MySQL复制(一)复制原理探讨
1 复制概述
1.1、复制解决的问题
数据复制技术有以下一些特点:
(1) 数据分布
(2) 负载平衡(load balancing)
(3) 备份
(4) 高可用性(high availability)和容错
1.2、复制如何工作
从高层来看,复制分成三步:
(1) master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events);
关于二进制日志更多内容,请参考MySQL知识总结(四)二进制日志
(2) slave将master的binary log events拷贝到它的中继日志(relay log);
(3) slave重做中继日志中的事件,将改变反映它自己的数据。
下图描述了这一过程:
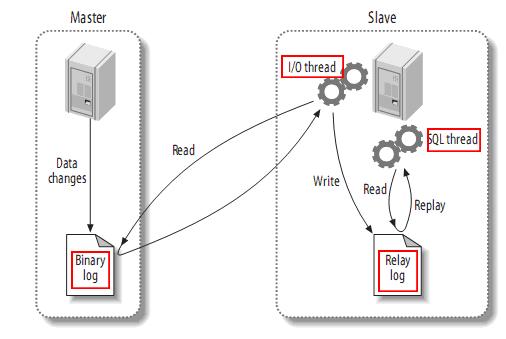
该过程的第一部分就是master记录二进制日志。在每个事务更新数据完成之前,master在二进制日志记录这些改变。MySQL将事务串行的写入二进制日志,即使事务中的语句都是交叉执行的。在事件写入二进制日志完成后,master通知存储引擎提交事务。
下一步就是slave将master的binary log拷贝到它自己的中继日志。首先,slave开始一个工作线程——I/O线程。I/O线程在master上打开一个普通的连接,然后开始binlog dump process。Binlog dump process从master的二进制日志中读取事件,如果已经跟上master,它会睡眠并等待master产生新的事件。I/O线程将这些事件写入中继日志。
SQL slave thread处理该过程的最后一步。SQL线程从中继日志读取事件,更新slave的数据,使其与master中的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于OS的缓存中,所以中继日志的开销很小。
此外,在master中也有一个工作线程:和其它MySQL的连接一样,slave在master中打开一个连接也会使得master开始一个线程。复制过程有一个很重要的限制——复制在slave上是串行化的,也就是说master上的并行更新操作不能在slave上并行操作。
该复制是属于异步复制,即主库的数据更新成功之后出现故障,从库的数据有可能未及时同步完成,此时应用切换到从库,将会出现数据不一致的情况
下一章开始讲解复制的实践
出处:http://www.cnblogs.com/tangyanbo/
本文以学习、研究和分享为主,欢迎转载,但必须在文章页面明显位置给出原文连接。 如果文中有不妥或者错误的地方还望高手的你指出,以免误人子弟。如果觉得本文对你有所帮助不如【推荐】一下!如果你有更好的建议,不如留言一起讨论,共同进步! 再次感谢您耐心的读完本篇文章。欢迎加QQ讨论群


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?