k8S中部署Filebeat+ELK日志系统
一. 概述
ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。新增了一个FileBeat,它是一个轻量级的日志收集处理工具(Agent),Filebeat占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具。
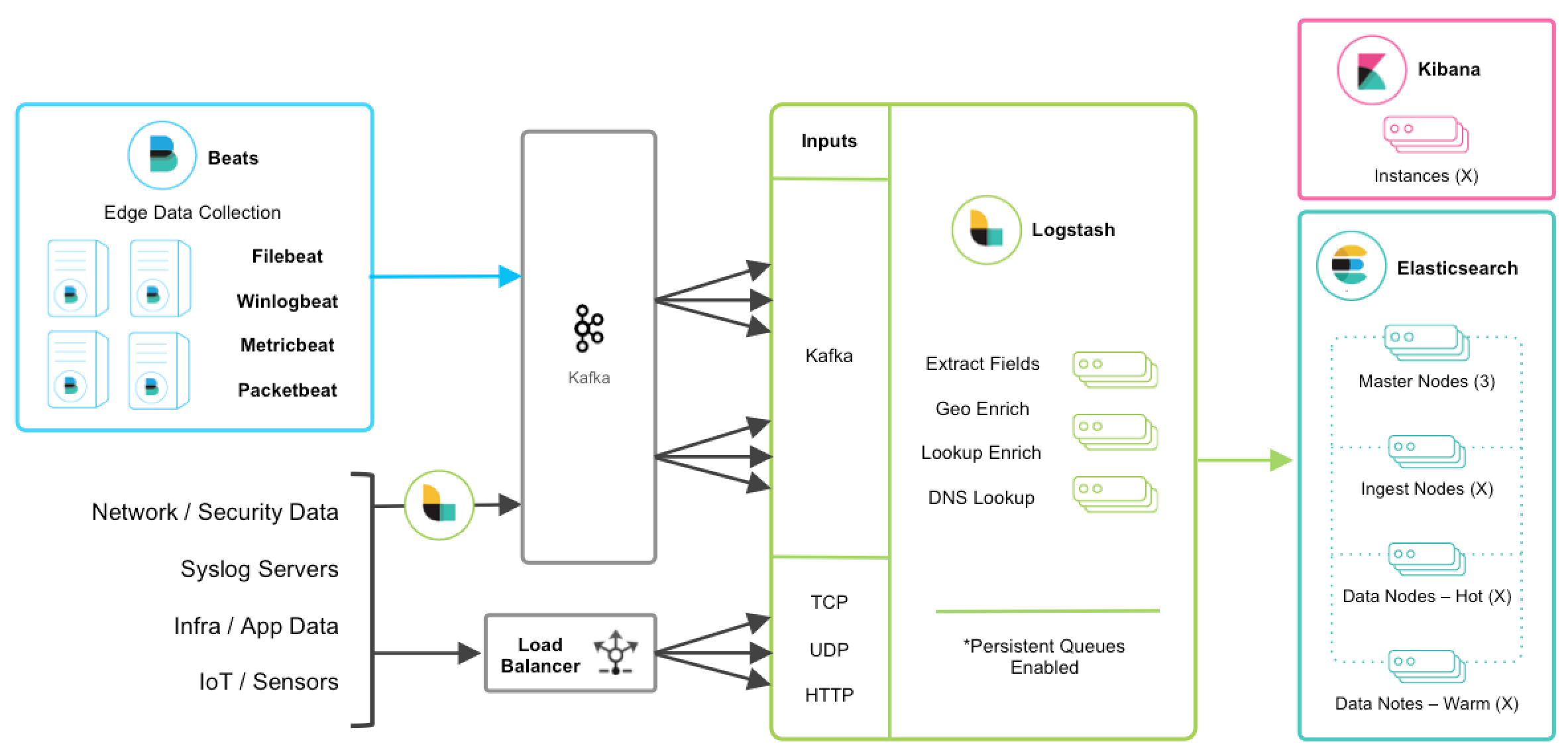
1.1 Elasticsearch 存储#
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
1.2 Filebeat 日志数据采集#
filebeat是Beats中的一员,Beats在是一个轻量级日志采集器,其实Beats家族有6个成员,早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、cpu、io等资源消耗比较高。相比Logstash,Beats所占系统的CPU和内存几乎可以忽略不计。
Filebeat是用于转发和集中日志数据的轻量级传送工具。Filebeat监视您指定的日志文件或位置,收集日志事件。
1.3 Kafka#
Kafka是一种高吞吐量的分布式发布订阅消息系统,它能帮助我们削峰。ELK也可以使用redis作为消息队列,但redis作为消息队列不是强项而且redis集群不如专业的消息发布系统kafka。
1.4 Logstash 过滤#
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
1.5 Kibana 展示#
Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
二. 架构介绍
2.1 最简单的 ELK 架构#
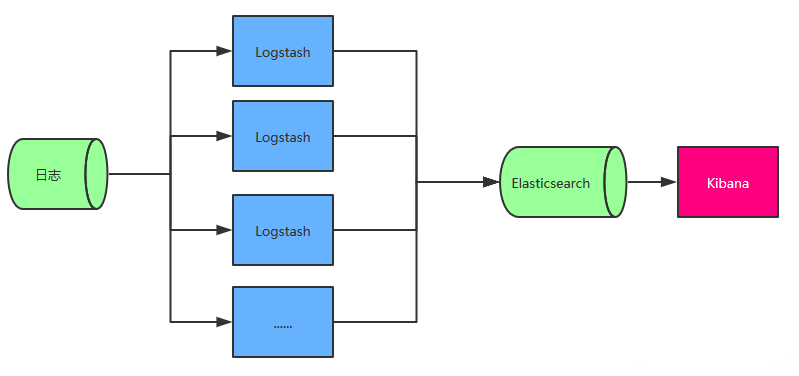
图中 Logstash 多个的原因是考虑到程序是分布式架构的情况,每台机器都需要部署一个 Logstash,如果确实是单服务器的情况部署一个 Logstash 即可。
此架构的优点是搭建简单,易于上手。缺点是Logstash消耗系统资源比较大,运行时占用CPU和内存资源较高。另外,由于没有消息队列缓存,可能存在数据丢失的风险,适合于数据量小的环境使用。
2.2 引入 Kafka 的典型 ELK 架构#
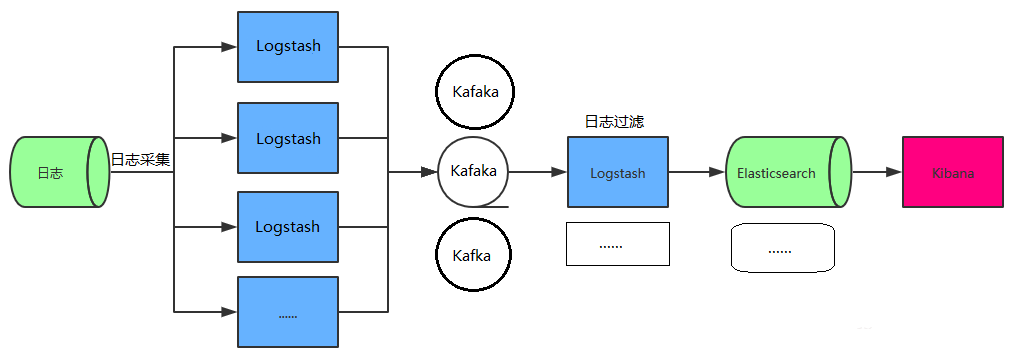
为保证日志传输数据的可靠性和稳定性,引入Kafka作为消息缓冲队列,位于各个节点上的Logstash Agent(一级Logstash,主要用来传输数据)先将数据传递给消息队列,接着,Logstash server(二级Logstash,主要用来拉取消息队列数据,过滤并分析数据)将格式化的数据传递给Elasticsearch进行存储。最后,由Kibana将日志和数据呈现给用户。由于引入了Kafka缓冲机制,即使远端Logstash server因故障停止运行,数据也不会丢失,可靠性得到了大大的提升。
该架构优点在于引入了消息队列机制,提升日志数据的可靠性,但依然存在Logstash占用系统资源过多的问题,在海量数据应用场景下,可能会出现性能瓶颈。
2.3 FileBeats + Kafka + ELK 集群架构#
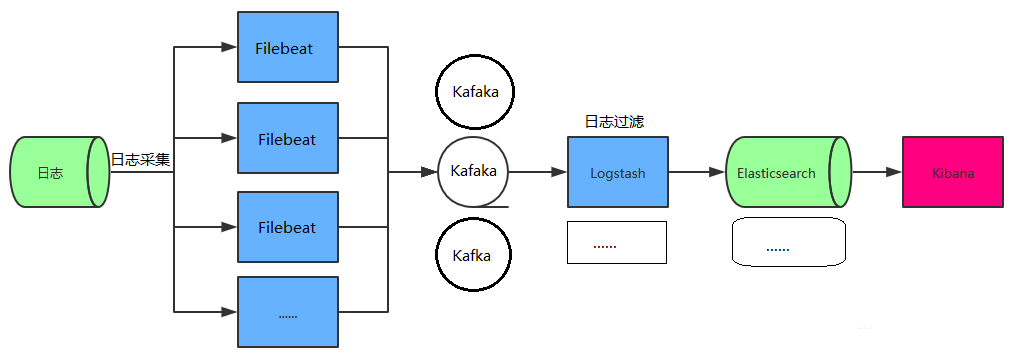
日志采集器Logstash其功能虽然强大,但是它依赖java、在数据量大的时候,Logstash进程会消耗过多的系统资源,这将严重影响业务系统的性能,而filebeat就是一个完美的替代者,它基于Go语言没有任何依赖,配置文件简单,格式明了,同时filebeat比logstash更加轻量级,所以占用系统资源极少,非常适合安装在生产机器上。这就是推荐使用filebeat,也是 ELK Stack 在 Agent 的第一选择。
此架构适合大型集群、海量数据的业务场景,它通过将前端Logstash Agent替换成filebeat,有效降低了收集日志对业务系统资源的消耗。同时,消息队列使用kafka集群架构,有效保障了收集数据的安全性和稳定性,而后端Logstash和Elasticsearch均采用集群模式搭建,从整体上提高了ELK系统的高效性、扩展性和吞吐量。我所在的项目组采用的就是这套架构,由于生产所需的配置较高,且涉及较多持久化操作,采用的都是性能高配的云主机搭建方式而非时下流行的容器搭建。
三. 部署(简化版本)
通过sidecar模式进行接入Filebeat(就是一个pod中部署两个容器,一个跑应用,一个采集日志,用emptdir的共享目录形式),把收集上来的信息直接发送到Elasticsearch中,在kibana中使用Kibana Query Language(KQL)语法进行查询
Elasticsearch 8.5.0
Filebeat 8.5.0
Kibana 8.5.0
3.1 Filebeat#
Configmap
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat
namespace: default
data:
log: |-
filebeat.inputs:
- type: log
enabled: true
paths:
- /app/storage/logs/access.log
processors:
- decode_json_fields:
fields: [ 'message' ]
target: "d"
overwrite_keys: false
process_array: false
max_depth: 1
tags: ["access"]
- type: log
enabled: true
paths:
- /app/storage/logs/error.log
processors:
- decode_json_fields:
fields: [ 'message' ]
target: "d"
overwrite_keys: false
process_array: false
max_depth: 1
tags: [ "error" ]
output.elasticsearch:
hosts: ["http://elasticsearch:9200"]
indices:
- index: "flow-access-%{[agent.version]}-%{+yyyy.MM.dd}"
when.contains:
tags: "access"
- index: "flow-error-%{[agent.version]}-%{+yyyy.MM.dd}"
when.contains:
tags: "error"
setup.template.enabled: true
setup.template.name: "flow"
setup.template.pattern: "flow-*"
setup.template.overwrite: false
setup.ilm.enabled: false
创建一个deployment资源,包含两个容器
apiVersion: apps/v1
kind: Deployment
metadata:
name: flow
namespace: default
spec:
replicas: 1
selector:
matchLabels:
workload.user.cattle.io/workloadselector: apps.deployment-default-flow
template:
metadata:
labels:
workload.user.cattle.io/workloadselector: apps.deployment-default-flow
spec:
containers:
- image: registry.cn-zhangjiakou.aliyuncs.com/lain-txl/flow # 应用镜像
imagePullPolicy: Always
name: flow
ports:
- containerPort: 80
name: 80tcp30002
protocol: TCP
volumeMounts:
- mountPath: /app/application.yml
name: application
subPath: application
- mountPath: /app/storage/logs # 共享的日志目录
name: storage-logs
- args:
- -c
- /config/filebeat.yml
image: docker.elastic.co/beats/filebeat:8.5.0
imagePullPolicy: Always
name: flow-log
volumeMounts:
- mountPath: /config/filebeat.yml # Filebeat 配置
name: log
subPath: log
- mountPath: /app/storage/logs # 共享的日志目录
name: storage-logs
volumes:
- emptyDir: {}
name: storage-logs
- configMap:
defaultMode: 429
name: flow
name: application
- configMap:
defaultMode: 429
name: filebeat
name: log
3.2 Elasticsearch#
Configmap
apiVersion: v1
kind: ConfigMap
metadata:
name: elasticsearch
namespace: default
data:
es1: |-
cluster.name: "docker-cluster"
network.host: 0.0.0.0
node.name: "es1"
cluster.initial_master_nodes: "es1"
#----------------------- BEGIN SECURITY AUTO CONFIGURATION -----------------------
#
# The following settings, TLS certificates, and keys have been automatically
# generated to configure Elasticsearch security features on 12-11-2022 11:29:11
#
# --------------------------------------------------------------------------------
# Enable security features
xpack.security.enabled: false
xpack.security.enrollment.enabled: true
# Enable encryption for HTTP API client connections, such as Kibana, Logstash, and Agents
xpack.security.http.ssl:
enabled: false
# Enable encryption and mutual authentication between cluster nodes
xpack.security.transport.ssl:
enabled: false
# Create a new cluster with the current node only
# Additional nodes can still join the cluster later
#----------------------- END SECURITY AUTO CONFIGURATION -------------------------
http.cors.enabled: true
http.cors.allow-origin: "*"
http.host: 0.0.0.0
Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
workload.user.cattle.io/workloadselector: apps.deployment-default-elasticsearch
name: elasticsearch
namespace: default
spec:
selector:
matchLabels:
workload.user.cattle.io/workloadselector: apps.deployment-default-elasticsearch
template:
metadata:
labels:
workload.user.cattle.io/workloadselector: apps.deployment-default-elasticsearch
spec:
containers:
- image: docker.elastic.co/elasticsearch/elasticsearch:8.5.0
imagePullPolicy: IfNotPresent
name: elasticsearch
ports:
- containerPort: 9200
name: 9200tcp
protocol: TCP
volumeMounts:
- mountPath: /usr/share/elasticsearch/config/elasticsearch.yml
name: elasticsearch
subPath: es1
volumes:
- configMap:
defaultMode: 429
name: elasticsearch
name: elasticsearch
3.3 Kibana#
Configmap
apiVersion: v1
kind: ConfigMap
metadata:
name: kibana
namespace: default
data:
kibana: |-
server.host: "0.0.0.0"
server.shutdownTimeout: "5s"
elasticsearch.hosts: [ "http://elasticsearch:9200" ]
elasticsearch.requestTimeout: 90000
xpack.encryptedSavedObjects.encryptionKey: 8fd1bcc0bfd4bffeea55c71cdf4213d3
xpack.reporting.encryptionKey: 692b708a150cb15f28f02590f9cec02d
xpack.security.encryptionKey: 7713f26f14f8aa5b683ca146524fa97e
xpack.reporting.kibanaServer.hostname: localhost
i18n.locale: "zh-CN"
Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
workload.user.cattle.io/workloadselector: apps.deployment-default-kibana
name: kibana
namespace: default
spec:
selector:
matchLabels:
workload.user.cattle.io/workloadselector: apps.deployment-default-kibana
template:
metadata:
labels:
workload.user.cattle.io/workloadselector: apps.deployment-default-kibana
spec:
containers:
- image: docker.elastic.co/kibana/kibana:8.5.0
imagePullPolicy: IfNotPresent
name: kibana
ports:
- containerPort: 5601
name: 5601tcp30001
protocol: TCP
volumeMounts:
- mountPath: /usr/share/kibana/config/kibana.yml
name: kibana
subPath: kibana
volumes:
- configMap:
defaultMode: 429
name: kibana
name: kibana
四. 验证

可以使用KQL搜索过滤
五. 总结
综上,通过上面部署命令来实现 ELK 的整套组件,包含了日志收集、过滤、索引和可视化的全部流程,基于这套系统实现分析日志功能。同时,通过水平扩展 Kafka、Elasticsearch 集群,可以实现日均亿级的日志实时存储与处理,但是从细节方面来看,这套系统还存着许多可以继续优化和改进的点:
- 日志格式需优化,每个系统收集的日志格式需要约定一个标准,比如各个业务系统在定义log4j或logback日志partern时可以按照【时间】【级别】【全局Traceid】【线程号】【方法名】【日志信息】统一输出。
- Logstash的正则优化,一旦约定了日志模式,编写Logstash的自定义grok正则就能过滤出关键属性存放于ES,那么基于时间、traceId以及方法名的查询则不在堆积于message,大大优化查询效率。
- TraceId埋点优化,分布式与微服务架构中,一个Restful请求的发起可能会经过多达十几个系统的处理流程,任何一个环节都有error可能,需要有一个全局ID进行全链路追踪,这里需要结合Java探针把tiraceId埋入日志模板里,现有PinPoint、SkyWalking与ZipKin都能为全局ID提供成熟的解决方案。
- ES存储优化,按照线上机器的业务量来看,每天TB级的日志数据都写入ES会造成较大的存储压力,时间越久的日志利用价值则越低,可以按照7天有效期来自动清理ES索引优化存储空间,参考【ES清理脚本】(https://www.cnblogs.com/richardzgt/articles/9685112.html)。
- 运维优化,一个复杂日志平台在运维方面有着巨大的成本,这里涉及到了Kafka、ZooKeeper、ELK等多个集群环境的维护,除了提供统一的集群操作指令以外,也需要形成对整套日志平台环境的监控视图。
- 性能优化,多组件、混合语言、分布式环境与集群林立的复杂系统,性能问题老生常谈,实践出真知,遇到了再补充!
参考:
企业级日志系统架构ELK
filebeat+ELK+kafka 架构体系 运行原理
详解Kibana中的KQL语法
Kibana:Kibana Query Language - KQL
使用 fluent-bit 采集文件



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了