ES(evolution strategy)进化策略、RL(reinforcement learning)强化学习
-
进化策略
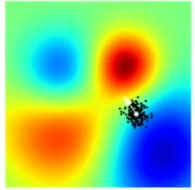
进化策略可被视为这样一个过程:从个体构成的群体中采样并让其中成功的个体引导未来后代的分布。如图中,一个白色箭头是由黑点中的优胜个体引导。
![]()
策略作用方式以交叉熵CEM(一种进化算法)为例:算法先随机初始化参数和确定根据参数生成解的规则,根据参数生成N组解并评价每组解的好坏,选出评估结果在前百分之ρ的解并根据这些精英解采取重要性采样方法更新参数,新参数被用作下一轮生成N组解,如此循环直到收敛。
特别的几点包括:进化策略的实现更加简单(不需要反向传播),更容易在分布式环境中扩展,不会受到奖励稀疏的影响,有更少的超参数。 -
强化学习
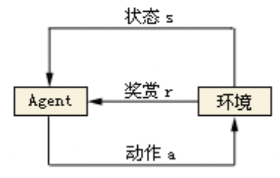
本质是:基于环境而行动,以取得最大化的预期收益。
强化学习具有高分导向性,和监督学习中的标签有些类似。但是又有些区别,区别就在于数据和标签一开始是不存在的,需要模型自己不断摸索。通过不断尝试,找到那些带来高分的行为。强化学习是机器学习中的一个领域,是除监督学习和非监督学习的第三种基本的机器学习方法。<A,S,R,P>就是强化学习中的经典四元组。
![]()
强化学习和有监督学习的区别:
- 有监督学习的训练样本是有标签的,强化学习的训练是没有标签的,它是通过环境给出的奖惩来学习;
- 有监督学习的学习过程是静态的,强化学习的学习过程是动态的。这里静态与动态的区别在于是否会与环境进行交互,有监督学习是给什么样本就学什么,而强化学习是要和环境进行交互,再通过环境给出的奖惩来学习;
- 有监督学习解决的更多是感知问题,尤其是深度学习,强化学习解决的主要是决策问题。因此有监督学习更像是五官,而强化学习更像大脑。
- 两者异同
相同点:两者目标都是预期奖励。
不同点:
- 强化学习是将噪声注入动作空间并使用反向传播来计算参数更新,而进化策略则是直接向参数空间注入噪声。
- RL通过与环境交互来进行学习,而ES通过种群迭代来进行学习;
- 强化学习一般在动作空间(Action Space)进行探索(Exploration)。而相应的Credit或者奖励,必须在动作空间起作用,因此,存在梯度回传(back propagation)。进化算法直接在参数空间探索,不关心动作空间多大,以及对动作空间造成多大影响。
- RL通过最大化累计回报来解决序列问题,而EAs通过最大化适应函数(Fitness Function)来寻求单步最优;
- RL对于state过于依赖,而EA在agent不能准确感知环境的状态类问题上也能适用。
参考:
RL&EA

 浙公网安备 33010602011771号
浙公网安备 33010602011771号