第六章 图 学习小结
第六章知识点总结
图是由一个顶点集V和一个边集E构成的数据结构。
图的基于邻接矩阵的结构定义


1 //用两个数组分别存储顶点表和邻接矩阵 2 const int MVNum = 100; //最大顶点数 3 typedef char VerTexType; /假设顶点的数据类型为字符型 4 typedef int ArcType; //假设边的权值类型为整型 5 typedef struct{ 6 VerTexType vexs[MVNum]; //顶点表 7 ArcType arcs[MVNum][MVNum]; //邻接矩阵 8 int vexnum,arcnum; //图的当前点数和边数 9 }AMGraph;
邻接矩阵与邻接表表示法的关系
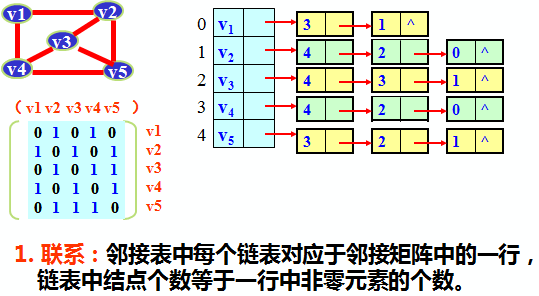
邻接表中顶点的结构:

1 typedef struct { 2 VerTexType data; // 顶点信息 3 ArcNode *firstarc; 4 // 指向第一条依附该顶点的弧 5 } VNode, AdjList[MVNUM];
邻接表中邻接点的结构

1 typedef struct ArcNode { 2 int adjvex; //该边所指向的顶点的位置 3 struct ArcNode *nextarc; //指向下一条边的指针 4 OtherInfo info; //和边相关的信息,例如权值 5 } ArcNode
图的基于邻接表的结构定义
1 typedef struct { 2 AdjList vertices; 3 int vexnum, arcnum; 4 //顶点数和边数 5 } ALGraph
图的遍历:
(也是一种递归调用)
1:深度优先搜索:(DFS)
即先纵向访问,访问到底了再回来
2:广度优先搜索:(BFS)
即横先搜索,搜索完一层再到下一层,不会往回走。
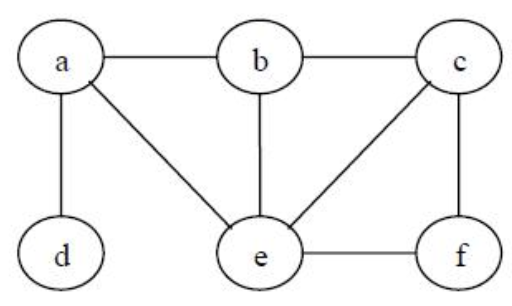
顶点a出发的深度优先遍历顺序(不唯一):
a b c f e d
顶点a出发的广度优先遍历顺序(不唯一):
a b e d c f
图的应用:
最小生成树:
1:普里姆算法:(选顶点)(适合稠密网)
我的理解:选一个顶点,然后在它的邻接顶点中选择权值最小的,做下一个顶点,直到下一个顶点是被选过的,然后沿原路返回,继续寻找没访问过的权值最小的顶点,直到全部顶点被访问完。

2:克鲁斯卡尔算法:(选边)(适合稀疏网)
(1) 先把权值从小到大排列
(2) 每个顶点自成一个联通分量,成一个集合T
(3) 选择两个权值最小的联通分量,若他们不形成回路,则结合成新的联通分量,删了结合前的,把结合后的加入集合T
(4) 直到所有顶点都在一条联通分量上即结束。
本周反思:对于关于图的应用,基本定义能理解,但是对于代码如何实现算法思想还不是很理解,应用在具体问题还是有点难度,PTA的作业还没写完,希望下周能熟练应用图的方法思想去解题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号