

利用IDEA构建springboot应用-如何优雅的使用mybatis
orm框架的本质是简化编程中操作数据库的编码
- 一个是宣称可以不用写一句SQL的hibernate,
- 一个是可以灵活调试动态sql的mybatis
mybatis-spring-boot-starter
mybatis-spring-boot-starter主要有两种解决方案,
一种是使用注解解决一切问题,
一种是简化后的老传统。
当然任何模式都需要首先引入mybatis-spring-boot-starter的pom文件
无配置文件注解版
1 添加相关maven文件
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.1.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
2、application.properties 添加相关配置
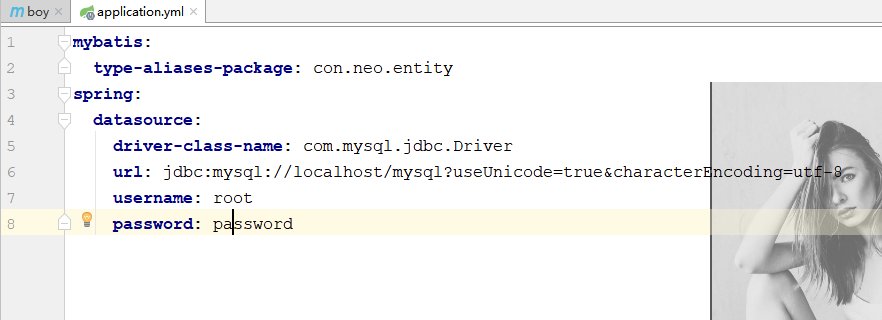
springboot会自动加载spring.datasource.*相关配置,数据源就会自动注入到sqlSessionFactory中,sqlSessionFactory会自动注入到Mapper中,对了你一切都不用管了,直接拿起来使用就行了。
在启动类中添加对mapper包扫描@MapperScan
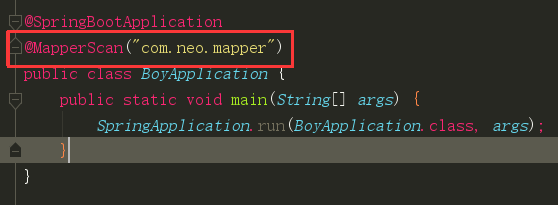
或者直接在Mapper类上面添加注解@Mapper,建议使用上面那种,不然每个mapper加个注解也挺麻烦的
3、开发Mapper
第三步是最关键的一块,sql生产都在这里
package com.neo.mapper; import org.apache.ibatis.annotations.*; import java.util.List; public interface UserMapper { @Select("SELECT * FROM users") @Results({ @Result(property = "userSex", column = "user_sex", javaType = UserSexEnum.class), @Result(property = "nickName", column = "nick_name") }) List<UserEntity> getAll(); @Select("SELECT * FROM users WHERE id = #{id}") @Results({ @Result(property = "userSex", column = "user_sex", javaType = UserSexEnum.class), @Result(property = "nickName", column = "nick_name") }) UserEntity getOne(Long id); @Insert("INSERT INTO users(userName,passWord,user_sex) VALUES(#{userName}, #{passWord}, #{userSex})") void insert(UserEntity user); @Update("UPDATE users SET userName=#{userName},nick_name=#{nickName} WHERE id =#{id}") void update(UserEntity user); @Delete("DELETE FROM users WHERE id =#{id}") void delete(Long id); }
为了更接近生产我特地将user_sex、nick_name两个属性在数据库加了下划线和实体类属性名不一致,另外user_sex使用了枚举
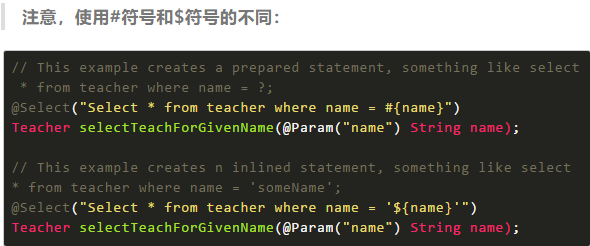
@Select 是查询类的注解,所有的查询均使用这个
@Result 修饰返回的结果集,关联实体类属性和数据库字段一一对应,如果实体类属性和数据库属性名保持一致,就不需要这个属性来修饰。
@Insert 插入数据库使用,直接传入实体类会自动解析属性到对应的值
@Update 负责修改,也可以直接传入对象
@delete 负责删除
4、使用
上面三步就基本完成了相关dao层开发,使用的时候当作普通的类注入进入就可以了
极简xml版本
极简xml版本保持映射文件的老传统,优化主要体现在不需要实现dao的是实现层,系统会自动根据方法名在映射文件中找对应的sql.
1、配置
pom文件和上个版本一样,只是application.yml新增以下配置
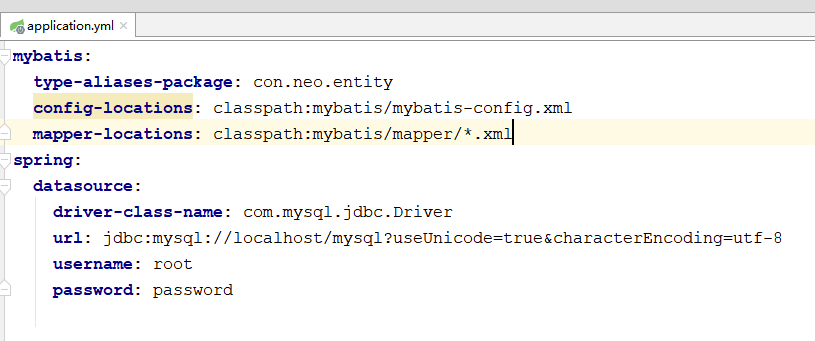
指定了mybatis基础配置文件和实体类映射文件的地址
mybatis-config.xml 配置
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<typeAliases>
<typeAlias alias="Integer" type="java.lang.Integer" />
<typeAlias alias="Long" type="java.lang.Long" />
<typeAlias alias="HashMap" type="java.util.HashMap" />
<typeAlias alias="LinkedHashMap" type="java.util.LinkedHashMap" />
<typeAlias alias="ArrayList" type="java.util.ArrayList" />
<typeAlias alias="LinkedList" type="java.util.LinkedList" />
</typeAliases>
</configuration>
这里也可以添加一些mybatis基础的配置
2、添加User的映射文件
其实就是把上个版本中mapper的sql搬到了这里的xml中了
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.neo.mapper.UserMapper">
<resultMap id="id" type="">
<id column="id" property="id" jdbcType="BIGINT" />
<result column="userName" property="userName" jdbcType="VARCHAR" />
<result column="passWord" property="passWord" jdbcType="VARCHAR" />
<result column="user_sex" property="userSex" javaType="com.neo.enums.UserSexEnum"/>
<result column="nick_name" property="nickName" jdbcType="VARCHAR" />
</resultMap>
<sql id="Base_Column_List" >
id, userName, passWord, user_sex, nick_name
</sql>
<select id="getAll" resultMap="BaseResultMap" >
SELECT
<include refid="Base_Column_List" />
FROM users
</select>
<select id="getOne" parameterType="java.lang.Long" resultMap="BaseResultMap" >
SELECT
<include refid="Base_Column_List" />
FROM users
WHERE id = #{id}
</select>
<insert id="insert" parameterType="com.neo.entity.UserEntity" >
INSERT INTO
users
(userName,passWord,user_sex)
VALUES
(#{userName}, #{passWord}, #{userSex})
</insert>
<update id="update" parameterType="com.neo.entity.UserEntity" >
UPDATE
users
SET
<if test="userName != null">userName = #{userName},</if>
<if test="passWord != null">passWord = #{passWord},</if>
nick_name = #{nickName}
WHERE
id = #{id}
</update>
<delete id="delete" parameterType="java.lang.Long" >
DELETE FROM
users
WHERE
id =#{id}
</delete>
</mapper>
3、编写Dao层的代码
package com.neo.mapper;
import com.neo.entity.UserEntity;
import com.neo.enums.UserSexEnum;
import org.apache.ibatis.annotations.*;
import java.util.List;
public interface UserMapper {
List<UserEntity> getAll();
UserEntity getOne(Long id);
void insert(UserEntity user);
void update(UserEntity user);
void delete(Long id);
}
对比上一步这里全部只剩了接口方法
如何选择
两种模式各有特点,注解版适合简单快速的模式,其实像现在流行的这种微服务模式,一个微服务就会对应一个自已的数据库,多表连接查询的需求会大大的降低,会越来越适合这种模式。
老传统模式比适合大型项目,可以灵活的动态生成SQL,方便调整SQL,也有痛痛快快,洋洋洒洒的写SQL的感觉。
