

服务器编程模型
最近看了UNP,这是对服务器编程模型的笔记
1.简单服务器模型(迭代)
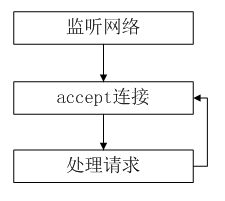
服务器进程接受连接,处理请求,然后等待下一个连接。从进程控制
的角度来说这种模型是最快的,因为没有进程间的切换,但是客户需要等待
在listen中等待服务器accept。
2.多进程模型
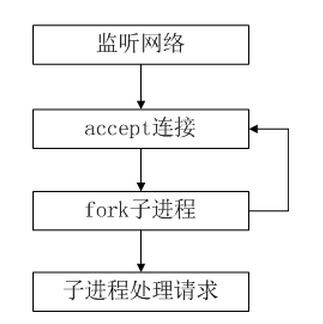
多进程模型适用于单个客户服务需要消耗较多的 CPU 资源,例如需要进行大
规模或长时间的数据运算或文件访问。多进程模型具有较好的安全性。在实现中
需要注意
3.预先分配进程,子进程同时accept
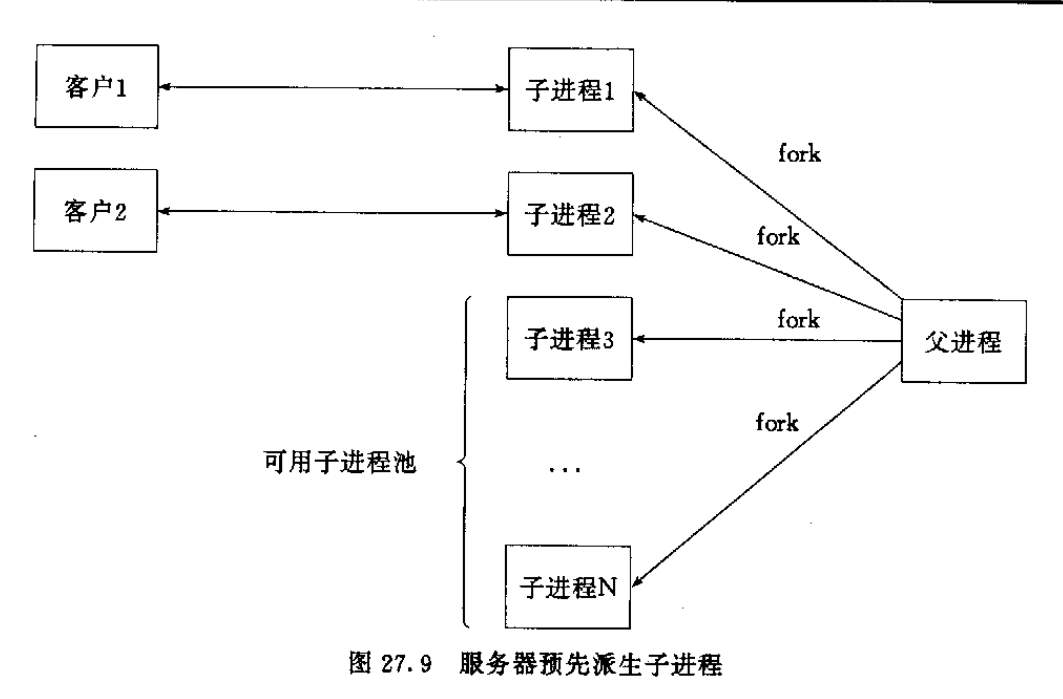
(Apatch 1.1)预先分配一批子进程,同时阻塞在listened套接口上等待客户的到来。
描述符只是某个数组的下标,用于引用一个file结构。fork复制描述符,
并且将file中的 引用计数加1. 所以子进程中描述符所引用的file结构
与父进程中描述符引用的file结构一致。(注意如果使用SVR4内核那么系统
提供的accept是哭喊数,将不支持同时阻塞在同一个套接口上---解决方法是
在各个process调用accept前竞争锁资源-----这里又有两种选择:1.文件锁
2.线程互斥锁+进程间共享内存{pthreead_mutext也可以用于进程互斥})
如图:
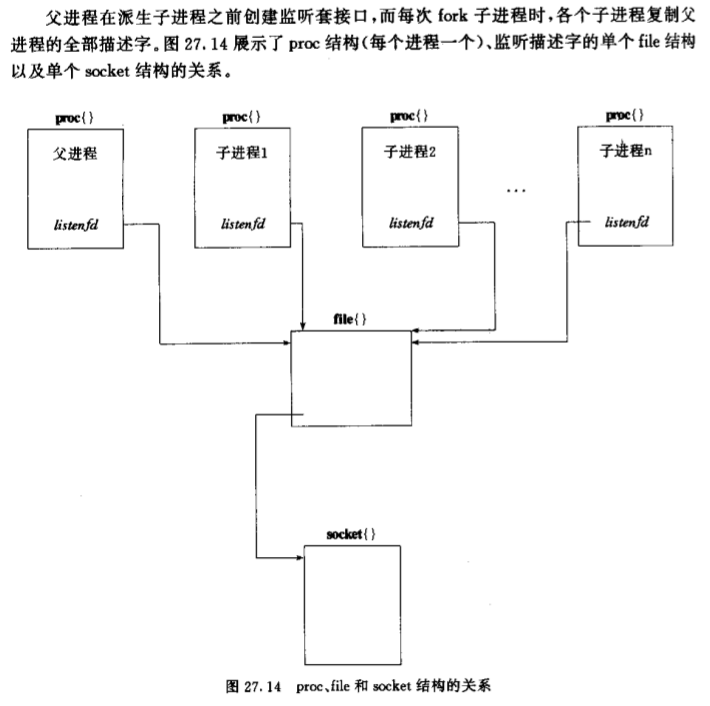
这种模式下N个子进程都调用accept并被内核置入睡眠状态(tsleep).
也就是说这N个进程都睡眠在同一个file结构的等待通道上(wait channel).
当某个客户到来时,N个进程同时被唤醒(惊群),但是只有一个进程能获得链接,
其它进程继续投入睡眠. 详细情况可以参考TCPv2 15.10节对tsleep函数的说明。
惊群(所有process被唤醒进行调度,但是只有1个成功返回,其它继续tsleep)
可能导致性能的下降。
4.预先分配进程,父进程accept
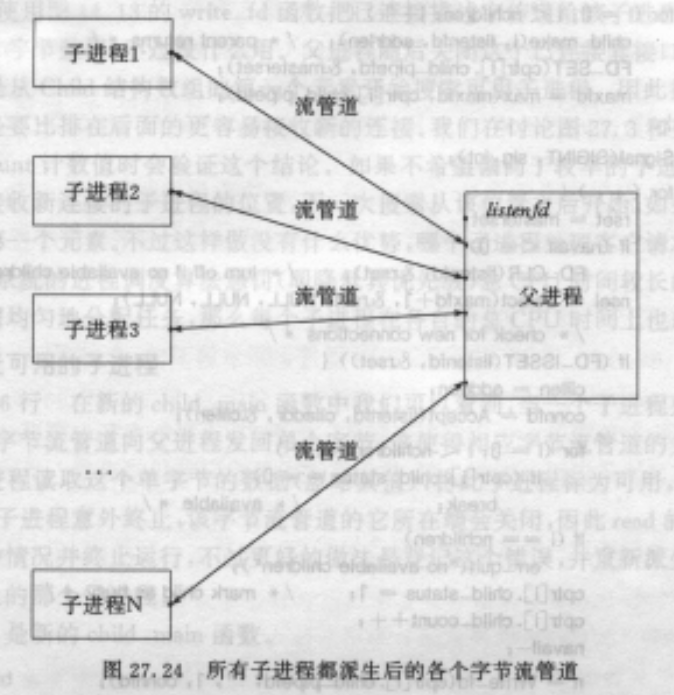
为了避免惊群以及同时accept在同一个监听套接口.可以选择在父进程中accept获得
链接套接口后讲链接套接口传给一个空闲进程。但是这样父进程就得跟踪各个子进程的状态
以便下发任务。
可以选择在孩儿们和父进程之间建立管道进行通信,老爸使用select同时监视listenfd和这N个
管道的fd。
这里的流管道有两个作用:
1.父进程将链接套接口传给子进程.
2.子进程管理:子进程处理完一个链接后写一下管道,导致父进程中的select等待的对应
描述符可读,父进程就知道该儿子闲了(read>0) 或者这个儿子挂了(read=0);
这种模式并不比靠锁进行同步(模式3)的方式快。
5.TCP 每个客户一个线程
每次accept返回connfd后调用pthread_create(&tid, NULL, &doit, (void *)connfd)
创建一个新线程(执行doit),在doit中detach不用主进程等自己,doit执行完后关闭connfd。
优势:线程调度轻于进程; connfd共享,不用传递。比前面的几个进程版本都快。
注意线程安全
6.TCP 预先分配线程池,同时accept
之前发现预先分配进程比每次单独分配快,那么我们现在搞一个线程池会有优化么?
思路:是预先创建N个thread,并循环的 用互斥锁互斥调用accept,处理链接,等待下一个链接。
如果内核支持同时多个accept阻塞在同一个fd上,可以减少加锁的代价,但是会产生惊群的消耗。
结果:很快
7.TCP 预先分配线程池,主线程accept
那么现在的问题就变成了怎么把获得的connfd交给子线程了,也就是一个典型的生产-消费问题。
使用
1. pthread_mutext : 竞争访问connfdseq.
2. pthread_cond_signal : 如果connfdseq空等待资源并释放mutext
可以解决。
结果:比6要慢一些
8.TCP 单进程, 使用select
即便是使用线程减少了调度的代价,但是代价还是有的,而且同步也需要机器的资源。
并且每个线程也要占用一定的资源来保存自己的一些信息(3M?)。既然大多数调用都是阻塞在
了IO上,那为什么我们不把这些IO操作交给内核管理呢? 这不久是select,pool的作用么?
将listenfd和connfd都交给select,返回是判断如果是listenfd好了,那么调用accept得到
connfd并且将其也放入select; 如果是某个connfd好了那就进行读写对客户进行服务。
最近在看的web.py 以及 torrando都是使用这种方式,并且有较高的效率(有epool等异步io的帮助)。

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步