Python: 通过Selenium爬取动态网页内容
前言
为帮助懒狗实现不用背题,轻松通过线上考试的目标。
需要把目标网站上的题库以及对应的答案,全部爬取到本地。
技术选型
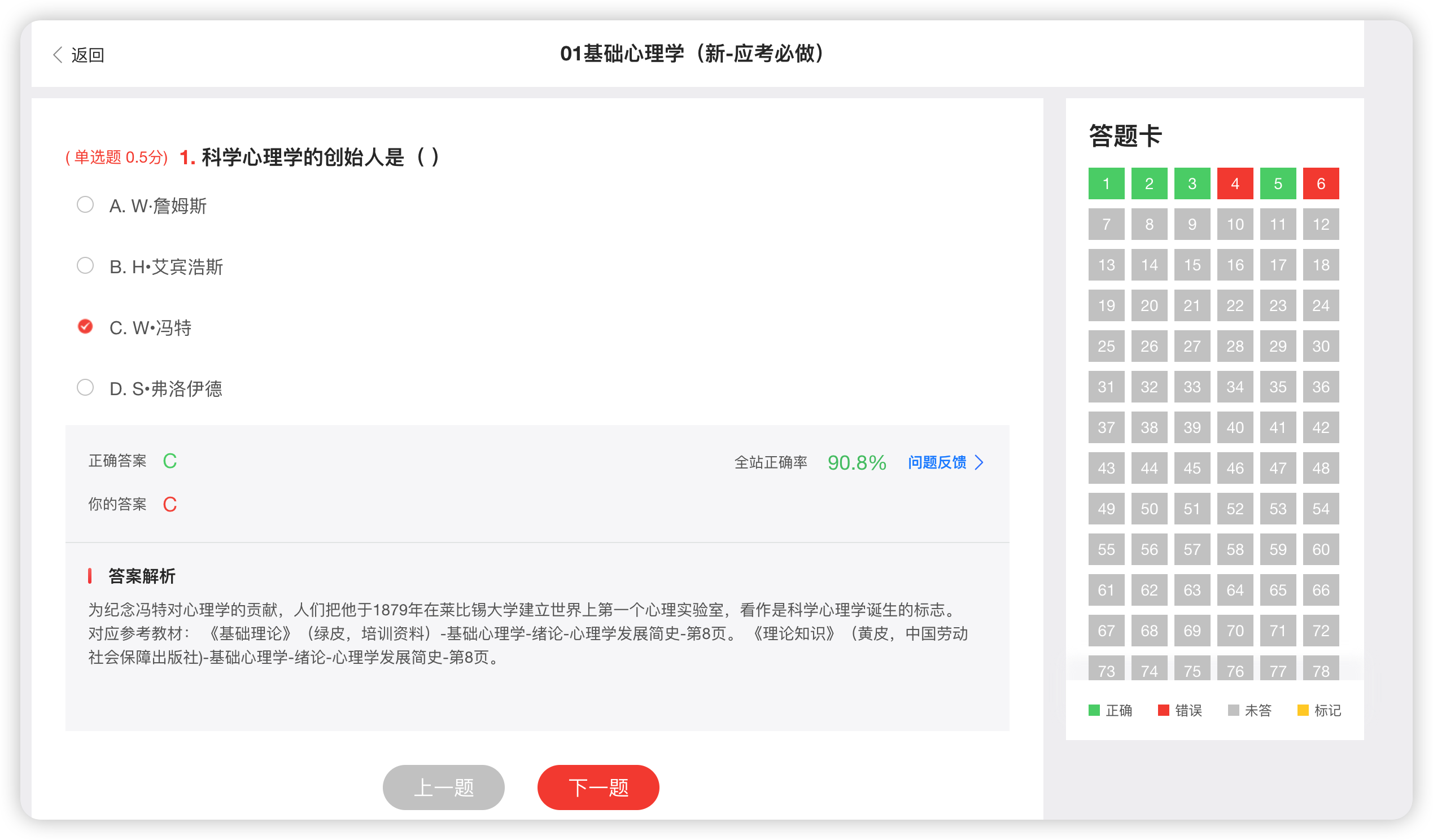
通过控制台发现点击下一题并不会产生新的资源链接。也就是说该页面是动态页面,那么像BeautifulSoup之类的库就没有用武之地了。
综上,所以考虑使用Selenium来模拟用户行为爬取数据。
准备步骤
- 不必多说
pip3 install selenium - 因为需要Chrome Driver和当前使用Chrome版本一致,所以可以在下方网页中,找到对应版本进行下载
http://chromedriver.storage.googleapis.com/index.html
实战
- 配置一下Chrome Driver路径,指定访问URL,启动。
如果Chrome浏览器能打开所指定网页,基本工作就算完成。
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
if __name__ == '__main__':
url = ""
headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36"
}
chrome_driver = "/usr/local/bin/chromedriver"
wb = webdriver.Chrome(executable_path=chrome_driver)
wb.get(url)
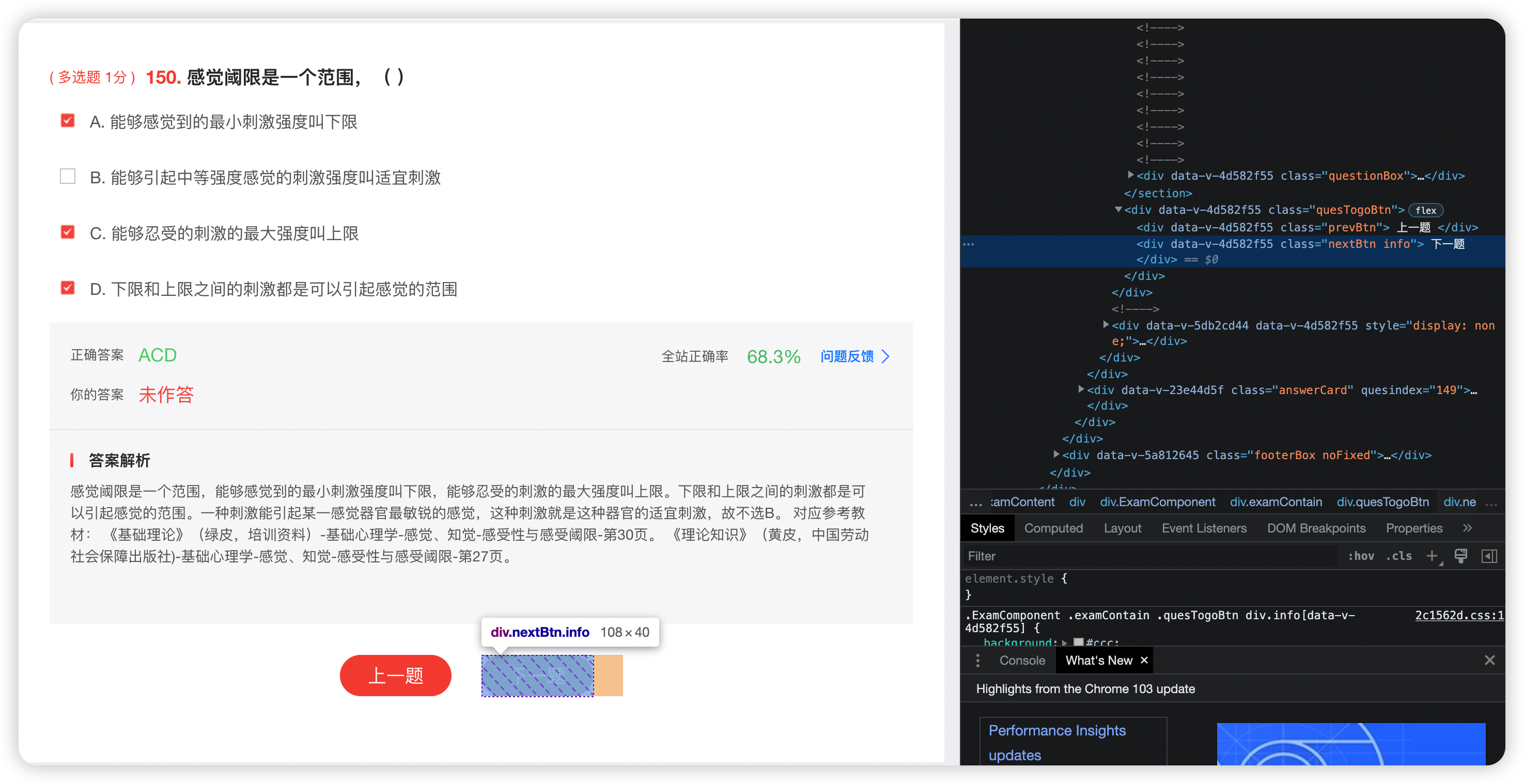
- 获取该页面题目,通过Full XPath
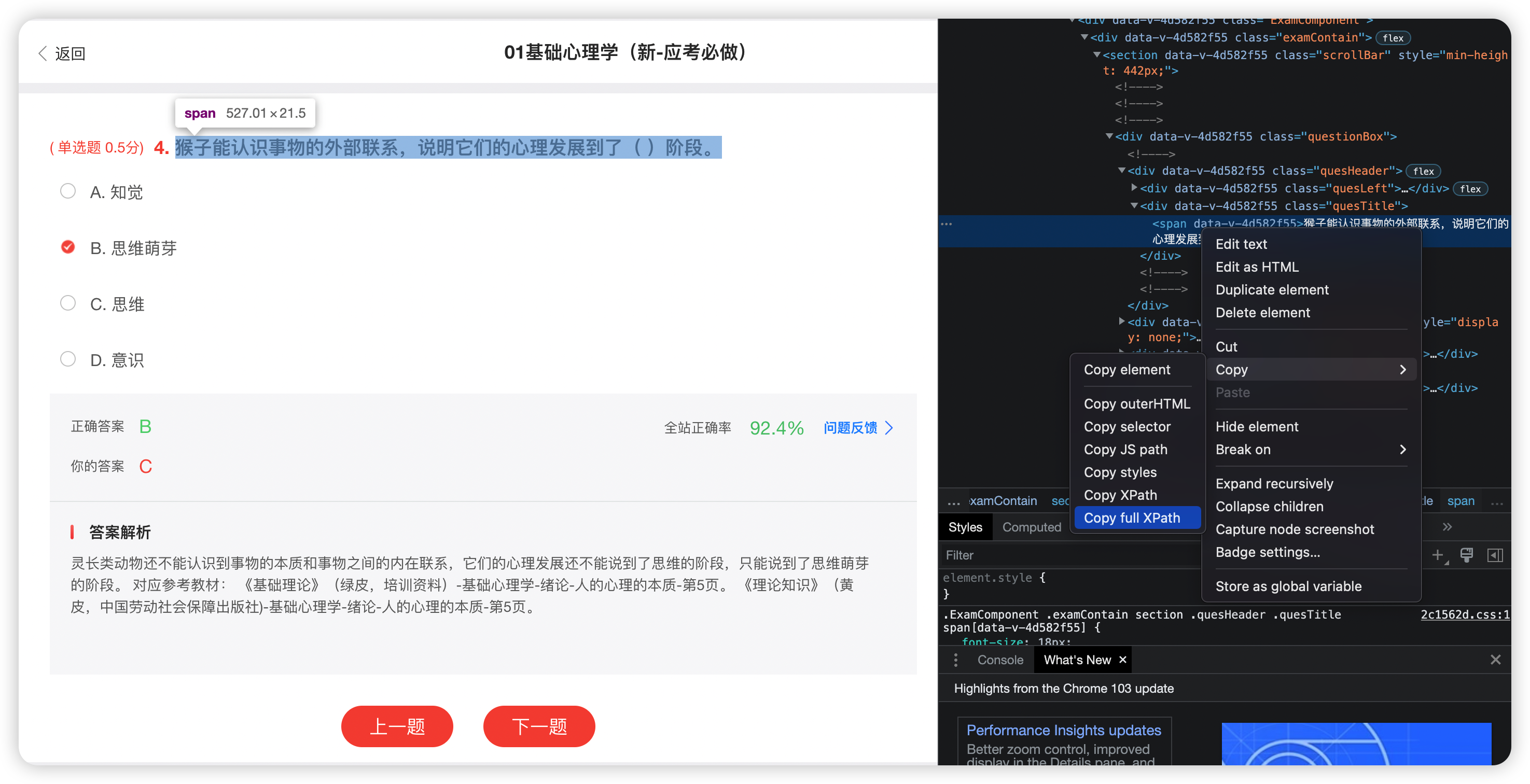
subject = wb.find_element_by_xpath(
'/html/body/div/div/div/div/div[2]/div[1]/div[2]/div[1]/div/div[1]/section/div/div[1]/div[2]/span')
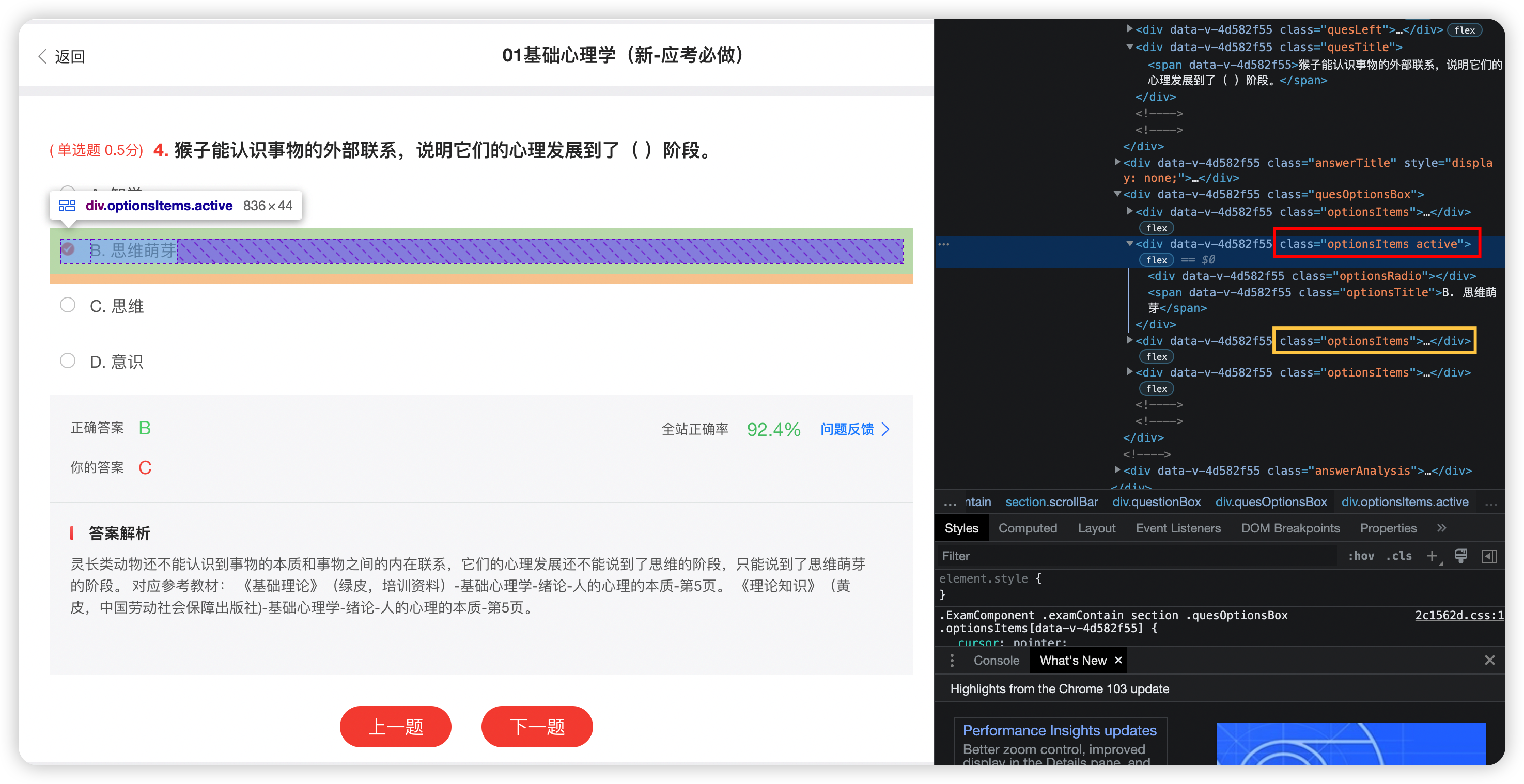
- 获取该页面答案,这里用XPath肯定是行不通的,因为每一页答案位置不固定
观察页面发现被选中答案的类选择器与未被选中不一致
所以从这里入手
answers = wb.find_elements_by_css_selector('.optionsItems.active')
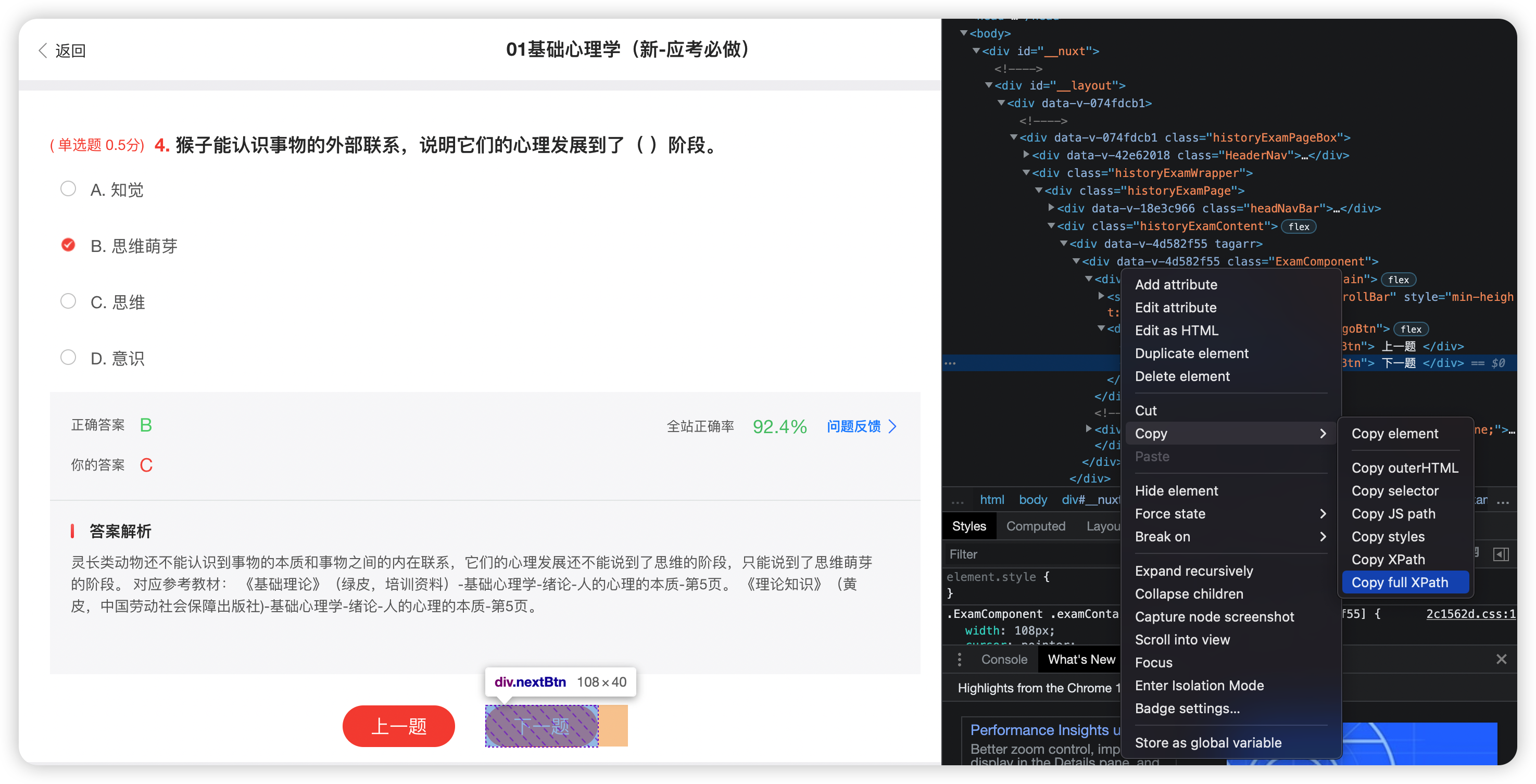
- 题目有了,答案也有了。复制下一题的Full XPath
一个最小单位的获取流程就结束了
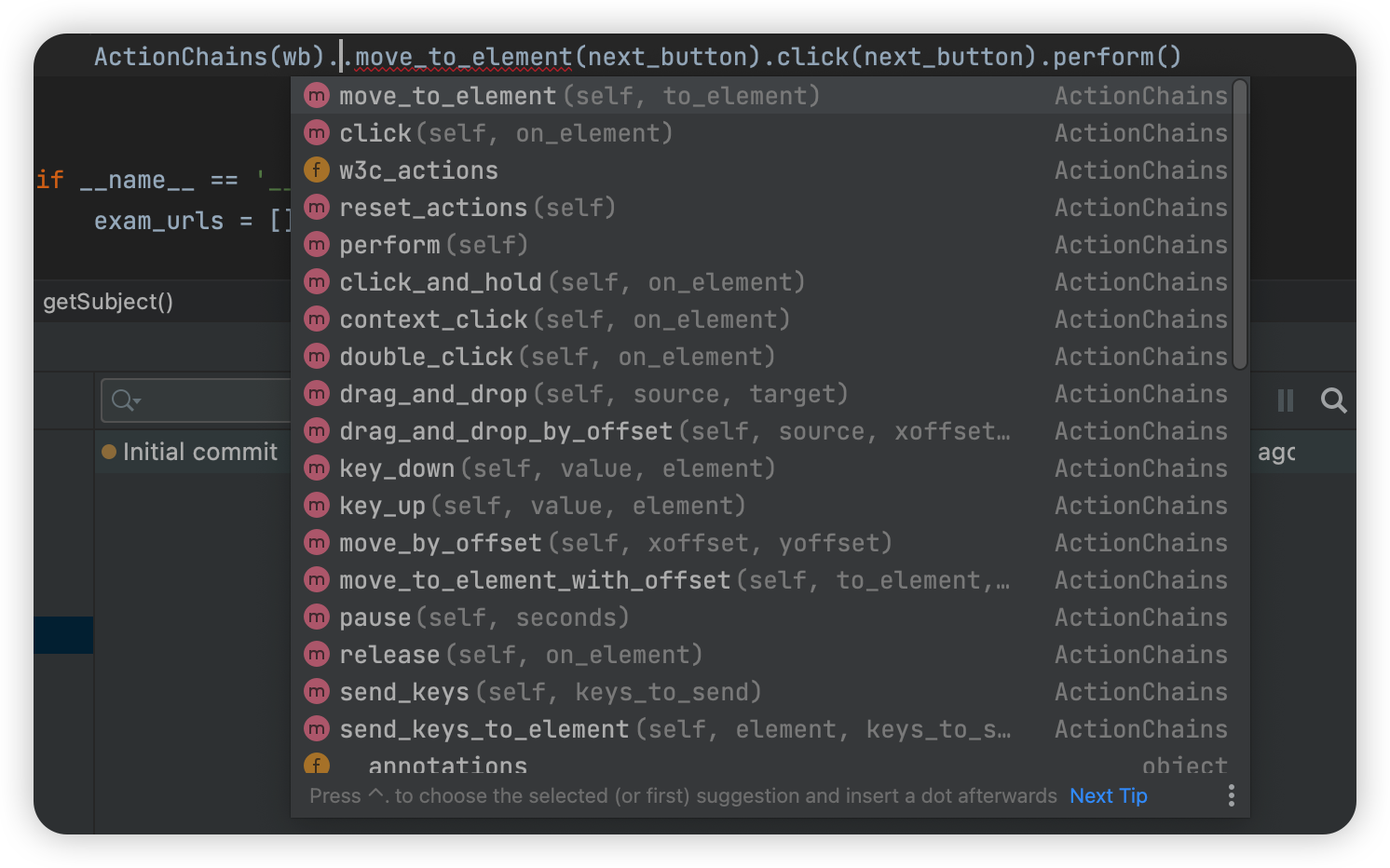
这里用ActionChains来模拟用户操作
button = wb.find_element_by_xpath(
'/html/body/div/div/div/div/div[2]/div[1]/div[2]/div[1]/div[2]/div/div[1]/div/div[2]')
ActionChains(wb).move_to_element(button).click(button).perform()
- 循环上一个步骤
发现到了最后一题,类选择器有不同
设置结束条件
try:
if wb.find_element_by_css_selector('.nextBtn.info') is not None:
break
except NoSuchElementException:
print()
这里需要注意设置了dealy(1),这是因为每次跳转到一个新页面后,页面元素可能还没加载出来,这个时候直接去通过selenium获取元素是拿不到的,并且会抛异常
for index, exam_url in enumerate(exam_urls):
wb.get(exam_url)
# 开始做题
delay(1)
for i in range(500):
getSubject()
try:
if wb.find_element_by_css_selector('.nextBtn.info') is not None:
break
except NoSuchElementException:
print()
总结
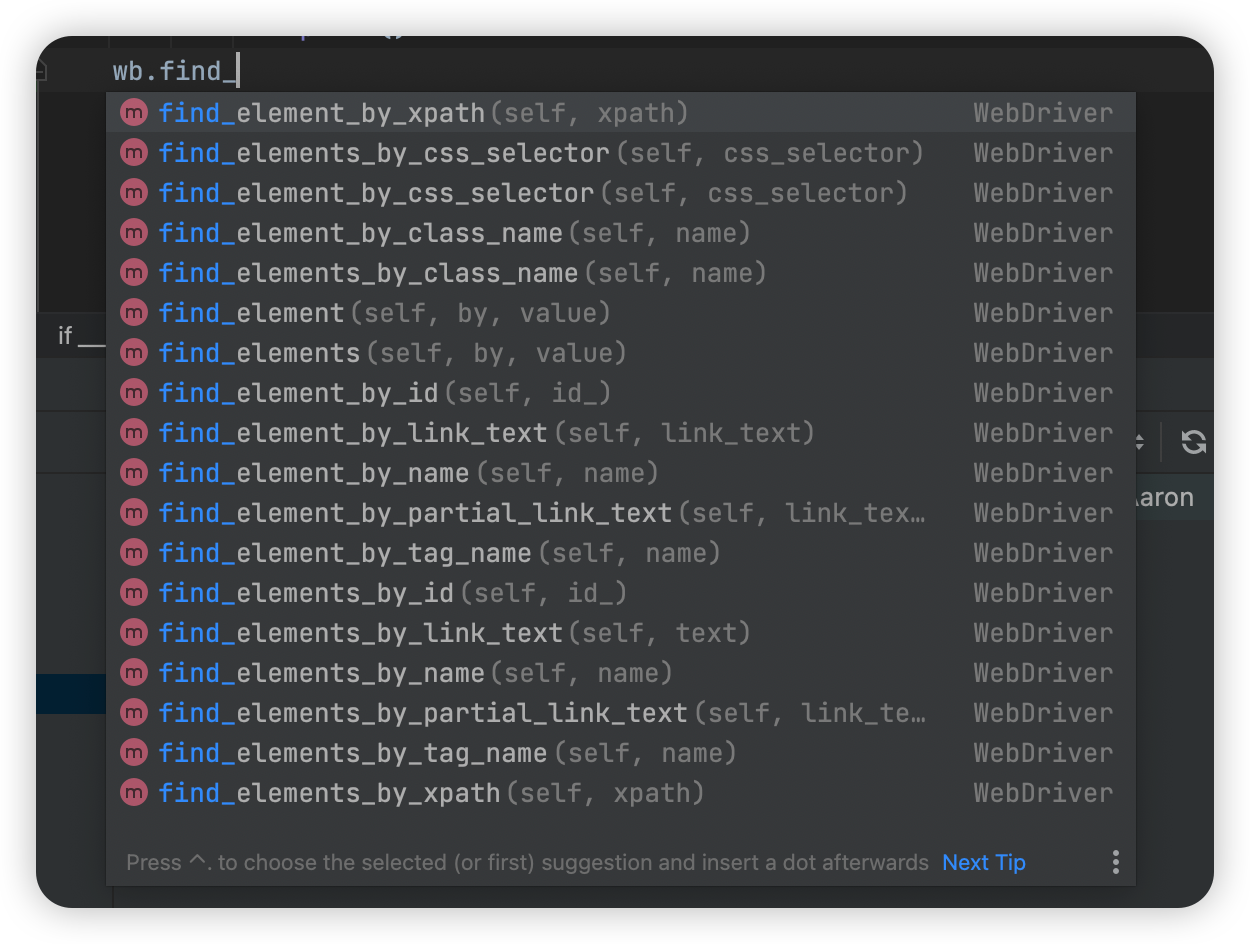
Selenium提供了很多查找页面元素的方法
ActionChains也非常强大,提供了许多模拟用户动作的方法
如有兴趣可自行研究,本案例为帮助他人即兴所写,不再深入
源码
源码地址:https://github.com/tanhaoo/python-selenium/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号