Python学习29
python—简单数据抓取六(安装scrapy环境并创建爬虫项目、以顶点小说网为例利用scrapy进行爬取、scrapy相关的注意事项)
学习内容:
- 学习使用scrapy
1、安装scrapy环境并创建爬虫项目
2、以顶点小说网为例利用scrapy进行爬取
3、scrapy相关的注意事项
1、安装scrapy环境并创建爬虫项目
windows电脑的cmd中输入canda install scrapy安装scrapy环境
scrapy爬虫为异步,在爬取的过程中就可能会出现显示顺序不一致
cmd到项目需要保存的位置,输入scrapy startproject 项目名创建项目
cd到项目下,scrapy genspider app名+爬取的网址 (项目下网站的一段网址作为app的名字)
运行scrapy是在cdm中输入:scrapy crawl 爬虫app名,点回车运行某个爬虫
scrapy运行流程:
2、以顶点小说网为例利用scrapy进行爬取
1、根据项目创建流程创建出顶点项目
2、进入app进行相关爬虫的编写,将爬取的顶点数据转入item购物车
在app23us中,编写主要的代码
import scrapy
from dingdian.items import DingdianItem
class A23usSpider(scrapy.Spider):
# 爬虫的名字,在terminal运行爬虫时,scrapy crawl 23us 即末尾加上爬虫的名字
name = '23us'
allowed_domains = ['www.23us.com']
# start_urls是爬虫自带的,它所请求的东西可以给到对应的parse方法
# start_urls = ['https://www.23us.com/class/'+str(type)+'_1.html' for type in range(1, 11)]
# parse方法
# def _parse(self, response):
# 将start_urls请求到的内容返回到parse方法,并打印出
# print(response.url)
# 这是比较自主的scrapy自带的方法,可以改写一些内容,比start_urls更方便
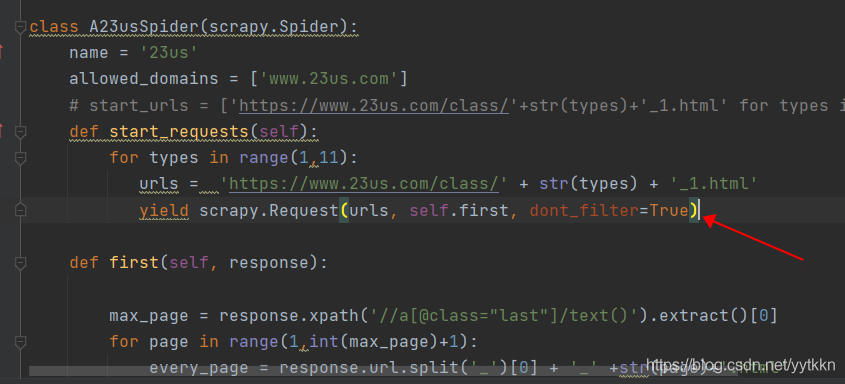
def start_requests(self):
for types in range(1, 11):
# 这里请求到顶点小说的十个大分类的连接
urls = 'https://www.23us.com/class/'+str(types)+'_1.html'
# 并且关系到下面的first方法,start_requests方法获取的东西都传给first方法
yield scrapy.Request(urls, self.first)
def first(self, response):
print(response.url)
# 在十个大分类的连接中xpath匹配到每一分类的最大页数,并从列表中取值出来
max_page = response.xpath('//a[@class="last"]/text()').extract()[0]
print(max_page)
# 循环每个大分类的每一页的连接并打印出来
for page in range(1, int(max_page)+1):
every_page = response.url.split('_')[0]+'_'+str(page)+'.html'
# 关系到下面的show方法,frist方法获取到的所有东西都传给show方法
yield scrapy.Request(every_page, self.show)
def show(self, response):
# item是scrapy的暂存库可以理解为购物车,此处是将item实例化
item = DingdianItem()
# 接frist方法的每一页的链接获取页面内容,提取出抓取内容xpath的公共部分为base
base = response.xpath('//*[@id="content"]/dd[1]/table//tr')
# 循环base中的元素,并分别获取后续的相关内容
for i in base:
book_name = i.xpath('td[1]/a[2]/text()').extract_first()
book_author = i.xpath('td[3]/text()').extract_first()
# 将获取的相关内容插入到item中
item['book_name'] = book_name
item['book_author'] = book_author
yield item
同时item的代码为:
import scrapy
class DingdianItem(scrapy.Item):
# define the fields for your item here like:
book_name = scrapy.Field()
book_author = scrapy.Field()
3、在__init.py__文件的request中存在dont_filter=False,为去重
注意它的作用,可能会因为去重造成相似的数据丢失
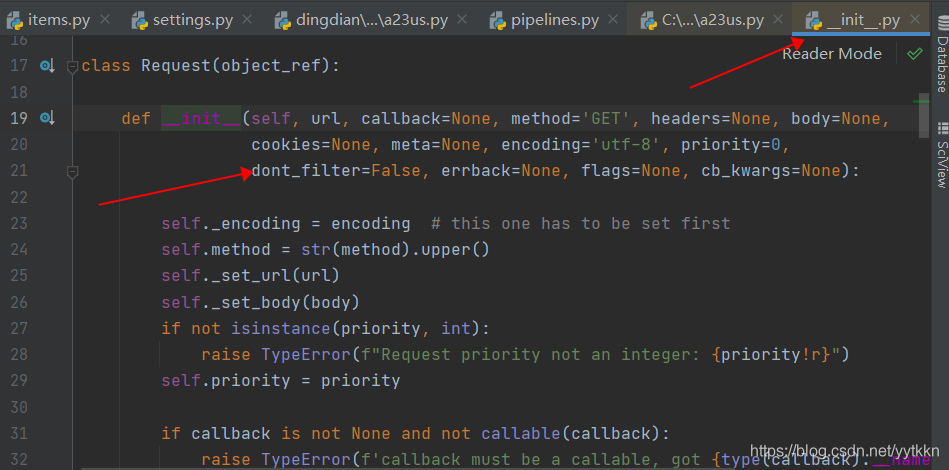
可以在request请求网页显示内容时引用dont_filter,可以为true或者false
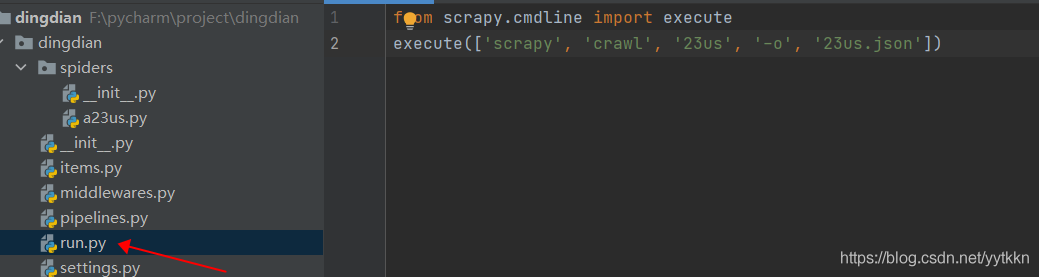
4、为了运行的方便可以创建一个启动py文件
23us为创建的app名

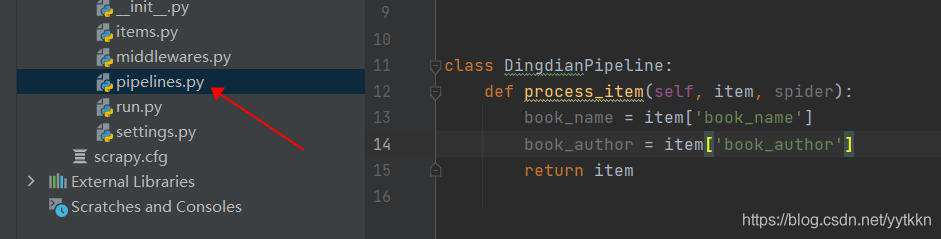
5、存入item购物车的数据需要到pipelines.py文件中取出利用
在pipelines中取出数据的同时,可以在该文件中编写数据库入库的相关代码
3、scrapy相关的注意事项
1、在scrapy运行时,应该注意setting文件中相关的内容要打开注解
pipelines注解,如果不打开,pipeline将不能正常取出数据
ITEM_PIPELINES = {
'dingdian.pipelines.DingdianPipeline': 300,
}
守约文件,需关闭,不然会影响爬取数据的完整性
ROBOTSTXT_OBEY = False
2、向项目中添加header头
在app中的request中直接添加相关header头
在setting中找到header头的位置,直接添加全局的header头,所有请求将使用该header头
在在setting中找到header头的位置,添加全局的公共header头,然后在需要添加特殊header头的请求添加其他部分header头(爬虫执行时会先执行代码中的header头,再执行setting中的header头)
在middlewares.py文件中,找到process_request方法,在该方法中可以编写代码判断不同的爬虫名,采用不同的header头
3、middlewares.py文件中的process_request方法和process_response方法
process_request方法:
返回response时,不经过downloader,直接返回到spiders
返回request时,就会进入一个无限循环
返回IgnoreRequest时,就是转到process_exception方法,重新编写方法
process_response方法
代理IP在此方法中添加
返回request时,将请求任务重新调度申请链接
返回response时,将下载器下载的内容正常放回送
4、将scrapy爬取的数据保存为json数据
在转json之前,数据应该先存入到item购物车
在terminal输入命令进行转json:scrapy crawl 23us(爬虫app名) -o 23us.json(保存的json文件名)
生成的json文件:
可以直接在爬取数据时将数据转为json,即在启动时就输入json转换命令,将指令写入启动py文件