
阅读文献《AcsiNet: Attention-Based Deep Learning Network for CSI Prediction in FDD MIMO Systems》
这篇文献的作者是南华大学的林文斌老师,于2023年3月3日发表在IEEE WIRELESS COMMUNICATIONS LETTERS。
文章直接对上行 CSI 矩阵使用离散傅里叶逆变换进行压缩,然后将其输入一个基于注意力(attention-based)的深度学习网络,该网络可以专注于关键的 CSI 特征,最后经过傅里叶变换和补零,预测出下行CSI矩阵。文献使用的方法可以直接从相应的上行链路预测下行链路的 CSI,不需要经过CSI反馈,从而完全消除了反馈开销。
1 研究背景
在大规模MIMO中,采用大规模天线 阵列和波束成形来提高网络吞吐量,同时减少传输延迟。为了提高下行传输性能,波束成形需要下行的CSI作为先验信息。在频分双工(FDD) MIMO系统中,基站的每个天线都需要获取下行CSI来进行波束成形,因此用户设备需要估计CSI并将其发送回基站。因为MIMO中的天线数非常巨大,所以CSI反馈会造成巨大的开销和传输延迟。
为了减少CSI反馈开销,除了传统的基于压缩感知(compressed sensing)的方法外,深度学习也能应用到通信之中。深度学习之中除了CsiNet类的编码-解码网络外,有一种完全消除反馈开销的方法:因为上行和下行CSI之间存在相关性,可以利用深度学习以完整的上行CSI作为输入,从上行链路直接预测出下行CSI。
文献的主要贡献有:
- 完全消除CSI反馈开销
- 上行CSI在输入深度学习模型前,利用离散傅里叶逆变换(IDFT)进行压缩,以降低模型复杂度
- 将注意力机制(attention mechanism)整合到深度学习网络中,提取CSI的关键特征
2 系统模型
考虑频分双工MIMO,在BS上的平面天线阵列有\(N_t=N_x×N_y\)根天线,CSI矩阵可以表示为:
其中\(g(·)\)为信道函数,\(f, \mathbf{d}, \mathbf{a}, \boldsymbol{\phi}, \boldsymbol{\theta}\)分别为传输频率、距离、路径增益、出发角、到达角。
假设上行通道和下行通道的空间传输参数不变,因此信号传播的物理路径不变,对于平面天线阵列,上行和下行CSI矩阵\(\mathbf{H}_{\mathrm{UL}}\)和\(\mathbf{H}_{\mathrm{DL}}\)可表示为:
其中\(\mathbf{d_{UL}} = \mathbf{d_{DL}}\),\(\mathbf{a_{UL}} = \mathbf{a_{DL}}\),\(\boldsymbol{\phi_{UL}}=\boldsymbol{\theta_{DL}}\),\(\boldsymbol{\phi_{DL}}=\boldsymbol{\theta_{UL}}\),除了传输频率不同之外,\(\mathbf{H}_{\mathrm{UL}}\)和\(\mathbf{H}_{\mathrm{DL}}\)是高度相关的,因此存在映射关系\(\mathbf{H}_{\mathrm{UL}}→\mathbf{H}_{\mathrm{DL}}\),该文献的主要工作就是使用深度学习的方法拟合这个映射关系。
在正交频分复用(OFDM)中,考虑有\(N_s\)个子载波,在平面天线阵列中,第\((i, j)\)个天线接收到的信号在频域可以表示为:
其中其中\(h_{ij}\)是第\((i, j)\)个天线的信道增益向量,\(diag(·)\)将一个向量转换为一个对角矩阵,\((·)^∗\)表示共轭转置,\(\mathbf{x}\)为一个OFDM周期内的传输符号,\(\mathbf{z}\)为加性复高斯白噪声。所有子载波的上行CSI可用矩阵\(\mathbf{H}_{\mathrm{UL}} = (h_{ij})_{N_x×N_y}\)表示,以子载波数为第一个维度,可以将矩阵\(\mathbf{H}_{\mathrm{UL}}\)重塑为三维矩阵\(N_s×N_x×N_y\)。
为了降低CSI矩阵的大小,首先用三维IDFT将\(\mathbf{H}_{\mathrm{UL}}\)转换为稀疏表示,变换后的其中一个维度对应于延迟,另外两个维度对应于方位角(AOA)和天顶角(ZOA),随后保留它延迟域的前M行,并把实部和虚部分别处理,\(\mathbf{H}_{\mathrm{C}}\)作为AcsiNet的输入。经过AcsiNet的处理后得到估计的下行信道矩阵\(\tilde{\mathbf{H}}_{DL}\):
\(\mathbf{w}\)是网络的权重系数。然后进行补零和DFT变换处理,最终获得的下行CSI矩阵\(\widehat{\mathbf{H}}_{DL}\),如图1所示。
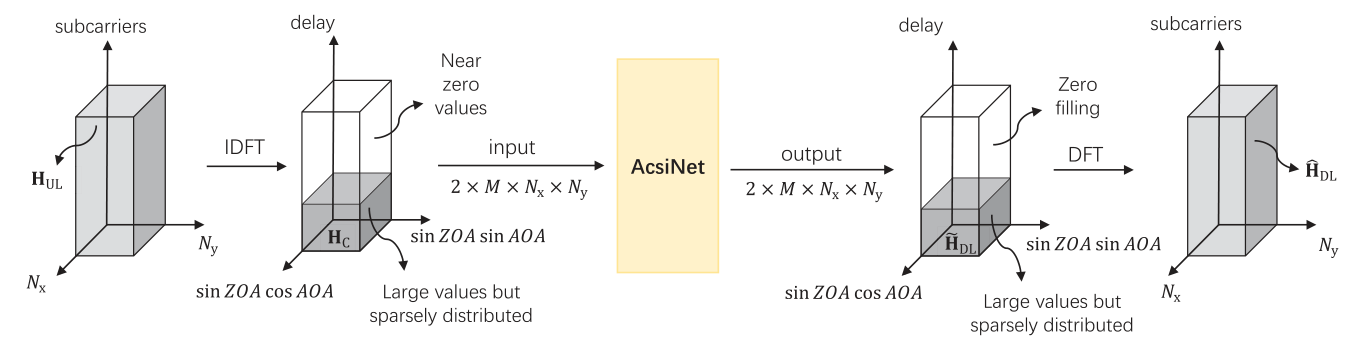
3 AcsiNet
如图2所示,将上行CSI矩阵实部和虚部的每一个值视作一个图像像素输入到AcsiNet中。在网络中首先通过两个数据通道将CSI矩阵输入到卷积层中来提取空间特征,在每个卷积层之后使用批归一化的正则化方法和LeakyReLU激活函数来保留提取的特征信息,最后在全连接层处理后使用ReLU来减少冗余信息。全连接层之后,经过重塑和卷积操作,将特征矩阵输入到两个残差块(Residual block),为了增加网络的泛化性能,两个残差块分别使用3×2×2和5×3×3的卷积核,最终输出估计的矩阵。
为了获取信道矩阵中的关键信息,还整合了两种注意力模块到AcsiNet中,分别是挤压激励网络(squeeze-and-excitation network,SENet)和卷积块注意模型(convolutional block attention module,CBAM),记为AcsiNet_SENet和AcsiNet_CBAM。
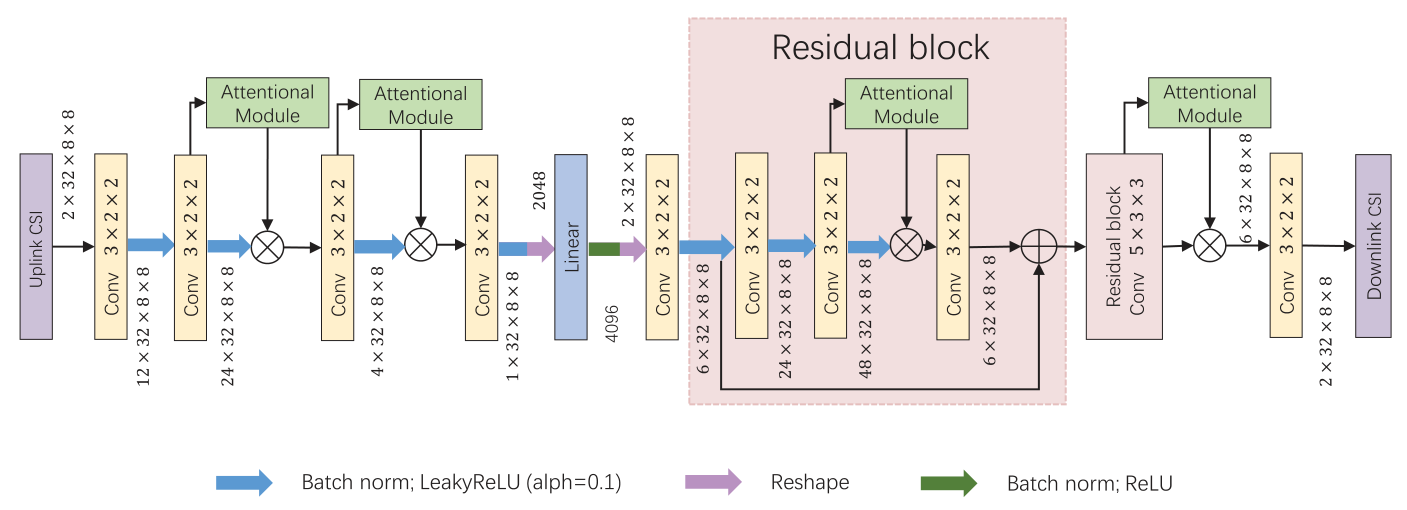
4 实验结果
4.1 实验设置
根据COST 2100通道模型生成室外农村场景,上行通道频率为2GHz,下行通道频率为2.06GHz,子载波数\(N_s = 600\),保留延迟域的前
32行,则\(\mathbf{H}_{\mathrm{C}}\)的大小为\(2 × 32 × 8 × 8(N_t = 64)\)和\(2 × 32 × 4 × 4(N_t = 16)\)。
训练过程中,优化器为Adam,minibatch为512,epoch为1000,初始学习率为\(10^{-3}\),当验证集的损失在20个epoch内没有减少时,就把学习率降低10倍,直到\(10^{-8}\)为止。训练集、验证集和测试集分别由20,000、6000和4000个信道组成。
4.2 结果分析
使用归一化均方误差(NMSE)表示估计的下行CSI矩阵\(\widehat{\mathbf{H}}_{DL}\)与原始\(\mathbf{H}_{\mathrm{DL}}\)的差距,定义为:
此外还用余弦相似度表示波束成形向量的质量,定义为:
其中\(\hat{\mathbf{v}}_i\)和$ \mathbf{v}i\(分别表示估计矩阵\)\widehat{\mathbf{H}}\(与原始\)\mathbf{H}_{\mathrm{DL}}\(中第\)i$个子载波的信道向量。
将实验结果与CsiNet和CV_3DCNN模型进行比较,CsiNet中考虑CsiNet_w/fb和CsiNet_wo/fb两种方案,CsiNet_w/fb代表需要反馈开销的方法,CsiNet_wo/fb代表不需要反馈的方法,使用CsiNet网络从上行CSI预测下行链路CSI。如表1,首先可以观察到AcsiNet_CBAM的性能略好于AcsiNet_SENet,这是因为CBAM比SENet具有额外的空间注意力,能更好地关注空间域中的数据特征;其次,在两种平面天线阵列下,AcsiNet_CBAM的预测精度都优于其他所有模型,AcsiNet的参数大小高于CsiNet_w/fb但低于其他模型。最后除了CV_3DCNN的FLOPs比较大外,其他模型的推理时间都在\(10^{-6}\)秒量级。

5 结论
文献的主要工作有:
- 直接从上行链路预测下行链路的CSI
- 整合注意力机制到深度学习网络中
提出的AcsiNet的CSI预测模型可以直接从上行链路预测下行链路的CSI,实验结果显示AcsiNet能够在不需要CSI反馈的同时提升网络性能,说明注意力机制可以获取信道矩阵中的关键信息,提升网络的性能。

