内容梳理——第1章-统计学习方法概论
1.1 统计学习
统计学习是计算机基于数据,构建统计概率模型,并运用该模型进行预测和分析。。。更偏向于概率统计模型;
学习指系统通过执行某个过程改善其自身的性能;
统计学习的对象就是数据,它是去学习数据的规律的;
统计学习的目的就是去对未知数据进行预测;
统计学习的方法有监督学习,非监督学习,半监督学习,强化学习等;
统计学习的步骤:
·1)得到有限的训练数据集;
2)确定适合这个训练集的所有可能的模型的假设空间,即学习模型的集合;
3)确定怎么选择模型的准则,即学习的策略;
4)实现求解最优模型的算法,即学习的算法;
5)通过学习方法找到最优模型;
6)利用最优模型,进行预测
统计学习的三要素:模型,策略,算法(因为这3个是人要自己动脑想的)
1.2 监督学习
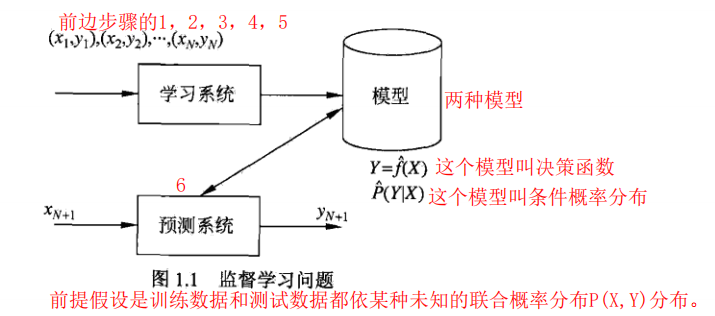
因为学习的过程需要训练数据,训练数据是人工给出的,所以叫监督学习;
监督学习的输入被叫做输入空间,输出被叫做输出空间,输入空间由特征向量组成;
根据输入输出数据的形式;输入和输出均连续的叫做回归问题,输出是离散的叫做分类问题,输入和输出均为变量序列的叫标注问题;
统计学习假设数据存在着一定的统计规律,即X和Y符合某种未知的联合概率分布;
假设空间就是函数的集合,它表明了输入到输出的映射;
1.3 统计学习三要素
统计学习方法 = 模型+策略+算法
两种模型:决策函数表示的模型为非概率模型,条件概率表示的模型为概率模型;
策略:按照什么样的规则来找到最优的模型;
损失函数的形式有多种,将某个具体数据代入得到实际输出和预测输出的差值;
损失函数的期望就是风险函数,也叫期望损失;
训练集的平均损失叫做经验风险;
当训练集最够大,经验风险就接近期望风险,但一般训练集数据有限,用经验风险评估期望风险常不理想,要对经验风险进行一定的矫正,从而有了结构风险;
结构风险 = 经验风险+表明模型复杂度的正则项;
根据学习策略,从假设空间种选择最优模型,然后用算法来求解最优模型;
1.4 模型评估和模型选择
训练误差的平均就是经验风险;
测试误差是测试数据的平均损失;
测试误差比训练误差更有意义一些;
只根据经验风险最小来选模型可能导致模型过拟合;从而可以使用正则化和交叉验证;
1.6 泛化能力
泛化能力只该方法学到的模型对未知数据的预测能力;
因为测试数据集是有限的,由它得到的评价结果是不可靠的;统计学理论试图从理论上对学习方法的泛化能力进行分析;
泛化误差就是测试误差的期望;
泛化误差上届是在假设空间中,训练误差最小的模型,它的泛化误差上界为:训练误差+要给参数项
1.7 生成模型与判别模型
生成方法得到的模型叫做生成模型,判别方法得到的模型叫做判别模型;
生成模型关心输入X和Y的生成关系;判别模型关系给定X,应该给什么Y;
1.8 分类问题
区分是否为分类问题看输出是否为离散的。
分类问题包括学习和分类两个过程,实际就是学习和预测两个过程,学习系统学习一个分类器(P(Y|X)或Y=f(X))。
评估其性能指标:分类准确率:分类正确的样本数 / 总样本数
1.9 标注问题
分类问题的推广>>标注问题的复杂化>>结构预测问题
标注问题的目标在于学习一个模型,使得它能够对观测序列,给出其预测的标记序列。
1.10 回归问题
回归问题的学习等价于学习一条函数曲线,进行拟合数据
根据输入变量的个数分为一元回归和多元回归,根据输入变量
