CS:APP Chapter 7 链接-读书笔记
Chapter-7 链接
我们常说的事情,计算机里的一切都是二进制数据,不管是你看到的像素,或者是你硬盘上的文件,正在执行的程序,你所倾听的音乐,在计算机里都是一串 010101 字符,再本质一点,他们就是一连串高低电平的组合。
但是,它们是如此的相似,而又如此的不同。就像大众给他们的分类一般,有的是程序,有的是音乐,有的是视频,是图片,那他们的区别何在,那就是计算机系统对待他们的方式不同!程序,又可以称之为可执行程序,在系统给定的特定上下文中执行的一段代码,众所周知,程序大多是由程序员创造出来的(也有很多不是,例如自动生成的模板代码,Low Code 平台生成的代码等等),那么程序,是怎样从普通的代码文本文件,变成一个可执行的程序?
计算机系统不能够直接执行 hello.c 文件,因为他不是一个可执行程序。让源代码变成程序的过程是有趣且复杂的。
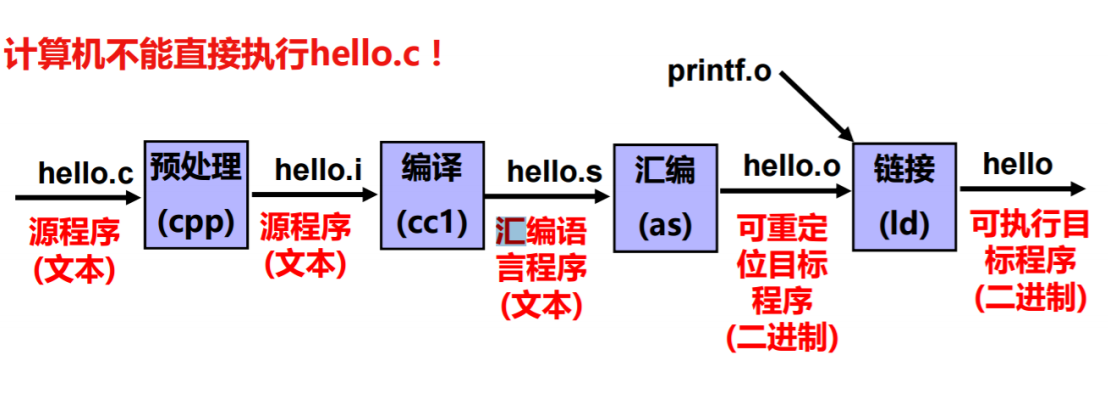
它需要经过:
-
预处理
-
编译
-
汇编
-
链接
等数个步骤之后才能得到一个可执行文件。这章主要为的是描述由c到hello的最后一步,链接的操作。
先来看一个简单的静态链接是怎么做的。
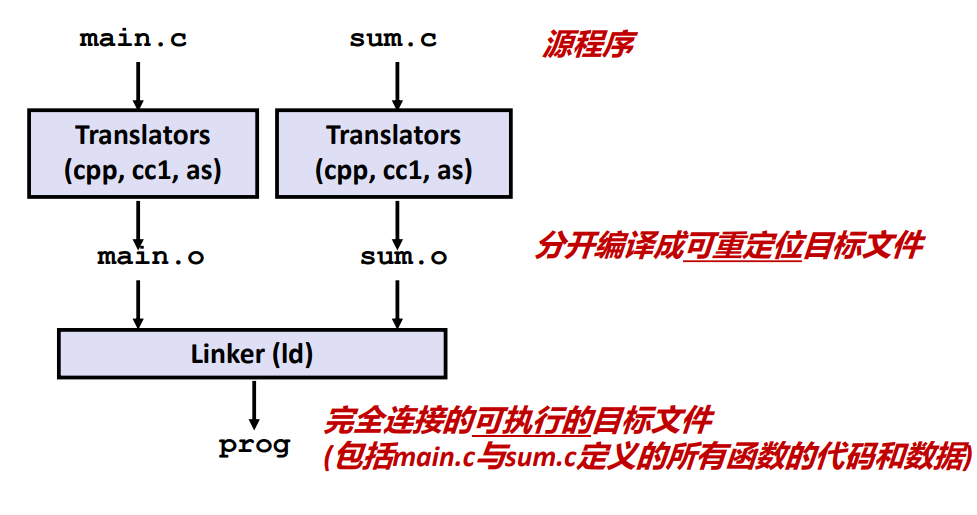
链接器的输入是多个可重定向文件,其输出是一个完成连接的可执行文件,它包含了 main.c 和 sum.c 中所有的代码和数据。
在探究动态链接和静态链接之前,我们应该先来了解一下为什么要插入一个链接阶段,以及链接到底做了哪几件事情。
为什么要用链接
文件解耦合。还记得刚开始用 C 写代码的日子,用的是 vs,把一整个贪吃蛇的代码都包揽在一个文件里,那个文件足足有 1500 行,不过是算上代码和注释的总行数,而在那时候,还是我学代码的第五个月,也没人告诉我可以分文件,甚至于调试的方法也没人告诉我。
后来写的多了,才慢慢意识到,分文件编码,大概算是工程化的第一步!也是解耦代码逻辑重要的一步,这样代码可以写在不同的小的文件中,而不是巨大一团,同时还可以构建公共的函数库,例如 C 中的数学库,标准库等等,减少重复代码。
除此以外,还可以实现增量编译,众所周知,C 的编译相对其他语言算是很慢很慢的了,有时候一个大型工程可能需要一两天才能编译完成,而链接器的输入就是一个个小的可链接文件,当编码者更改一部分代码,整个编译的流程只需要针对那些做过更改的代码进行,只需要重新编译修改过的文件,然后再与其他已经编译成可链接文件的部分进行链接,因此就能大幅度提高编译速率。
还有,并不是所有的程序都会用的公共库的所有函数,在执行的时候往往只会用到一部分,因此可以把公共函数聚合成一个文件,让最终的可执行文件只包含他们实际上使用的函数和代码。
链接的步骤
符号解析
链接就像是一个对对碰的游戏,目的是找出所有符号的对应。一般来说,需要确定的符号是函数和变量,因为他们都有可能在外部被定义,因此在当前文件可能没有显示的定义需要看别的地方有没有对它的描述,如果没有,那么就应该抛出异常。
在符号解析步骤中,链接器将每个符号引用与一个确定的符号定义关联起来
重定位
-
将多个单独的代码节和数据节合并为单个节
-
将符号从它们的在.o 文件的相对位置重新定位到可执行文件的最终绝对内存位置。
-
更新所有对这些符号的引用来反映它们的新位置
在原来的可链接文件中,函数、变量的位置都是相对的,因为不知道最终会被放在可执行程序的哪个段,因此不能使用绝对定位,而链接的目的是确定最终位置,并且此时所有的文件都已经就位,所以可以直接确定绝对内存位置。另外根据上一个步骤找到的符号引用,我们可以替换所有相同符号的引用来反映他们的新位置。

三种目标文件
可重定位目标文件.o文件
为了要和其他的可重定位目标文件相结合,所有他的代码和数据地址都是从 0 开始的,这样方便相对位置和最终内存位置,并且每一个.o都是从一个源文件.c文件生成来的,它包含了可结合的代码和数据。
可执行目标文件a.out文件
包含可以直接执行,可以直接复制到内存中并执行的代码和数据,因此他的代码和数据中的地址都是虚拟地址空间中的地址,实际上就是程序所能看到的 “内存地址”。
共享目标文件.so文件
这是一种特数的可重定位目标文件,因为它是在程序运行时才会加载进去的文件,这与一般的静态可重定位目标文件不同,它们是在链接的时候就已经一起结合成可执行目标文件了。
Windows 中的共享目标文件的后缀名为.dll。
一个可重定位目标文件的标准格式被称为可执行可链接格式,Executable and Linkable Format (ELF)。

要知道,可执行的目标文件也是 ELF 格式的,ELF 是一个比较宽泛的范围和概念。
符号表解析
首先我们应该要了解符号的定义与分类。
全局符号
-
由模块 m 定义的,可以被其他模块引用的符号
-
例如:非静态 C 函数与非静态全局变量
-
简而言之,在本文件中定义的,可被其他文件引用的符号
外部符号
- 由模块 m 引用的,来自外部其他文件定义的符号
局部 / 本地符号
-
在模块 m 定义的,并且只在 m 中被引用的符号
-
例如使用静态属性定义的 c 函数和全局变量。static
-
本地链接符号不包括非静态本地程序变量,那些是局部符号?
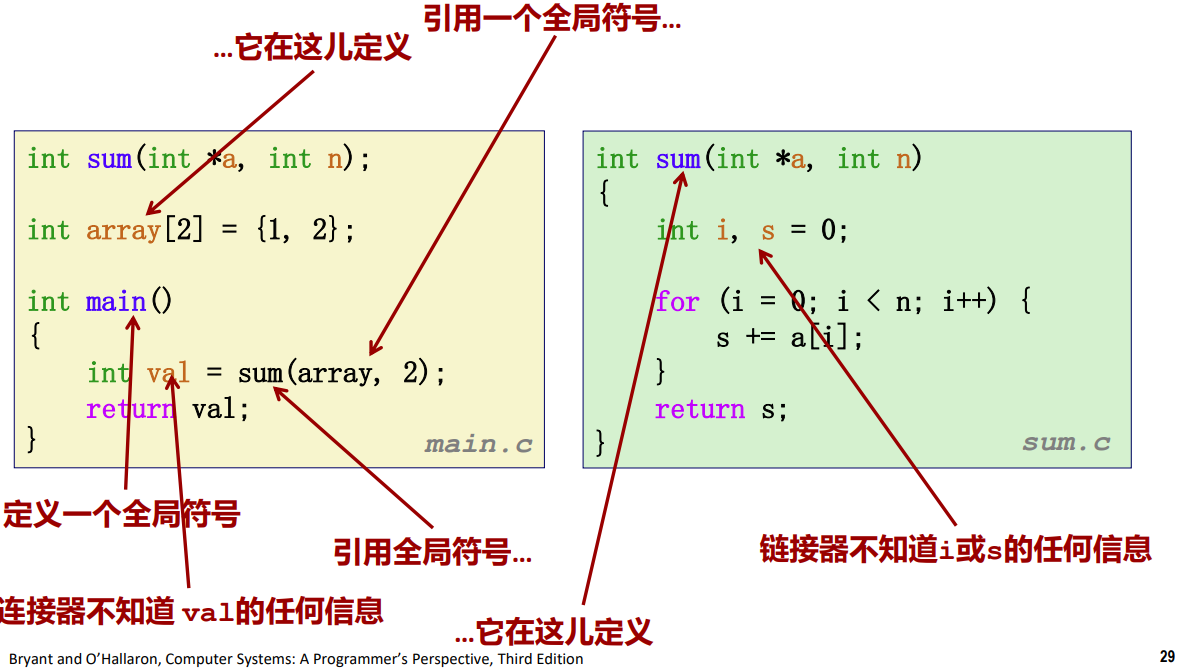
再来看一个例子
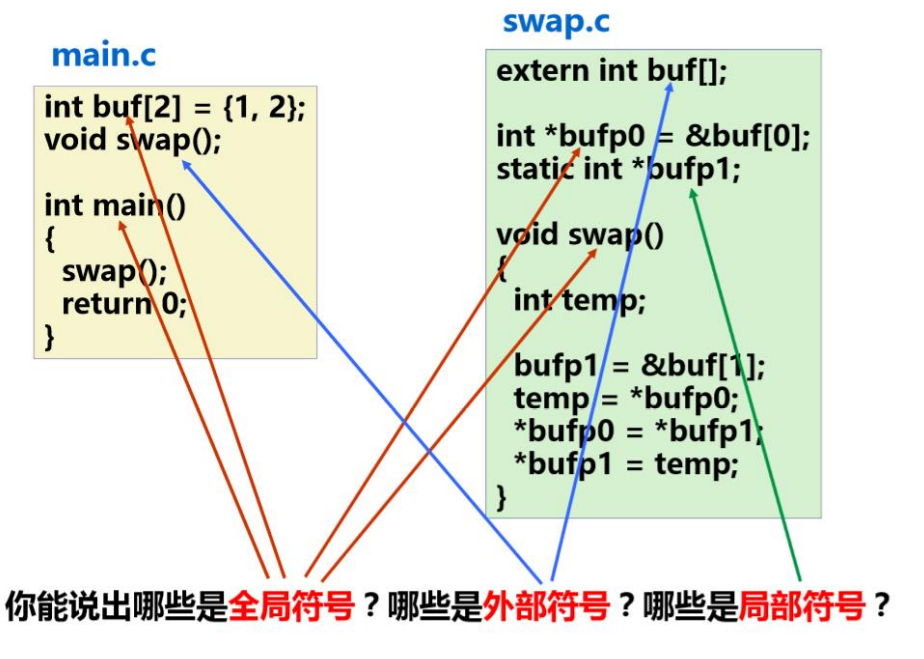
对于 C 语言中的静态变量与非静态变量,程序执行的时候有不一样的行为。
-
本地非静态 C 变量:存储在栈上
-
本地的静态 C 变量,存储在未初始化节
.bss上或者是.data上。
int f()
{
static int x = 0;
return x;
}
int g()
{
static int x = 1;
return x;
}
而对于在链接的时候遇到的同名本地符号,编译器会在.data上给每个同名符号分配空间,并给他们在符号表中创建唯一名称的本地符号,例如x.1,x.2之类的。
全局符号的强弱特性
程序符号要么是强符号,要么就是弱符号,这里的强弱是根据有没有被初始化来定义的,而对于函数而言,要看这个函数是在被声明还是在被定义,如果是在被定义,那么不管函数体中是否有东西,那么他就是强符号!
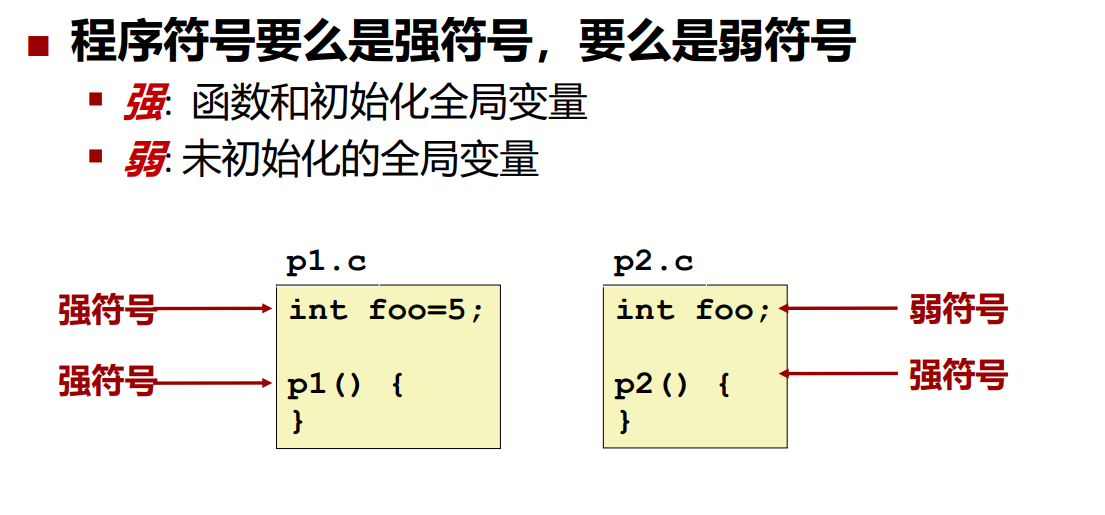
但是符号同名是很容易出现的事情,所以链接器必须要有一个处理这些符号的规则。
链接器处理符号的规则
不允许多个同名的强符号
-
每个强符号只能定义一次
-
否则:链接器抛出错误
若有一个强符号和多个弱符号同名,则选择强符号(按强符号定义为准)
- 对弱符号的引用被解析为强符号
如果有多个弱符号定义,那么就会任意在这其中选择一个弱符号
- 可以用 gcc –fno-common 命令,告诉连接器在遇到多个弱定义的全局符号时输出警告信息。
一些可能令人疑惑的例子

而事实证明,这些强弱符号确实会导致很多的问题。

这些错误大多都很隐蔽,难以察觉,因此应该尽量少使用全局变量,尽量使用本地变量(static),如果要使用全局变量最好应该对它进行初始化。
重定位
ELF 可重定位目标文件的格式
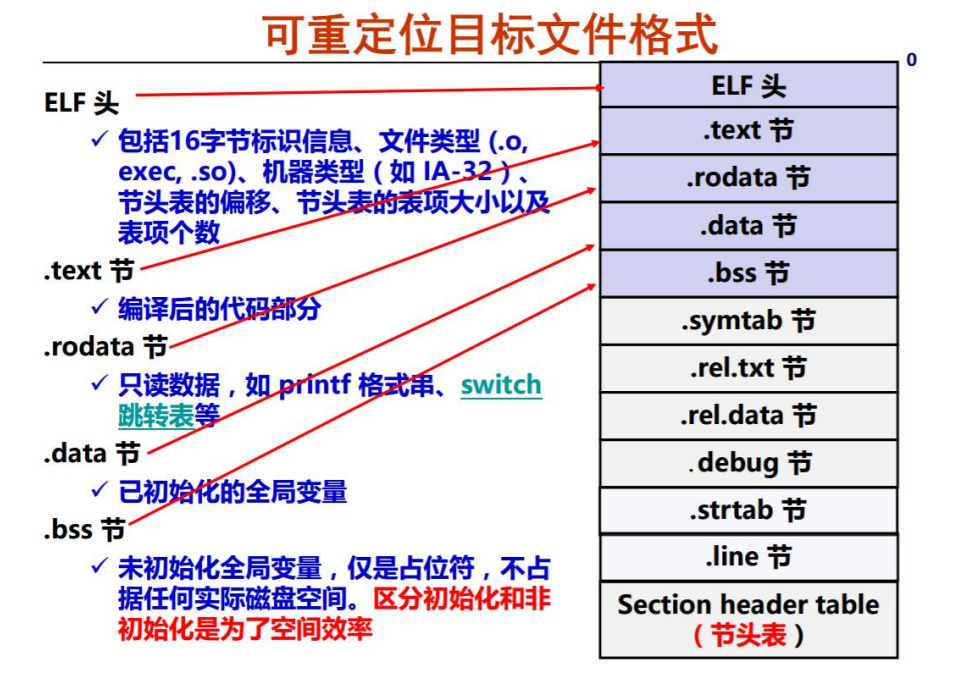

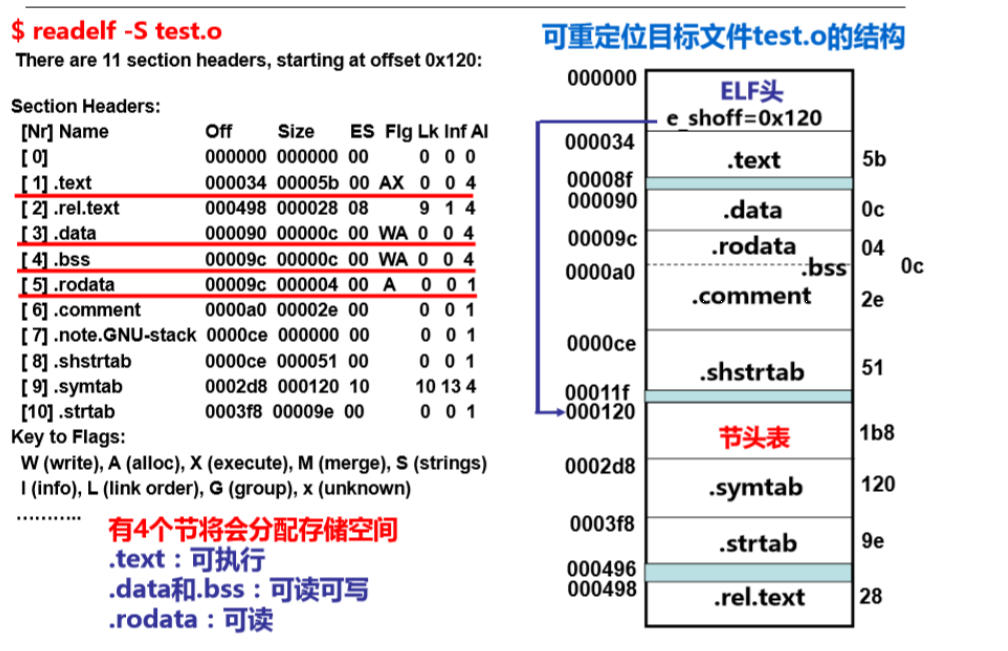
一般来说,整个 ELF 文件中可以为我们提供最多信息的是 ELF 头以及最后的节头表。
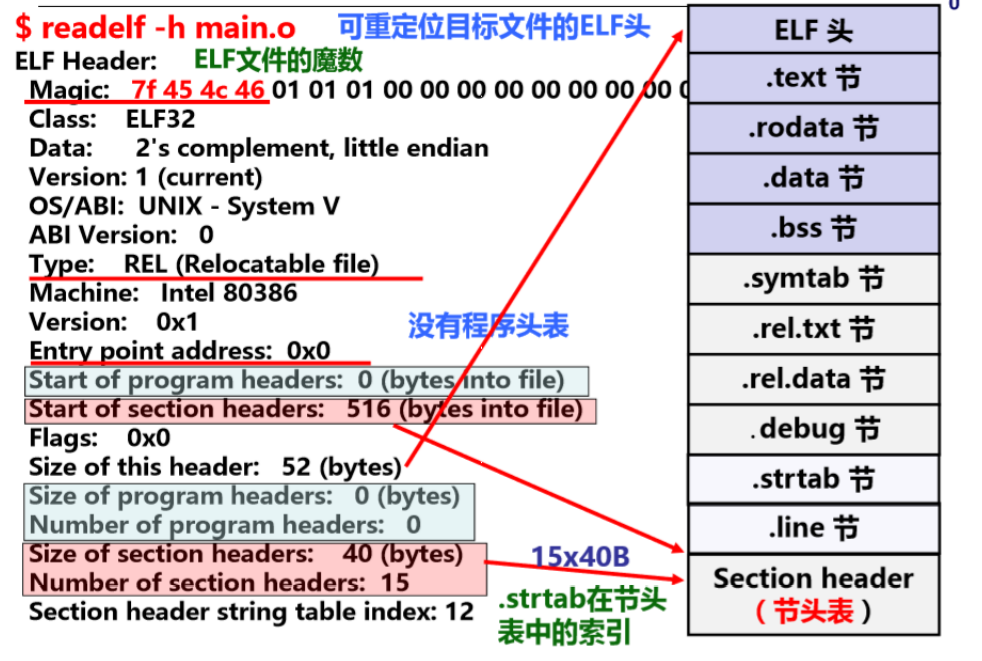
ELF 头信息举例
节头表信息结构体 Section Header Table

信息举例
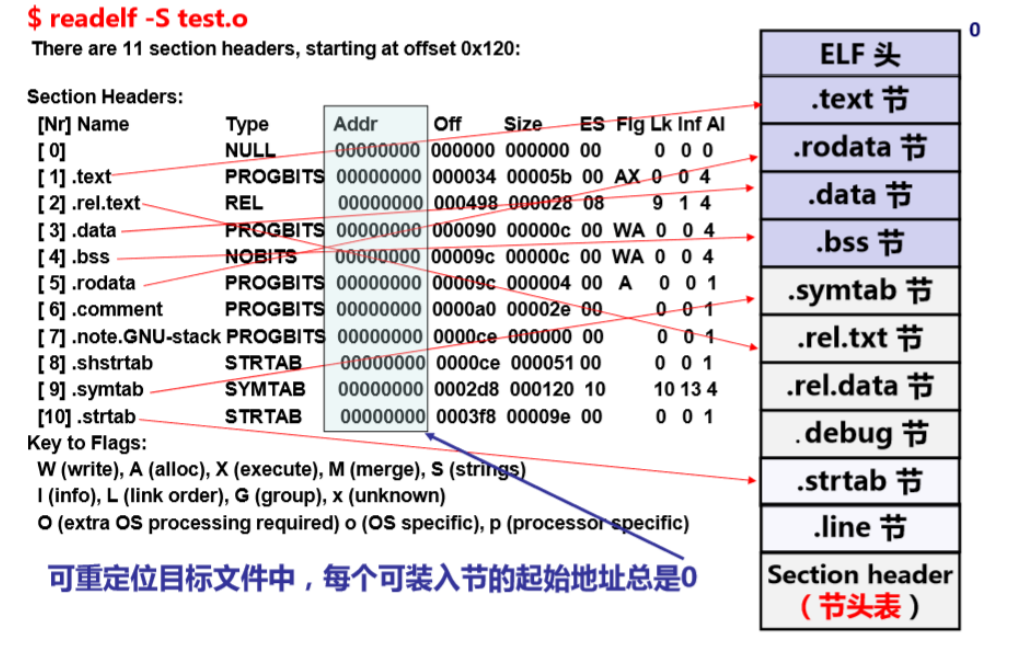
因为要装入最终的可执行文件中计算最终的内存地址,所以此处 ELF 文件的可装入节起始地址都是 0.
除此以外我们还可以辊距节头表信息中的 Flg 位知道这个节是否需要分配空间,以及是否可读写可执行。
ELF 可执行目标文件
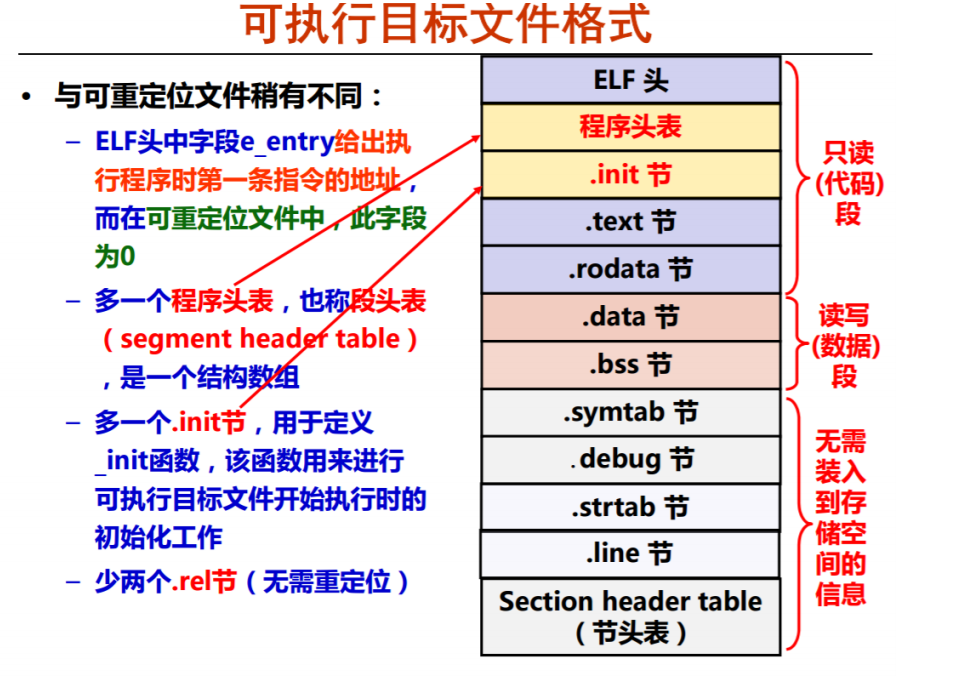
多了一个程序入口地址,这个字段虽然在可重定位目标文件中也有,但是在那里面程序入口地址为 0。
还有一个值得注意的点,在这种文件中不再有要重定位的代码、数据部分,例如rel.text或者是rel.data之类的节。
而当我们有了一个可执行文件的时候,我们要怎么做才能让他跑起来?所以我们还需要了解可执行文件的存储器映像。
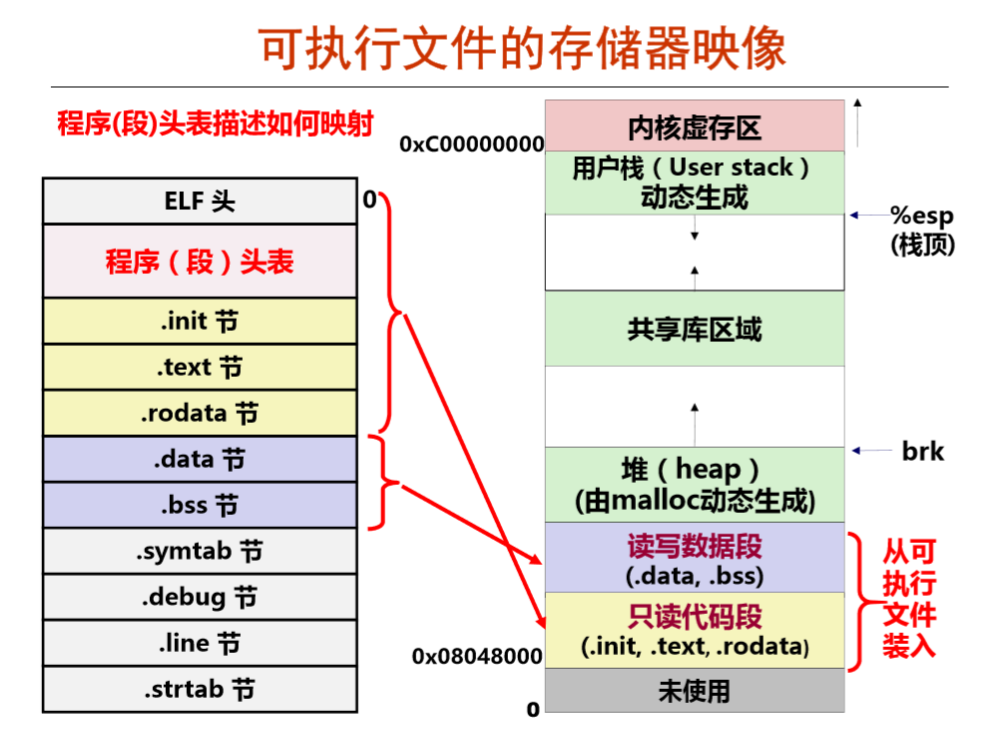
虽然 ELF 中有很多节,但是这里在装载的时候只用到了一部分,并分为可读写以及只读部分。而对于可执行目标文件而言,最重要的表当属程序头表,它描述了文件中节和虚拟空间之间的存储段的映射关系,一个表项代表了一个连续的段或是一个特殊的节。
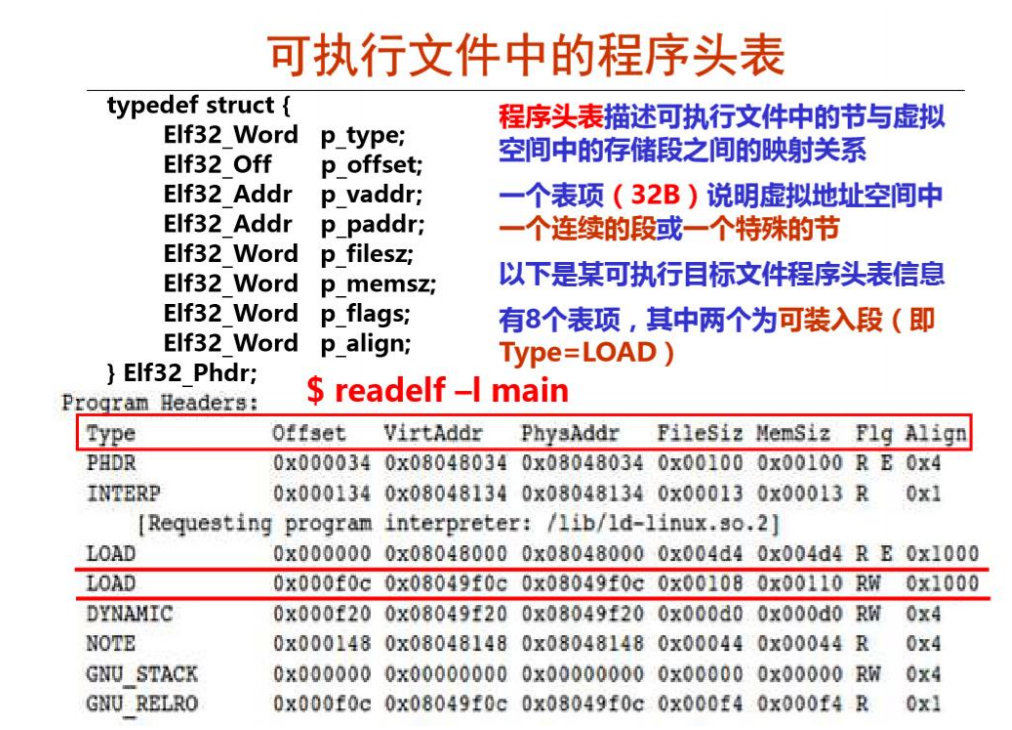
而对于其中的两个LOAD段,有以下功能。

两个可装入段都对应了不同的节,要注意区分。
常用函数的处理办法
程序员在编写程序的时候难免要用到通用库里的函数,这些函数往往包含了很多功能的最佳实践,在某种意义上来说是不可或缺的。但同样的,由于它们封装的太过良好,导致包含这些函数的库文件比较大,如果需要打包这些函数的话,在当下的链接器框架中,我们往往有两个选择。
-
将所有函数都放入到一个源文件中,但是这样子的话这个源文件就会非常大,因为并不是每个函数都会在程序员编写的程序中被用到。
-
将每个函数都放到单独的源文件中,这样用到函数的时候就直接手动引用文件,虽然这样降低了打包后的体积,但是这样也增加了编码的负担。
链接器符号解析的全过程
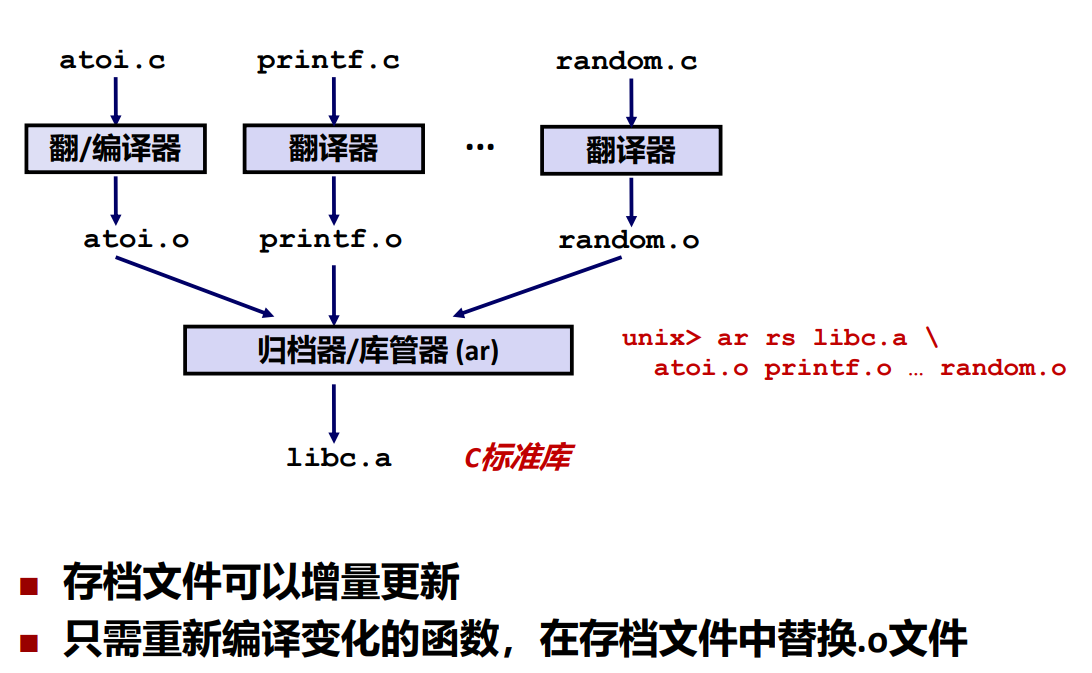
传统的解决方案:静态库
静态库的后缀是.a归档文件。
-
将所有的目标模块打包成一个单独的库文件,被称为静态库文件,也叫归档文件 archive。
-
当使用静态库一起编译链接的时候,增强链接器通过查找一个或者多个库文件中定义的符号来解析符号引用。
-
如果一个存档成员文件解析了符号引用,就把它链接入最终的可执行目标文件,并且只链接这个成员文件,与其他成员无关。
创建静态库的过程
首先是要用三个集合,用来存放从目标文件中读取到的符号引用。
-
\(E\) 是将被合并以组成可执行文件的所有目标文件的集合。
-
\(U\) 当前所有未被解析的引用符号的集合。
-
\(D\) 当前所有定义符号的集合。
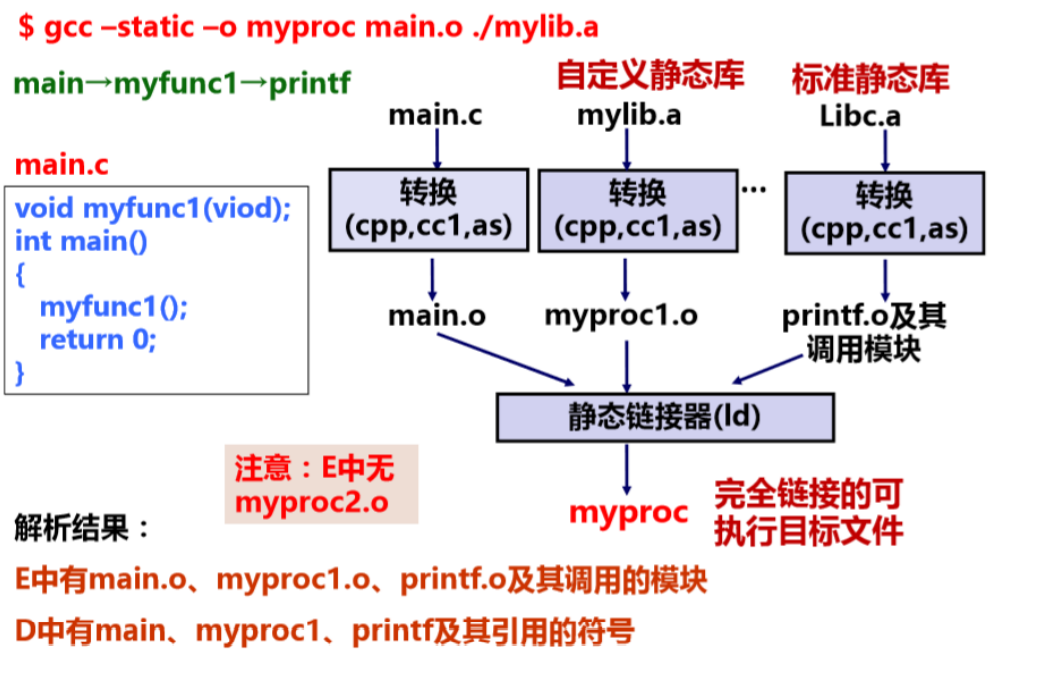
以自定义静态库文件和一个简单的 C 文件来解释,然后通过以下的过程来解析符号。


- 刚开始的时候三个集合 \(E,D,U\) 全部都为空,此时扫描目标文件
main.o,并把文件加入到集合 \(E\) 中,同时把这个文件中读取到的未找到对应的符号myfunc1加入到 \(U\) 中,然后把 main 函数加入到 \(D\) 中。 - 然后扫描静态库文件,使用当前 \(U\) 中的符号去跟静态库文件里的符号进行匹配,根据上面的例子,此处应该找到对应的是静态库文件里的
myproc1.o,因为这个目标文件里面定义了 \(U\) 中的那个函数引用,所以就把myproc1.o加入 \(E\) 中,然后把之前未解析的myfunc1符号转移到 \(D\) 集合中去。 - 然后再去扫描
myproc1.o文件,发现里面有未解析的printf,因此将其加入到 \(U\) 中,等待下一个库文件的解析对应。 - 不断在
mylib.a的各个模块上进行匹配,直到集合 \(U、D\) 都不再变化,然后丢弃静态库文件中没有使用到的目标文件,完成这一步的搜索。 - 接着,扫描静态库文件
libc.a,这个文件是默认的库文件,找到 \(U\) 中的符号。 - 不管如何,最终扫描完全部之后,集合 \(U\) 中肯定是空的。
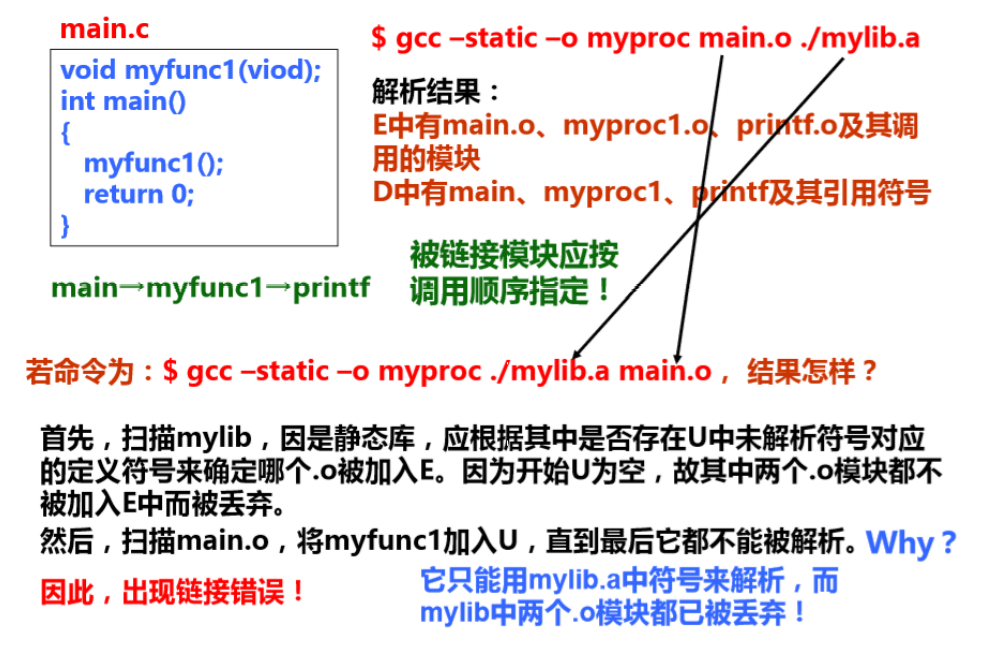
注意,此处编译的文件顺序对最终结果也有影响,如果顺序被调换可能出错。
现代的解决方案:共享库
静态库的缺点
-
显而易见的,使用静态库肯定要把那些公共的函数打包到最终的可执行目标文件中。这样就会造成磁盘浪费。
-
在运行的时候,会把这些公共库都加载到内存中,如果有很多个类似的可执行文件被同时执行,那么内存中就会有很多份重复的公共库文件,导致内存的浪费。
-
如果系统公共库出现了一些错误,那么每个应用程序都要显式的重新链接程序,这样对普通用户非常不友好。
因此现代的解决方案是使用共享库
-
包含代码和数据的目标文件,在它们的加载时或运行时,被动态地加载并链接到应用程序中(磁盘和内存中只有一个备份)
-
这种共享库也叫动态链接库,后缀名为
dll或者是so。
动态链接可以通过两种方式加载。
-
在可执行文件第一次被加载和运行的时候载入动态链接。
-
Linux 的常用做法是,使用动态链接器来自动处理
ld-linux.so。 -
C 语言中标准库
libc.so往往采用动态链接的方式来进行加载。
-
-
在程序启动之后再加载动态链接库,此时被称为运行时链接。
- 在 Linux 中,运行时链接是通过调用
dlopen来完成的。
- 在 Linux 中,运行时链接是通过调用
位置无关代码 PIC
可以加载而无需重定位的代码被称为位置无关代码。
对于上文中提到的共享库代码,它的位置实际上就是不确定,因为只有在被载入内存之后,其他要用到这个动态链接库的程序才能得到真实地址位置,而且,即使共享库代码的长度发生变化,也不影响调用它的程序。而共享库代码就是一种位置无关代码 PIC。
而创造这种代码规范的目的是为了方便链接,让链接器在无需更改代码的情况下,就可以让共享库被加载到任意地址运行。
因此,对于这种库文件,其内部的过程调用,程序变量等引用情况有一些特定的要求。
-
模块内的过程调用、跳转要采用 PC 相对偏移寻址。
-
模块内的数据访问,如模块内的全局变量、静态变量等。
-
模块外的过程调用、跳转需要调整。
-
对模块外部的数据访问也需要调整,例如外部变量的访问等。
可执行文件的加载
一般来说,用户在使用系统运行程序的时候往往用的是shell程序,shell或使用execve系统调用函数来调用加载器,加载器根据可执行文件的程序头表、程序段中的信息来处理文件的执行过程。调用之后,会赋予这个程序对应的上下文和运行时参数,如果调用错误,就会给调用这个程序的程序返回码,用以处理错误。

Linux 库打桩技术
在不破坏原有程序的前提下,监控程序的部分函数的运行状况。
库打桩技术一般有三种解决方案:在编译时打桩,链接时打桩以及在加载 / 运行时打桩,此处以 lib malloc 和 free 函数打桩为例子。
#include <stdio.h>
#include <malloc.h>
int main()
{
int *p = malloc(32);
free(p);
return(0);
}
编译时打桩
wrapper 函数,覆盖原来的 malloc 和 free 函数。mymalloc.c
#ifdef COMPILETIME
#include <stdio.h>
#include <malloc.h>
/* malloc wrapper function */
void *mymalloc(size_t size)
{
void *ptr = malloc(size);
printf("malloc(%d)=%p\n",
(int)size, ptr);
return ptr;
}
/* free wrapper function */
void myfree(void *ptr)
{
free(ptr);
printf("free(%p)\n", ptr);
}
#endif
替换标准函数。malloc.h,这个函数要放在所有文件的同一级目录下。
#define malloc(size) mymalloc(size)
#define free(ptr) myfree(ptr)
void *mymalloc(size_t size);
void myfree(void *ptr);
然后编译运行函数。
linux> gcc -Wall -DCOMPILETIME -c mymalloc.c
linux> gcc -Wall -I. -o intc int.c mymalloc.o
linux> ./intc
malloc(32)=0x1edc010
free(0x1edc010)
linux>
链接时打桩
这里要用到的大多是 gcc 的特殊语法,使用一些变换,将真实的 malloc 和 free 替换成我们想要监控的函数。mymalloc.c
#ifdef LINKTIME
#include <stdio.h>
void *__real_malloc(size_t size);
void __real_free(void *ptr);
/* malloc wrapper function */
void *__wrap_malloc(size_t size)
{
void *ptr = __real_malloc(size); /* Call libc malloc */
printf("malloc(%d) = %p\n", (int)size, ptr);
return ptr;
}
/* free wrapper function */
void __wrap_free(void *ptr)
{
__real_free(ptr); /* Call libc free */
printf("free(%p)\n", ptr);
}
#endif
然后使用下列命令编译程序。
gcc -Wall -DLINKTIME -c mymalloc.c
gcc -Wall -c int.c
gcc -Wall -Wl,--wrap,malloc -Wl,--wrap,free -o intl int.o mymalloc.o
# 运行程序
./intl
malloc(32) = 0x55e1abfdb2a0
free(0x55e1abfdb2a0)
加载 / 运行时打桩
首先给出的CSAPP原书上的代码,但因为运行的那个程序中printf这个函数也会调用malloc,然后导致malloc函数循环调用了,进而使得栈溢出,引发段错误,使书上的执行函数无法运行。
#ifdef RUNTIME
#define _GNU_SOURCE
#include <stdio.h>
#include <stdlib.h>
#include <dlfcn.h>
/* malloc wrapper function */
void *malloc(size_t size)
{
void *(*mallocp)(size_t size);
char *error;
mallocp = dlsym(RTLD_NEXT, "malloc"); /* Get addr of libc malloc */
if ((error = dlerror()) != NULL)
{
fputs(error, stderr);
exit(1);
}
char *ptr = mallocp(size); /* Call libc malloc */
printf("malloc(%d) = %p\n", (int)size, ptr);
return ptr;
}
/* free wrapper function */
void free(void *ptr)
{
void (*freep)(void *) = NULL;
char *error;
if (!ptr)
return;
freep = dlsym(RTLD_NEXT, "free"); /* Get address of libc free */
if ((error = dlerror()) != NULL)
{
fputs(error, stderr);
exit(1);
}
freep(ptr); /* Call libc free */
printf("free(%p)\n", ptr);
}
#endif
我们可以来复现一下错误样例。
编译执行的命令行:
gcc -Wall -DRUNTIME -shared -fpic -o mymalloc.so mymalloc.c -ldl
gcc -Wall -o intr int.c
LD_PRELOAD="./mymalloc.so" ./intr
如果我们使用上述指令执行程序,并进行运行时打桩,就会导致段错误。
[1] 1258 segmentation fault ( LD_PRELOAD="./mymalloc.so" ./intr; )
对于这个问题,我在网上找到了一个解答。CSAPP第三版运行时打桩Segmentation fault_imred的专栏-CSDN博客从这里可知,出现错误的原因是printf函数循环调用了malloc,而malloc也调用了printf导致一直在循环,无法跳出。
解决办法是加一个计数器,只有第一层可以调用malloc,否则就直接跳过。新函数如下。
void *malloc(size_t size)
{
static __thread int print_times = 0;
print_times++;
void *(*mallocp)(size_t size);
char *error;
mallocp = dlsym(RTLD_NEXT, "malloc");
if ((error = dlerror()) != NULL)
{
fputs(error, stderr);
exit(1);
}
char *ptr = mallocp(size);
if (print_times == 1)
{
printf("malloc(%d) = %p\n", (int)size, ptr);
}
print_times = 0;
return ptr;
}
事实证明结果是正确的,运行之后可以得到:
LD_PRELOAD="./mymalloc.so" ./intrmalloc(32) = 0x5565c9cee2a0
free(0x5565c9cee2a0)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号