

利用IDEA构建springboot应用-数据库操作(Mysql)
Spring-Date-Jpa
定义了一系列对象持久化的标准 例如Hibernate,TopLink等 spring data jpa让我们解脱了DAO层的操作,基本上所有CRUD都可以依赖于它来实现
注意:JPA是一套规范,不是一套产品,那么像Hibernate,TopLink,JDO他们是一套产品,如果说这些产品实现了这个JPA规范,那么我们就可以叫他们为JPA的实现产品
(一)预先生成方法
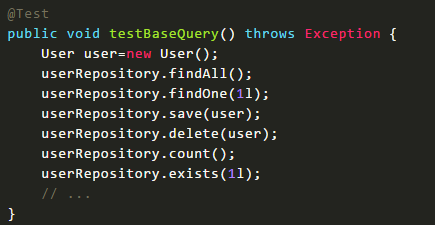
spring data jpa 默认预先生成了一些基本的CURD的方法,例如:增、删、改等等
1 继承JpaRepository

2 使用默认方法
(二)自定义简单查询
自定义的简单查询就是根据方法名来自动生成SQL,主要的语法是findXXBy,readAXXBy,queryXXBy,countXXBy, getXXBy后面跟属性名称:

也使用一些加一些关键字And、 Or

修改、删除、统计也是类似语法

基本上SQL体系中的关键词都可以使用,例如:LIKE、 IgnoreCase、 OrderBy。

(三)复杂查询
分页查询
分页查询在实际使用中非常普遍了,spring data jpa已经帮我们实现了分页的功能,在查询的方法中,需要传入参数Pageable
,当查询中有多个参数的时候Pageable建议做为最后一个参数传入

Pageable 是spring封装的分页实现类,使用的时候需要传入页数、每页条数和排序规则

限制查询
有时候我们只需要查询前N个元素,或者支取前一个实体。
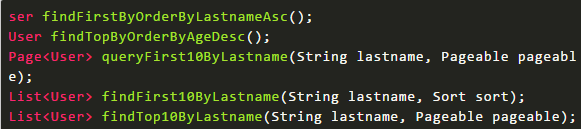
自定义SQL查询
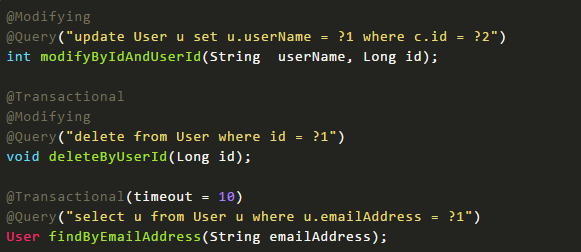
其实Spring data 觉大部分的SQL都可以根据方法名定义的方式来实现,但是由于某些原因我们想使用自定义的SQL来查询,spring data也是完美支持的;在SQL的查询方法上面使用@Query注解,如涉及到删除和修改在需要加上@Modifying.也可以根据需要添加 @Transactional 对事物的支持,查询超时的设置等
多表查询
多表查询在spring data jpa中有两种实现方式,第一种是利用hibernate的级联查询来实现,第二种是创建一个结果集的接口来接收连表查询后的结果,这里主要第二种方式。
首先需要定义一个结果集的接口类。
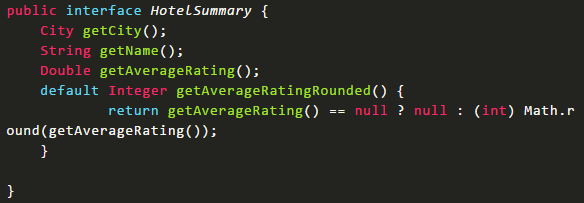
查询的方法返回类型设置为新创建的接口
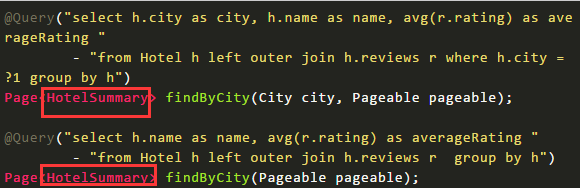
使用

在运行中Spring会给接口(HotelSummary)自动生产一个代理类来接收返回的结果,代码汇总使用getXX的形式来获取
(四)多数据源的支持
同源数据库的多源支持
日常项目中因为使用的分布式开发模式,不同的服务有不同的数据源,常常需要在一个项目中使用多个数据源,因此需要配置sping data jpa对多数据源的使用,一般分一下为三步:
-
1 配置多数据源
-
2 不同源的实体类放入不同包路径
-
3 声明不同的包路径下使用不同的数据源、事务支持
异构数据库多源支持
比如我们的项目中,即需要对mysql的支持,也需要对mongodb的查询等。
实体类声明@Entity 关系型数据库支持类型、声明@Document 为mongodb支持类型,不同的数据源使用不同的实体就可以了
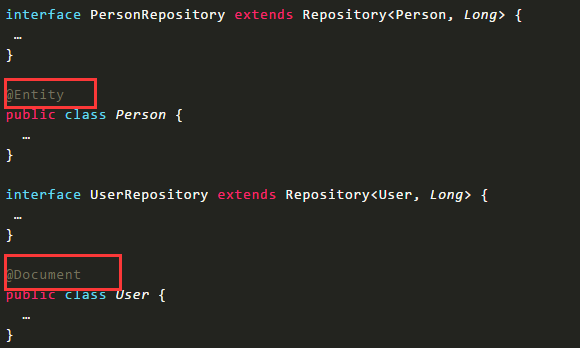
但是,如果User用户既使用mysql也使用mongodb呢,也可以做混合使用

也可以通过对不同的包路径进行声明,比如A包路径下使用mysql,B包路径下使用mongoDB

其它
使用枚举
使用枚举的时候,我们希望数据库中存储的是枚举对应的String类型,而不是枚举的索引值,需要在属性上面添加@Enumerated(EnumType.STRING) 注解

不需要和数据库映射的属性
正常情况下我们在实体类上加入注解@Entity,就会让实体类和表相关连如果其中某个属性我们不需要和数据库来关联只是在展示的时候做计算,只需要加上@Transient属性既可。

源码案例
这里有一个开源项目几乎使用了这里介绍的所有标签和布局,大家可以参考:https://github.com/cloudfavorites/favorites-web
RESTful API设计
| 请求类型 | 请求路径 | 功能 |
| GET | /girls | 获取女生列表 |
| POST | /girls | 创建一个女生 |
| GET | /girls/id | 通过id查询一个女生 |
| PUT | /girls/id | 通过id更新一个女生 |
| DELETE | /girls/id | 通过id删除一个女生 |
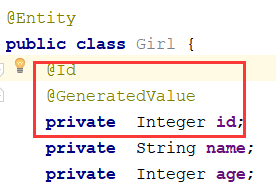
@Entity 表示对应数据库那张表
@Id
@GeneratedValue 表示自增
create //删除表创建新表
update //更新当前表的内容
create-drop //应用停下来 删除表
validate //验证表中数据是否一致
none //什么都不干

