
视觉SLAM开端
SLAM是Simultaneous Localization and Mapping 的缩写,译为“同时定位与地图构建”,当看到专业术语还是有点蒙的,用白话来说就是自己的位置和自己周围的环境。
自己的位置--定位
周围的环境--地图构建
而SLAM的目的是解决‘定位’和‘地图构建’这两个问题,也就是说一边估计自身的位置,一边要建立周围环境的模型。
简单的说了一下SLAM的理解,接下来解剖SLAM框架
我学习视觉SLAM用的RGB-D深度摄像头,普及一下摄像头
相机可分为:单目相机、双目相机、深度相机三大类
1.单目相机
单目相机只用一个摄像头拍摄照片,而照片本质上是在相机的成像平面上留下的一个投影,它以二维的形式记录了三维的世界,但是在这个过程丢掉了场景的一个维度-深度。
在单目相机中,我们无法通过单张图片计算场景中与相机之间的距离,在SLAM中将是非常重要的信息,由于单目相机拍摄的图像只是三维空间的二维投影,如果想恢复三维结构,
必须改变相机的视角,在单目SLAM中必须移动相机,这些物体在图像上的运动就形成了视差,就可以定量地判断物体离的远近,但这只是一个相对的值,而无法凭借图像确定这个
真实的尺度。
2.双目相机
双目相机由两个单目相机组成,但这两个相机之间的距离(称为基线)是已知的,我们就可以通过这个基线来估计每个像素的空间位置。就能够知道物体的远近,但是双目相机还是有缺点的
需要大量的计算才能估计每一个像素点的深度,双目相机测量的深度范围与基线有很大关系,基线距离越大测量的物体就越远。双目相机的距离估计是比较左右眼的图像获得的,并不依赖于其他
设备,既能应用在室内,又可应用于室外。但是双目和多目相机的缺点是配置和标定,其深度量程和精度受双目的基线与分辨率所限,而且视差的计算非常消耗计算资源。
3.深度相机
RGB-D深度摄像头最大的特点是可以通过红外结构光或(TOF)原理,主动向物体发射光并接收返回的光,测出物体与相机之间的距离。
不过在视觉SLAM方面主要用于室内。室外则难应用。
废话说的有点多了,开始解剖SLAM框架了
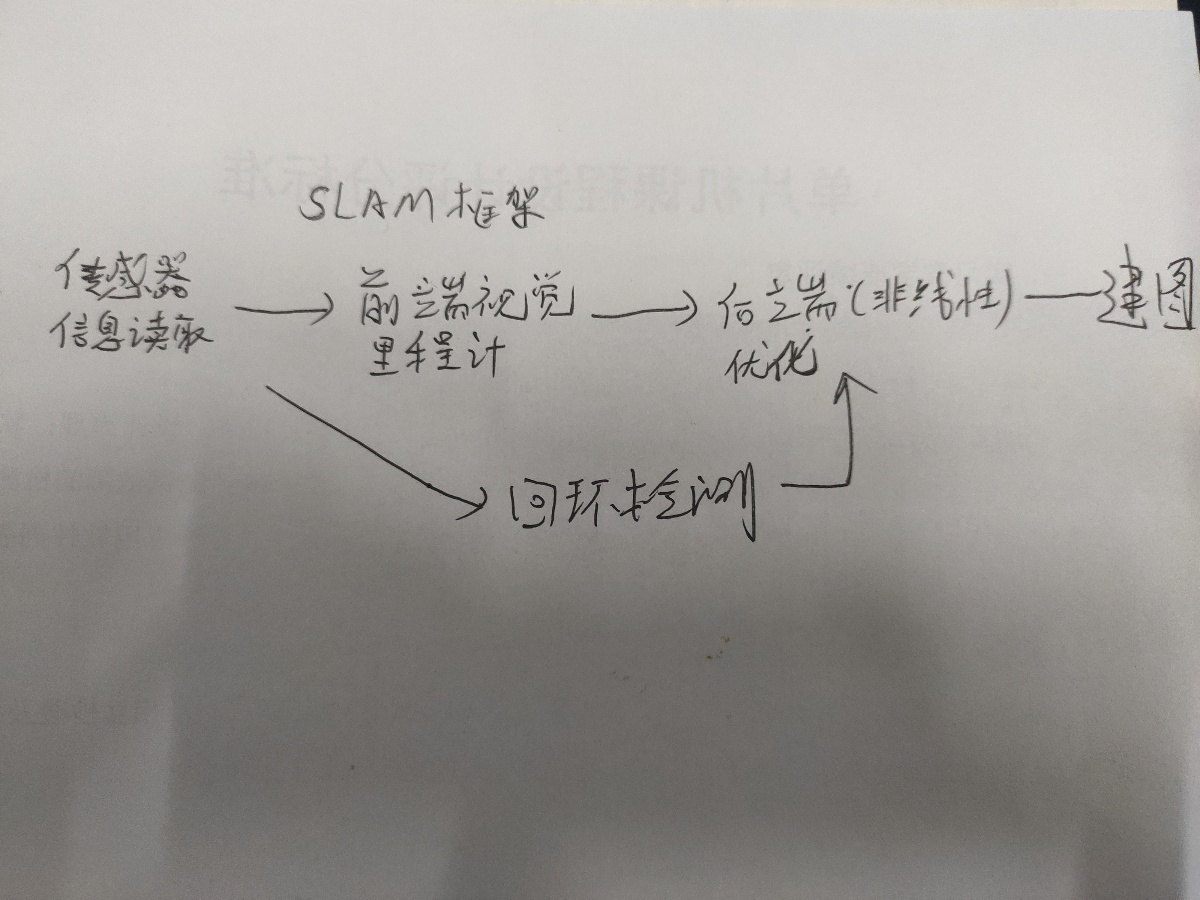
SALM可大致分为以下几个模块
1.传感器信息读取:在视觉SLAM中主要为相机图像信息的读取和预处理,如果是在机器人中,其他传感器等其他信息的读取和同步。
2.前端视觉里程计(Visual Odometry),视觉里程计的任务是估算相邻图像之间相机的运动,最简单的就是两张图像之间的运动关系,视觉里程计估计两张图像间的相机运动,
一方面只要把相邻时刻的运动“串”起来。构建了机器人的运动轨迹,解决了定位问题,另一方面根据每个时刻的相机位置,计算出各像素对应的空间点的位置,就得到地图。
这样一来有了视觉里程计就可以解决SLAM问题了吗,然而,仅通过视觉里程计来估计轨迹,将不可避免出现的累积漂移。这是由于视觉里程计在最简单的只估计两张图像间的运动
造成的,例如机器人先向左转90度,再向右转90度,由于误差,把第一次的90度估计成了88度,再右转机器人并未回到原点,累计下来就形成了累积漂移,接下来就需要
“后端优化”和“回环检测”去解决了,回环检测负责把“机器人回到原始位置”的事情检测出来,而后端优化则根据该信息,校正整个轨迹的形状。
3。回环检测:主要解决位置估计随时间漂移的问题,回环检测判断机器人的是否到达先前的位置,如果检测到回环,就会把相应的信息告诉后端优化,然后根据这些新的信息,把
轨迹和地图调整到符合回环检测结果的样子
4.后端优化:后端优化更多的是处理SLAM过程中的噪声问题,当我们获得的前端数据时,这些数据都会带有一些噪声,根据传感器的精度决定着误差的大小,传感器受到很多因素的
影响,当我们在传输数据时,相应的噪声也会传输到下一时刻,而后端优化考虑的问题就是如何从这些带有噪声的数据中估计整个系统的状态,以及这个状态估计的不确定性有多大--
称为最大后验概率估计,然后进行数据的优化,主要是滤波和非线性优化算法。
5.建图:对于建图,其实就是根据前面估计的状态,建立和要求对应的地图。
到这里就基本上解决了SLAM两大问题,SLAM框架大致就是这个样子
刚刚学习,可以一起交流哦。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号