K8S学习笔记-helm
https://github.com/helm/helm/blob/master/docs/charts.md
什么是 Helm
在没使用 helm 之前,向 kubernetes 部署应用,我们要依次部署 deployment、svc 等,步骤较繁琐。况且随着很多项目微服务化,复杂的应用在容器中部署以及管理显得较为复杂,helm 通过打包的方式,支持发布的版本管理和控制,很大程度上简化了 Kubernetes 应用的部署和管理
Helm 本质就是让 K8s 的应用管理(Deployment,Service 等 ) 可配置,能动态生成。通过动态生成 K8s 资源清单文件(deployment.yaml,service.yaml)。然后调用 Kubectl 自动执行 K8s 资源部署
Helm 是官方提供的类似于 YUM 的包管理器,是部署环境的流程封装。Helm 有两个重要的概念:chart 和 release
- chart 是创建一个应用的信息集合,包括各种 Kubernetes 对象的配置模板、参数定义、依赖关系、文档说明等。chart 是应用部署的自包含逻辑单元。可以将 chart 想象成 apt、yum 中的软件安装包
- release 是 chart 的运行实例,代表了一个正在运行的应用。当 chart 被安装到 Kubernetes 集群,就生成一个 release。chart 能够多次安装到同一个集群,每次安装都是一个 release
Helm 包含两个组件:Helm 客户端和 Tiller 服务器,如下图所示
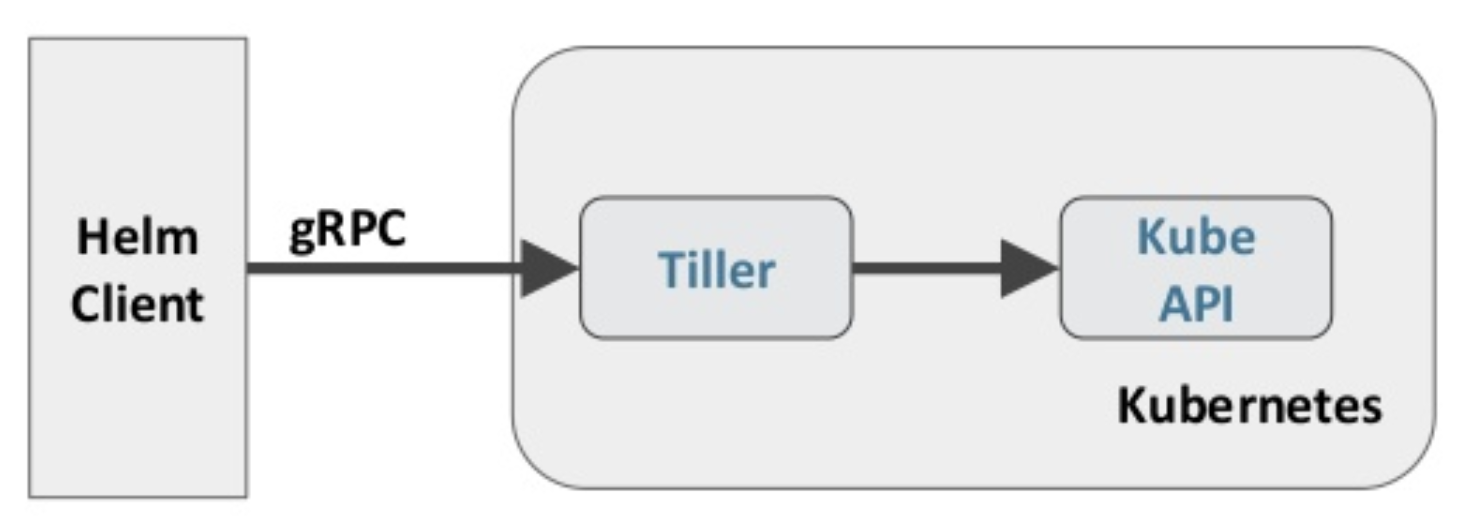
Helm 客户端负责 chart 和 release 的创建和管理以及和 Tiller 的交互。Tiller 服务器运行在 Kubernetes 集群中,它会处理 Helm 客户端的请求,与 Kubernetes API Server 交互
Helm 部署
越来越多的公司和团队开始使用 Helm 这个 Kubernetes 的包管理器,我们也将使用 Helm 安装 Kubernetes 的常用组件。 Helm 由客户端命 helm 令行工具和服务端 tiller 组成,Helm 的安装十分简单。 下载 helm 命令行工具到 master 节点 node1 的 /usr/local/bin 下,这里下载的 2.13. 1版本:
$ ntpdate ntp1.aliyun.com
$ wget https://storage.googleapis.com/kubernetes-helm/helm-v2.13.1-linux-amd64.tar.gz
$ tar -zxvf helm-v2.13.1-linux-amd64.tar.gz
$ cd linux-amd64/
$ cp helm /usr/local/bin/
为了安装服务端 tiller,还需要在这台机器上配置好 kubectl 工具和 kubeconfig 文件,确保 kubectl 工具可以在这台机器上访问 apiserver 且正常使用。 这里的 node1 节点以及配置好了 kubectl
因为 Kubernetes APIServer 开启了 RBAC 访问控制,所以需要创建 tiller 使用的 service account: tiller 并分配合适的角色给它。 详细内容可以查看helm文档中的 Role-based Access Control。 这里简单起见直接分配 cluster- admin 这个集群内置的 ClusterRole 给它。创建 rbac-config.yaml 文件:
apiVersion: v1
kind: ServiceAccount
metadata:
name: tiller
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: tiller
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: tiller
namespace: kube-system
$ kubectl create -f rbac-config.yaml
serviceaccount/tiller created
clusterrolebinding.rbac.authorization.k8s.io/tiller created
$ helm init --service-account tiller --skip-refresh
tiller 默认被部署在 k8s 集群中的 kube-system 这个namespace 下
$ kubectl get pod -n kube-system -l app=helm
NAME READY STATUS RESTARTS AGE
tiller-deploy-c4fd4cd68-dwkhv 1/1 Running 0 83s
$ helm version
Client: &version.Version{SemVer:"v2.13.1", GitCommit:"618447cbf203d147601b4b9bd7f8c37a5d39fbb4", GitTreeState:"clean"}
Server: &version.Version{SemVer:"v2.13.1", GitCommit:"618447cbf203d147601b4b9bd7f8c37a5d39fbb4", GitTreeState:"clean"}
Helm 自定义模板
# 创建文件夹
$ mkdir ./hello-world
$ cd ./hello-world
# 创建自描述文件 Chart.yaml , 这个文件必须有 name 和 version 定义
$ cat <<'EOF' > ./Chart.yaml
name: hello-world
version: 1.0.0
EOF
# 创建模板文件, 用于生成 Kubernetes 资源清单(manifests)
$ mkdir ./templates
$ cat <<'EOF' > ./templates/deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: hello-world
spec:
replicas: 1
template:
metadata:
labels:
app: hello-world
spec:
containers:
- name: hello-world
image: hub.atguigu.com/library/myapp:v1
ports:
- containerPort: 8080
protocol: TCP
EOF
$ cat <<'EOF' > ./templates/service.yaml
apiVersion: v1
kind: Service
metadata:
name: hello-world
spec:
type: NodePort
ports:
- port: 8080
targetPort: 8080
protocol: TCP
selector:
app: hello-world
EOF
# 使用命令 helm install RELATIVE_PATH_TO_CHART 创建一次Release
$ helm install .
# 列出已经部署的 Release
$ helm ls
# 查询一个特定的 Release 的状态
$ helm status RELEASE_NAME
# 移除所有与这个 Release 相关的 Kubernetes 资源
$ helm delete cautious-shrimp
# helm rollback RELEASE_NAME REVISION_NUMBER
$ helm rollback cautious-shrimp 1
# 使用 helm delete --purge RELEASE_NAME 移除所有与指定 Release 相关的 Kubernetes 资源和所有这个 Release 的记录
$ helm delete --purge cautious-shrimp
$ helm ls --deleted
# 配置体现在配置文件 values.yaml
$ cat <<'EOF' > ./values.yaml
image:
repository: gcr.io/google-samples/node-hello
tag: '1.0'
EOF
# 这个文件中定义的值,在模板文件中可以通过 .VAlues对象访问到
$ cat <<'EOF' > ./templates/deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: hello-world
spec:
replicas: 1
template:
metadata:
labels:
app: hello-world
spec:
containers:
- name: hello-world
image: {{ .Values.image.repository }}:{{ .Values.image.tag }}
ports:
- containerPort: 8080
protocol: TCP
EOF
# 在 values.yaml 中的值可以被部署 release 时用到的参数 --values YAML_FILE_PATH 或 --set key1=value1, key2=value2 覆盖掉
$ helm install --set image.tag='latest' .
# 升级版本
helm upgrade -f values.yaml test .
Debug
# 使用模板动态生成K8s资源清单,非常需要能提前预览生成的结果。
# 使用--dry-run --debug 选项来打印出生成的清单文件内容,而不执行部署
helm install . --dry-run --debug --set image.tag=latest
使用Helm部署 dashboard
kubernetes-dashboard.yaml:
image:
repository: k8s.gcr.io/kubernetes-dashboard-amd64
tag: v1.10.1
ingress:
enabled: true
hosts:
- k8s.frognew.com
annotations:
nginx.ingress.kubernetes.io/ssl-redirect: "true"
nginx.ingress.kubernetes.io/backend-protocol: "HTTPS"
tls:
- secretName: frognew-com-tls-secret
hosts:
- k8s.frognew.com
rbac:
clusterAdminRole: true
$ helm install stable/kubernetes-dashboard \
-n kubernetes-dashboard \
--namespace kube-system \
-f kubernetes-dashboard.yaml
$ kubectl -n kube-system get secret | grep kubernetes-dashboard-token kubernetes.io/service-account-token 3 3m7s
$ kubectl describe -n kube-system secret/kubernetes-dashboard-token-pkm2s
$ kubectl edit svc kubernetes-dashboard -n kube-system
修改 ClusterIP 为 NodePort
typora-root-url: Png
Operator 是何物
Kubernetes Operator 是一种封装、部署和管理 Kubernetes 应用的方法。我们使用 Kubernetes API(应用编程接口)和 kubectl 工具在 Kubernetes 上部署并管理 Kubernetes 应用
相关地址信息
Prometheus github 地址:https://github.com/coreos/kube-prometheus
组件说明
1.MetricServer:是 kubernetes 集群资源使用情况的聚合器,收集数据给 kubernetes 集群内使用,如kubectl,hpa,scheduler等
2.PrometheusOperator:是一个系统监测和警报工具箱,用来存储监控数据
3.NodeExporter:用于各 node 的关键度量指标状态数据
4.KubeStateMetrics:收集k ubernetes 集群内资源对象数据,制定告警规则
5.Prometheus:采用pull方式收集 apiserver,scheduler,controller-manager,kubelet 组件数据,通过http 协议传输
6、Grafana:是可视化数据统计和监控平台
构建记录
$ git clone https://github.com/coreos/kube-prometheus.git
cd /root/kube-prometheus/manifests
修改 grafana-service.yaml 文件,使用 nodepode 方式访问 grafana:
$ vim grafana-service.yaml
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: monitoring
spec:
type: NodePort #添加内容
ports:
- name: http
port: 3000
targetPort: http
nodePort: 30100 #添加内容
selector:
app: grafana
修改 prometheus-service.yaml,改为 nodepode
$ vim prometheus-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
prometheus: k8s
name: prometheus-k8s
namespace: monitoring
spec:
type: NodePort
ports:
- name: web
port: 9090
targetPort: web
nodePort: 30200
selector:
app: prometheus
prometheus: k8s
修改 alertmanager-service.yaml,改为 nodepode
vim alertmanager-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
alertmanager: main
name: alertmanager-main
namespace: monitoring
spec:
type: NodePort
ports:
- name: web
port: 9093
targetPort: web
nodePort: 30300
selector:
alertmanager: main
app: alertmanager
Horizontal Pod Autoscaling
HPA 可以根据 CPU 利用率自动伸缩 RC、Deployment、RS 中的 Pod 数量
$ kubectl run php-apache --image=wangyanglinux/hpa:latest --requests=cpu=200m --expose --port=80
创建 HPA 控制器
$ kubectl autoscale deployment php-apache --cpu-percent=50 --min=2 --max=10
增加负载,查看负载节点数目
$ kubectl run -i --tty work --image=busybox /bin/sh
while true; do wget -q -O- http://php-apache.default.svc.cluster.local; done
资源限制 - Pod
Kubernetes 对资源的限制实际上是通过 CGROUP 来控制的,CGROUP 是容器的一组用来控制内核如果运行进程的相关属性集合。针对内存、CPU、和各种设备都有对应的 CGROUP
默认情况下,Pod 运行没有 CPU 和内存的限额。这意味着系统中任何 Pod 将能够执行该节点所有的运算资源,消耗足够多的 CPU 和内存。一般会针对某些应用的 Pod 资源进行资源限制,这个资源限制是通过 resources 的 requests 和 limits 来实现
spec:
containers:
- image: wangyanglinux/myapp:v1
name: auth
resources:
limits:
cpu: "4"
memory: 2Gi
requests:
cpu: 250m
memory: 250Mi
requests 要分配的资源,limits 为最高请求的资源,可以理解为初始值和最大值
资源限制 - 名称空间
一、计算资源配额
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
namespace: spark-cluster
spec:
hard:
requests.cpu: "20"
requests.memory: 100Gi
limits.cpu: "40"
limits.memory: 200Gi
二、配置对象数量配额限制
apiVersion: v1
kind: ResourceQuota
metadata:
name: object-counts
namespace: spark-cluster
spec:
hard:
pods: "20"
configmaps: "10"
persistentvolumeclaims: "4"
replicationcontrollers: "20"
secrets: "10"
services: "10"
services.loadbalancers: "2"
三、配置 CPU 和 内存 limitrange
apiVersion: v1
kind: LimitRange
metadata:
name: mem-limit-range
namespace: example
spec:
limits:
- default: # 默认限制值
memory: 512Mi
cpu: 2
defaultRequest: # 默认请求值
memory: 256Mi
cpu: 0.5
max: # 最大的资源限制
memory: 800Mi
cpu: 3
min: # 最小限制
memory: 100Mi
cpu: 0.3
maxLimitRequestRatio: # 超售值
memory: 2
cpu: 2
type: Container # Container / Pod / PersistentVolumeClaim
添加 Google incubator 仓库
helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator
部署 Elasticsearch
kubectl create namespace efk
helm fetch incubator/elasticsearch
helm install --name els1 --namespace=efk -f values.yaml incubator/elasticsearch
kubectl run cirror-$RANDOM --rm -it --image=cirros -- /bin/sh
curl Elasticsearch:Port/_cat/nodes
部署 Fluentd
helm fetch stable/fluentd-elasticsearch
vim values.yaml
# 更改其中 Elasticsearch 访问地址
helm install --name flu1 --namespace=efk -f values.yaml stable/fluentd-elasticsearch
部署 kibana
helm fetch stable/kibana --version 0.14.8
helm install --name kib1 --namespace=efk -f values.yaml stable/kibana --version 0.14.8

 浙公网安备 33010602011771号
浙公网安备 33010602011771号