排序算法
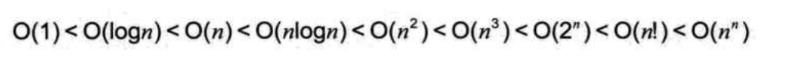
1. 排序的基本概念与分类
(1)稳定性:关键字相等的记录在排序后没有改变起初的先后关系,那么该排序是稳定的
(2)内排序与外排序
内排序:待排序记录全部在内存里 外排序:记录数太多,排序时要在内外存之间多次交换数据
内排序:
时间性能:比较、移动
辅助空间
算法的复杂性:算法本身的复杂性
内排序主要分类:插入排序(直接插入排序、希尔排序)、交换排序(冒泡、快速)、选择排序(简单选择、堆排序)、归并排序
(3)各排序算法复杂度汇总
冒泡:O(N2)
2. 排序
#define MAXSIZE 10 typedef struct { int r[MAXSIZE+1]; int length; }sqList;
2.1 冒泡排序
属于交换排序
数组长为n
(1)v1
从最前面开始,两两相邻元素比较。如果前面的比后面的大,就交换(升序);如果前面的比后面的小,就交换(降序)。
两层for循环,数组长为n则要进行 n-1 次大循环,每经过一个大循环,一个最大的数(或最小的数)就交换到最后面去了。
比较次数:n-1 + n-2 +...+1=(n2-n)/2 比较次数是固定的
交换次数:最坏是(n2-n)/2
稳定性:由于写的是只有大于或者小于才交换,且交换发生在相邻的元素上,所以是稳定的
1 //flag==true,升序;false,降序 2 void bubbleSort0(sqList *L,bool flag) 3 { 4 int len = L->length; 5 for(int i=0;i<len-1;i++) { 6 for(int j=0;(j+1)<(len-i);j++) { 7 if(flag) { 8 if(L->r[j] > L->r[j+1]) { //升序 把大的数往后挪 9 myswap(L,j,j+1); 10 } 11 } 12 else { 13 if(L->r[j] < L->r[j+1]) { //降序 把小的数往后挪 14 myswap(L,j,j+1); 15 } 16 } 17 } 18 } 19 }
或者可以从后往前:
void bubbleSort1(sqList *L,bool flag) { int len = L->length; for(int i=0;i<len-1;i++) { for(int j=len-1;(j-1)>=i;j--) { if(flag) { if(L->r[j-1] > L->r[j]) { //升序 把小的数往前挪 myswap(L,j-1,j); } } else { if(L->r[j-1] < L->r[j]) { //降序 把大的数往前挪 myswap(L,j-1,j); } } } } }
(2)v2
优化:对于已经是升序或降序的数组,我们就没有必要进行那么多次的比较了。或者对于一些排序了几次就已经全部有序的,那么后续的比较也没有意义了。
增加一个标志flag,如果在对待排序的部分进行比较后没有进行元素交换,那说明这部分已经有序了
比较次数:最好:n-1次 最差同(1)
交换次数:最好:0次 最差同(1)
1 void bubbleSort2(sqList *L,bool flag) 2 { 3 int len = L->length; 4 bool status = true; 5 for(int i=0;i<len-1 && status;i++) { 6 status = false; 7 for(int j=len-1;(j-1)>=i;j--) { 8 if(flag) { 9 if(L->r[j-1] > L->r[j]) { //升序 把小的数往前挪 10 myswap(L,j-1,j); 11 status = true; 12 } 13 } 14 else { 15 if(L->r[j-1] < L->r[j]) { //降序 把大的数往前挪 16 myswap(L,j-1,j); 17 status = true; 18 } 19 } 20 } 21 } 22 }
2.2 简单选择排序 simple selection sort
通过 n - i 次关键字之间的比较,从 n - i + 1个记录中选出关键字最小的记录,并和第 i(1≤i≤n) 各记录交换之。
每经过一个小循环,用min_max标记了最小的或最大的元素,然后与最前面的元素交换。
比较次数:最好最坏情况一样 n-1 + n-2 +...+1=(n2-n)/2
交换次数:最好0次 最差:n-1次
稳定性:由于从前往后找最值,且把最值放在前面,那么对于相等的两个元素,一定是前面的先移动,因此是稳定的
1 void simpleSelection(sqList *L,bool flag) 2 { 3 int len = L->length; 4 int min_max = 0; 5 for(int i = 0;i<len-1;i++) { 6 min_max = i; 7 for(int j= i+1;j<len;j++) { //小循环找到待排序里面的最小(或最大)元素 8 if(flag) { //升序 9 if(L->r[min_max]>L->r[j]) { 10 min_max = j; 11 } 12 } 13 else { //降序 14 if(L->r[min_max]<L->r[j]) { 15 min_max = j; 16 } 17 } 18 } 19 if(min_max != i) { 20 myswap(L,i,min_max); 21 } 22 } 23 }
2.3 直接插入排序 straight insertion sort
将整个记录看作有序部分和无序部分,每次从无序部分取一个放到有序表中合适位置,从而得到一个新的、记录数增1的有序表。
空间消耗:需要一个辅助空间tmp
比较次数:最好情况:比较(行7)n-1次,没有行7那就是在里面的for里面比较n-1次
最坏情况:比较1+2+...+n-1=(n2-n)/2
移动次数:最好情况:移动0次
最坏情况:移动1+2+...+n-1=(n2-n)/2
1 void insertionSort(sqList *L,bool flag) 2 { 3 int len = L->length; 4 int tmp,i,j; 5 for(i=1;i<len;i++) { //L->r[i] 之前的数组都是有序的 6 if(flag) { 7 if(L->r[i]<L->r[i-1]) { //取出的来无序元素小于有序表的最后一个元素才往下执行 8 tmp = L->r[i]; 9 for(j=i-1;(j>=0) && (tmp<L->r[j]);j--) { 10 L->r[j+1] = L->r[j]; 11 } 12 L->r[j+1] = tmp; 13 // for(j=i;(j>0) && (tmp<L->r[j-1]);j--) { 14 // L->r[j] = L->r[j-1]; 15 // } 16 // L->r[j] = tmp; 17 } 18 } 19 else { 20 //降序 21 if(L->r[i]>L->r[i-1]) { 22 tmp = L->r[i]; 23 for(j=i-1;(j>=0)&&(tmp>L->r[j]);j--) { 24 L->r[j+1] = L->r[j]; 25 } 26 L->r[j+1] = tmp; 27 // for(j=i;(j>0) && (tmp>L->r[j-1]);j--) { 28 // L->r[j] = L->r[j-1]; 29 // } 30 // L->r[j] = tmp; 31 } 32 } 33 } 34 }
第7行、第21行:比如要对0,1,2升序排序,则不需要进到里面的for循环里面去。
简单选择排序与直接插入排序比较:
简单选择排序:数据移动少,最坏情况只要O(N)
时间复杂度与序列的有序性无关
直接插入排序:对于部分有序的序列性能较高
2.4 希尔排序
上面的排序都适合O(N2)时间复杂度的
希尔排序是优化的直接插入排序
先将较大的数据集合逻辑上分成若干组(增量组),然后对每一个小组的组内进行直接插入排序,因为小组内数据量小所以效率较高。小组内有序后,然后缩短增量,将整个数据集分成数据量比之前多一点的小组,虽然元素个数增多了,但是现在的小组内部分有序了,然后再次对各个小组直接插入排序。继续缩短增量,直到增量为1,这时的小组就是整个数据集合了,进行一次直接插入排序,整个数据集合就整体有序了。
增量的选择:
时间复杂度:一般O(n3/2) 最低:O(n*log2n)
不稳定的算法
1 void shellSort(sqList *L,bool flag) 2 { 3 int len = L->length; 4 int gap,tmp,i,j; 5 for(gap=len/2;gap>0;gap/=2) { 6 7 for(i=gap;i<len;i++) { 8 if(flag) { 9 if(L->r[i]<L->r[i-gap]) { 10 tmp = L->r[i]; 11 for(j=i-gap;(j>=0)&& tmp<L->r[j];j-=gap) { 12 L->r[j+gap] = L->r[j]; 13 } 14 L->r[j+gap] = tmp; 15 } 16 } 17 else { 18 if(L->r[i]>L->r[i-gap]) { 19 tmp = L->r[i]; 20 for(j=i-gap;(j>=0)&& tmp>L->r[j];j-=gap) { 21 L->r[j+gap] = L->r[j]; 22 } 23 L->r[j+gap] = tmp; 24 } 25 } 26 } 27 } 28 }
通过第一层for控制增量,第二层和第三层for是对各组内进行直接插入排序
2.5 堆排序
简单选择排序中,每次在n个待排序的记录中经过n-1次比较找一个最小的记录。但是没有把每一次的比较结果保存下来,在后面的比较中,有很多已经在前一趟做过比较了,导致了比较次数比较多。
(1)大根堆、小根堆
堆:一个完全二叉树。大根堆是每个结点的值都大于或等于其左右孩子的值 小根堆是每个结点的值都小于或等于其左右孩子的值
(2)堆排序
属于选择排序
将整个待排序序列构成大根堆,将根结点值放到序列最后并从堆上移走,将剩余元素重新构成堆,得到次大值.....
关键步骤:①无序元素构成堆 ②输出堆顶元素后,调整剩余元素称为新的堆
最坏、最好、平均时间复杂度:O(n*log2n)
不稳定的排序算法
(3)
结点从0开始:结点 i 的左子是 2*i + 1 右子是:2*i +1 +1
结点 i 的双亲结点是 (i-1)/2
共n个结点:最后一个非叶子结点是 n/2 -1
调整以结点 i 为根结点的子树:使根结点最大
1 static void heapAdjust(sqList *L,int i,int len) 2 { 3 int temp,j; 4 temp = L->r[i]; 5 for(j=2*i+1;j<len;j=2*j+1) { 6 if((j+1)<len && L->r[j]<L->r[j+1]) { 7 ++j; 8 } 9 if(L->r[j]>temp) { 10 L->r[i] = L->r[j]; 11 i = j; 12 } 13 else { 14 break; 15 } 16 } 17 L->r[i] = temp; 18 }
构建大根堆:
1 int len = L->length; 2 for(int i=len/2-1;i>=0;i--) { 3 //从第一个非叶子结点开始调整结构-----大根堆 4 heapAdjust(L,i,len); 5 } 6 7 static void heapAdjust(sqList *L,int i,int len) 8 { 9 int temp,j; 10 temp = L->r[i]; 11 for(j=2*i+1;j<len;j=2*j+1) { 12 if((j+1)<len && L->r[j]<L->r[j+1]) { //找到左子、右子中较大的 13 ++j; 14 } 15 if(L->r[j]>temp) { 16 L->r[i] = L->r[j]; 17 i = j; 18 } 19 else { 20 break; 21 } 22 } 23 L->r[i] = temp; 24 }
完整的堆排序:
1 void headSort(sqList *L,bool flag) 2 { 3 int len = L->length; 4 for(int i=len/2-1;i>=0;i--) { 5 //从第一个非叶子结点开始调整结构-----大根堆 6 heapAdjust(L,i,len,flag); 7 } 8 for(int j=len-1;j>0;j--) { 9 myswap(L,0,j); //交换堆顶(0)元素和末尾元素 10 heapAdjust(L,0,j,flag); //调整整个堆,不包括最后面的元素 11 } 12 }
(4)降序
(3)的是构建大根堆,然后升序排序。降序需要构建小根堆。
修改heapAdjust的行12、15
构建小根堆:
1 int len = L->length; 2 for(int i=len/2-1;i>=0;i--) { 3 //从第一个非叶子结点开始调整结构-----小根堆 4 heapAdjust(L,i,len); 5 } 6 7 static void heapAdjust(sqList *L,int i,int len) 8 { 9 int temp,j; 10 temp = L->r[i]; 11 for(j=2*i+1;j<len;j=2*j+1) { 12 if((j+1)<len && L->r[j]>L->r[j+1]) { //找到左子、右子中较小的 13 ++j; 14 } 15 if(L->r[j]<temp) { 16 L->r[i] = L->r[j]; 17 i = j; 18 } 19 else { 20 break; 21 } 22 } 23 L->r[i] = temp; 24 }
完整的降序:同升序,区别在于heapAdjust方法不同
(5)升序、降序写在一起
1 static void heapAdjust(sqList *L,int i,int len,bool flag) 2 { 3 int temp,j; 4 temp = L->r[i]; 5 for(j=2*i+1;j<len;j=2*j+1) { 6 if(flag) { 7 if((j+1)<len && L->r[j]<L->r[j+1]) { 8 ++j; 9 } 10 if(L->r[j]>temp) { 11 L->r[i] = L->r[j]; 12 i = j; 13 } 14 else { 15 break; 16 } 17 } 18 else { 19 if((j+1)<len && L->r[j]>L->r[j+1]) { 20 ++j; 21 } 22 if(L->r[j]<temp) { 23 L->r[i] = L->r[j]; 24 i = j; 25 } 26 else { 27 break; 28 } 29 } 30 31 } 32 L->r[i] = temp; 33 } 34 35 void headSort(sqList *L,bool flag) 36 { 37 int len = L->length; 38 for(int i=len/2-1;i>=0;i--) { 39 //从第一个非叶子结点开始调整结构-----大/小根堆 40 heapAdjust(L,i,len,flag); 41 } 42 for(int j=len-1;j>0;j--) { 43 myswap(L,0,j); //交换堆顶(0)元素和末尾元素 44 heapAdjust(L,0,j,flag); //调整整个堆 45 } 46 }
2.6 归并排序 merging sort
初始序列有n个记录,看成n个长度为1的子序列。两两归并,得到[n/2]个长度为2或1的有序子序列;继续两两归并....直到得到一个长度为n的有序序列为止。这种排序方法叫2路归并排序。
最好、最坏、平均时间复杂度为O(n*log2n)
但是需要一块序列同样长度的空间
稳定排序算法
(1)递归形式
1 void mergeSort(sqList *L,bool flag) 2 { 3 int *tmp = nullptr; 4 int n = L->length; 5 tmp = (int*)malloc(n*sizeof(int)); 6 if(tmp == nullptr) { 7 return; 8 } 9 msort(L->r,tmp,0,n-1,flag); 10 if(tmp != nullptr) { 11 free(tmp); 12 } 13 }
1 static void msort(int * a,int * tmp,int left,int right,bool flag) 2 { 3 int center; 4 if(left<right) { 5 center = (left+right)/2; 6 msort(a,tmp,left,center,flag); 7 msort(a,tmp,center+1,right,flag); 8 merge(a,tmp,left,center+1,right,flag); 9 } 10 }
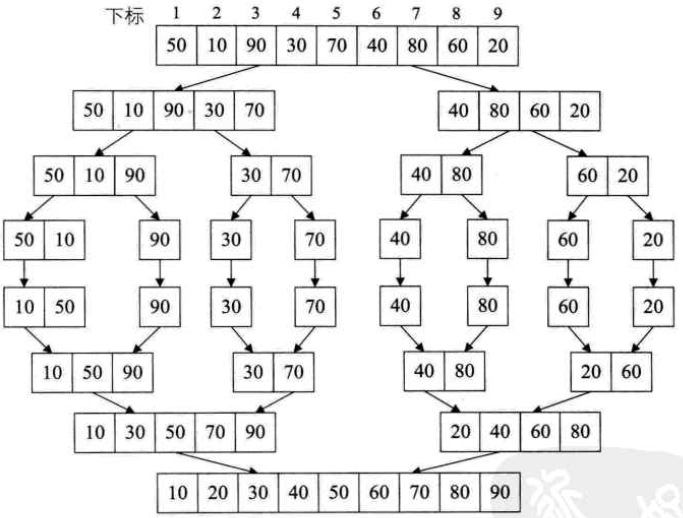
归并的递归程序,不断进入递归(分),直到 msort() 的left、right相邻(间隔1单位),如上面的图进入【50,10】,然后进入merge进行真正的比较和排序。
merge函数:
1 static void merge(int a[],int tmp[],int lpos,int rpos,int rightend,bool flag) 2 { 3 int i,leftend,nums,tmppos; 4 leftend = rpos - 1; 5 tmppos = lpos; 6 nums = rightend - lpos + 1; //元素个数 7 8 while(lpos<=leftend && rpos<=rightend) { 9 if(flag) { 10 if(a[lpos]<=a[rpos]) {//这个等号是保证稳定必须的,不然右边的相等数就会先放到tmp数组了 11 tmp[tmppos++] = a[lpos++]; 12 } 13 else { 14 tmp[tmppos++] = a[rpos++]; 15 } 16 } 17 else { 18 if(a[lpos]>=a[rpos]) {//这个等号是保证稳定必须的,不然右边的相等数就会先放到tmp数组了 19 tmp[tmppos++] = a[lpos++]; 20 } 21 else { 22 tmp[tmppos++] = a[rpos++]; 23 } 24 } 25 26 } 27 28 while(lpos<=leftend) { 29 tmp[tmppos++] = a[lpos++]; 30 } 31 while(rpos<=rightend) { 32 tmp[tmppos++] = a[rpos++]; 33 } 34 35 for(int i=0;i<nums;i++,rightend--) { 36 a[rightend] = tmp[rightend]; 37 } 38 39 }
merge函数的过程如下图:图来自https://www.cnblogs.com/chengxiao/p/6194356.html
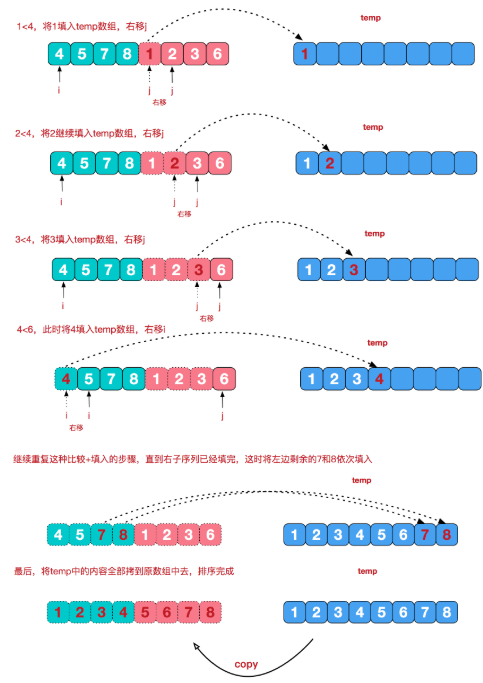
(2)非递归形式的
代码没有递归的简洁,且很多地方判断容易出错,但是效率比递归的要好
1 void mergeSort2(sqList *L,bool flag) 2 { 3 int* tmp = (int *)malloc(L->length*sizeof(int)); 4 int k = 1; 5 while(k<L->length) { 6 mergePass(L->r,tmp,k,L->length,flag); 7 k *= 2; 8 mergePass(tmp,L->r,k,L->length,flag); 9 k *= 2; 10 } 11 }
为什么要先mergePass(r,tmp)在mergePass(tmp,r):
避免不必要的复制。这个复制来自哪里呢? 假如while循环里只用mergePass(r,tmp),则mergePass里面每次以k为间隔排序小组后,要在merge里面要先将元素排序到tmp,然后复制回r。然后变更k 值,又以新的k在merge里面先排序到tmp,再复制回r。这个复制是没必要的。我们直接将元素从r排序到tmp,再从tmp以新的间隔排序回r就行了。
①先以k=1为间隔,将数组r相邻的元素排序放到tmp中
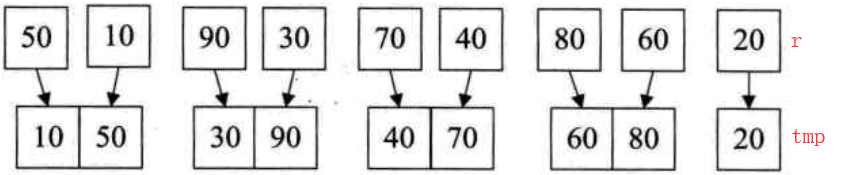
②以k=2,将tmp的元素排序到r
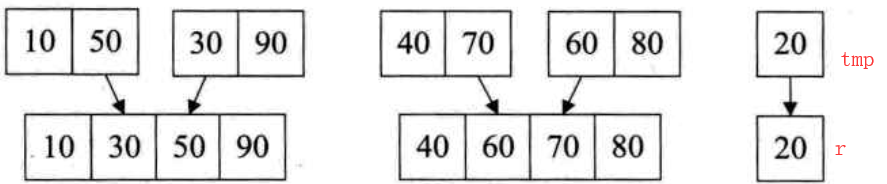
③以k=4,将r元素排序到tmp

④以k=8,将tmp元素排序到r
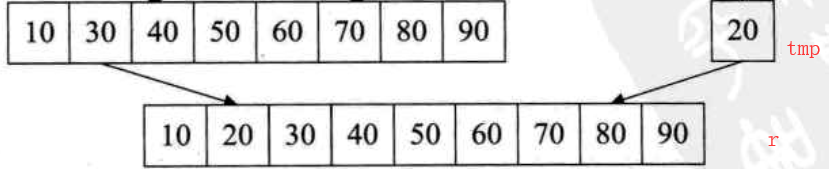
⑤k=16,超过数组长度,则归并排序完成,退出
1 static void mergePass(int* a,int* tmp,int s,int n,bool flag) 2 { 3 int i = 0; 4 int j; 5 while((i+2*s-1)<n) { //保证rightend小于n 6 merge(a,tmp,i,i+s,i+2*s-1,flag); 7 i += 2*s; 8 } 9 /*分情况,(1)要么n是2*s的倍数,则整个数组已经归并完了 i==n 10 (2)要么n是2*s的倍数还多几个,则没有归并完,没有归并完又分两种情况 11 ①剩下来2组,即1组够s个,1组不够s个 i+s(rpos)<n 12 ②剩下来1组,这1组是组内有序的(单独的组内必然是有序的) 13 */ 14 //if(i<n) { 15 if((i+s)<n) { //上面的if(i<n)是不必要的,i+s<n则必定i是小于n的 16 merge(a,tmp,i,i+s,n-1,flag); 17 } 18 else { 19 for(int j=i;j<n;j++) { 20 tmp[j] = a[j]; 21 } 22 } 23 //} 24 25 }
各行解释:
首先要了解merge函数各个参数:将 [lpos,leftend]、[rpos,rightend] 这两个小组的元素排序放到另一个数组
mergePass的参数s是要归并的小组的元素间隔:间隔从1起,则为1时有两个元素 n是原无序数组长度
mergePass基本功能是:将a数组元素以k为间隔,将元素排序到tmp数组
lpos为 i,i一开始是0:lpos是i,间隔是s,则leftend是i+s-1 rpos就是i+s rightend就是i+2*s-1
这两个小组排序完成后,到下一对小组, lpos就是 i+2*s
行5:要确保rightend要小于n 否则会越界
当退出循环时,要么整个数组已经排序完成了,这时候 i 等于 n。要是没有排序完,即剩下的元素不够 一对小组(剩下的元素还有两种情况)
行15:对还剩下元素这种情况进行处理,情况①剩下的元素虽然不够一对小组(一对意识指两个小组元素个数相同),但是有1个组元素(组内肯定是有序的)加几个不够一小组的元素
这种情况要继续merge,只是rightend是n-1 这种情况的判断依据就是 rpos要小于n ②剩下的元素是s个或更少,即只有一个小组或不够一个小组,这个组内是有序的,则直接复制到tmp数组去 就行了(这里说的tmp是是指第二个参数指向的数组,有时候并不是真的指mergeSort2里面malloc的那个tmp)-----复制即行20
根据上面的做法:我们从r排序到tmp,又从tmp复制到r,因此merge函数需要对递归的merge改动一下---------注释了35~37
1 static void merge(int a[],int tmp[],int lpos,int rpos,int rightend,bool flag) 2 { 3 int i,leftend,nums,tmppos; 4 leftend = rpos - 1; 5 tmppos = lpos; 6 nums = rightend - lpos + 1; //元素个数 7 8 while(lpos<=leftend && rpos<=rightend) { 9 if(flag) { 10 if(a[lpos]<=a[rpos]) {//这个等号是保证稳定必须的,不然右边的相等数就会先放到tmp数组了 11 tmp[tmppos++] = a[lpos++]; 12 } 13 else { 14 tmp[tmppos++] = a[rpos++]; 15 } 16 } 17 else { 18 if(a[lpos]>=a[rpos]) {//这个等号是保证稳定必须的,不然右边的相等数就会先放到tmp数组了 19 tmp[tmppos++] = a[lpos++]; 20 } 21 else { 22 tmp[tmppos++] = a[rpos++]; 23 } 24 } 25 26 } 27 28 while(lpos<=leftend) { 29 tmp[tmppos++] = a[lpos++]; 30 } 31 while(rpos<=rightend) { 32 tmp[tmppos++] = a[rpos++]; 33 } 34 35 // for(int i=0;i<nums;i++,rightend--) { 36 // a[rightend] = tmp[rightend]; 37 // } 38 39 }
2.7 快速排序
冒泡排序的升级版,属于交换排序
采取双向查找的策略,每一趟选择当前所有子序列中一个关键字作为 枢纽轴,比这个枢纽小的前移,大的后移。第一次完成后得到两组序列,一组序列的值全部比另一组的小,然后分别对两个组进行 同样操作:选择枢纽轴,前移后移......
最好情况:O(n*log2n) 最坏:O(n2) 平均:O(n*log2n)
不稳定算法
1 void quickSort(sqList *L,bool flag) 2 { 3 qSort(L,0,L->length-1,flag); 4 }
1 static void qSort(sqList *L,int low,int high,bool flag) 2 { 3 int pivot; 4 if(low<high) { 5 pivot = partition(L,low,high,flag); 6 qSort(L,low,pivot-1,flag); 7 qSort(L,pivot+1,high,flag); 8 } 9 }
1 static int partition(sqList *L,int low,int high,bool flag) 2 { 3 int pivotkey = L->r[low]; 4 while(low<high) { 5 if(flag) { 6 while(low<high && L->r[high]>=pivotkey) { 7 high--; 8 }//遇到比pivotkey小的值了退出while 9 myswap(L,low,high); 10 while(low<high && L->r[low]<=pivotkey) { 11 low++; 12 } 13 myswap(L,low,high); 14 } 15 else { 16 while(low<high && L->r[high]<=pivotkey) { 17 high--; 18 }//遇到比pivotkey大的值了退出while 19 myswap(L,low,high); 20 while(low<high && L->r[low]>=pivotkey) { 21 low++; 22 } 23 myswap(L,low,high); 24 } 25 } 26 return low; 27 }
快速排序的优化:
①优化选取枢纽轴
当这个值是整个序列有序情况下最中间的值时候,排序性能最好
三数取中法:取三个关键字先排序,取中间数作为枢纽轴,则至少这个值不会是整个序列中最小或最大的数
1 static int median3(sqList *L,int low,int high) 2 { 3 int pivotkey = 0; 4 int m = low+(high-low)/2; 5 if(L->r[low]>L->r[high]) { 6 myswap(L,low,high); //左右端交换,则左端较小 7 } 8 if(L->r[m]>L->r[high]) { 9 myswap(L,m,high); //中间和右端交换,则中间较小 10 } 11 if(L->r[m]>L->r[low]) { 12 myswap(L,m,low); //中间和左边交换,则r[m]是 13 } 14 //到这里,r[low]就是中间的值 15 pivotkey = L->r[low]; 16 return pivotkey; 17 }
九数取中:分三次取,每次取三个数得到各自的中值,再对三个中值取中值
②优化不必要的交换
2.8

 浙公网安备 33010602011771号
浙公网安备 33010602011771号