实时数仓项目-01实时模块搭建
学习资料收集于尚硅谷
一、实时模块搭建
1、创建模块gmall-realtime
<properties>
<spark.version>2.4.0</spark.version>
<scala.version>2.11.8</scala.version>
<kafka.version>1.0.0</kafka.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.56</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-spark</artifactId>
<version>4.14.2-HBase-1.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>io.searchbox</groupId>
<artifactId>jest</artifactId>
<version>5.3.3</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>net.java.dev.jna</groupId>
<artifactId>jna</artifactId>
<version>4.5.2</version>
</dependency>
<dependency>
<groupId>org.codehaus.janino</groupId>
<artifactId>commons-compiler</artifactId>
<version>2.7.8</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 该插件用于将Scala代码编译成class文件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.6</version>
<executions>
<execution>
<!-- 声明绑定到maven的compile阶段 -->
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
2、创建配置文件config.properties
# Kafka配置
kafka.broker.list=cdh01:9092,cdh02:9092,cdh03:9092
# Redis配置
redis.host=cdh01
redis.port=6379
3、PropertiesUtil
package com.learning.realtime.util
import java.io.InputStreamReader
import java.util.Properties
object PropertiesUtil {
def main(args: Array[String]): Unit = {
val properties: Properties = PropertiesUtil.load("config.properties")
println(properties.getProperty("kafka.broker.list"))
}
def load(propertieName:String): Properties ={
val prop=new Properties();
prop.load(new InputStreamReader(Thread.currentThread().getContextClassLoader.getResourceAsStream(propertieName) , "UTF-8"))
prop
}
}
4、KafkaUtil
package com.learning.realtime.util
import java.util.Properties
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
object KafkaUtil {
private val properties: Properties = PropertiesUtil.load("config.properties")
val broker_list = properties.getProperty("kafka.broker.list")
// kafka消费者配置
var kafkaParam = collection.mutable.Map(
"bootstrap.servers" -> broker_list,//用于初始化链接到集群的地址
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
//用于标识这个消费者属于哪个消费团体
"group.id" -> "gmall_consumer_group",
//如果没有初始化偏移量或者当前的偏移量不存在任何服务器上,可以使用这个配置属性
//可以使用这个配置,latest自动重置偏移量为最新的偏移量
"auto.offset.reset" -> "latest",
//如果是true,则这个消费者的偏移量会在后台自动提交,但是kafka宕机容易丢失数据
//如果是false,会需要手动维护kafka偏移量
"enable.auto.commit" -> (true: java.lang.Boolean)
)
// 创建DStream,返回接收到的输入数据
// LocationStrategies:根据给定的主题和集群地址创建consumer
// LocationStrategies.PreferConsistent:持续的在所有Executor之间分配分区
// ConsumerStrategies:选择如何在Driver和Executor上创建和配置Kafka Consumer
// ConsumerStrategies.Subscribe:订阅一系列主题
def getKafkaStream(topic: String,ssc:StreamingContext ): InputDStream[ConsumerRecord[String,String]]={
val dStream = KafkaUtils.createDirectStream[String,String](ssc, LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String,String](Array(topic),kafkaParam ))
dStream
}
def getKafkaStream(topic: String,ssc:StreamingContext,groupId:String): InputDStream[ConsumerRecord[String,String]]={
kafkaParam("group.id")=groupId
val dStream = KafkaUtils.createDirectStream[String,String](ssc, LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String,String](Array(topic),kafkaParam ))
dStream
}
def getKafkaStream(topic: String,ssc:StreamingContext,offsets:Map[TopicPartition,Long],groupId:String): InputDStream[ConsumerRecord[String,String]]={
kafkaParam("group.id")=groupId
val dStream = KafkaUtils.createDirectStream[String,String](ssc, LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String,String](Array(topic),kafkaParam,offsets))
dStream
}
}
5、RedisUtil
package com.learning.realtime.util
import redis.clients.jedis.{Jedis, JedisPool, JedisPoolConfig}
object RedisUtil {
var jedisPool:JedisPool=null
def getJedisClient: Jedis = {
if(jedisPool==null){
// println("开辟一个连接池")
val config = PropertiesUtil.load("config.properties")
val host = config.getProperty("redis.host")
val port = config.getProperty("redis.port")
val jedisPoolConfig = new JedisPoolConfig()
jedisPoolConfig.setMaxTotal(100) //最大连接数
jedisPoolConfig.setMaxIdle(20) //最大空闲
jedisPoolConfig.setMinIdle(20) //最小空闲
jedisPoolConfig.setBlockWhenExhausted(true) //忙碌时是否等待
jedisPoolConfig.setMaxWaitMillis(500)//忙碌时等待时长 毫秒
jedisPoolConfig.setTestOnBorrow(true) //每次获得连接的进行测试
jedisPool=new JedisPool(jedisPoolConfig,host,port.toInt)
}
// println(s"jedisPool.getNumActive = ${jedisPool.getNumActive}")
// println("获得一个连接")
jedisPool.getResource
}
}
6、log4j.properties
log4j.appender.atguigu.MyConsole=org.apache.log4j.ConsoleAppender
log4j.appender.atguigu.MyConsole.target=System.out
log4j.appender.atguigu.MyConsole.layout=org.apache.log4j.PatternLayout
log4j.appender.atguigu.MyConsole.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %10p (%c:%M) - %m%n
log4j.rootLogger =error,atguigu.MyConsole
7、业务类DauApp
package com.learning.realtime.app
import java.text.SimpleDateFormat
import java.util.Date
import com.alibaba.fastjson.{JSON, JSONObject}
import com.learning.realtime.util.KafkaUtil
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object DauApp {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("dau_app")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val groupId = "GMALL_DAU_CONSUMER"
val topic = "GMALL_STARTUP"
val startupInputDstream: InputDStream[ConsumerRecord[String, String]] = KafkaUtil.getKafkaStream(topic, ssc)
val startLogInfoDStream: DStream[JSONObject] = startupInputDstream.map { record =>
val startupJson: String = record.value()
val startupJSONObj: JSONObject = JSON.parseObject(startupJson)
val ts: Long = startupJSONObj.getLong("ts")
val dateHourStr: String = new SimpleDateFormat("yyyy-MM-dd :HH").format(new Date(ts))
val dateHour = dateHourStr.split(" ")
startupJSONObj.put("dt",dateHour(0))
startupJSONObj.put("hr",dateHour(1))
startupJSONObj
}
startLogInfoDStream.print(100)
ssc.start()
ssc.awaitTermination()
}
}
8、启动
在cdh01启动
/opt/module/nginx/sbin/nginx
cdh01、cdh02、cdh03
java -jar /opt/gmall/gmall-logger-0.0.1-SNAPSHOT.jar >/dev/null 2>&1 &
启动日志生成器 在cdh01
java -jar /opt/applog/gmall2020-mock-log-2020-05-10.jar
在idea中启动DauApp。
如果idea控制台能够打印出数据,初步搭建成功。
二、Redis去重
redis安装参考REDIES归一化文档
在cdh01启动redis
/usr/local/redis/bin/redis-server /usr/local/redis/bin/redis.conf
val filterDstream = startLogInfoDStream.mapPartitions{itr => {
val filterList: ListBuffer[JSONObject] = new ListBuffer[JSONObject]
val jedisClient = RedisUtil.getJedisClient
//把迭代器的数据提取到对象中,便于观察
val listJsonObjs: List[JSONObject] = itr.toList
println("过滤前:" + listJsonObjs.size)
for (jsonObj <- listJsonObjs) {
val dt = jsonObj.getString("dt")
val mid = jsonObj.getJSONObject("common").getString("mid")
var daukey = "dau:" + dt
val res = jedisClient.sadd(daukey, mid) //如果不存在,保存,返回1,如果已经存在,不保存,返回0
if (res == 1L) {
filterList += jsonObj
}
}
jedisClient.close()
println("过滤后:" + filterList.size)
filterList.toIterator
}}
filterDstream.print(1)
三、数据保存到ES
3.1创建索引模板
PUT _template/gmall_dau_info_template
{
"index_patterns": ["gmall_dau_info*"],
"settings": {
"number_of_shards": 3
},
"aliases" : {
"{index}-query": {},
"gmall_dau_info-query":{}
},
"mappings": {
"_doc":{
"properties":{
"mid":{
"type":"keyword"
},
"uid":{
"type":"keyword"
},
"ar":{
"type":"keyword"
},
"ch":{
"type":"keyword"
},
"vc":{
"type":"keyword"
},
"dt":{
"type":"keyword"
},
"hr":{
"type":"keyword"
},
"mi":{
"type":"keyword"
},
"ts":{
"type":"date"
}
}
}
}
}
3.2创建case class
case class DauInfo(
mid:String,
uid:String,
ar:String,
ch:String,
vc:String,
var dt:String,
var hr:String,
var mi:String,
ts:Long) {
}
3.3 添加依赖
<dependency>
<groupId>io.searchbox</groupId>
<artifactId>jest</artifactId>
<version>5.3.3</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>net.java.dev.jna</groupId>
<artifactId>jna</artifactId>
<version>4.5.2</version>
</dependency>
<dependency>
<groupId>org.codehaus.janino</groupId>
<artifactId>commons-compiler</artifactId>
<version>2.7.8</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.elasticsearch/elasticsearch -->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>2.4.6</version>
</dependency>
3.4 添加批量保存的方法
def bulkInsert(sourceList:List[Any],indexName:String): Unit ={
if(sourceList != null && sourceList.size >0){
val jest: JestClient = getClient
val builder: Bulk.Builder = new Bulk.Builder
for ( source<- sourceList ) {
val index: Index = new Index.Builder(source).index(indexName).`type`("_doc").build()
builder.addAction(index)
}
val result: BulkResult = jest.execute(builder.build())
val items: util.List[BulkResult#BulkResultItem] = result.getItems
println("保存到ES中的条数:"+items.size())
jest.close()
}
}
3.5主流程代码
filterDstream.foreachRDD(rdd=>{
rdd.foreachPartition( itr =>{
val list: List[JSONObject] = itr.toList
val dauinfoList: List[DauInfo] = list.map(jsonObj => {
val commonJSONObj: JSONObject = jsonObj.getJSONObject("common")
DauInfo(
commonJSONObj.getString("mid"),
commonJSONObj.getString("uid"),
commonJSONObj.getString("ar"),
commonJSONObj.getString("ch"),
commonJSONObj.getString("vc"),
jsonObj.getString("dt"),
jsonObj.getString("hr"),
"00",
jsonObj.getLong("ts")
)
})
val dt: String = new SimpleDateFormat("yyyy-MM-dd").format(new Date())
EsUtils.bulkInsert(dauinfoList,"gmall_dau_info_"+dt)
})
})
3.6清空redis中的数据
./redis-cli
flushall
3.7查询数据
GET gmall_dau_info-query/_search
四、精确一次消费
4.1 定义
精确一次消费(Exactly-once) 是指消息一定会被处理且只会被处理一次。不多不少就一次处理。
如果达不到精确一次消费,可能会达到另外两种情况:
至少一次消费(at least once),主要是保证数据不会丢失,但有可能存在数据重复问题。
最多一次消费(at most once),主要是保证数据不会重复,但有可能存在数据丢失问题。
如果同时解决了数据丢失和数据重复的问题,那么就实现了精确一次消费的语义了。
4.2 问题如何产生
数据何时会丢失: 比如实时计算任务进行计算,到数据结果存盘之前,进程崩溃,假设在进程崩溃前kafka调整了偏移量,那么kafka就会认为数据已经被处理过,即使进程重启,kafka也会从新的偏移量开始,所以之前没有保存的数据就被丢失掉了。
数据何时会重复: 如果数据计算结果已经存盘了,在kafka调整偏移量之前,进程崩溃,那么kafka会认为数据没有被消费,进程重启,会重新从旧的偏移量开始,那么数据就会被2次消费,又会被存盘,数据就被存了2遍,造成数据重复。
4.3 如何解决
策略一:利用关系型数据库的事务进行处理。
出现丢失或者重复的问题,核心就是偏移量的提交与数据的保存,不是原子性的。如果能做成要么数据保存和偏移量都成功,要么两个失败。那么就不会出现丢失或者重复了。
这样的话可以把存数据和偏移量放到一个事务里。这样就做到前面的成功,如果后面做失败了,就回滚前面那么就达成了原子性。
问题与限制
但是这种方式有限制就是数据必须都要放在某一个关系型数据库中,无法使用其他功能强大的nosql数据库。如果保存的数据量较大一个数据库节点不够,多个节点的话,还要考虑分布式事务的问题。
策略二:手动提交偏移量+幂等性处理
咱们知道如果能够同时解决数据丢失和数据重复问题,就等于做到了精确一次消费。
那咱们就各个击破。
首先解决数据丢失问题,办法就是要等数据保存成功后再提交偏移量,所以就必须手工来控制偏移量的提交时机。
但是如果数据保存了,没等偏移量提交进程挂了,数据会被重复消费。怎么办?那就要把数据的保存做成幂等性保存。即同一批数据反复保存多次,数据不会翻倍,保存一次和保存一百次的效果是一样的。如果能做到这个,就达到了幂等性保存,就不用担心数据会重复了。
难点
话虽如此,在实际的开发中手动提交偏移量其实不难,难的是幂等性的保存,有的时候并不一定能保证。所以有的时候只能优先保证的数据不丢失。数据重复难以避免。即只保证了至少一次消费的语义。
五、偏移量管理
本身kafka 0.9版本以后consumer的偏移量是保存在kafka的__consumer_offsets主题中。但是如果用这种方式管理偏移量,有一个限制就是在提交偏移量时,数据流的元素结构不能发生转变,即提交偏移量时数据流,必须是InputDStream[ConsumerRecord[String, String]] 这种结构。但是在实际计算中,数据难免发生转变,或聚合,或关联,一旦发生转变,就无法在利用以下语句进行偏移量的提交:
xxDstream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
所以实际生产中通常会利用zookeeper,redis,mysql等工具对偏移量进行保存。
5.1OffsetManager
package com.learning.realtime.util
import java.util
import org.apache.kafka.common.TopicPartition
import org.apache.spark.TaskContext
import org.apache.spark.streaming.kafka010.OffsetRange
import redis.clients.jedis.Jedis
import scala.collection.JavaConversions._
object OffsetManager {
def getOffset(groupId:String,topic:String):Map[TopicPartition,Long]={
var offsetMap=Map[TopicPartition,Long]()
val jedisClient: Jedis = RedisUtil.getJedisClient
val redisOffsetMap: util.Map[String, String] = jedisClient.hgetAll("offset:"+groupId+":"+topic)
jedisClient.close()
if(redisOffsetMap!=null&&redisOffsetMap.isEmpty){
null
}else {
val redisOffsetList: List[(String, String)] = redisOffsetMap.toList
val kafkaOffsetList: List[(TopicPartition, Long)] = redisOffsetList.map { case ( partition, offset) =>
println("加载分区偏移量:"+partition+"\t start:->"+offset)
(new TopicPartition(topic, partition.toInt), offset.toLong)
}
kafkaOffsetList.toMap
}
}
/**
* 偏移量写入到Redis中
* @param groupId
* @param topic
* @param offsetArray
*/
def saveOffset(groupId:String,topic:String ,offsetArray:Array[OffsetRange]):Unit= {
val offsetKey = "offset:" + groupId + ":" + topic
val jedisClient: Jedis = RedisUtil.getJedisClient
var offsetMap: util.HashMap[String, String] = new util.HashMap[String,String]()
for( offset <- offsetArray) {
val partition: Int = offset.partition
val untilOffset: Long = offset.untilOffset
offsetMap.put(partition+"",untilOffset+"")
//观察偏移量
println("写入分区:"+partition+"\t start:->"+offset.fromOffset+"\t end: "+offset)
}
jedisClient.hmset(offsetKey, offsetMap)
jedisClient.close()
}
}
5.2DauApp
完整代码:
package com.learning.realtime.app
import java.text.SimpleDateFormat
import java.util.Date
import com.alibaba.fastjson.{JSON, JSONObject}
import com.learning.realtime.DauInfo
import com.learning.realtime.util.{EsUtils, KafkaUtil, OffsetManager, RedisUtil}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.spark.{SparkConf, TaskContext}
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{HasOffsetRanges, OffsetRange}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable.ListBuffer
object DauApp {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("dau_app")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val groupId = "GMALL_DAU_CONSUMER"
val topic = "GMALL_STARTUP"
//val startupInputDstream: InputDStream[ConsumerRecord[String, String]] = KafkaUtil.getKafkaStream(topic, ssc)
//从redis读取偏移量
val startupOffsets: Map[TopicPartition, Long] = OffsetManager.getOffset(groupId,topic)
var startupInputDstream: InputDStream[ConsumerRecord[String, String]] = null
if(startupOffsets!=null&&startupOffsets.isEmpty){
//根据偏移起始点获得数据
startupInputDstream = KafkaUtil.getKafkaStream(topic, ssc,startupOffsets,groupId)
}else {
startupInputDstream = KafkaUtil.getKafkaStream(topic, ssc)
}
//获得本批次偏移结束点,在transform中的目的是为了给startupOffsetRanges赋值
var startupOffsetRanges: Array[OffsetRange] = Array.empty[OffsetRange]
val startupInputGetOffsetDstream: DStream[ConsumerRecord[String, String]] = startupInputDstream.transform { rdd =>
startupOffsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}
val startLogInfoDStream: DStream[JSONObject] = startupInputGetOffsetDstream.map { record =>
val startupJson: String = record.value()
val startupJSONObj: JSONObject = JSON.parseObject(startupJson)
val ts: Long = startupJSONObj.getLong("ts")
val dateHourStr: String = new SimpleDateFormat("yyyy-MM-dd :HH").format(new Date(ts))
val dateHour = dateHourStr.split(" ")
startupJSONObj.put("dt",dateHour(0))
startupJSONObj.put("hr",dateHour(1))
startupJSONObj
}
//startLogInfoDStream.print(100)
val filterDstream = startLogInfoDStream.mapPartitions{itr => {
val filterList: ListBuffer[JSONObject] = new ListBuffer[JSONObject]
val jedisClient = RedisUtil.getJedisClient
//把迭代器的数据提取到对象中,便于观察
val listJsonObjs: List[JSONObject] = itr.toList
println("过滤前:" + listJsonObjs.size)
for (jsonObj <- listJsonObjs) {
val dt = jsonObj.getString("dt")
val mid = jsonObj.getJSONObject("common").getString("mid")
var daukey = "dau:" + dt
val res = jedisClient.sadd(daukey, mid) //如果不存在,保存,返回1,如果已经存在,不保存,返回0
if (res == 1L) {
filterList += jsonObj
}
}
jedisClient.close()
println("过滤后:" + filterList.size)
filterList.toIterator
}}
filterDstream.foreachRDD(rdd=>{
rdd.foreachPartition( itr =>{
val list: List[JSONObject] = itr.toList
val dauinfoList: List[DauInfo] = list.map(jsonObj => {
val commonJSONObj: JSONObject = jsonObj.getJSONObject("common")
DauInfo(
commonJSONObj.getString("mid"),
commonJSONObj.getString("uid"),
commonJSONObj.getString("ar"),
commonJSONObj.getString("ch"),
commonJSONObj.getString("vc"),
jsonObj.getString("dt"),
jsonObj.getString("hr"),
"00",
jsonObj.getLong("ts")
)
})
val dt: String = new SimpleDateFormat("yyyy-MM-dd").format(new Date())
EsUtils.bulkInsert(dauinfoList,"gmall_dau_info_"+dt)
})
OffsetManager.saveOffset(groupId ,topic, startupOffsetRanges)
})
ssc.start()
ssc.awaitTermination()
}
}
六、kibana搭建数据可视化
6.1创建index patterns
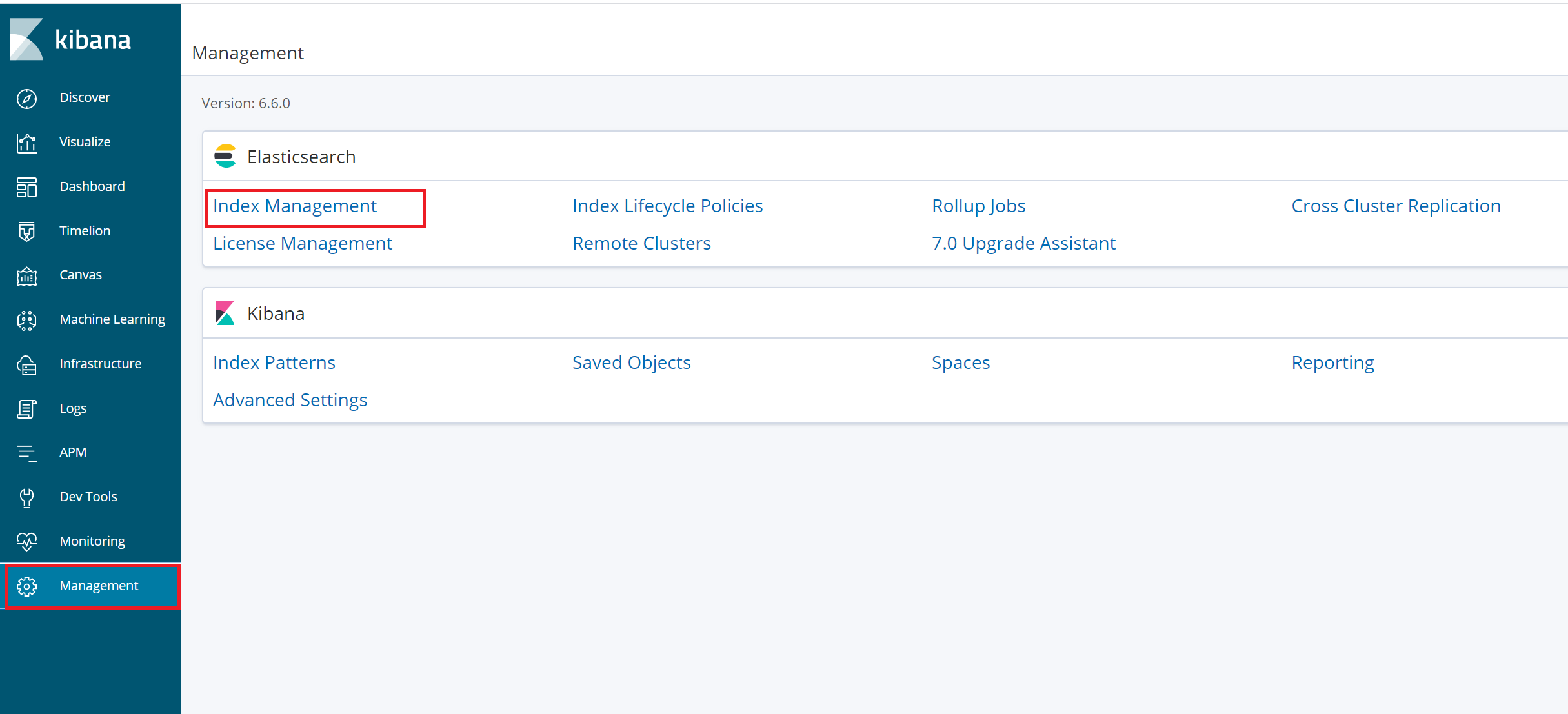
上图圈错了,是Index Patterns
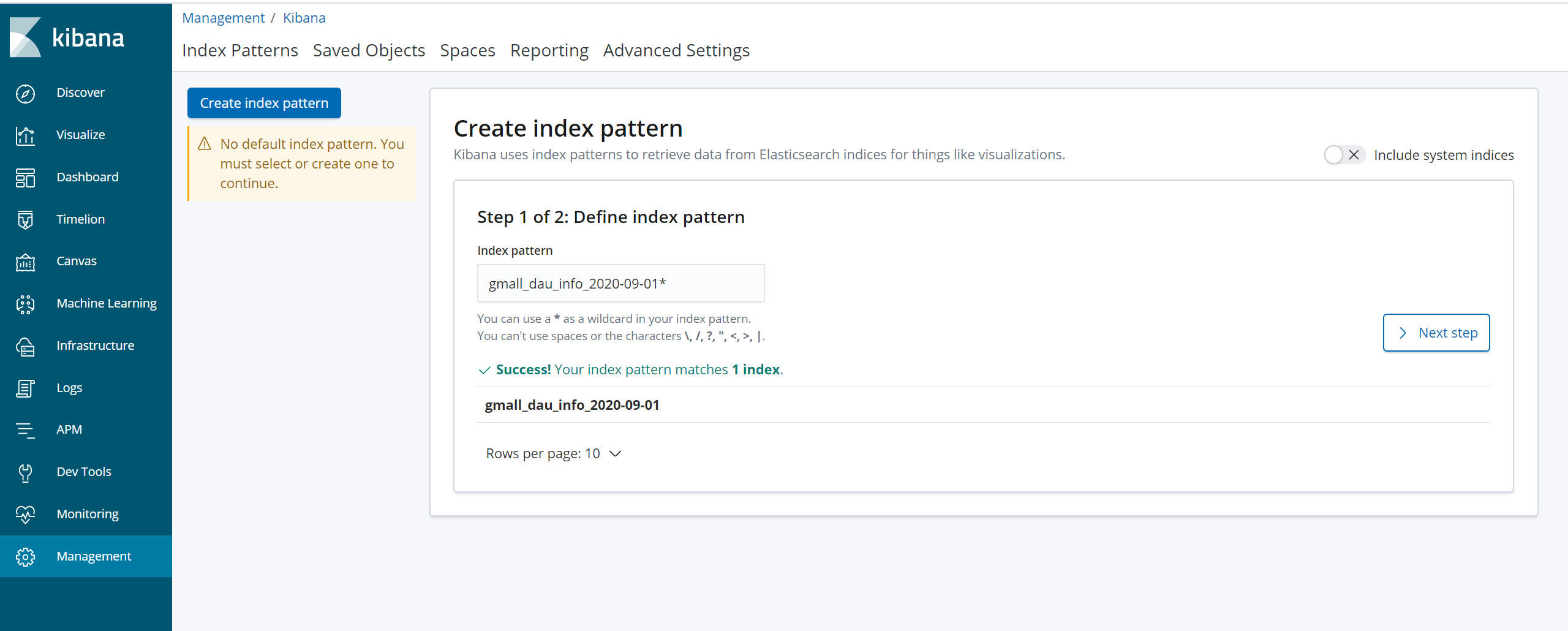
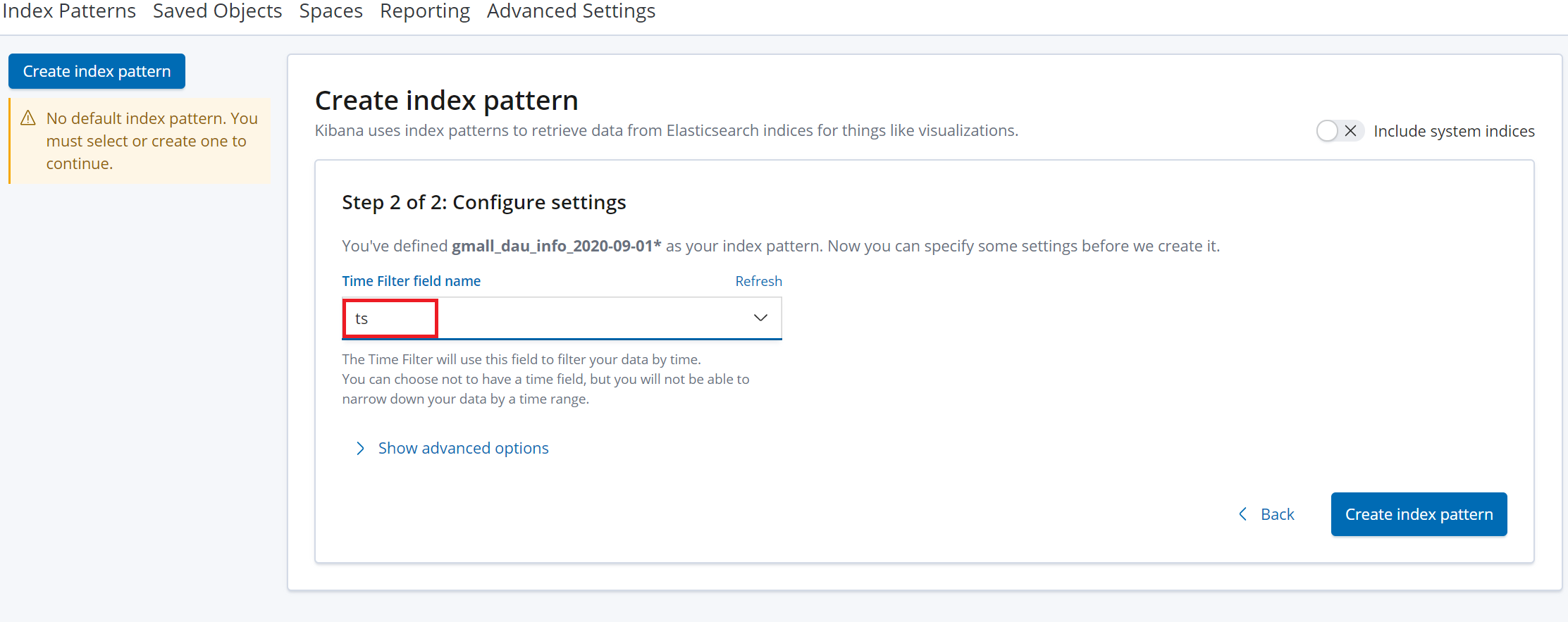
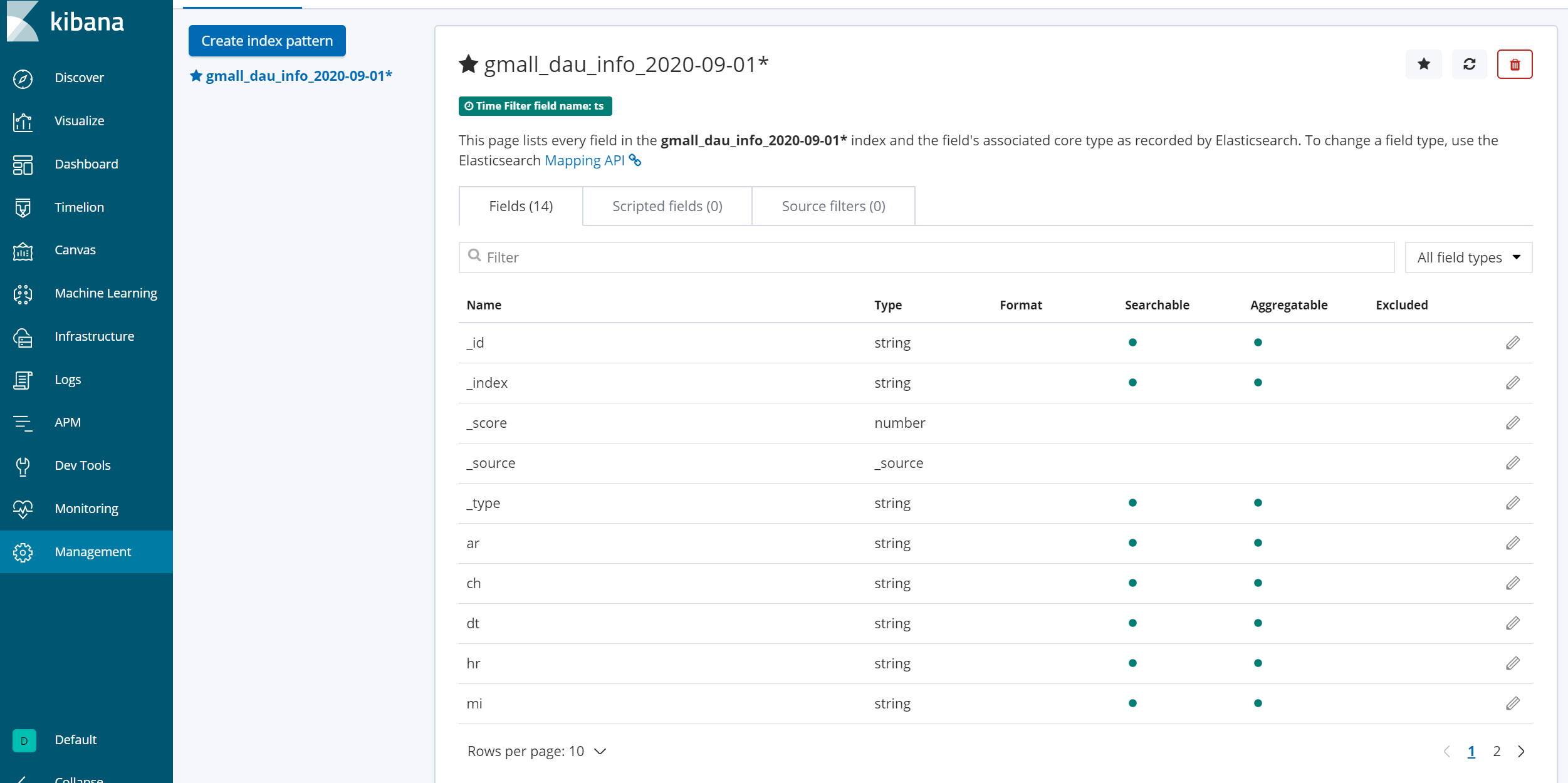
6.2 配置单图
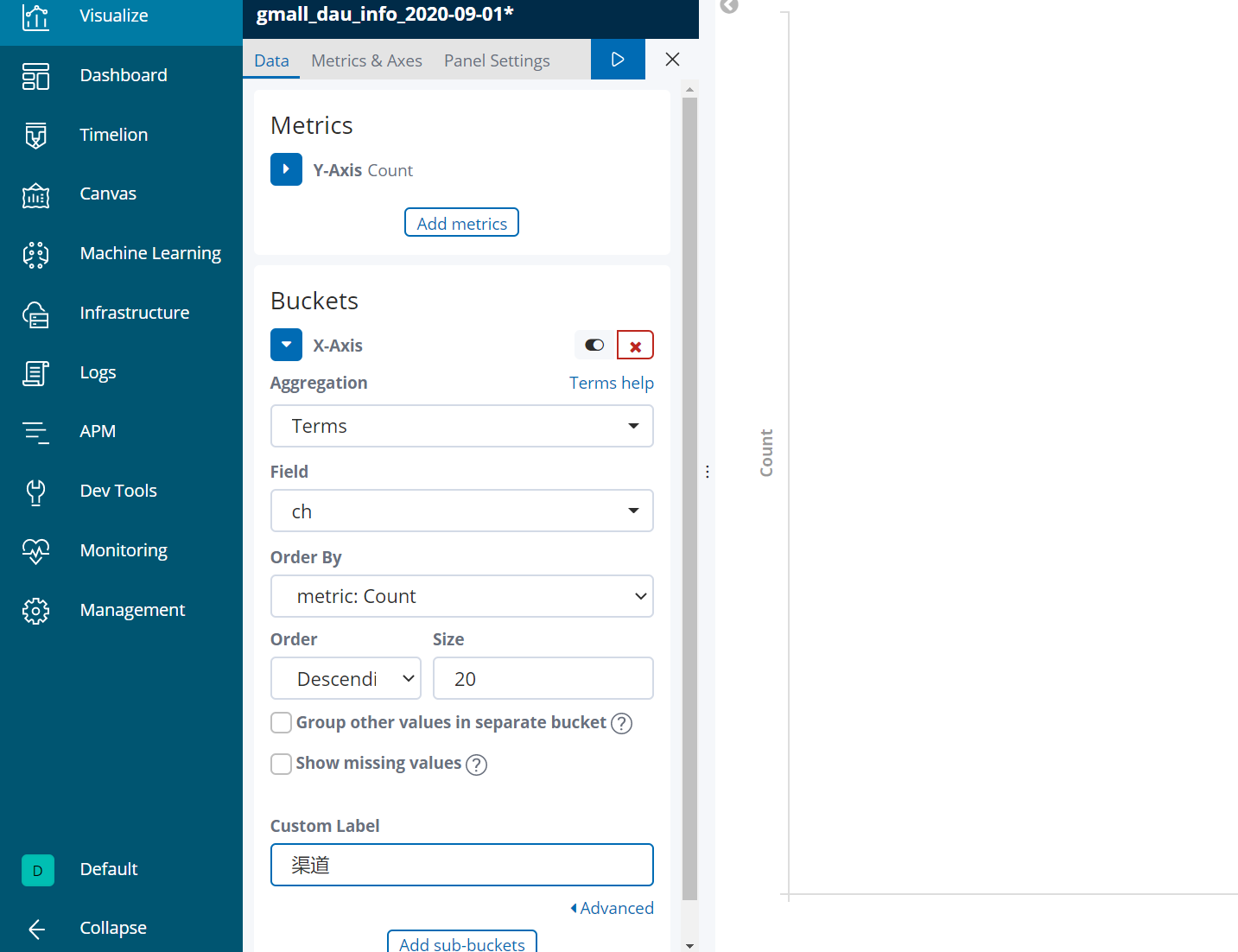
横坐标是渠道:
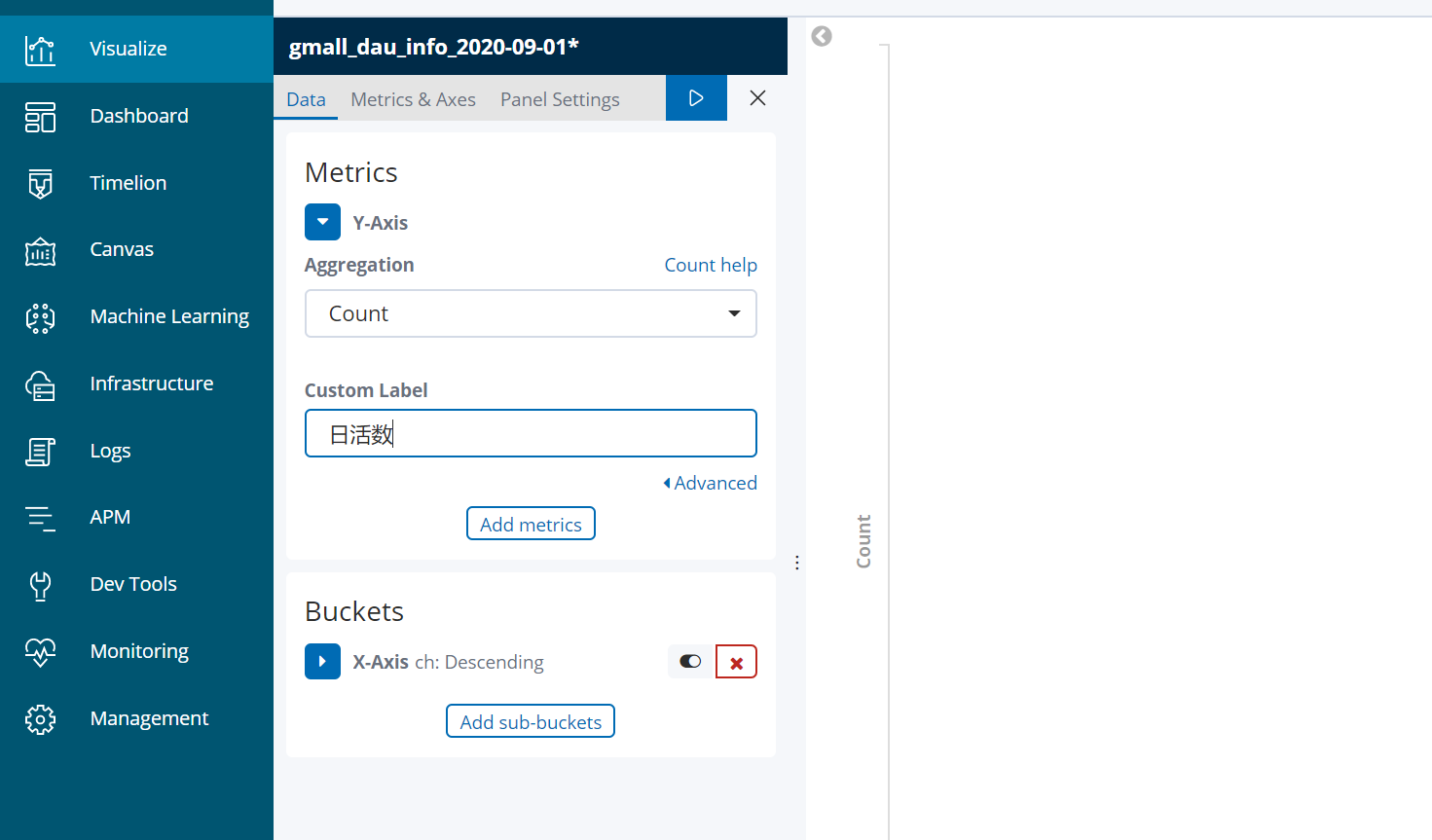

6.3 配置仪表盘
七、发布查询接口
7.1创建springboot模块
gmall-publisher
7.2 导入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.15.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.learning</groupId>
<artifactId>gmall-publisher</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>gmall-publisher</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>19.0</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.8.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.56</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.searchbox</groupId>
<artifactId>jest</artifactId>
<version>5.3.3</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>net.java.dev.jna</groupId>
<artifactId>jna</artifactId>
<version>4.5.2</version>
</dependency>
<dependency>
<groupId>org.codehaus.janino</groupId>
<artifactId>commons-compiler</artifactId>
<version>2.7.8</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>2.4.6</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
7.3 修改配置文件
#配置成master所在的节点
spring.elasticsearch.jest.uris=http://cdh01:9200
server.port=8070
7.4 service层代码
package com.learning.gmallpublisher.service;
import java.util.Map;
public interface PubliserService {
//日活的总数查询
public Long getDauTotal(String date);
//日活的分时查询
public Map getDauHour(String date);
}
package com.learning.gmallpublisher.service;
import io.searchbox.client.JestClient;
import io.searchbox.core.Search;
import io.searchbox.core.SearchResult;
import io.searchbox.core.search.aggregation.TermsAggregation;
import org.elasticsearch.index.query.MatchAllQueryBuilder;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.bucket.terms.TermsBuilder;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@Service
public class PubliserServiceImpl implements PubliserService{
@Autowired
private JestClient jestClient;
@Override
public Long getDauTotal(String date) {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(new MatchAllQueryBuilder());
String query = searchSourceBuilder.toString();
String indexName="gmall_dau_info_"+date+"-query";
System.out.println(indexName);
Search search = new Search.Builder(query).addIndex(indexName).addType("_doc").build();
Long total=0L;
try {
SearchResult searchResult = jestClient.execute(search);
if(searchResult.getTotal()!=null){
total = searchResult.getTotal();
}
} catch (IOException e) {
e.printStackTrace();
throw new RuntimeException("查询ES异常");
}
return total;
}
@Override
public Map getDauHour(String date) {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
TermsBuilder termsBuilder = AggregationBuilders.terms("groupby_hr").field("hr").size(24);
searchSourceBuilder.aggregation(termsBuilder);
String query = searchSourceBuilder.toString();
String indexName="gmall_dau_info_"+date+"-query";
Search search = new Search.Builder(query).addIndex(indexName).addType("_doc").build();
Map aggsMap=new HashMap();
try {
SearchResult searchResult = jestClient.execute(search);
if(searchResult.getAggregations().getTermsAggregation("groupby_hr")!=null){
List<TermsAggregation.Entry> buckets = searchResult.getAggregations().getTermsAggregation("groupby_hr").getBuckets();
for (TermsAggregation.Entry bucket : buckets) {
aggsMap.put( bucket.getKey(),bucket.getCount());
}
}
} catch (IOException e) {
e.printStackTrace();
//throw new RuntimeException("查询ES异常");
}
return aggsMap;
}
}
7.5 controller层代码
package com.learning.gmallpublisher.controller;
import com.alibaba.fastjson.JSON;
import com.learning.gmallpublisher.service.PubliserService;
import org.apache.commons.lang3.time.DateUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.*;
@RestController
public class PublisherController {
@Autowired
private PubliserService esService;
//@RequestMapping(value = "realtime-total" ,method = RequestMethod.GET)
@GetMapping("realtime-total")
public String realtimeTotal(@RequestParam("date") String dt){
List<Map> totalList=new ArrayList<>();
HashMap dauMap = new HashMap<>();
dauMap.put("id","dau");
dauMap.put("name","新增日活");
Long dauTotal = esService.getDauTotal(dt);
dauMap.put("value",dauTotal);
totalList.add(dauMap);
HashMap newMidMap = new HashMap<>();
newMidMap.put("id","dau");
newMidMap.put("name","新增设备");
newMidMap.put("value",233);
totalList.add(newMidMap);
return JSON.toJSONString(totalList);
}
@GetMapping("realtime-hour")
public String realtimeHour(@RequestParam(value = "id",defaultValue ="-1" ) String id ,@RequestParam("date") String dt ){
if(id.equals("dau")){
Map<String,Map> hourMap=new HashMap<>();
Map dauHourTdMap = esService.getDauHour(dt);
hourMap.put("today",dauHourTdMap);
String yd = getYd(dt);
Map dauHourYdMap = esService.getDauHour(yd);
hourMap.put("yesterday",dauHourYdMap);
return JSON.toJSONString(hourMap);
}
return null;
}
private String getYd(String td){
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd");
String yd=null;
try {
Date tdDate = dateFormat.parse(td);
Date ydDate = DateUtils.addDays(tdDate, -1);
yd=dateFormat.format(ydDate);
} catch (ParseException e) {
e.printStackTrace();
throw new RuntimeException("日期格式转变失败");
}
return yd;
}
}
7.6 接口验证
http://localhost:8070/realtime-hour?id=dau&&date=2020-08-30
http://localhost:8070/realtime-total?date=2020-08-30

 浙公网安备 33010602011771号
浙公网安备 33010602011771号