知识蒸馏loss求解方法
本文简单介绍知识蒸馏教师模型与学生模型使用loss方法:
一 .loss求解方法
hard label:训练的学生模型结果与真实标签进行交叉熵loss,类似正常网络训练。
soft label:训练的学生网络与已经训练好的教师网络进行KL相对熵求解,可添加系数,如温度,使其更soft。
知乎回答:loss是KL divergence,用来衡量两个分布之间距离。而KL divergence在展开之后,第一项是原始预测分布的熵,由于是已知固定的,可以消去。第二项是 -q log p,叫做cross entropy,就是平时分类训练使用的loss。与标签label不同的是,这里的q是teacher model的预测输出连续概率。而如果进一步假设q p都是基于softmax函数输出的概率的话,求导之后形式就是 q - p。直观理解就是让student model的输出尽量向teacher model的输出概率靠近。
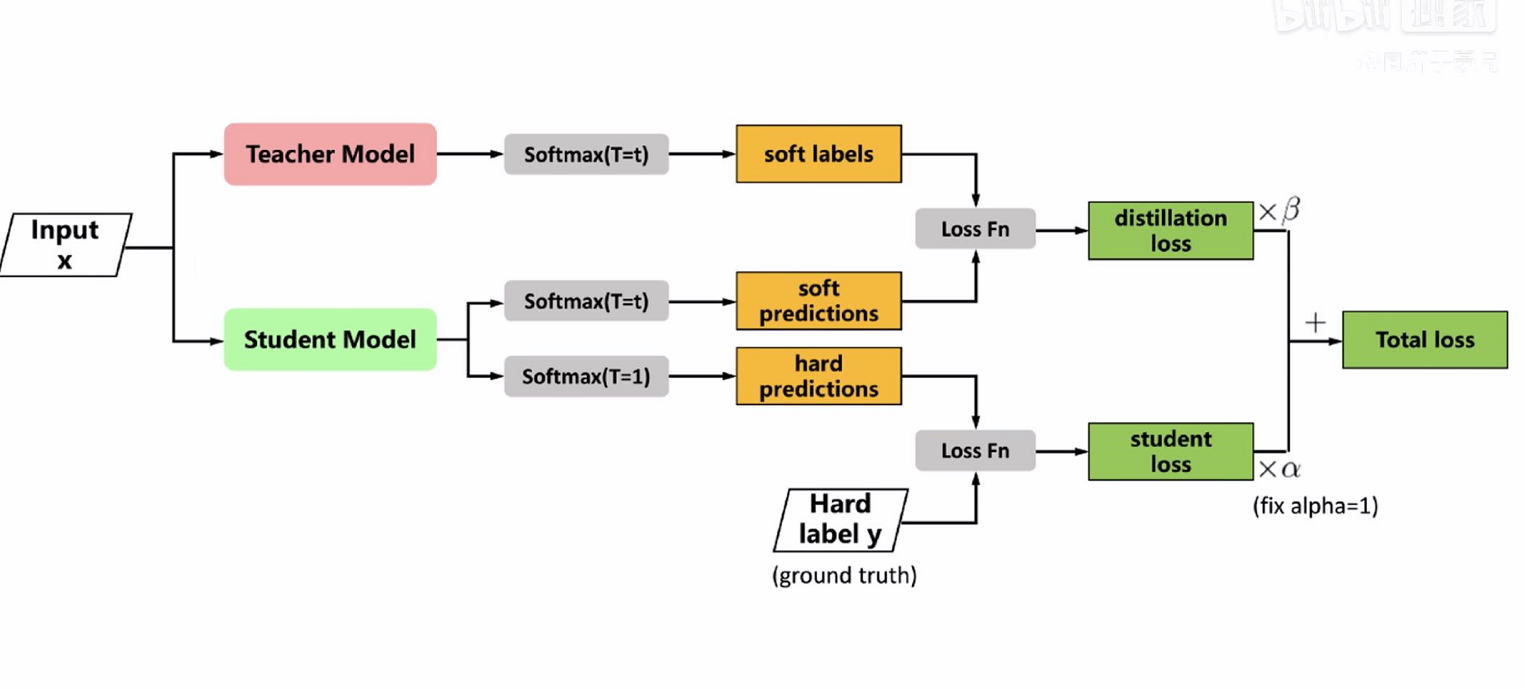
二.展示蒸馏网络过程图
![]()
三.展示代码与结果
三.展示代码与结果
蒸馏模型分类loss代码如下:
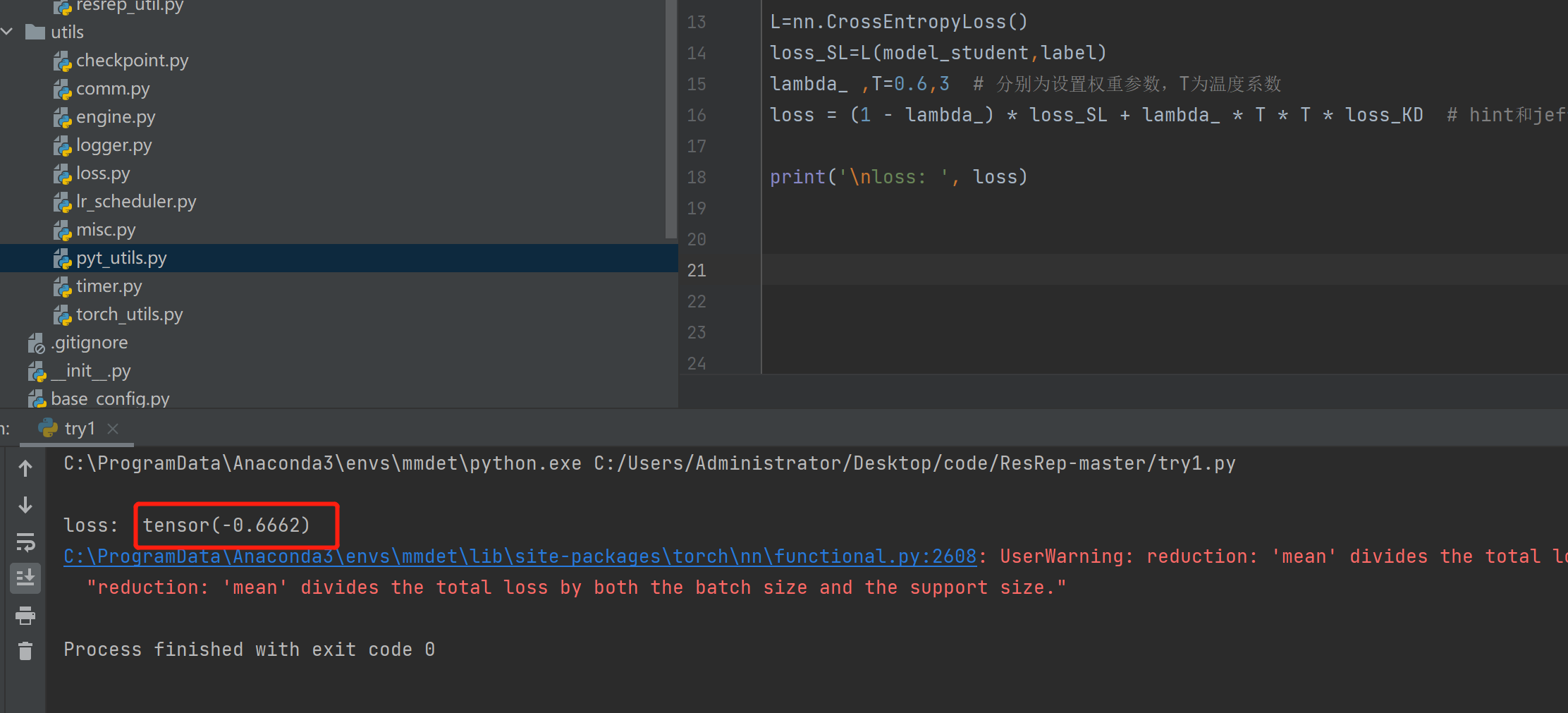
import torch import torch.nn as nn import numpy as np loss_f = nn.KLDivLoss() # 生成网络输出 以及 目标输出 model_student = torch.from_numpy(np.array([[0.1132, 0.5477, 0.3390]])).float() # 假设学生模型输出 model_teacher = torch.from_numpy(np.array([[0.8541, 0.0511, 0.0947]])).float() #假设教师模型输出 label=torch.tensor([0]) # 真实标签 loss_KD = loss_f(model_student, model_teacher) L=nn.CrossEntropyLoss() loss_SL=L(model_student,label) lambda_ ,T=0.6,3 # 分别为设置权重参数,T为温度系数 loss = (1 - lambda_) * loss_SL + lambda_ * T * T * loss_KD # hint和jeff dean论文 print('\nloss: ', loss)
结果图显示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号