
【论文总结】Zero-Shot Semantic Segmentation
论文地址:https://arxiv.org/abs/1906.00817
代码:https://github.com/valeoai/ZS3
一、内容
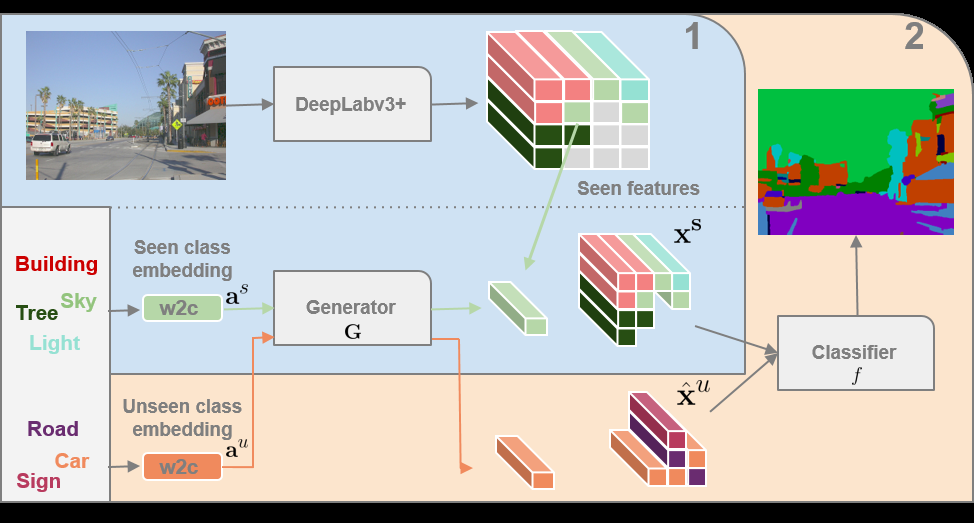
Step 0:首先使用数据集(完全不包含 Unseen Classes 的图片)训练 DeepLabv3+ 模型,得到的模型可以对只含有 Seen Classes 的图片进行分类,去掉训练好的 DeepLabv3+ 的最后一层分类层,将其变成一个特征提取器。将所有 Classes 输入到 w2c 模型,得到每个Class 对应的向量,将此向量连接到 ground-truth 中每个像素上,即每个像素都有其对应的类的向量。
Step 1:使用数据集(完全不包含 Unseen Classes 的图片)输入到 DeepLabv3+ 模型,得到特征图,根据 ground-truth 上的 Class 筛选出不同类别的特征,将每个类的特征作为 Label,对应类的 w2c 输出的向量作为输入,训练 GMMN 模型。
Step 2:使用完整数据集 (包含 Seen 和 Unseen Classes 的图片)输入到 DeepLabv3+ 模型,如果不包含 Unseen Classes,那么直接拿出特征图去训练最终的分类器,如果包含,则根据图片的 ground-truth 对应的类的向量一一生成特征,将不同类特征组合到一起,再去训练最终的分类器。
二、理解
1. 代码中将 Step 1 和 2 和在了一起,为了便于理解,把 Step 1 和 2 分开解释。
2. Step 2 中使用了两次包含 Unseen Classes 的图像和其 ground-truth。
- 在逐个对类的词向量生成特征时,用到了 ground-truth,根据 ground-truth 知道了类的总数、每个类的位置、以及对应的词向量。
- 在最终训练分类器时,也用到了含有 Unseen Class 的图像的 ground-truth。
- 也可以直接忽略 DeepLab 生成的特征图,直接根据 Seen 和 Unseen 标签随机生成图片,利用类的词向量通过 GMMN 生成特征,结合生成的图片的 Label 去训练最终分类器。
3. w2c 和 GMMN 是文章的关键,w2c 建立了一个从词语到向量的联系,GMMN 建立了一个从词向量到特征图上的视觉特征的联系,比如,使用 Unseen Class 为子弹,Seen Class 中包括弹匣,其他都是些不相干的类,自然子弹和弹匣在词向量中的联系比较起来相对紧密,从而子弹通过 GMMN 生成的特征也更与弹匣类似,通过最终分类器的训练,也就更容易能分辨出子弹。
4. GMMN 生成 Unseen Class的特征,代替了把 Unseen Class 经过 deeplab 特征提取器获得的特征,仍然需要 Unseen Class 的 ground-truth 作为 label 训练最后的分类器,但是不需要太多的 Unseen Class 的数据。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话