


hive文件存储格式
link:http://blog.csdn.net/yfkiss/article/details/7787742
hive在建表是,可以通过‘STORED AS FILE_FORMAT’ 指定存储文件格式
例如:
- > CREATE EXTERNAL TABLE MYTEST(num INT, name STRING)
- > ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
- > STORED AS TEXTFILE
- > LOCATION '/data/test';
> CREATE EXTERNAL TABLE MYTEST(num INT, name STRING) > ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' > STORED AS TEXTFILE > LOCATION '/data/test';
指定文件存储格式为“TEXTFILE”。
hive文件存储格式包括以下几类:
- TEXTFILE
- SEQUENCEFILE
- RCFILE
- 自定义格式
TEXTFIEL
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。
可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
实例:
- > create table test1(str STRING)
- > STORED AS TEXTFILE;
- OK
- Time taken: 0.786 seconds
- #写脚本生成一个随机字符串文件,导入文件:
- > LOAD DATA LOCAL INPATH '/home/work/data/test.txt' INTO TABLE test1;
- Copying data from file:/home/work/data/test.txt
- Copying file: file:/home/work/data/test.txt
- Loading data to table default.test1
- OK
- Time taken: 0.243 seconds
> create table test1(str STRING) > STORED AS TEXTFILE; OK Time taken: 0.786 seconds #写脚本生成一个随机字符串文件,导入文件: > LOAD DATA LOCAL INPATH '/home/work/data/test.txt' INTO TABLE test1; Copying data from file:/home/work/data/test.txt Copying file: file:/home/work/data/test.txt Loading data to table default.test1 OK Time taken: 0.243 seconds
SEQUENCEFILE:
SequenceFile是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。
SequenceFile支持三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩。
示例:
- > create table test2(str STRING)
- > STORED AS SEQUENCEFILE;
- OK
- Time taken: 5.526 seconds
- hive> SET hive.exec.compress.output=true;
- hive> SET io.seqfile.compression.type=BLOCK;
- hive> INSERT OVERWRITE TABLE test2 SELECT * FROM test1;
> create table test2(str STRING) > STORED AS SEQUENCEFILE; OK Time taken: 5.526 seconds hive> SET hive.exec.compress.output=true; hive> SET io.seqfile.compression.type=BLOCK; hive> INSERT OVERWRITE TABLE test2 SELECT * FROM test1;
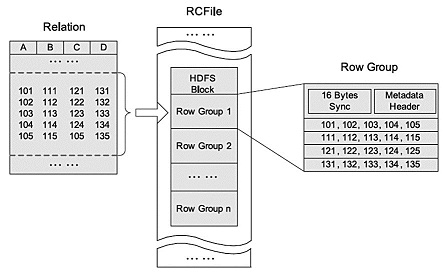
RCFILE
RCFILE是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。RCFILE文件示例:
- > create table test3(str STRING)
- > STORED AS RCFILE;
- OK
- Time taken: 0.184 seconds
- > INSERT OVERWRITE TABLE test3 SELECT * FROM test1;
> create table test3(str STRING) > STORED AS RCFILE; OK Time taken: 0.184 seconds > INSERT OVERWRITE TABLE test3 SELECT * FROM test1;
自定义格式
当用户的数据文件格式不能被当前 Hive 所识别的时候,可以自定义文件格式。
用户可以通过实现inputformat和outputformat来自定义输入输出格式,参考代码:
.\hive-0.8.1\src\contrib\src\java\org\apache\hadoop\hive\contrib\fileformat\base64
实例:
建表
- > create table test4(str STRING)
- > stored as
- > inputformat 'org.apache.hadoop.hive.contrib.fileformat.base64.Base64TextInputFormat'
- > outputformat 'org.apache.hadoop.hive.contrib.fileformat.base64.Base64TextOutputFormat';
> create table test4(str STRING) > stored as > inputformat 'org.apache.hadoop.hive.contrib.fileformat.base64.Base64TextInputFormat' > outputformat 'org.apache.hadoop.hive.contrib.fileformat.base64.Base64TextOutputFormat';
$ cat test1.txt
aGVsbG8saGl2ZQ==
aGVsbG8sd29ybGQ=
aGVsbG8saGFkb29w
test1文件为base64编码后的内容,decode后数据为:
hello,hive
hello,world
hello,hadoop
load数据并查询:
- hive> LOAD DATA LOCAL INPATH '/home/work/test1.txt' INTO TABLE test4;
- Copying data from file:/home/work/test1.txt
- Copying file: file:/home/work/test1.txt
- Loading data to table default.test4
- OK
- Time taken: 4.742 seconds
- hive> select * from test4;
- OK
- hello,hive
- hello,world
- hello,hadoop
- Time taken: 1.953 seconds
hive> LOAD DATA LOCAL INPATH '/home/work/test1.txt' INTO TABLE test4; Copying data from file:/home/work/test1.txt Copying file: file:/home/work/test1.txt Loading data to table default.test4 OK Time taken: 4.742 seconds hive> select * from test4; OK hello,hive hello,world hello,hadoop Time taken: 1.953 seconds
总结:
相比TEXTFILE和SEQUENCEFILE,RCFILE由于列式存储方式,数据加载时性能消耗较大,但是具有较好的压缩比和查询响应。数据仓库的特点是一次写入、多次读取,因此,整体来看,RCFILE相比其余两种格式具有较明显的优势。
reference:
Hive Data Definition Language
浅谈hadoop文件格式
Facebook数据仓库揭秘:RCFile高效存储结构

