

有效预警6要素:亿级调用量的阿里云弹性计算SRE实践
 关注保持良好的预警处理,持续解决系统隐患,促进系统稳定健康发展。
关注保持良好的预警处理,持续解决系统隐患,促进系统稳定健康发展。
编者按:随着分布式系统和业务需求的飞速发展,监控告警在我们保障系统稳定性和事故快速恢复的全周期中都是至关重要的。9 月 3 号,阿里云弹性计算管控 SRE 李成武老师(花名佐井),受「TakinTalks 稳定性社区」邀请,在线分享日常预警治理工作的经验和心得,帮助大家实现精准的监控和告警,把问题扼杀在摇篮里,减少故障带来的业务损失。
以下是本次分享内容的文字整理。
如果事情有变坏的可能,不管这种可能性有多小,它总会发生。—— 墨菲定律
系统的稳定性离不开有效的预警机制,根据墨菲定律:可能出错的地方,一定会出错,我们没法准确预测系统会在什么时候在什么地方出错,但是却可以知道当系统出问题的时候,接口响应变慢、系统服务不可用、业务流量下跌或客户操作无法完成甚至有客户投诉。
为了对抗墨菲定律,我们必须未雨绸缪地在各种系统节点上配置预警信息,以免出问题的时候太过被动;同时为了追求问题发现率(更多的预警项、更不合理的阈值、更无关紧要的内容),我们有陷入了预警覆盖的悖论,最终导致了现在普遍的预警地狱现象。我们看下图,这是一个非常典型的正反馈增强回路,导致预警问题越来越多。
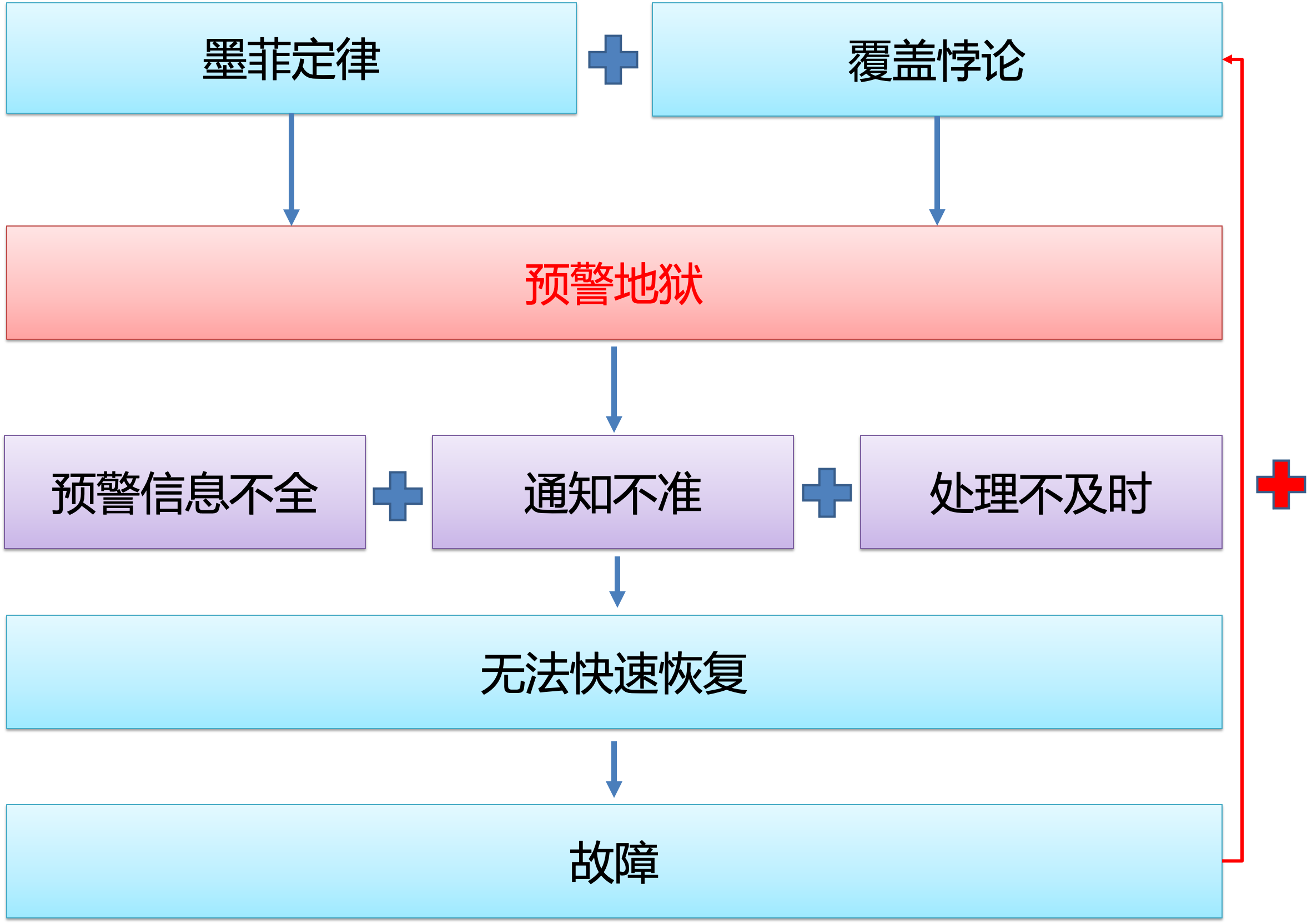
图:预警的正反馈增强回路
更多的预警项会使问题变好吗?根据熵增定律,这一过程必然导致不可逆的破坏性,最终可能分不清哪些预警需要处理,甚至导致对预警的漠视。有没有办法解决这个问题?有,做负熵!从预警的各个环节循序渐进做减法,今天我们就聊聊预警环节的 6 要素。
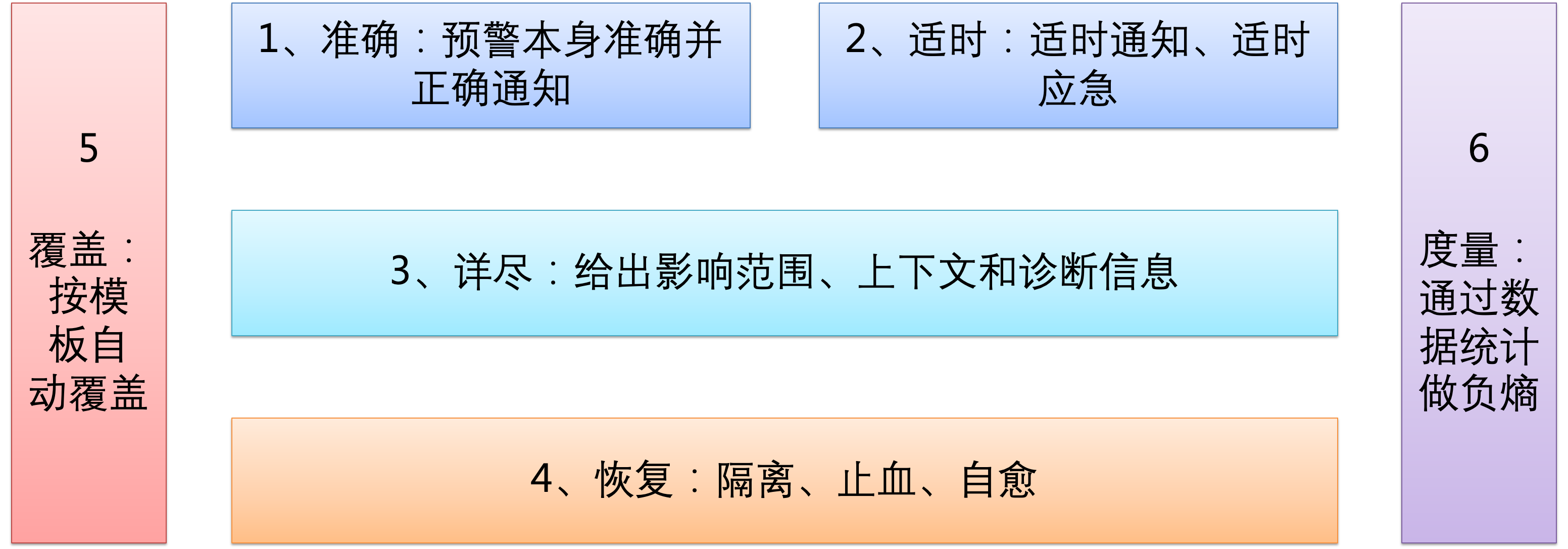
在这 6 个预警要素中,有些是被公认且显而易见的,另外一些常被忽略导致预警地狱,本文综合了日常预警定义、通知、治理的经验和智慧,是预警治理的理想实践标准,关注保持良好的预警处理,持续解决系统隐患,促进系统稳定健康发展。
01 准确:预警本身准确并正确通知
在大量被忽略的预警中,有很大一部分可以称为不准确,因为即使没有处理也不会发生什么实际问题,准确的第一个定义是预警达到了警告级别。无需处理的预警会导致“狼来了”效应,对预警越来越漠视,最终漏掉真正有需要处理的预警;曾经发现过这样的团队,几个小时报一次的预警没人看,只有到短时间高密度的预警通知才能引起注意,这样的团队对预警的免疫能力越来越强,也越来越危险。另外无效的预警通知还会导致不必须到资源浪费,比如:短信、电话费用等。所以,从现在开始,行动起来把无效预警干掉吧。
准确第二个定义是预警准确地通知到正确的接收人。不要以为预警通知的人越多就越可能被处理,实际不相关人收到告警更多是观望,实际上根本没人行动,因为这些无关的人没有动力也没有能力这么做。曾经遇到过一个 case,与预警无关的同学通知需要预警应急的团队,看看你们系统是不是出力问题,虽然这种情况下无关通知起了作用,但对应该预警应急的团队是多么尴尬和可怕的事情啊。另外接收预警应急的同学也需要对预警通知做响应动作,一方面告知关注的同学,预警已经有人响应处理了,另一方面也未后面对预警的度量做数据准备。

总结下准确要素是把真正的预警信息通知到正确的接收人,这里面真正的预警和正确的接收人缺少哪个都不应该发送;同时,这也是一次握手过程,接收人收到通知后要接手并准备处理。
02 适时:适时通知、适时应急
如果按预警的响应率,难道不是及时通知和响应更好,有些情况确实如此;但是别忘了我们来做负熵的,大部分情况我们做到适时就够了,避免过度紧张和恐慌。
首先,适时需要我们在不同时间段采用不同强度的通知渠道,比如夜间需要应急的预警,短信或 IM 很可能无法及时触达,需要用更强烈的通知方式,比如电话;但是在正常的工作时间,大家都是在线状态就没有这个必要。非常严重的预警,还是需要继续保持紧急的强通知以达到时效性,但是我们还是倡议非必须尽量不用。
其次,在应急上,对于没有及时响应的预警,可以升级成更强烈的通知渠道;同时也可以在处理人员上做升级,比如升级到主管、SRE 等,以达到适时应急的目的。并不是每个预警都需要紧急处理的,比如:服务宕机,如果是线上许多机器中的一台,对业务流量不会造成影响,可以稍后再处理。
最后,适时要保障相同的预警不要短时间重复发送,避免淹没在预警炸弹中。一般情况是合并报警并做相关统计,然后根据预警分类做对应的抑制操作,或者让人工选择暂停一段时间的这类预警发送。当第一条预警被认领后,表示相关的应急处理已经启动,再推送相关预警更多是干扰,处理的效果可以通过监控观察,所以是不需要继续再报同样的预警的。
03 详尽:给出影响范围、上下文和诊断信息
收到告警后第一要事是确定问题然后采取对应的隔离或止血措施,如果告警内容太过简单,会让这个过程变成一个猜谜游戏,需要重新去现场,通过多种手段验证和推测,才能确定问题所在,这也是处理预警耗时最多的地方,而且这里很多是靠经验吃饭,新同学几乎很难插手。所以,在预警信息中给出影响范围和上下文和诊断信息,会上问题定位事半功倍。
首先,预警的影响范围是判断应急轻重缓急的重要指标。影响范围包括资源、业务、用户等维度:
-
资源:单机、集群、相关依赖;
-
用户:个别、部分还是全部客户;
-
业务:核心业务、旁路业务、非核心业。
如果影响范围是个别情况,可以快速做隔离,比如把单个机器做隔离,摘除掉非核心链路或者单个客户做流控降级。相反,如果面积级别的,需要更采用更紧急响应机制,比如拉起更多的人处理:主管、SRE 以及团队其它同学,甚至升级成故障级别。
其次,上下文信息会让定位事半功倍。上下文信息有助于判断错误的诊断,省去重新还原现场的麻烦。上下文信息包括:
◾ trace:给出预警问题的一条 trace 链路,相当于把现场还原;
◾ 日志:详细的错误日志 link 能定位到具体代码和当时的堆栈信息;
◾ 关联:关联的预警或变更,方便快速判断预警是不是由其它问题关联导致或因变更引起。
有了上下文信息,进一步排查的路径基本也确定了;否则需要去各种平台搜集信息、甚至需要重新恢复现成,而这些操作不仅耗时,还可能因为信息不全或时间流程导致无法得到需要的信息。
最后,预警中的诊断信息,甚至能直接给出定界原因,免去排查时间。问题的定位很多时候依赖处理人对业务的理解,对工具的使用,对平台的数据和曾经的经验。预警诊断就是把这些脑海中的流程经验通过规则+数据变成结果直接输出,诊断需要一定的系统能力建设才能实现,比如 ECS 内部采用下面的架构来支撑诊断:
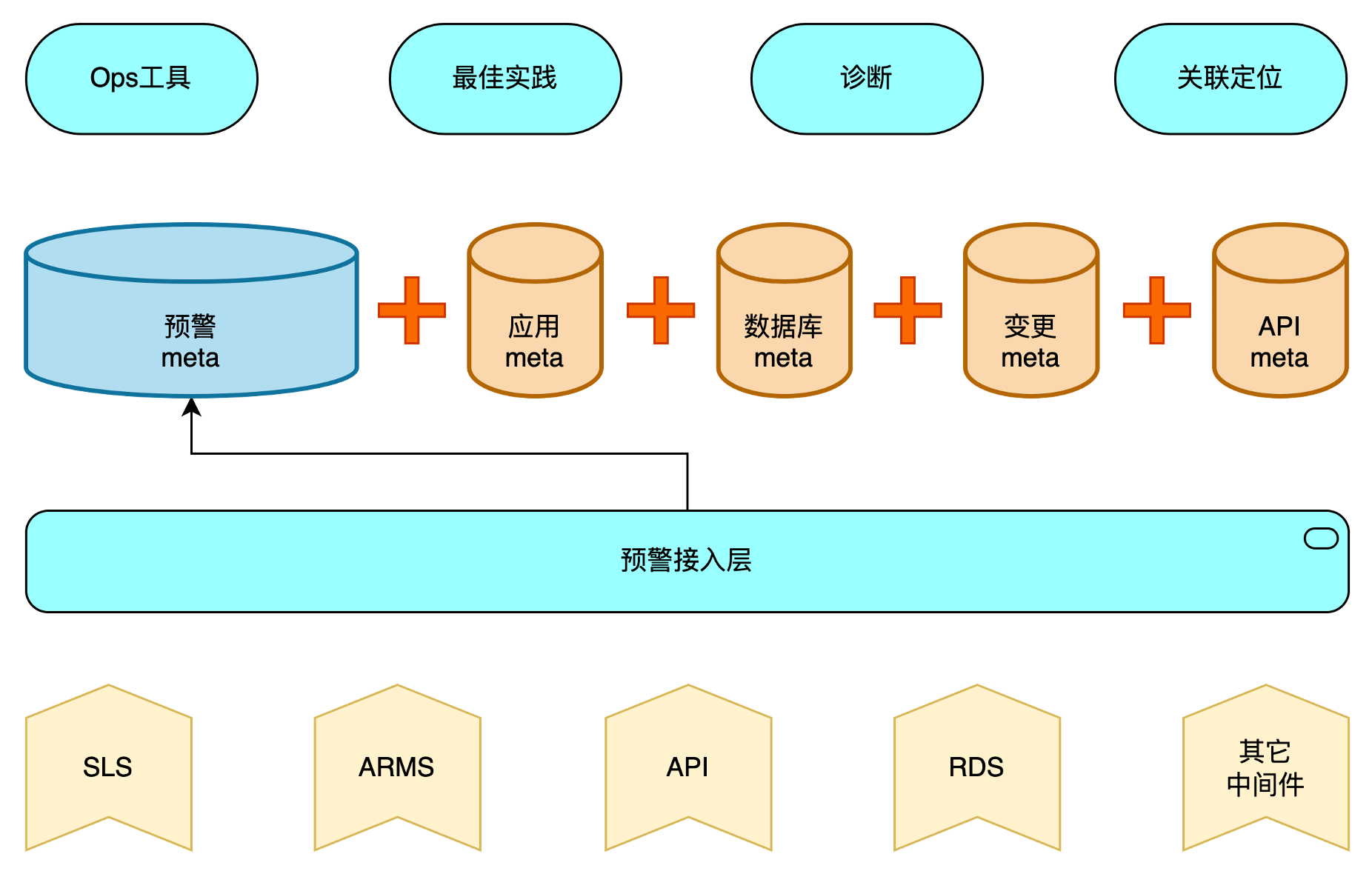
1. 需要把不同渠道的预警信息统一接入,预警信息如果直接发送出去,就丢失了诊断环节,预警信息首先接入诊断层,才能实现后续诊断动作。
2. 需要有一定的信息收集能力,包括:各种 meta 信息(应用、数据库、api、人员、值班 …)、变更信息、运维工具、日志和其它预警信息等。
3. 需要有一定的信息整合能力,把预警和收集的信息做整合,结合诊断框架给出诊断结果。
04 恢复:隔离、止血、自愈
恢复是预警处理的第一要事,先要消除对系统、业务、客户的影响,然后才是排查问题。要素 3(详尽:给出影响范围、上下文和诊断信息)业务为了定位到哪里出了问题,然后采取对应的恢复手动。
一般情况下,恢复需要执行一些动作,如果预警能更进一步,给出恢复操作,那将极大提升响应速度。
一般情况下恢复动作有以下执行路径:
◾ 故障自愈,根据预警判断影响并关联预制动作完成故障自愈。首先需要预警支持绑定 call back 动作,可以根据预警内容选择正确自愈操作;其次动作执行控制范围,避免自动执行动作带来二次故障。比如:我们可以检测到单机问题,把机器摘除掉。自愈需要判断好执行的范围和影响面,对有信心的动作才能自动执行。
◾ 止血动作的 action,可以通过 link 或者 chatops 方式嵌入到预警内容中,点击相关 action 快速消除影响。比如:我们会在预警通知中,给出一些流控、重启、开关等动作,一键即可完成操作。
◾ 最佳实践、操作手册或者相关联系人,在没有止血 action 的时候,可以给出继续操作的指引,按照手册继续操作或联系能处理的人。
至此,我们通过 4 个要素的优化,完成了预警的整个应急过程,接下来 2 个要素讲关注预警的运营,通过高效、有效的运营,更进一步对预警进行治理。
05 覆盖:按模板自动覆盖
在故障复盘中,有不少问题没有及时发现的原因是缺少对应的监控。监控项是不可能覆盖全的,但是经验是可以积累传承的,通用、标准的预警适用大部分业务,可以通过模板方式做到更大范围的覆盖。
一类预警有这相似的监控项甚至差不多的阈值定义,这类标准的监控要能够在多个应用甚至业务上快速覆盖,通过巡检机制保障不会被遗漏。一般情况下预警的监控项分为基础监控和业务监控,业务重要等级不同,对监控和预警的定义也有差异。比如我们根据应用等级对监控也提出响应的等级,按照等级对监控通过模板进行覆盖,这样避免了忘记配置问题,同时新增资源或服务情况也做到自动覆盖。
通用的监控需要积累并模板化,这样能把经验传递下去,避免发送类似的问题。比如:之前兄弟团队出现过一个这样的故障。由于发布脚本问题,导致发布过程中从 vip 摘除的机器在发布完成后没有挂载上,当最后一个机器发布完成后,整个 vip 没有 server 导致业务不可用。我们通过复盘总结这样一个通用规则:vip 中挂载的机器超过 xx%被摘除后,出发一个预警,并应用到多个组织中,就避免了后续再发生类似的事情。
06 度量:通过数据统计做负熵
最后我们来聊聊预警的数据统计。管理大师德鲁克曾经说过:
你如果无法度量它,就无法管理它。(If you can’t measure it, you can’t manage it.) —— 彼得·德鲁克
度量是完成预警治理闭环的重要一环,其实我们这里是借助“精益”的思想,通过数据反馈发现问题,然后在问题上进行尝试,再回头看数据。
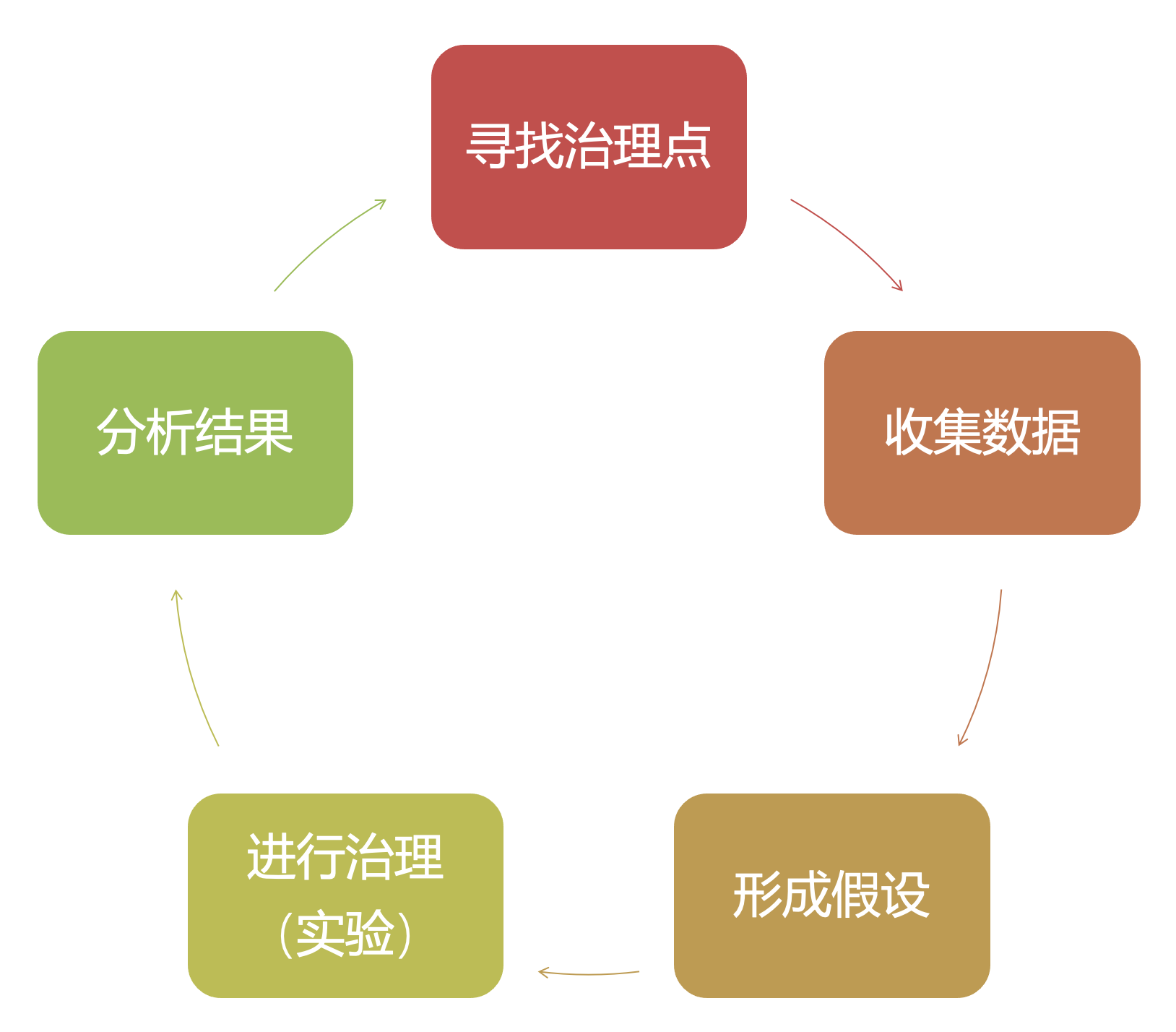
度量的数据可以包括以下几个方面:
◾ 预警的具体数据:用于分析后续分析改进、统计通知频率、统计预警量,比如:每个平均 1 天不超过 3 条,TOP 人/团队/应用等红黑榜。
◾ 是否被标记无效:清理无效预警。
◾ 是否有人认领:认领率需要通过红黑榜通晒。
◾ 认领的时间:应急改进,故障类的可以参考 “1-5-10”(1 分钟发现问题,5 分钟定位,10 分钟恢复)。
◾ 解决的时间:更好的完成 “1-5-10”。
◾ 预警工具的使用情况:改进工具的推荐准确性。
有了这些运营的数据,治理起来就有了抓手,持续的运营下去,才能让预警往更健康的方向演进。
总 结
最后,结合一个阿里云弹性计算的内部实践,说明我们怎么结合 6 要素进行预警治理的。
我们在预警方面构建了一个统一的预警平台,把 6 要素通过工程方式融入到预警生命周期管理上。
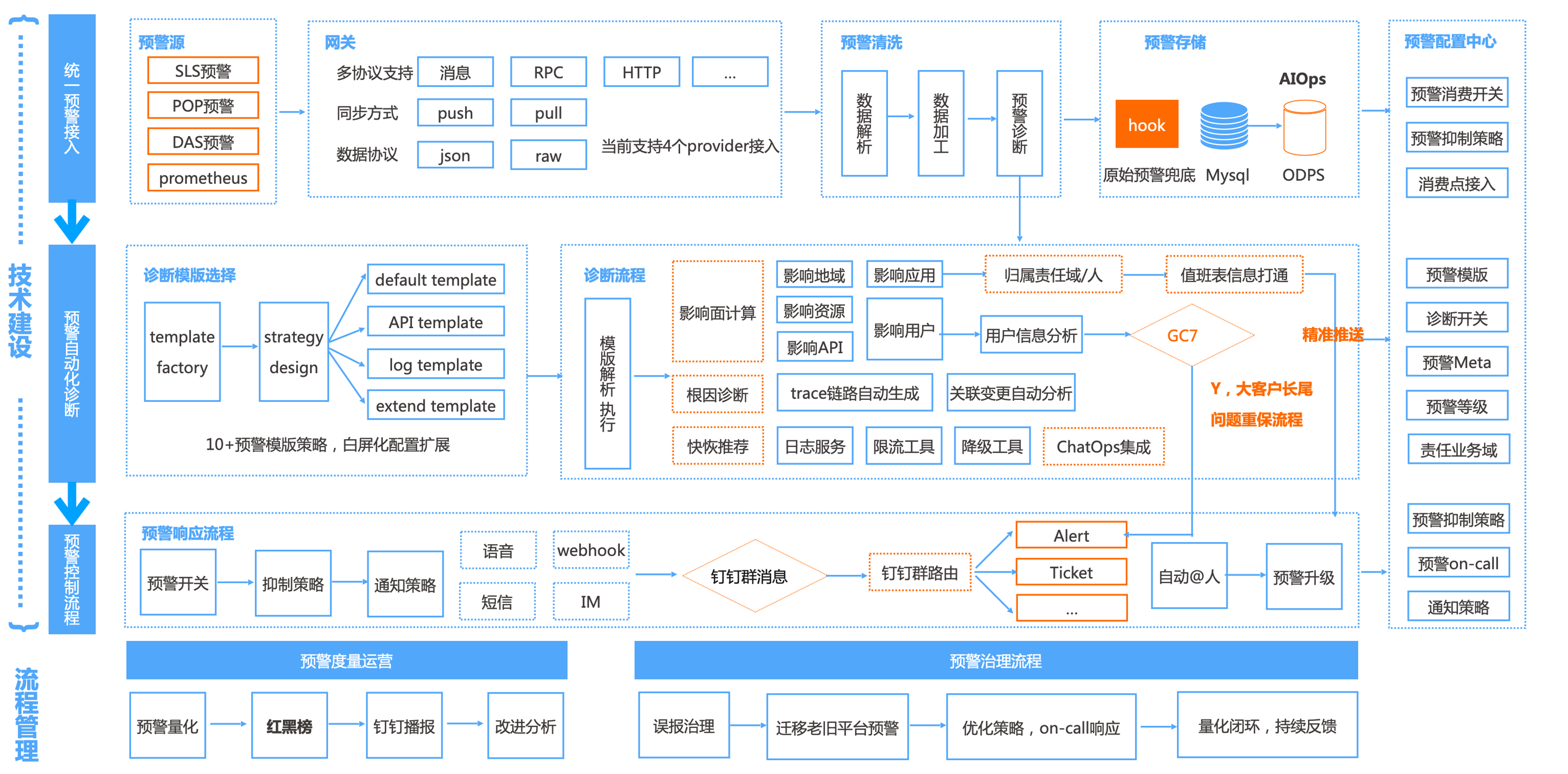
首先我们收口了大部分的预警渠道,在内部我们有 SLS、POP、ARMS、DAS、Promethues 等多个预警源,这些预警会通知到预警网关而不是具体的人。预警网关会对这些数据进行解析、架构和诊断操作。
诊断环境我们把会输出影响面、根因和快恢工具,这部分是最复杂的,需要有一定的信息整合能力和诊断能力。首先我们会把预警信息与 meta 进行关联,meta 是我们内部持续建设的基础数据,里面包含了,资源信息(机器、数据库、API、应用等等)、组织信息(组织架构、owner 信息、值班信息)和策略信息(应急流程、升级策略、通知策略等);除此之外,针对预警内容我们还要做诊断影响面(影响客户、地域、资源、api 等),同时保留上下文并抓取日志或 trace 链路,最后结合对预警内容的分析给出恢复工具。这些信息会通过模板引擎进行渲染,最终推送到具体人。
在诊断过程,如果我们发现预警需要升级,会自动升级预警基本并启动对应的应急流程,比如:识别重保客户,会启动 alert 流程进行应急。
最后,通过数据的量化,形成对应的红黑榜通晒,持续对不达标的指标进行治理。同时也会通过数据分析我们在治理流程上的不足,持续迭代,形成闭环。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?