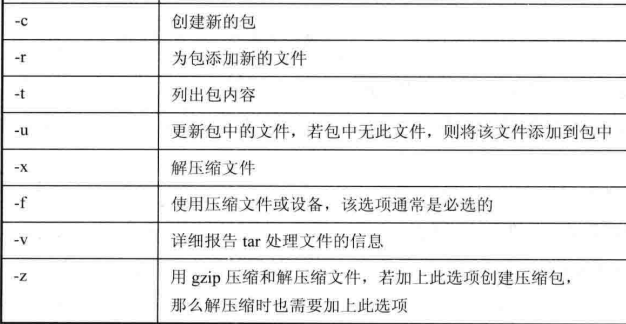
生成归档文件后,再用gzip命令压缩
5. 关于变量和引用
5.1 变量
本地变量:用户当前shell生命期的脚本中使用的变量(类似局部变量)
环境变量:作用于由登录进程产生的子进程
位置参数:用于向shell脚本传递参数,只读
(1)赋值

赋值:
variable1 = 1 ${variable1 = 1}
取值:
echo ${variable1}
清除变量的值:
unset variable1
设置只读:
variable1 = 2 readonly vatiable1
(2)变量"类型"
只包含数字的认为是数值型,其它全是字符串
数值类型默认初值是0,字符型默认初值为空
(3)环境变量操作
定义、清除:
VARIA1=value
export VARIA1
unset VARIA1
(4)重要的环境变量
①PWD:当前目录路径 OLDPWD:旧的工作目录
②PATH:命令的位置
(5)位置参数
$0:脚本名字

5.2 引用
屏蔽特殊字符的特殊意义,展现其字面值

6. 结构
7. I/O重定向
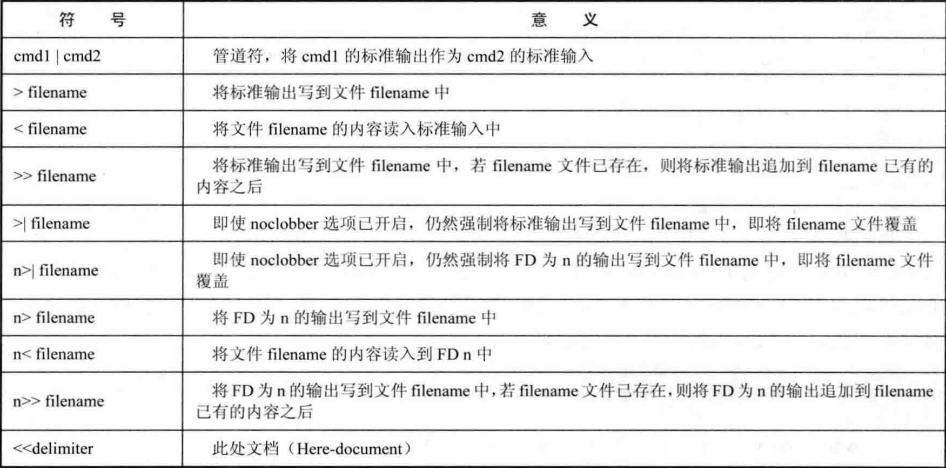
7.1 管道
管道是FIFO的,可用于进程和命令之间、进程之间、命令之间通信
形式:命令1 | 命令2 | 命令3
命令2的输出数据传给2,命令2处理后传给3,3后面没有管道,则输出到shell上
7.2 I/O重定向
捕捉一个文件、命令、程序、脚本、代码块的输出,将这个输出作为输入发送给另一个文件、命令、程序或脚本
进程默认打开三个文件:标准输入、标准输出、标准错误输出,与文件描述符0、1、2标识。
默认情况下,标准输入与键盘输入关联、标准输出和标准错误输出与显示器关联,I/O重定向可使这三个文件与其它内容关联
(1)重定向标识符及其用法
基本I/O重定向符号:
①>| 是将标准输出强制覆盖到某文件中
默认情况下是可以覆盖的,如果设置shell的noclobber选项则不允许覆盖文件。用 >| 时,即使设置了不允许覆盖,也可以强制覆盖文件
set -o noclobber
ls -l /etc | grep vi > abc
ls -l /etc | grep vi > abc

强制覆盖:

②指定分隔符 << CLOUD
将此分解符CLOUD之后直到下一个CLOUD之前的内容作为输入的内容
例:cat命令的标准输出重定向到一个文件abc,标准输入还是键盘输入,以CLOUD作为输入结束符(作用相当于Ctrl+D)
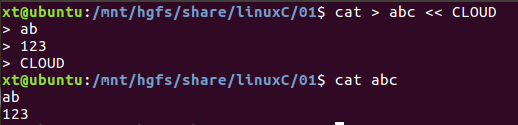
-<<CLOUD 输入文本前的Tab抛弃掉,空格不抛弃
(2)exec命令