
MySQL高可用架构之分库分表——ShardingJDBC的使用
1. 准备工作
项目文件链接如下。
链接:https://pan.baidu.com/s/1_qkkCEBvYPCmagFD9Y8-nA
提取码:kbtg
创建两个字符集相同的数据库,再在每个数据库中创建两个数据结构相同的表结构。这里我创建的数据库为shardingjdbc_1,shardingjdbc_2,表为student_1,student_2。
CREATE TABLE `student_1` ( `id` bigint NOT NULL, `name` varchar(64) DEFAULT NULL COMMENT '姓名', `sex` char(1) DEFAULT NULL COMMENT '性别', `age` int DEFAULT NULL COMMENT '年龄', `address` varchar(255) DEFAULT NULL COMMENT '地址', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;
创建一个springBoot项目,导入如下依赖。


<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
<version>2.6.7</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.9</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.1</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
2. ShardingJDBC分库分表实战
2.1 inline分片算法的使用
使用场景:SQL 语句中有>,>=, <=,<,=,IN 和 BETWEEN AND 操作符,都可以应用此分片策略。标准分片策略(StandardShardingStrategy),它只支持对单个分片健(字段)为依据的分库分表,并提供了两种分片算法 PreciseShardingAlgorithm(精准分片)和 RangeShardingAlgorithm(范围分片)。在使用标准分片策略时,精准分片算法是必须实现的算法,用于 SQL 含有 = 和 IN 的分片处理;范围分片算法是非必选的,用于处理含有 BETWEEN AND 的分片处理。 inline策略为最基本,也为最常见,最简单的分片策略,使用的yml配置文件如下。
spring: shardingsphere: datasource: names: m1 m1: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://rm-bp1347i6zmc5iozp59o.mysql.rds.aliyuncs.com:3306/shardingjdbc_1?characterEncoding=utf8&characterSetResults=utf8&autoReconnect=true&failOverReadOnly=false&useSSL=false&serverTimezone=GMT%2B8 username: root password: txb@root sharding: tables: student: actualDataNodes: m1.student_$->{1..2} #该写法说明表从student_1到student_2 keyGenerator: column: id # 分表所根据的表列名 type: SNOWFLAKE # 此处采用雪花算法 tableStrategy: inline: shardingColumn: id algorithmExpression: student_$->{id % 2 + 1} #分片算法为根据id除以2取模,偶数存入student_1,奇数存入student_2 props: sql: show: true
新建实体类与mapper后在测试类中测试新增数据是否成功,代码如下。
@Test public void addStudent(){ for (int i = 0; i < 10; i++) { Student student = new Student(); student.setName("檀潇斌" + i); student.setAge(18); student.setSex("1"); student.setAddress("安徽省"); studentMapper.insert(student); } }
从执行结果来看,偶数存入student_1,奇数存入student_2
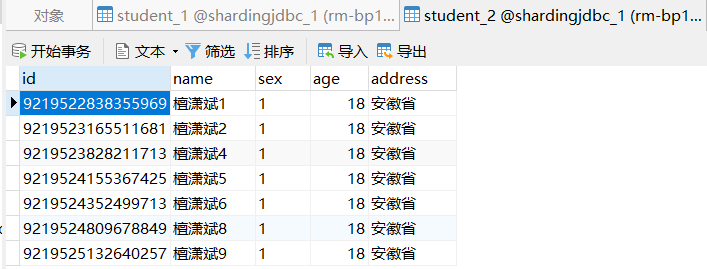
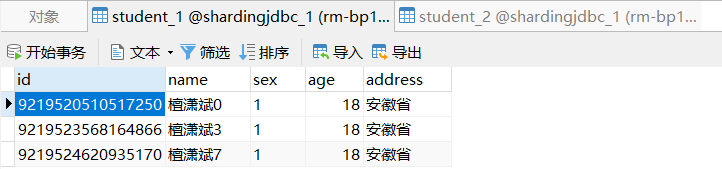
以上为分表策略,接下来看如何配置多个库,配置文件如下。
spring: shardingsphere: datasource: names: m1,m2 m1: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://rm-bp1347i6zmc5iozp59o.mysql.rds.aliyuncs.com:3306/shardingjdbc_1?characterEncoding=utf8&characterSetResults=utf8&autoReconnect=true&failOverReadOnly=false&useSSL=false&serverTimezone=GMT%2B8 username: root password: txb@root m2: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://rm-bp1347i6zmc5iozp59o.mysql.rds.aliyuncs.com:3306/shardingjdbc_2?characterEncoding=utf8&characterSetResults=utf8&autoReconnect=true&failOverReadOnly=false&useSSL=false&serverTimezone=GMT%2B8 username: root password: txb@root sharding: tables: student: actualDataNodes: m$->{1..2}.student_$->{1..2} keyGenerator: column: id type: SNOWFLAKE props: worker: id: 1 # 分库算法 databaseStrategy: inline: shardingColumn: id algorithmExpression: m$->{id % 2 + 1} # 分表算法 tableStrategy: inline: shardingColumn: id algorithmExpression: student_$->{((id + 1) % 4).intdiv(2)} # 打印sql语句 props: sql: show: true
2.2 standard分片算法的使用
当我们 SQL中的分片健字段用到 BETWEEN AND操作符会使用到此算法,会根据 SQL中给出的分片健值范围值处理分库、分表逻辑。编写rangeAlgorithmClassName、preciseAlgorithmClassName、MyRangeDSShardingAlgorithm、MyPreciseDSShardingAlgorithm 类以及yml文件如下。
public class MyRangeTableShardingAlgorithm implements RangeShardingAlgorithm<Long> { /** * * @param availableTargetNames * @param shardingValue 包含逻辑表名、分片列和分片列的条件范围。 * @return 返回目标结果。可以是多个。 */ @Override public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Long> shardingValue) { //实现按照 Between 进行范围分片。 //例如 select * from course where cid between 2000 and 3000; Long lowerEndpoint = shardingValue.getValueRange().lowerEndpoint(); Long upperEndpoint = shardingValue.getValueRange().upperEndpoint();
//实现course_$->{(3000 -2000 )%2+1} 分片策略
return Arrays.asList(shardingValue.getLogicTableName()+"_1",shardingValue.getLogicTableName()+"_2");
}
}
public class MyPreciseTableShardingAlgorithm implements PreciseShardingAlgorithm<Long> { /** * @param availableTargetNames 有效的数据源或表的名字。这里就对应配置文件中配置的数据源信息 * @param shardingValue 包含 逻辑表名、分片列和分片列的值。 * @return 返回目标结果 */ @Override public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) { //实现按照 = 或 IN 进行精确分片。 //例如 select * from course where cid = 1 or cid in (1,3,5) //实现course_$->{cid%2+1} 分表策略 BigInteger shardingValueB = BigInteger.valueOf(shardingValue.getValue()); BigInteger resB = (shardingValueB.mod(new BigInteger("2"))).add(new BigInteger("1")); String key = shardingValue.getLogicTableName()+"_"+resB ; if(availableTargetNames.contains(key)){ return key; } throw new UnsupportedOperationException(" route "+key+" is not supported. please check your config"); } }
public class MyRangeDSShardingAlgorithm implements RangeShardingAlgorithm<Long> { /** * * @param availableTargetNames * @param shardingValue 包含逻辑表名、分片列和分片列的条件范围。 * @return 返回目标结果。可以是多个。 */ @Override public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Long> shardingValue) { //实现按照 Between 进行范围分片。 //例如 select * from course where cid between 2000 and 3000; Long lowerEndpoint = shardingValue.getValueRange().lowerEndpoint(); Long upperEndpoint = shardingValue.getValueRange().upperEndpoint(); //对于我们这个奇偶分离的场景,大部分范围查询都是要两张表都查。 return availableTargetNames; } }
public class MyPreciseDSShardingAlgorithm implements PreciseShardingAlgorithm<Long> { /** * @param availableTargetNames 有效的数据源或表的名字。这里就对应配置文件中配置的数据源信息 * @param shardingValue 包含 逻辑表名、分片列和分片列的值。 * @return 返回目标结果 */ @Override public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) { //实现按照 = 或 IN 进行精确分片。 //例如 select * from course where cid = 1 or cid in (1,3,5) // select * from course where userid- 'xxx'; //实现course_$->{cid%2+1} 分表策略 BigInteger shardingValueB = BigInteger.valueOf(shardingValue.getValue()); BigInteger resB = (shardingValueB.mod(new BigInteger("2"))).add(new BigInteger("1")); String key = "m"+resB ; if(availableTargetNames.contains(key)){ return key; } throw new UnsupportedOperationException(" route "+key+" is not supported. please check your config"); } }
spring: shardingsphere: datasource: names: m1,m2 m1: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://rm-bp1347i6zmc5iozp59o.mysql.rds.aliyuncs.com:3306/shardingjdbc_1?characterEncoding=utf8&characterSetResults=utf8&autoReconnect=true&failOverReadOnly=false&useSSL=false&serverTimezone=GMT%2B8 username: root password: txb@root m2: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://rm-bp1347i6zmc5iozp59o.mysql.rds.aliyuncs.com:3306/shardingjdbc_2?characterEncoding=utf8&characterSetResults=utf8&autoReconnect=true&failOverReadOnly=false&useSSL=false&serverTimezone=GMT%2B8 username: root password: 123456@txb sharding: tables: student: actualDataNodes: m$->{1..2}.student_$->{1..2} keyGenerator: column: id type: SNOWFLAKE props: worker-id: 1 # 分库算法 databaseStrategy: standard: shardingColumn: id rangeAlgorithmClassName: com.txb.algorithm.MyRangeDSShardingAlgorithm preciseAlgorithmClassName: com.txb.algorithm.MyPreciseDSShardingAlgorithm # 分表算法 tableStrategy: standard: shardingColumn: id rangeAlgorithmClassName: com.txb.algorithm.MyRangeTableShardingAlgorithm preciseAlgorithmClassName: com.txb.algorithm.MyPreciseTableShardingAlgorithm # 打印sql语句 props: sql: show: true
2.3 complex分片算法的使用
SQL 语句中有>,>=, <=,<,=,IN 和 BETWEEN AND 等操作符,不同的是复合分片策略支持对多个分片健操作。下面我们实现同时以 order_id、user_id 两个字段作为分片健,自定义复合分片策略。编写MyComplexDSShardingAlgorithm、MyComplexTableShardingAlgorithm类以及yml文件如下。
public class MyComplexDSShardingAlgorithm implements ComplexKeysShardingAlgorithm<Long> { @Override public Collection<String> doSharding(Collection<String> availableTargetNames, ComplexKeysShardingValue<Long> shardingValue) { Collection<Long> cidCol = shardingValue.getColumnNameAndShardingValuesMap().get("id"); List<String> result = new ArrayList<>(); //实现自定义分片逻辑 例如可以自己实现 course_$->{cid%2+1 + (30-20)+1} 这样的复杂分片逻辑 for(Long cid : cidCol){ BigInteger cidI = BigInteger.valueOf(cid); BigInteger target = (cidI.mod(BigInteger.valueOf(2L))).add(new BigInteger("1")); result.add("m"+target); } return result; } }
public class MyComplexTableShardingAlgorithm implements ComplexKeysShardingAlgorithm<Long> { /** * * @param availableTargetNames 目标数据源 或者 表 的值。 * @param shardingValue logicTableName逻辑表名 columnNameAndShardingValuesMap 分片列的精确值集合。 columnNameAndRangeValuesMap 分片列的范围值集合 * @return */ @Override public Collection<String> doSharding(Collection<String> availableTargetNames, ComplexKeysShardingValue<Long> shardingValue) { Collection<Long> cidCol = shardingValue.getColumnNameAndShardingValuesMap().get("id"); List<String> result = new ArrayList<>(); //实现自定义分片逻辑 例如可以自己实现 course_$->{cid%2+1 + (30-20)+1} 这样的复杂分片逻辑 for(Long cid : cidCol){ BigInteger cidI = BigInteger.valueOf(cid); BigInteger target = (cidI.mod(BigInteger.valueOf(2L))).add(new BigInteger("1")); result.add("student_"+target); } return result; } }
spring: shardingsphere: datasource: names: m1,m2 m1: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://rm-bp1347i6zmc5iozp59o.mysql.rds.aliyuncs.com:3306/shardingjdbc_1?characterEncoding=utf8&characterSetResults=utf8&autoReconnect=true&failOverReadOnly=false&useSSL=false&serverTimezone=GMT%2B8 username: root password: txb@root m2: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://rm-bp1347i6zmc5iozp59o.mysql.rds.aliyuncs.com:3306/shardingjdbc_2?characterEncoding=utf8&characterSetResults=utf8&autoReconnect=true&failOverReadOnly=false&useSSL=false&serverTimezone=GMT%2B8 username: root password: 123456@txb sharding: tables: student: actualDataNodes: m$->{1..2}.student_$->{1..2} keyGenerator: column: id type: SNOWFLAKE props: worker-id: 1 # 分库算法 databaseStrategy: complex: shardingColumns: id algorithmClassName: com.txb.algorithm.MyComplexDSShardingAlgorithm # 分表算法 tableStrategy: complex: shardingColumns: id,name algorithmClassName: com.txb.algorithm.MyComplexTableShardingAlgorithm # 打印sql语句 props: sql: show: true
2.4 hint分片算法的使用
行表达式分片策略(InlineShardingStrategy),在配置中使用 Groovy 表达式,提供对 SQL语句中的 = 和 IN 的分片操作支持,它只支持单分片健。行表达式分片策略适用于做简单的分片算法,无需自定义分片算法,省去了繁琐的代码开发,是几种分片策略中最为简单的。编写MyHintDSShardingAlgorithm、MyHintTableShardingAlgorithm类以及yml文件如下。
public class MyHintDSShardingAlgorithm implements HintShardingAlgorithm<Integer> { /** * * @param availableTargetNames 可选 数据源 和 表 的名称 * @param shardingValue * @return */ @Override public Collection<String> doSharding(Collection<String> availableTargetNames, HintShardingValue<Integer> shardingValue) { // 对SQL的零侵入分片方案。shardingValue是通过HintManager. // 比如我们要实现将 select * from t_user where user_id in {1,2,3,4,5,.....}; 按照in的第一个值,全部路由到course_1表中。 // 注意他使用时有非常多的限制。 return Arrays.asList("m1","m2"); } }
public class MyHintTableShardingAlgorithm implements HintShardingAlgorithm<Integer> { /** * * @param availableTargetNames 可选 数据源 和 表 的名称 * @param shardingValue * @return */ @Override public Collection<String> doSharding(Collection<String> availableTargetNames, HintShardingValue<Integer> shardingValue) { // 对SQL的零侵入分片方案。shardingValue是通过HintManager. // 比如我们要实现将 select * from t_user where user_id in {1,2,3,4,5,.....}; 按照in的第一个值,全部路由到course_1表中。 // 注意他使用时有非常多的限制。 String key = "student_"+shardingValue.getValues().toArray()[0]; if(availableTargetNames.contains(key)){ return Arrays.asList(key); } throw new UnsupportedOperationException(" route "+key+" is not supported. please check your config"); } }
spring: shardingsphere: datasource: names: m1,m2 m1: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://rm-bp1347i6zmc5iozp59o.mysql.rds.aliyuncs.com:3306/shardingjdbc_1?characterEncoding=utf8&characterSetResults=utf8&autoReconnect=true&failOverReadOnly=false&useSSL=false&serverTimezone=GMT%2B8 username: root password: 123456@txb m2: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://rm-bp1347i6zmc5iozp59o.mysql.rds.aliyuncs.com:3306/shardingjdbc_2?characterEncoding=utf8&characterSetResults=utf8&autoReconnect=true&failOverReadOnly=false&useSSL=false&serverTimezone=GMT%2B8 username: root password: txb@root sharding: tables: student: actualDataNodes: m$->{1..2}.student_$->{1..2} keyGenerator: column: id type: SNOWFLAKE props: worker-id: 1 # 分库算法 databaseStrategy: hint: shardingColumns: id algorithmClassName: com.txb.algorithm.MyHintDSShardingAlgorithm # 分表算法 tableStrategy: hint: shardingColumns: id,name algorithmClassName: com.txb.algorithm.MyHintTableShardingAlgorithm # 打印sql语句 props: sql: show: true
3. ShardingJDBC其他分片算法
3.1 broadcast-tables广播表策略
在实际业务中有的表在不同的数据库中都需要,例如数据字典表dict,因此在dict表中需要都插入数据,此时便用到广播表策略,实际使用过程如下,我们在shardingjdbc_1数据库与shardingjdbc_2数据库中创建dict表。
CREATE TABLE `dict` ( `id` bigint NOT NULL, `key_data` char(1) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL, `value_data` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;
创建字段表的实体类与mapper,再配置yml文件如下。
spring: shardingsphere: datasource: names: m1,m2 m1: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://rm-bp1347i6zmc5iozp59o.mysql.rds.aliyuncs.com:3306/shardingjdbc_1?characterEncoding=utf8&characterSetResults=utf8&autoReconnect=true&failOverReadOnly=false&useSSL=false&serverTimezone=GMT%2B8 username: root password: 123456@txb m2: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://rm-bp1347i6zmc5iozp59o.mysql.rds.aliyuncs.com:3306/shardingjdbc_2?characterEncoding=utf8&characterSetResults=utf8&autoReconnect=true&failOverReadOnly=false&useSSL=false&serverTimezone=GMT%2B8 username: root password: 123456@txb sharding: tables: dict: actualDataNodes: m$->{1..2}.dict_$->{1..2} keyGenerator: column: id type: SNOWFLAKE props: worker-id: 1 # 广播表 broadcast-tables: - dict # 打印sql语句 props: sql: show: true
这时,写一个测试类,插入两条数据,会发现两个库的两张表里面都有相同的数据,而且此时该表就算配上其他策略也不会生效。
@Test public void dictInsert(){ Dict dict1 = new Dict(); dict1.setKeyData("1"); dict1.setValueData("正常"); dictMapper.insert(dict1); Dict dict2 = new Dict(); dict2.setKeyData("2"); dict2.setValueData("异常"); dictMapper.insert(dict2); }
3.2 binding-tables绑定表策略
对于多表关联查询需要用到此策略,如果不使用此策略会出现冗余数据,下面进行举例说明,分别在shardingjdbc_1和shardingjdbc_2中添加表user_1和user_2,dict_1和dict_2。
CREATE TABLE `dict_1` ( `id` bigint NOT NULL, `key_data` char(1) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL, `value_data` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL, `status` char(1) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3; CREATE TABLE `user_1` ( `id` bigint NOT NULL, `dict_id` bigint DEFAULT NULL, `name` varchar(255) DEFAULT NULL, `status` char(1) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;
先使用基本inline策略将一些数据插入表中。
spring: shardingsphere: datasource: names: m1,m2 m1: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://rm-bp1347i6zmc5iozp59o.mysql.rds.aliyuncs.com:3306/shardingjdbc_1?characterEncoding=utf8&characterSetResults=utf8&autoReconnect=true&failOverReadOnly=false&useSSL=false&serverTimezone=GMT%2B8 username: root password: 123456@txb m2: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://rm-bp1347i6zmc5iozp59o.mysql.rds.aliyuncs.com:3306/shardingjdbc_2?characterEncoding=utf8&characterSetResults=utf8&autoReconnect=true&failOverReadOnly=false&useSSL=false&serverTimezone=GMT%2B8 username: root password: 123456@txb sharding: tables: dict: actualDataNodes: m$->{1..2}.dict_$->{1..2} keyGenerator: column: id type: SNOWFLAKE props: worker-id: 1 databaseStrategy: inline: shardingColumn: status algorithmExpression: m$->{status} tableStrategy: inline: shardingColumn: status algorithmExpression: dict_$->{status} user: actualDataNodes: m$->{1..2}.user_$->{1..2} keyGenerator: column: id type: SNOWFLAKE props: worker-id: 1 databaseStrategy: inline: shardingColumn: status algorithmExpression: m$->{status} tableStrategy: inline: shardingColumn: status algorithmExpression: user_$->{status} # 打印sql语句 props: sql: show: true
@Test public void dictInsert(){ Dict dict1 = new Dict(); dict1.setKeyData("1"); dict1.setValueData("正常"); dict1.setStatus("1"); dictMapper.insert(dict1); Dict dict2 = new Dict(); dict2.setKeyData("2"); dict2.setValueData("异常"); dict2.setStatus("2"); dictMapper.insert(dict2); } @Test public void addUser(){ for (int i = 0; i < 10; i++) { User user = new User(); user.setName(i+ ""); user.setStatus((i % 2 + 1) + ""); userMapper.insert(user); } }
插入成功后,我们进行以status为关联字段的连表查询
@Select("select u.id,u.name,d.value_data status from user u left join dict d on d.status = u.status") public List<User> queryUser();
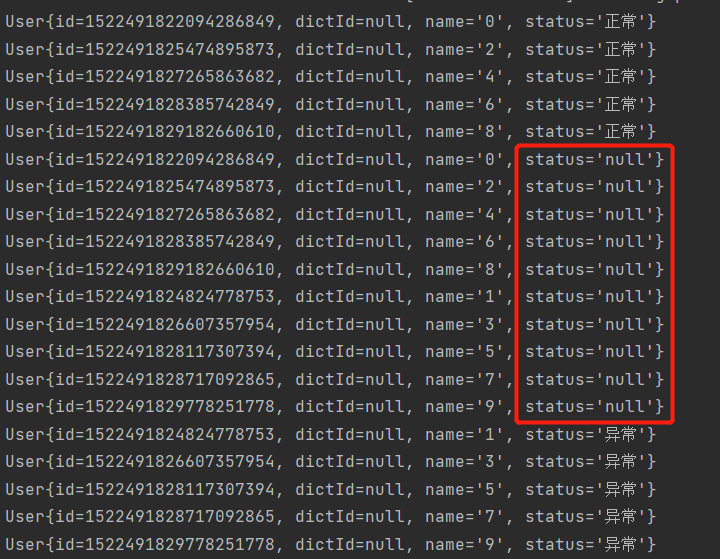
会发现查询出的数据中有status为空的,这是因为这两张表做了笛卡尔积进行关联,接下来我们看下使用绑定表策略之后的结果。
sharding: binding-tables: - user,dict
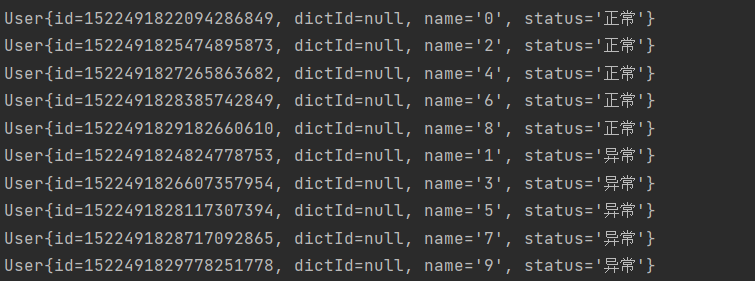
由此可见,使用绑定表策略之后,真正做到了分表后的关联查询。
3.3 master-slave-rules读写分离策略
shardingjdbc提供了业务上的读写分离策略,即写入使用主表,读取使用从表,具体配置如下。
spring: shardingsphere: datasource: names: m1,m2 m1: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://rm-bp1347i6zmc5iozp59o.mysql.rds.aliyuncs.com:3306/shardingjdbc_1?characterEncoding=utf8&characterSetResults=utf8&autoReconnect=true&failOverReadOnly=false&useSSL=false&serverTimezone=GMT%2B8 username: root password: 123456@txb m2: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://rm-bp1347i6zmc5iozp59o.mysql.rds.aliyuncs.com:3306/shardingjdbc_2?characterEncoding=utf8&characterSetResults=utf8&autoReconnect=true&failOverReadOnly=false&useSSL=false&serverTimezone=GMT%2B8 username: root password: 123456@txb sharding: # 主从配置 master-slave-rules: ds0: masterDataSourceName: m1 slaveDataSourceNames: - m2 tables: dict: actualDataNodes: ds0.dict keyGenerator: column: id type: SNOWFLAKE props: worker-id: 1 # 打印sql语句 props: sql: show: true
此时,使用插入语句会发现实际执行的表均为dict_1,而使用查询语句实际执行的表均为dict_2。需要注意的是真正意义上的读写分离需要mysql自己的主从机制来实现,shardingjdbc只做sql语句的转发者。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号