第一次个人编程作业
论文查重
Github链接
下面介绍一下大致流程图

一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 80 | 80 |
| Estimate | 估计这个任务需要多少时间 | 1500 | 1860 |
| Development | 开发 | 1400 | 1600 |
| Analysis | 需求分析 (包括学习新技术) | 240 | 270 |
| Design Spec | 生成设计文档 | 90 | 120 |
| Design Review | 设计复审 | 60 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 90 | 60 |
| Design | 具体设计 | 180 | 150 |
| Coding | 具体编码 | 600 | 900 |
| Code Review | 代码复审 | 60 | 90 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 90 |
| Reporting | 报告 | 120 | 180 |
| Test Repor | 测试报告 | 60 | 120 |
| Size Measurement | 计算工作量 | 30 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 1560 | 1920 |
二、计算模块接口的设计与实现过程
-
算法简述
一看到题目,仿佛看见了一座不可逾越的大山,开始了一天面向百度的程序设计。。。
simhash算法分为5个步骤:分词、hash、加权、合并、降维,具体过程如下所述:
(1)分词
给定一段语句,进行分词,得到有效的特征向量,然后为每一个特征向量设置1-5等5个级别的权重(如果是给定一个文本,那么特征向量可以是文本中的词,其权重可以是这个词出现的次数)。例如给定一段语句:“CSDN博客结构之法算法之道的作者July”,分词后为:“CSDN 博客 结构 之 法 算法 之 道 的 作者 July”,然后为每个特征向量赋予权值:CSDN(4) 博客(5) 结构(3) 之(1) 法(2) 算法(3) 之(1) 道(2) 的(1) 作者(5) July(5),其中括号里的数字代表这个单词在整条语句中的重要程度,数字越大代表越重要。
(2)hash
通过hash函数计算各个特征向量的hash值,hash值为二进制数01组成的n-bit签名。比如“CSDN”的hash值Hash(CSDN)为100101,“博客”的hash值Hash(博客)为“101011”。就这样,字符串就变成了一系列数字。
(3)加权
在hash值的基础上,给所有特征向量进行加权,即W = Hash * weight,且遇到1则hash值和权值正相乘,遇到0则hash值和权值负相乘。例如给“CSDN”的hash值“100101”加权得到:W(CSDN) = 100101 4 = 4 -4 -4 4 -4 4,给“博客”的hash值“101011”加权得到:W(博客)=101011 5 = 5 -5 5 -5 5 5,其余特征向量类似此般操作。
(4)合并
将上述各个特征向量的加权结果累加,变成只有一个序列串。拿前两个特征向量举例,例如“CSDN”的“4 -4 -4 4 -4 4”和“博客”的“5 -5 5 -5 5 5”进行累加,得到“4+5 -4+-5 -4+5 4+-5 -4+5 4+5”,得到“9 -9 1 -1 1”。
(5)降维
对于n-bit签名的累加结果,如果大于0则置1,否则置0,从而得到该语句的simhash值,最后我们便可以根据不同语句simhash的海明距离来判断它们的相似度。例如把上面计算出来的“9 -9 1 -1 1 9”降维(某位大于0记为1,小于0记为0),得到的01串为:“1 0 1 0 1 1”,从而形成它们的simhash签名。
三、计算机接口部分的性能改善
1.关键代码
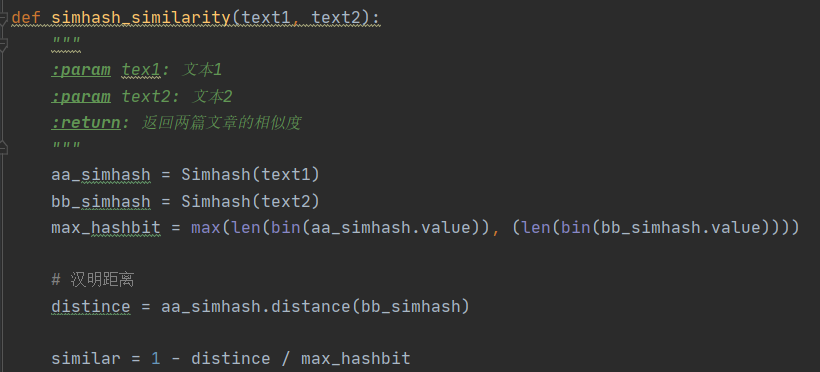
2.测试代码

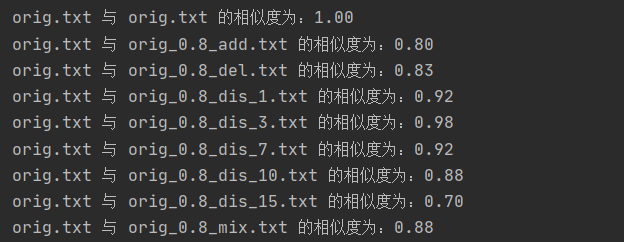
3.测试结果展示
4.性能分析
(1)数据展示
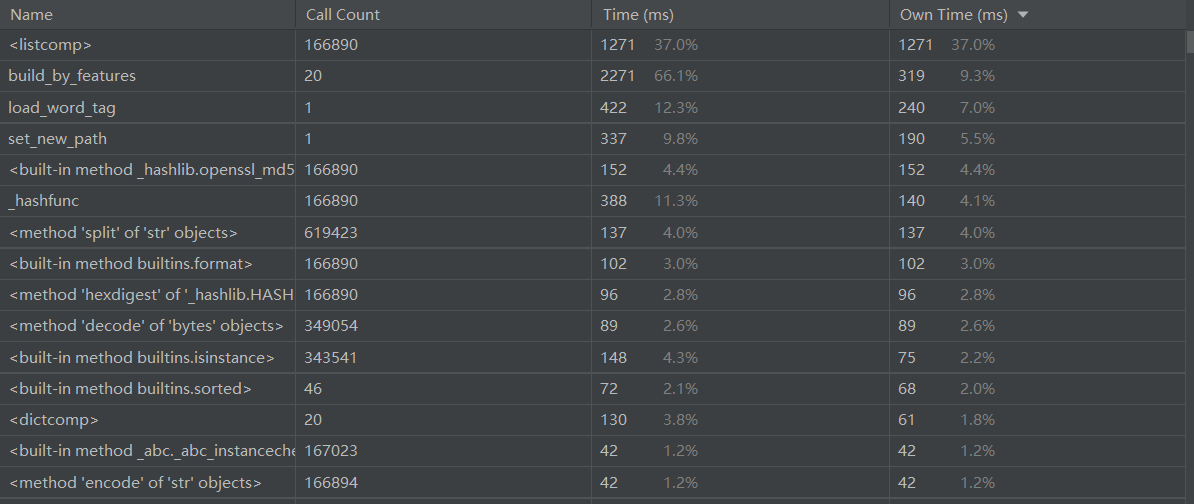
(2)调用关系图
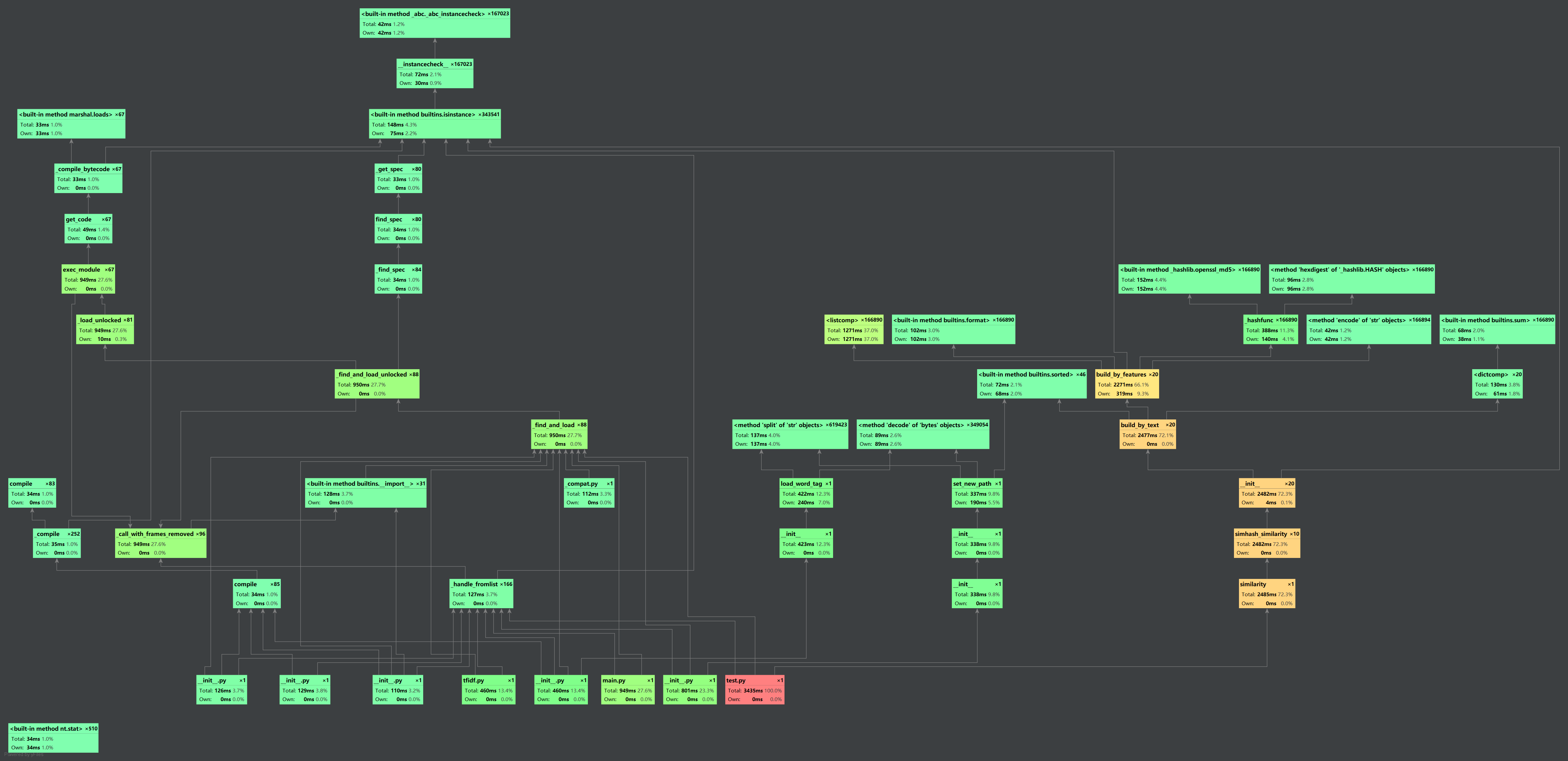
(3)消耗最大
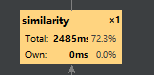
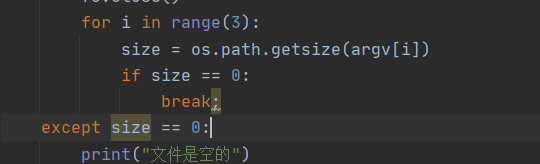
四、异常部分说明
写了一个简单实用的异常测试。
五、总结
本次面向百度的编程个人感觉还是不错的,锻炼了自己的自学能力,在自学的过程中也发现了许多不足,发际线又上移了很明显又变强了。在写博客的过程中又一次回顾了内容,加深了对代码的理解,以后可以多采用这种办法提升一下自己。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号