
深入理解mysql索引机制
深入理解mysql B+tree索引机制
一: 理解清楚索引定义和工作原理
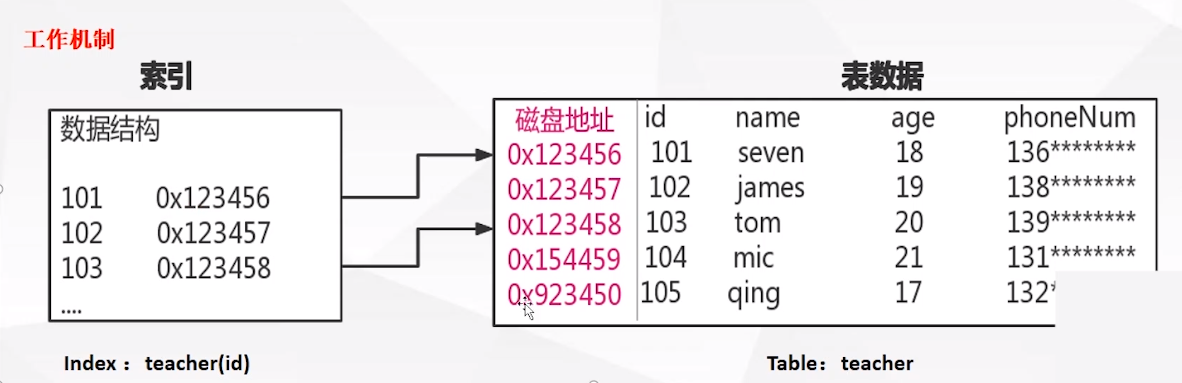
索引的定义:索引是为了加速对表中数据行的检索而创建的一种分散存储的数据结构
工作机制:
二:MySQL为什么选择B+tree
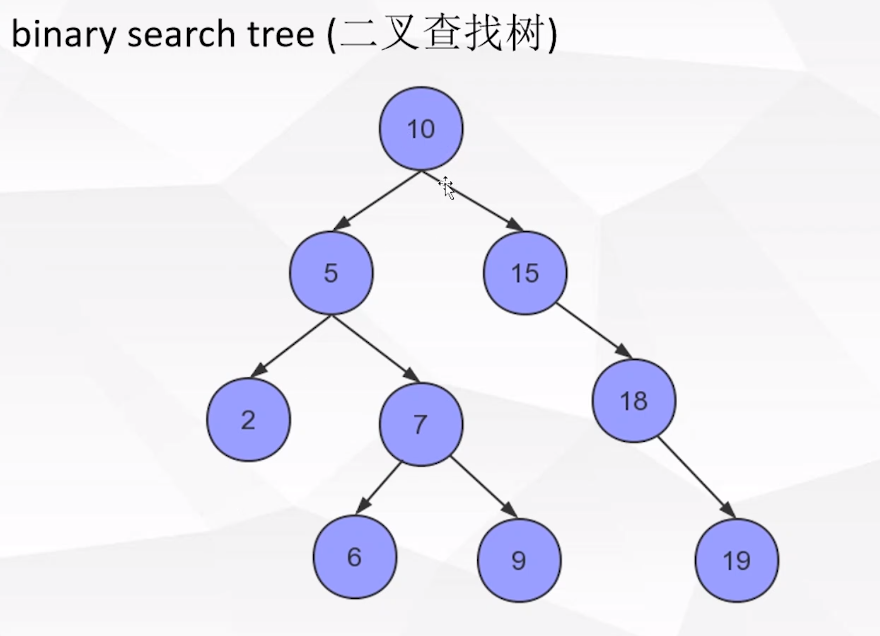
1:二叉查找树
2:平衡二叉查找树
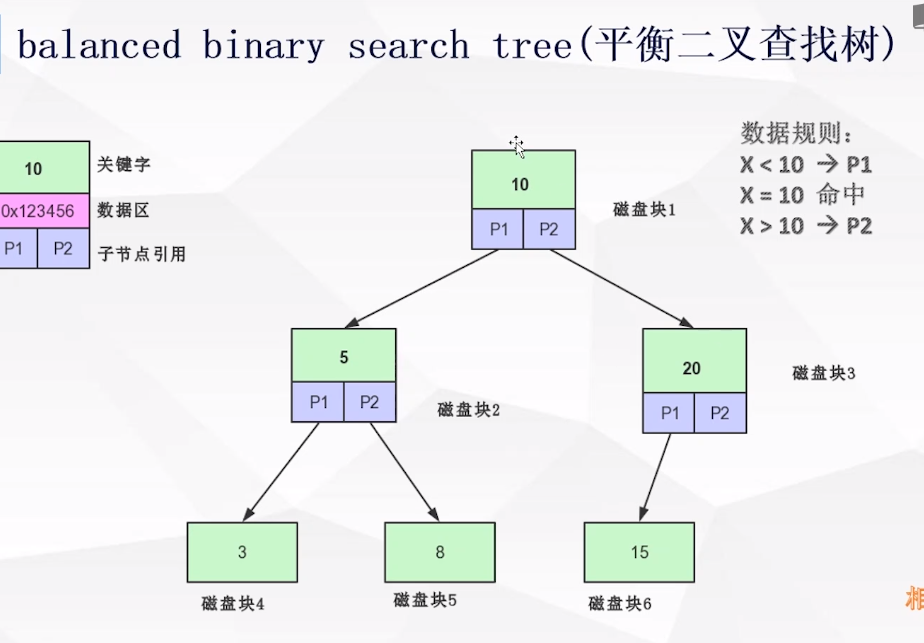
缺点:2.1:搜索效率不足:
一般来说,树结构中数据的深度决定它的搜索io次数
2.2:节点数据内容太少
每一个磁盘块(节点/页)保存的关键字数据量太少
没有很好利用操作系统和磁盘数据的交换特性(最少4BK)和磁盘预读能力(空间局部性原理)
3:B tree(多路平衡查找树)
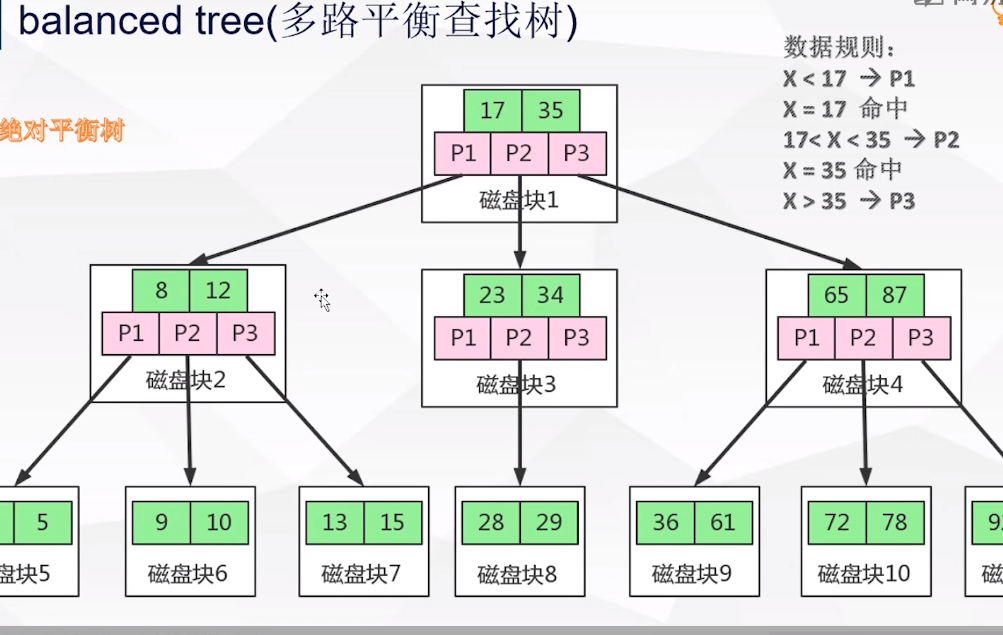
缺点:3.1 非叶子节点,保存了数据区,减少了关键字(相对于B+tree)
4:B+tree(加强版多路平衡查找树)
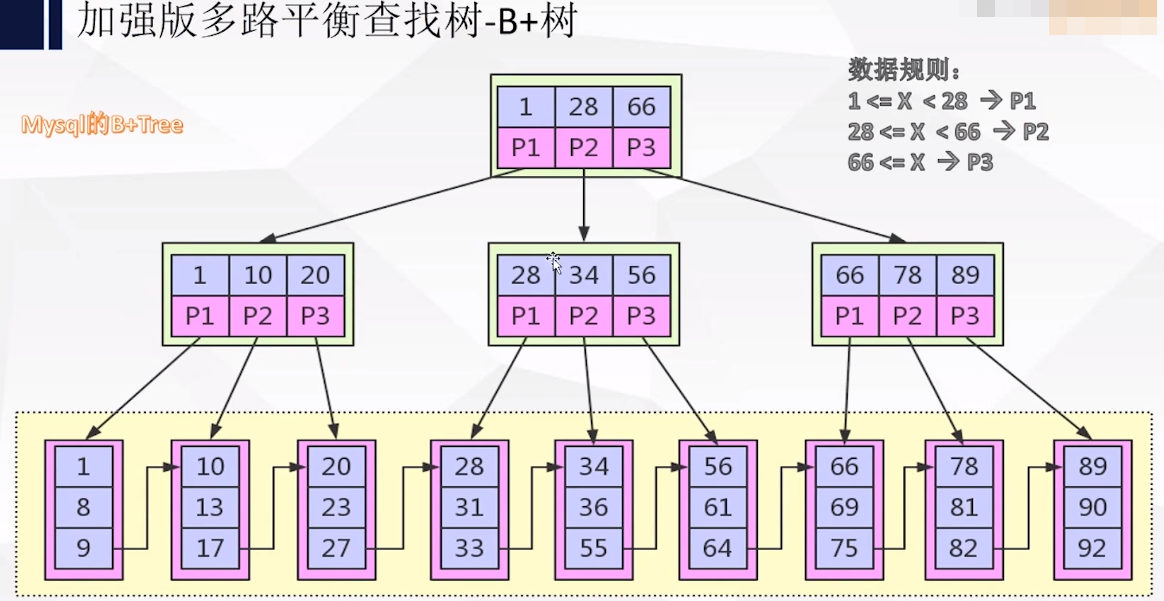
优点:B+节点关键字搜索采用闭合区间
B+非叶子节点不保存数据相关信息,只保存关键字和子节点的引用
B+关键字对应的数据保存在叶子节点中
B+叶子结点是顺序排列的,并且相邻节点具有顺序引用关系
通过比较B数的数据结构,得出MySQL为什么选择B+tree
·B+树是B树的加强版,它拥有B树的优势
·B+树扫库,扫表能力更强
·B+树的磁盘读写能力更强
·B+树的排序能力更强
·B+树的查询效率更加稳定
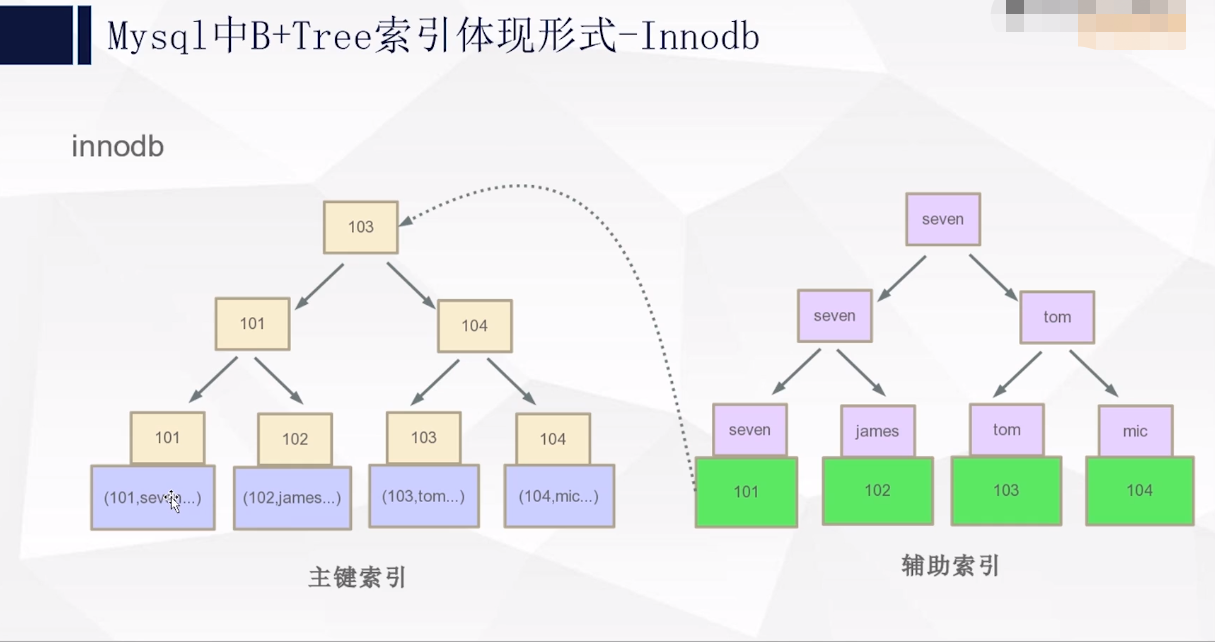
三:MySQL中B+tree索引是如何落地
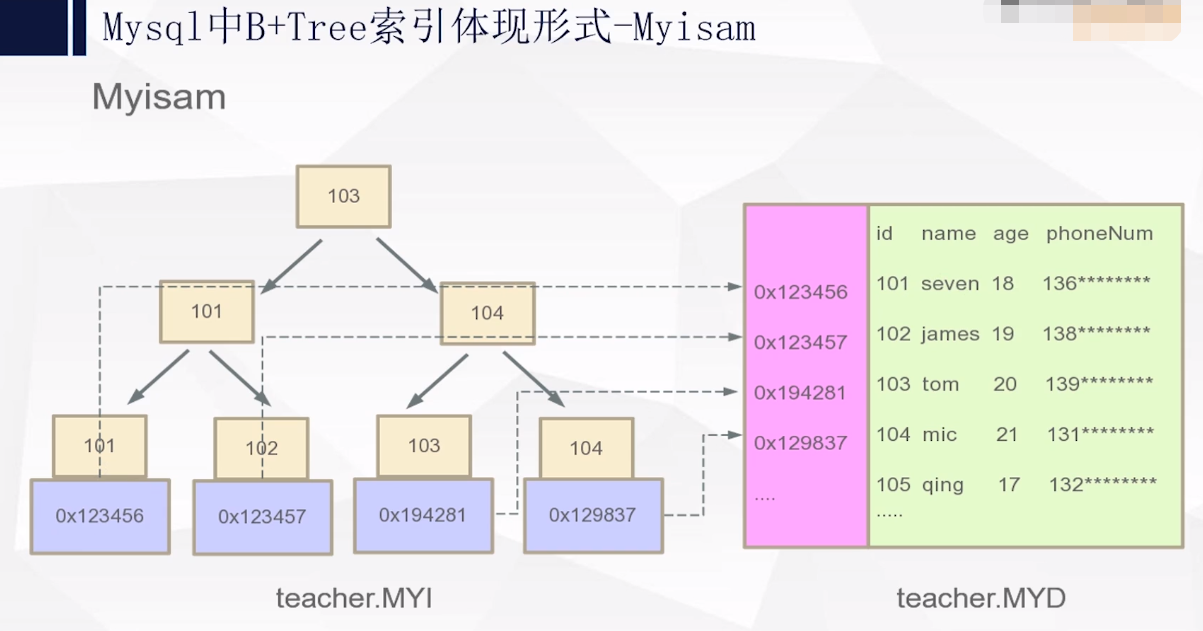
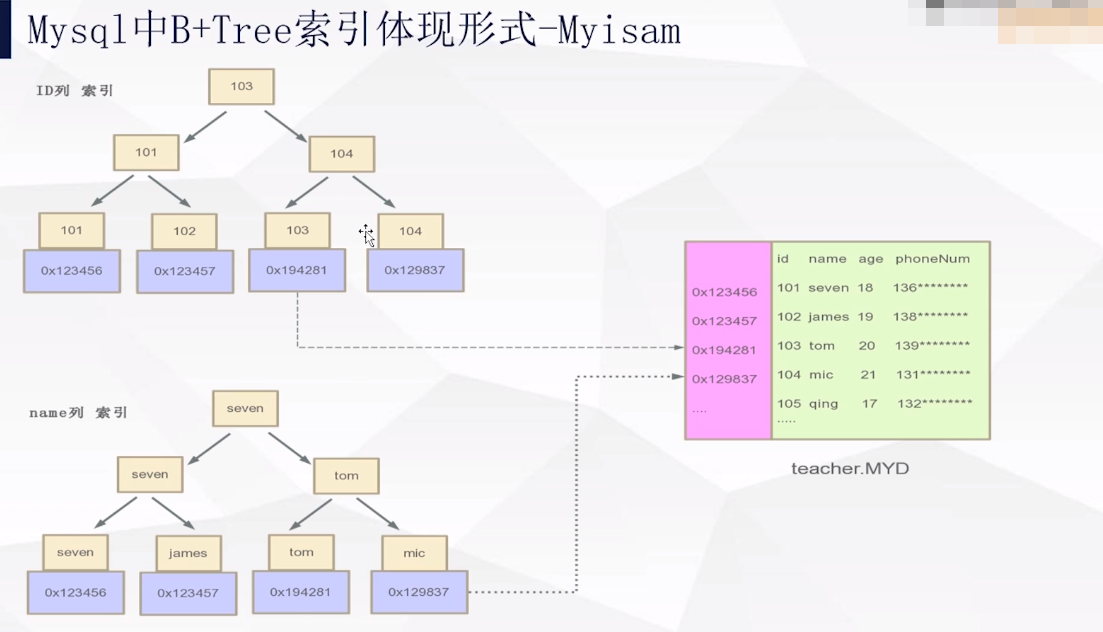
1: myisam引擎
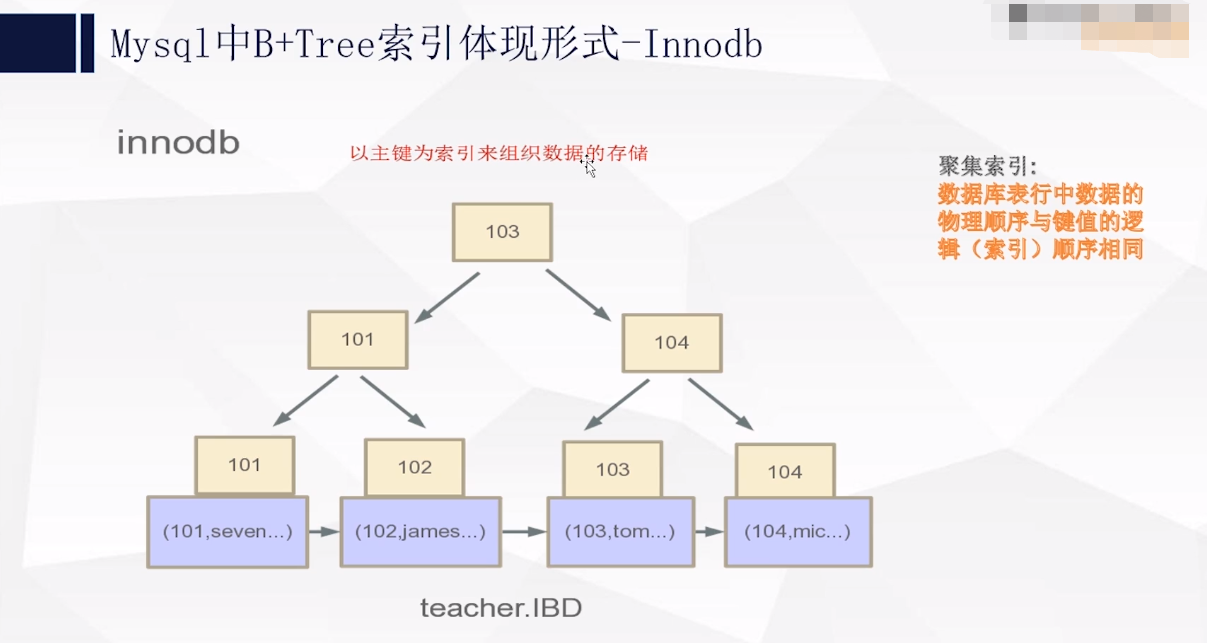
2:Inodb引擎
四:理解MySQL索引的几个原则
1:列的离散性(离散性越高,选择性越好) 计算公式 count(distinct(column)):count(column)
2:最左匹配原则,对索引中关键字进行对比,一定是从左往右依次进行且不可跳过
五:So easy,索引不过如此
《 索引无敌》
全值匹配我最爱,最左前缀要遵守;
带头大哥不能死,中间兄弟不能断;
索引列上少计算,范围之后全失效;
like百分写最左,覆盖索引不写*;
不等空值还有or,索引失效要少用;
