软工实践寒假作业(2/2)
| 这个作业属于哪个课程 | 2020春S班 |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | GitHub使用,代码规范制定,分析程序需求,进行程序编码,博客撰写 |
| 作业正文 | 正文 |
| 其他参考文献 | CSDN,Github,博客园等 |
一、Github仓库地址
作业主仓库: https://github.com/numb-men/InfectStatistic-main
个人Github仓库:https://github.com/tangxiaoxiong/InfectStatistic-main
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 15 |
| Estimate | 估计这个任务需要多少时间 | 40 | 35 |
| Development | 开发 | 40 | 45 |
| Analysis | 需求分析 (包括学习新技术) | 120 | 100 |
| Design Spec | 生成设计文档 | 40 | 45 |
| Design Review | 设计复审 | 20 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 60 | 60 |
| Design | 具体设计 | 120 | 100 |
| Coding | 具体编码 | 1000 | 1020 |
| Code Review | 代码复审 | 20 | 15 |
| Test | 测试(自我测试,修改代码,提交修改) | 400 | 300 |
| Reporting | 报告 | 120 | 100 |
| Test Repor | 测试报告 | 40 | 45 |
| Size Measurement | 计算工作量 | 20 | 25 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 25 |
| 合计 | 2170 | 1850 |
三、解题思路描述

1.解析命令行
首先解析命令行,分离数据,得到参数-log,-out,-date,-province,-type
2.初始化
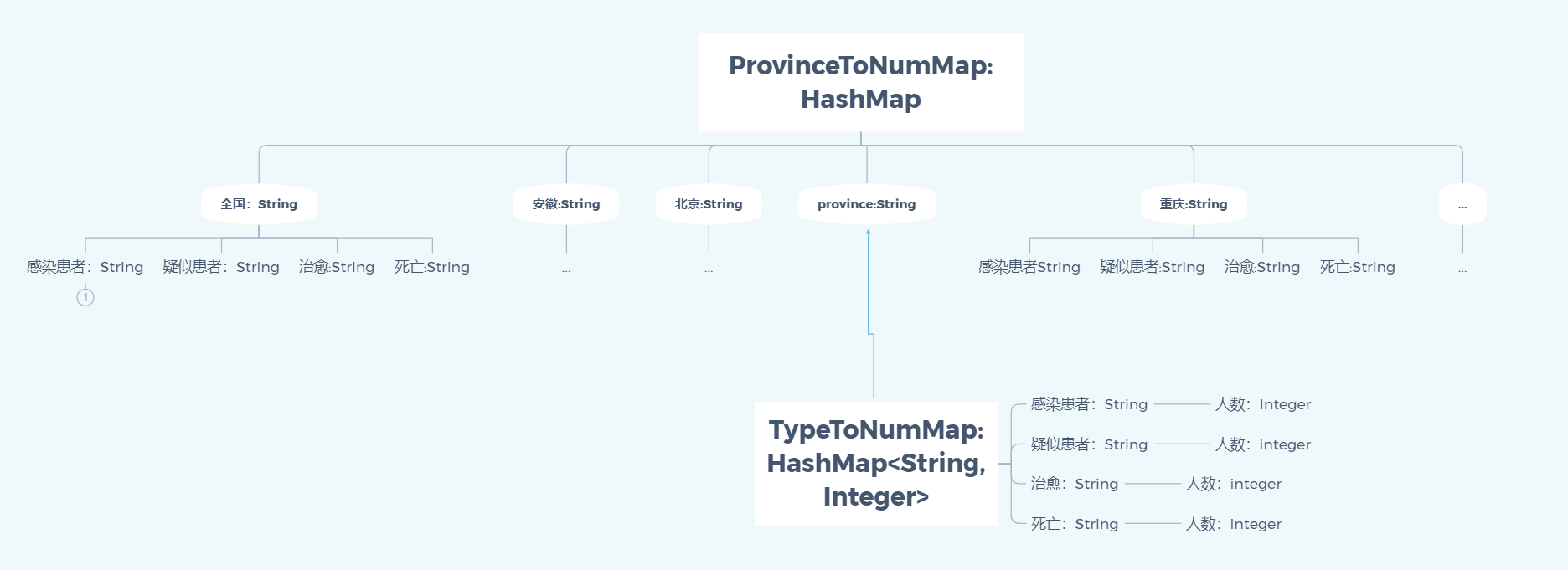
构造一个双层嵌套的哈希表,ProvinceToNumMap<String,<String,Integer>>用于存放省份对应类型的数据,TypeToNumMap<String,Integer>用于存放类型对应的数据
3.读取文件数据
利用-log路径,读取所有不晚于-date的文件,将每行数据都存储在事先初始化好的表与字符串,字符串数组中
4.输出文件数据
利用-out路径,将数据输出到对应的文件加中
四、设计实现过程

首先将整个疫情统计系统拆分成analyseCommandLine,searchFile,outputData三个功能函数,分别用于解析命令行,寻找对应的文件,输出数据。
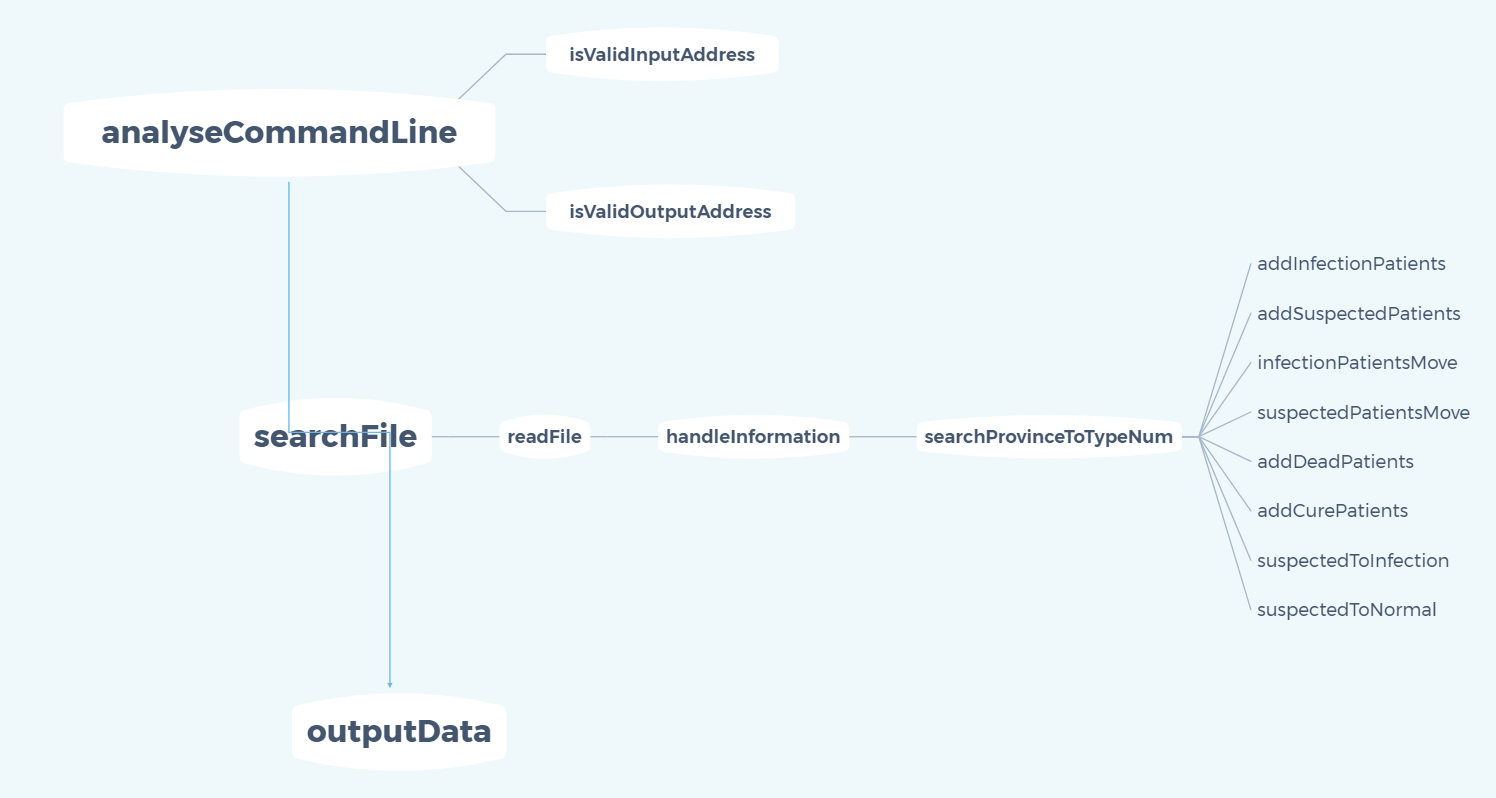
(1)在解析命令行过程中,判断输入路径是否正确,以及输出路径是否正确,以及初始化工作
(2)在查询文件过程中,首先读取符合命题的文件,其次处理文件中的信息handleInformation,在文件中中处理每一行数据时,首先查询对应省份对应类型的人数后,再根据行数据类型不同进行不同处理:
addInfectionPatients(新增感染患者)
addSuspectedPatients(新增疑似患者)
infectionPatientsMove(感染患者流动)
suspectedPatientsMove(疑似患者流动)
addDeadPatients(新增死亡)
addCurePatients(新增治愈)
suspectedToInfection(疑似患者确认感染)
suspectedToNormal(排除疑似患者)
(3)最终再将所有数据输出到指定文件中
五、代码说明
初始化
重点在于哈希表的初始化,关键在于为每一个省份分配一个TypeToNumMap
// 构造一个双层嵌套的哈希表
static HashMap<String, HashMap<String, Integer>> ProvinceToNumMap;
...
static String provinceList[] = { "全国", "安徽", "北京", "重庆", "福建", "甘肃", "广东", "广西", "贵州", "海南", "河北", "河南", "黑龙江",
"湖北", "湖南", "吉林", "江苏", "江西", "辽宁", "内蒙古", "宁夏", "青海", "山东", "山西", "陕西", "上海", "四川", "天津", "西藏", "新疆", "云南",
"浙江" };
public InfectStatistic() {
ProvinceToNumMap = new HashMap<String, HashMap<String, Integer>>();
for (int i = 0; i < provinceList.length; i++) {
HashMap<String, Integer> TypeToNumMap = new HashMap<String, Integer>();
// 初始化TypeToNum哈希表
TypeToNumMap.put("感染患者", 0);
TypeToNumMap.put("疑似患者", 0);
TypeToNumMap.put("治愈", 0);
TypeToNumMap.put("死亡", 0);
ProvinceToNumMap.put(provinceList[i], TypeToNumMap);
}
}
...
// type和province的类型可能不止一种,故创建其字符串list
static List<String> typeList = new LinkedList<>();
static List<String> commandProvinceList = new LinkedList<String>();
解析命令行
比较关键的是在类型分析过程中用到,switch-case的方式,将-type中的ip/sp/cure/dead分别替换为感染患者,疑似患者,治愈和死亡
/*
* 函数功能:解析命令行 输入参数:命令行字符串 输出参数:无
**/
public void analyseCommandLine(String args[]) {
String province, type;
int commandOrder = 0;
if (!args[0].equals("list")) {
System.out.println("命令行的格式有误");
} else {
while (commandOrder < args.length) {
.....
else if (args[commandOrder].equals("-type")) {
type = args[++commandOrder];
// 若类型是不以-开头的,则不断添加到类型列表中
while (!type.startsWith("-")) {
switch (type) {
case "ip":
typeList.add("感染患者");
break;
case "sp":
typeList.add("疑似患者");
break;
case "cure":
typeList.add("治愈");
break;
case "dead":
typeList.add("死亡");
break;
}
if (commandOrder == args.length - 1)
break;
type = args[++commandOrder];
}
......
}
}
// 若args中无-province则加入“全国”
if (isEmptyCommandProvince == true) {
commandProvinceList.add("全国");
}
}
处理文本数据
在此处我犯了一个错误,在书写正则表达式时,没有注意到S的大小写问题,导致后期调试花费许多时间。
/*
* 函数功能:统计省份疫情人数 输入参数:每一行的信息 输出参数:无
**/
public void handleInformation(String lineInformation) {
String lineTypeOne = "(\\S+) 新增 感染患者 (\\d+)人";
String lineTypeTwo = "(\\S+) 新增 疑似患者 (\\d+)人";
String lineTypeThree = "(\\S+) 治愈 (\\d+)人";
String lineTypeFour = "(\\S+) 死亡 (\\d+)人";
String lineTypeFive = "(\\S+) 感染患者 流入 (\\S+) (\\d+)人";
String lineTypeSix = "(\\S+) 疑似患者 流入 (\\S+) (\\d+)人";
String lineTypeSeven = "(\\S+) 疑似患者 确诊感染 (\\d+)人";
String lineTypeEight = "(\\S+) 排除 疑似患者 (\\d+)人";
if (Pattern.matches(lineTypeOne, lineInformation)) {
addInfectionPatients(lineInformation);
}
....
}
获取对应省份对应类型的人数
此个函数是后续统计省份对应类型人数的关键函数,主要用到二级嵌套哈希表的循环判断
/*
* 函数功能:获取对应省份对应类型的患者previousNum 输入参数: 省份和类型 输出参数:previousNum
**/
public int searchProvinceToTypeNum(String province, String type) {
// 获取省份对应类型下的患者数量
int previousNum = 0;
Set<String> thisSet = ProvinceToNumMap.keySet();
for (String str : thisSet) {
if (str.equals(province)) {
HashMap<String, Integer> thisMap = ProvinceToNumMap.get(province);
Set<String> typeKeys = thisMap.keySet();
for (String strTwo : typeKeys) {
if (strTwo.equals(type)) {
previousNum = thisMap.get(type);
}
}
}
}
return previousNum;
}
情况处理,数据更新
其余相似函数功能类似
/*
* 函数功能:感染患者增加数据更新 输入参数: 输出参数:
**/
public void addInfectionPatients(String lineInformation) {
// 先将每一行的字符串分隔成字符串数组
String[] linePart = lineInformation.split(" ");
String province = linePart[0];
// 新增感染患者的数量
int num;
// 去除数字后面的“人”,取出单独的数字
num = Integer.valueOf(linePart[3].replaceAll("人", ""));
int previousNum, countryPreviousNum, currentNum, countryCurrentNum;
previousNum = searchProvinceToTypeNum(province, "感染患者");
countryPreviousNum = searchProvinceToTypeNum("全国", "感染患者");
currentNum = num + previousNum;
countryCurrentNum = num + countryPreviousNum;
ProvinceToNumMap.get(province).replace("感染患者", currentNum);
ProvinceToNumMap.get("全国").replace("感染患者", countryCurrentNum);
}
输出数据
根据需求的省份以及类型按规定格式输出数据
/*
* 函数功能:输出统计结果到文件中 输入参数: 输出参数:
**/
public void outputData(String path) {
.....
if (typeList.isEmpty()) {
typeList.add("感染患者");
typeList.add("疑似患者");
typeList.add("治愈");
typeList.add("死亡");
}
for (int i = 0; i < commandProvinceList.size(); i++) {
Set<String> thisSet = ProvinceToNumMap.keySet();
for (String strKey : thisSet) {
if (strKey.equals(commandProvinceList.get(i))) {
writer.write(strKey);
HashMap<String, Integer> TypeToNumValue = ProvinceToNumMap.get(strKey);
for (int j = 0; j < typeList.size(); j++) {
Set<String> set = TypeToNumValue.keySet();
for (String integerKey : set) {
if (integerKey.equals(typeList.get(j))) {
switch (typeList.get(j)) {
case "感染患者":
Integer value = TypeToNumValue.get("感染患者");
writer.write("感染患者" + value + "人" + " ");
break;
case "疑似患者":
Integer value1 = TypeToNumValue.get("疑似患者");
writer.write("疑似患者" + value1 + "人" + " ");
break;
case "治愈":
Integer value2 = TypeToNumValue.get("治愈");
writer.write("治愈" + value2 + "人" + " ");
break;
case "死亡":
Integer value3 = TypeToNumValue.get("死亡");
writer.write("死亡" + value3 + "人" + " ");
break;
}
}
}
}
writer.write("\n");
}
}
}
......
}
六、代码测试
这次我一共编写了13个测试用例,并且全部通过测试
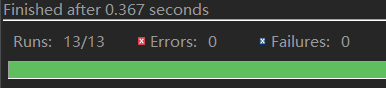
1.若为命令行提供全面完整的信息


2.更改-type的顺序会按typeList添加顺序输出


3.在不提供-type情况下会按照ip,sp,cure,dead顺序输出


4.省份会按照-province添加顺序输出


5.若不提供-province则会先输出全国的数据之后,按照文件中省份出现的顺序输出数据


6.更改-date,系统会统计不同时间之前的数据


7.若不提供-date,则-date会被赋值为文件中最晚的日期


8.若-date大于当前的日期,则系统会报错:日期超出范围


9.若无-province和-type,则系统会按照全国以及文件中出现的省份按照ip,sp,cure,dead顺序输出


10.若没有-province和-date,则会按照日志最晚时间按全国以及日志出现省份顺序输出数据


11.若没有-date和-type,则按日志最晚日期前的所有数据按照ip,sp,cure,dead顺序输出数据


12.若仅有-log和-out则系统会按照日志最晚日期,以ip,sp,cure,dead顺序输出全国以及在日志中出现过的省份的数据


13.若-province中的省份在文件中未出现过,则输出数据0


七、单元测试覆盖优化和性能测试

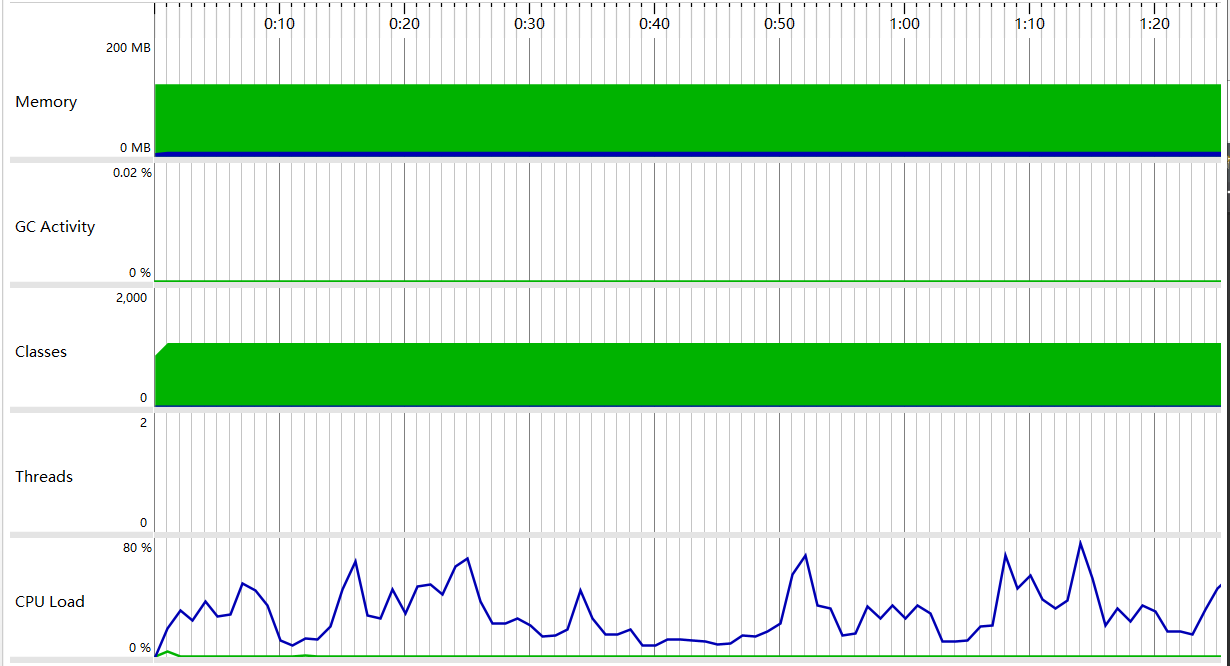
测试了单元覆盖率,达到97.8%,因为在编写测试时就做好代码区块的划分以及函数功能的分隔,已经尽量去掉无法覆盖的代码,做了基本的优化。
以下是性能测试
八、个人代码规范
codeStyle链接:https://github.com/tangxiaoxiong/InfectStatistic-main/blob/master/221701136/codestyle.md
九、心路历程与收获
心路历程: 在这几天里,从第一次看这作业的一头雾水到烦躁,最后认真研读好几遍作业要求,并与舍友讨论了一下大致知道需求之后水落石出,在debug过程中又陷入泥淖,最后一个一个修正之后的豁然开朗。
收获: 在遇到困难的时候,千万不能否定自己,我一开始就是觉得,我一个人在家没有舍友的帮助是不可能独立完成这样的工程,在debug过程也常常在想如果有舍友一同帮助我debug该多好。正是这样无可奈何的环境,才造就了我全程独立自主完成的结果,原来自己也是有这样的能力。还有一点就是,遇到不懂得东西,先自己查阅资料,这几天百度上的各种论坛成为我的伴侣,脑子里有一万个不明白,那就把这些不明白化成一万个知识点。最后一点,只有自己踩过坑,才能继续向前走!
十、技术路线图相关的仓库
1.Spring Boot学习示例
简介:Spring Boot 使用的各种示例,以最简单、最实用为标准,此开源项目中的每个示例都以最小依赖,最简单为标准,帮助初学者快速掌握 Spring Boot 各组件的使用。
2.JavaGuide
简介:Java学习+面试指南 :一份涵盖大部分Java程序员所需要掌握的核心知识
3.JavaEETest
简介:包含了一些关于Spring、SpringMVC、MyBatis、Spring Boot案例
4.3y
简介:从Java基础、JavaWeb基础到常用的框架再到面试题都有完整的教程,几乎涵盖了Java后端必备的知识点
5.JAVAWeb-Project
简介:初学JAVA-WEB开发的小项目,也适合初学者进行练习

