Attention is all you need 深入解析
最近一直在看有关transformer相关网络结构,为此我特意将经典结构 Attention is all you need 论文进行了解读,并根据其源码深入解读attntion经典结构,
为此本博客将介绍如下内容:
论文链接:https://arxiv.org/abs/1706.03762
一.Transformer结构与原理解释。
第一部分介绍Attention is all you need 结构、模块、公式。暂时不介绍什么Q K V 什么Attention 什么编解码等,单我将会根据代码解读介绍,让读者更容易理解。
①结构: Transformer由且仅由self.Attention和Feed Forward Neural Network组成,即mutil-head-attention与FFN,如下图。

②模块结构:除了以上提到mutil-head-attention与FFN外,还需有个位置编码结构positional encoding以及mask编码模块。
③公式:
位置编码公式(还有很多其它公式,该论文使用此公式)
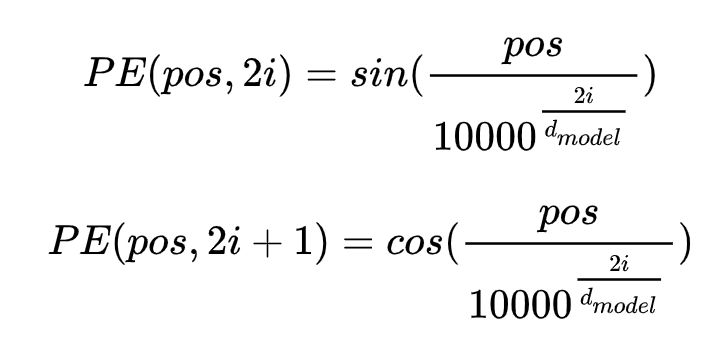
Q K V公式

FFN基本是由nn.Linear线性和激活变化,在后面用代码讲解。
二.代码解读。
第二部分会从模型输入开始,层层递推介绍整个编码和解码过程、以及整个过程中使用的Attention编码、FFN编码、位置编码等。
ENCODE模块:
① 编码输入数据介绍:
enc_input = [
[1, 3, 4, 1, 2, 3],
[1, 3, 4, 1, 2, 3],
[1, 3, 4, 1, 2, 3],
[1, 3, 4, 1, 2, 3]]
编码使用输入数据,为4x6行,表示4个句子,每个句子有6个单词,包含标点符号。
② 输入值的Embedding与位置编码
输入值embedding:
self.src_emb = nn.Embedding(vocab_size, d_model) # d_model=128
vocab_size:词典的大小尺寸,比如总共出现5000个词,那就输入5000。此时index为(0-4999)d_model:嵌入向量的维度,即用多少维来表示一个词或符号
随后可将输入x=enc_input,可将enc_outputs则表示嵌入成功,维度为[4,6,128]分别表示batch为4,词为6,用128维度描述词6
x = self.src_emb(x) # 词嵌入
位置编码:
以下使用位置编码公式的代码,为此无需再介绍了。
1 pe = torch.zeros(max_len, d_model) 2 position = torch.arange(0., max_len).unsqueeze(1) 3 div_term = torch.exp(torch.arange(0., d_model, 2) * -(math.log(10000.0) / d_model)) # 偶数列 4 pe[:, 0::2] = torch.sin(position * div_term) # 奇数列 5 pe[:, 1::2] = torch.cos(position * div_term) 6 pe = pe.unsqueeze(0)
将编码进行位置编码后,位置为[1,6,128]+输入编码的[4,6,128],相当于句子已经结合了位置编码信息,作为新新的输入。
x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False) # torch.autograd.Variable 表示有梯度的张量变量
③self.attention的编码:
在介绍此之前,先普及一个知识,若X与Y相等,则为self attention 否则为cross-attention,因为解码时候X!=Y.
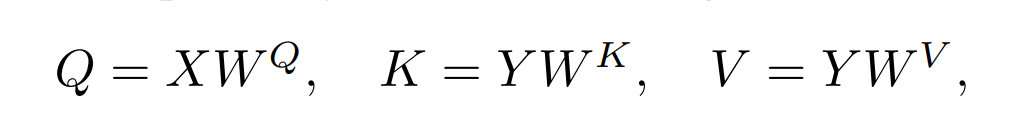
获取Q K V 代码,实际是一个线性变化,将以上输入x变成[4,6,512],然后通过head个数8与对应dv,dk将512拆分[8,64],随后移维度位置,变成[4,8,6,64]
1 self.WQ = nn.Linear(d_model, d_k * n_heads) # 利用线性卷积 2 self.WK = nn.Linear(d_model, d_k * n_heads) 3 self.WV = nn.Linear(d_model, d_v * n_heads)
变化后的q k v
1 q_s = self.WQ(Q).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2) # 线性卷积后再分组实现head功能 2 k_s = self.WK(K).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2) 3 v_s = self.WV(V).view(batch_size, -1, self.n_heads, self.d_v).transpose(1, 2) 4 attn_mask = attn_mask.unsqueeze(1).repeat(1, self.n_heads, 1, 1) # 编导对应的头
随后通过以上self公式,将其编码计算
1 scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(self.d_k) 5 attn = nn.Softmax(dim=-1)(scores) 6 context = torch.matmul(attn, V)
以上编码将是encode编码得到结果,我们将得到结果进行还原:
1context = context.transpose(1, 2).contiguous().view(batch_size, -1, self.n_heads * self.d_v) # 将其还原 2output = self.linear(context) # 通过线性又将其变成原来模样维度 3layer_norm(output + Q) # 这里加Q 实际是对Q寻找
以上将重新得到新的输入x,维度为[4,6,128]
④ FFN编码:
将以上的输出维度为[4,6,128]进行FNN层变化,实际类似线性残差网络变化,得到最终输出
1 class PoswiseFeedForwardNet(nn.Module): 2 3 def __init__(self, d_model, d_ff): 4 super(PoswiseFeedForwardNet, self).__init__() 5 self.l1 = nn.Linear(d_model, d_ff) 6 self.l2 = nn.Linear(d_ff, d_model) 7 8 self.relu = GELU() 9 self.layer_norm = nn.LayerNorm(d_model) 10 11 def forward(self, inputs): 12 residual = inputs 13 output = self.l1(inputs) # 一层线性卷积 14 output = self.relu(output) 15 output = self.l2(output) # 一层线性卷积 16 return self.layer_norm(output + residual)
⑤ 重复以上步骤编码,即将得到经过FFN变化的输出x,维度为[4,6,128],将其重复步骤③-④,因其编码为6个,可重复5个便是完成相应的编码模块。
DECODE模块:
①解码输入数据介绍,包含以下数据输入(dec_input)、enc_input的输入与解码后输出的数据,维度为[4,6,128]:
dec_input = [
[1, 0, 0, 0, 0, 0],
[1, 3, 0, 0, 0, 0],
[1, 3, 4, 0, 0, 0],
[1, 3, 4, 1, 0, 0]]
②dec_input的Embedding与位置编码
因其与encode的实现方法一致,只需将enc_input使用dec_input取代,得到dec_outputs,因此这里将不在介绍。
③mask编码,包含整体编码与局部编码
整体编码,代码如下:
1 def get_attn_pad_mask(seq_q, seq_k, pad_index): 2 batch_size, len_q = seq_q.size() 3 batch_size, len_k = seq_k.size() 4 pad_attn_mask = seq_k.data.eq(pad_index).unsqueeze(1) 5 pad_attn_mask = torch.as_tensor(pad_attn_mask, dtype=torch.int) 6 return pad_attn_mask.expand(batch_size, len_q, len_k)
以上代码实际是将dec_input进行处理,实际变成以下数据:
[[0, 1, 1, 1, 1, 1],
[0, 0, 1, 1, 1, 1],
[0, 0, 0, 1, 1, 1],
[0, 0, 0, 0, 1, 1]]
将其增添维度为[4,1,6],并将其扩张为[4,6,6]
局部代码编写,实际为上三角矩阵:
[[0. 1. 1. 1. 1. 1.]
[0. 0. 1. 1. 1. 1.]
[0. 0. 0. 1. 1. 1.]
[0. 0. 0. 0. 1. 1.]
[0. 0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0. 0.]]
将以上数据添加维度为[1,6,6],在将扩展变成[4,6,6]
关于整体mask与局部mask编码,我的理解是整体信息为语句4个词6个,根据解码输入编码整体信息,而局部编码是基于一个语句6*6编码信息,将其扩张重复到4个语句,
使其mask获得整体信息与局部信息。
1 dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs, self.pad_index) # 整体编码的mask 2 dec_self_attn_subsequent_mask = get_attn_subsequent_mask(dec_inputs) 3 dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0) # torch.gt(a,b) a>b 则为1否则为0 4 dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs, self.pad_index)
最终将mask整合,获取dec_self_attn_mask信息,同理dec_enc_attn_mask(维度为解码编码词维度)采用dec_self_attn_mask的第一步便可获取。
④编码输入self-Attention,包含2部分
解码输入dec_outputs进行self.Attention:
实际使用以上Q K V公式,具体实现和编码实现方法一致,唯一不同是
在Q*KT会使用解码maskdec_self_attn_mask,其重要代码为scores.masked_fill_(attn_mask, -1e9),其它代码为:
1 class ScaledDotProductAttention(nn.Module): 2 3 def __init__(self, d_k, device): 4 super(ScaledDotProductAttention, self).__init__() 5 self.device = device 6 self.d_k = d_k 7 8 def forward(self, Q, K, V, attn_mask): 9 scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(self.d_k) 10 attn_mask = torch.as_tensor(attn_mask, dtype=torch.bool) 11 attn_mask = attn_mask.to(self.device) 12 scores.masked_fill_(attn_mask, -1e9) # it is true give -1e9 13 attn = nn.Softmax(dim=-1)(scores) 14 context = torch.matmul(attn, V) 15 return context, attn
以上代码将执行以下代码:
context, attn = ScaledDotProductAttention(d_k=self.d_k, device=self.device)(Q=q_s, K=k_s, V=v_s,
attn_mask=attn_mask)
context = context.transpose(1, 2).contiguous().view(batch_size, -1, self.n_heads * self.d_v) # 将其还原
output = self.linear(context) # 通过线性又将其变成原来模样维度
dec_outputs = self.layer_norm(output + Q) # 这里加Q 实际是对Q寻找
到此为止已经完成了解码输入的self-attention模块,输出为dec_outputs实际除了增加mask编码调整Q*KT以外,其它完全相同。
编码输出dec_outputs进行Cross Attention:
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask) # 重点说明enc_outputs来源编码结果,是一直不变的
以上为Cross Attention 过程,以上代码除了Q来源dec_outputs,K V 来源编码输出enc_outputs以外,即论文所说X与Y不等得到的Q K V称为Cross Attention。
实际以上代码与执行解码self-Attention方法完全一致,仅仅mask更改上文提供的方法,得到输出结果为dec_outputs,因此这里将不在解释了。
⑤ FFN编码。
通过④的attention编码,得到dec_outputs后,采用编码步骤④的FNN方法。
⑥ 重复步骤④-⑤多次,便实现了解码过程。
至此,本文已完全解读完Attention is all you need的编码与解码结构。
个人重点总结:
①未使用通常kernel=3的CNN卷积,而所有均使用Linear卷积;
②编码传递K V 解码传递Q;
③self-attention 和 cross attention本质是X与Y值不同,即得到Q 和 K V 数据来源不同,但实现方法一致;
④ transformer重点模块为attention(一般是mutil-head attention)、FFN、位置编码、mask编码;
最后贴上完整代码,便于读者深入理解:
整体代码:
1 import json 2 import math 3 import torch 4 import torchvision 5 import torch.nn as nn 6 import numpy as np 7 from pdb import set_trace 8 9 from torch.autograd import Variable 10 11 12 def get_attn_pad_mask(seq_q, seq_k, pad_index): 13 batch_size, len_q = seq_q.size() 14 batch_size, len_k = seq_k.size() 15 pad_attn_mask = seq_k.data.eq(pad_index).unsqueeze(1) 16 pad_attn_mask = torch.as_tensor(pad_attn_mask, dtype=torch.int) 17 return pad_attn_mask.expand(batch_size, len_q, len_k) 18 19 20 def get_attn_subsequent_mask(seq): 21 attn_shape = [seq.size(0), seq.size(1), seq.size(1)] 22 subsequent_mask = np.triu(np.ones(attn_shape), k=1) 23 subsequent_mask = torch.from_numpy(subsequent_mask).int() 24 return subsequent_mask 25 26 27 class GELU(nn.Module): 28 29 def forward(self, x): 30 return 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3)))) 31 32 33 class PositionalEncoding(nn.Module): 34 "Implement the PE function." 35 36 def __init__(self, d_model, dropout, max_len=5000): # 37 super(PositionalEncoding, self).__init__() 38 self.dropout = nn.Dropout(p=dropout) 39 40 # Compute the positional encodings once in log space. 41 pe = torch.zeros(max_len, d_model) 42 position = torch.arange(0., max_len).unsqueeze(1) 43 div_term = torch.exp(torch.arange(0., d_model, 2) * -(math.log(10000.0) / d_model)) # 偶数列 44 pe[:, 0::2] = torch.sin(position * div_term) 45 pe[:, 1::2] = torch.cos(position * div_term) 46 pe = pe.unsqueeze(0) 47 self.register_buffer('pe', pe) # 将变量pe保存到内存中,不计算梯度 48 49 def forward(self, x): 50 x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False) # torch.autograd.Variable 表示有梯度的张量变量 51 return self.dropout(x) 52 53 54 class ScaledDotProductAttention(nn.Module): 55 56 def __init__(self, d_k, device): 57 super(ScaledDotProductAttention, self).__init__() 58 self.device = device 59 self.d_k = d_k 60 61 def forward(self, Q, K, V, attn_mask): 62 scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(self.d_k) 63 attn_mask = torch.as_tensor(attn_mask, dtype=torch.bool) 64 attn_mask = attn_mask.to(self.device) 65 scores.masked_fill_(attn_mask, -1e9) # it is true give -1e9 66 attn = nn.Softmax(dim=-1)(scores) 67 context = torch.matmul(attn, V) 68 return context, attn 69 70 71 class MultiHeadAttention(nn.Module): 72 73 def __init__(self, d_model, d_k, d_v, n_heads, device): 74 super(MultiHeadAttention, self).__init__() 75 self.WQ = nn.Linear(d_model, d_k * n_heads) # 利用线性卷积 76 self.WK = nn.Linear(d_model, d_k * n_heads) 77 self.WV = nn.Linear(d_model, d_v * n_heads) 78 79 self.linear = nn.Linear(n_heads * d_v, d_model) 80 81 self.layer_norm = nn.LayerNorm(d_model) 82 self.device = device 83 84 self.d_model = d_model 85 self.d_k = d_k 86 self.d_v = d_v 87 self.n_heads = n_heads 88 89 def forward(self, Q, K, V, attn_mask): 90 batch_size = Q.shape[0] 91 q_s = self.WQ(Q).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2) # 线性卷积后再分组实现head功能 92 k_s = self.WK(K).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2) 93 v_s = self.WV(V).view(batch_size, -1, self.n_heads, self.d_v).transpose(1, 2) 94 95 attn_mask = attn_mask.unsqueeze(1).repeat(1, self.n_heads, 1, 1) # 编导对应的头 96 context, attn = ScaledDotProductAttention(d_k=self.d_k, device=self.device)(Q=q_s, K=k_s, V=v_s, 97 attn_mask=attn_mask) 98 context = context.transpose(1, 2).contiguous().view(batch_size, -1, self.n_heads * self.d_v) # 将其还原 99 output = self.linear(context) # 通过线性又将其变成原来模样维度 100 return self.layer_norm(output + Q), attn # 这里加Q 实际是对Q寻找 101 102 103 class PoswiseFeedForwardNet(nn.Module): 104 105 def __init__(self, d_model, d_ff): 106 super(PoswiseFeedForwardNet, self).__init__() 107 self.l1 = nn.Linear(d_model, d_ff) 108 self.l2 = nn.Linear(d_ff, d_model) 109 110 self.relu = GELU() 111 self.layer_norm = nn.LayerNorm(d_model) 112 113 def forward(self, inputs): 114 residual = inputs 115 output = self.l1(inputs) # 一层线性卷积 116 output = self.relu(output) 117 output = self.l2(output) # 一层线性卷积 118 return self.layer_norm(output + residual) 119 120 121 class EncoderLayer(nn.Module): 122 123 def __init__(self, d_model, d_ff, d_k, d_v, n_heads, device): 124 super(EncoderLayer, self).__init__() 125 self.enc_self_attn = MultiHeadAttention(d_model=d_model, d_k=d_k, d_v=d_v, n_heads=n_heads, device=device) 126 self.pos_ffn = PoswiseFeedForwardNet(d_model=d_model, d_ff=d_ff) 127 128 def forward(self, enc_inputs, enc_self_attn_mask): 129 enc_outputs, attn = self.enc_self_attn(Q=enc_inputs, K=enc_inputs, V=enc_inputs, attn_mask=enc_self_attn_mask) 130 # X=Y 因此Q K V相等 131 enc_outputs = self.pos_ffn(enc_outputs) # 132 return enc_outputs, attn 133 134 135 class Encoder(nn.Module): 136 137 def __init__(self, vocab_size, d_model, d_ff, d_k, d_v, n_heads, n_layers, pad_index, device): 138 # 4 128 256 64 64 8 4 0 139 super(Encoder, self).__init__() 140 self.device = device 141 self.pad_index = pad_index 142 self.src_emb = nn.Embedding(vocab_size, d_model) 143 # vocab_size:词典的大小尺寸,比如总共出现5000个词,那就输入5000。此时index为(0-4999) d_model:嵌入向量的维度,即用多少维来表示一个符号 144 self.pos_emb = PositionalEncoding(d_model=d_model, dropout=0) 145 146 self.layers = [] 147 for _ in range(n_layers): 148 encoder_layer = EncoderLayer(d_model=d_model, d_ff=d_ff, d_k=d_k, d_v=d_v, n_heads=n_heads, device=device) 149 self.layers.append(encoder_layer) 150 self.layers = nn.ModuleList(self.layers) 151 152 def forward(self, x): 153 enc_outputs = self.src_emb(x) # 词嵌入 154 enc_outputs = self.pos_emb(enc_outputs) # pos+matx 155 enc_self_attn_mask = get_attn_pad_mask(x, x, self.pad_index) 156 157 enc_self_attns = [] 158 for layer in self.layers: 159 enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask) 160 enc_self_attns.append(enc_self_attn) 161 162 enc_self_attns = torch.stack(enc_self_attns) 163 enc_self_attns = enc_self_attns.permute([1, 0, 2, 3, 4]) 164 return enc_outputs, enc_self_attns 165 166 167 class DecoderLayer(nn.Module): 168 169 def __init__(self, d_model, d_ff, d_k, d_v, n_heads, device): 170 super(DecoderLayer, self).__init__() 171 self.dec_self_attn = MultiHeadAttention(d_model=d_model, d_k=d_k, d_v=d_v, n_heads=n_heads, device=device) 172 self.dec_enc_attn = MultiHeadAttention(d_model=d_model, d_k=d_k, d_v=d_v, n_heads=n_heads, device=device) 173 self.pos_ffn = PoswiseFeedForwardNet(d_model=d_model, d_ff=d_ff) 174 175 def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask): 176 dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask) 177 dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask) 178 dec_outputs = self.pos_ffn(dec_outputs) 179 return dec_outputs, dec_self_attn, dec_enc_attn 180 181 182 class Decoder(nn.Module): 183 184 def __init__(self, vocab_size, d_model, d_ff, d_k, d_v, n_heads, n_layers, pad_index, device): 185 super(Decoder, self).__init__() 186 self.pad_index = pad_index 187 self.device = device 188 self.tgt_emb = nn.Embedding(vocab_size, d_model) 189 self.pos_emb = PositionalEncoding(d_model=d_model, dropout=0) 190 self.layers = [] 191 for _ in range(n_layers): 192 decoder_layer = DecoderLayer(d_model=d_model, d_ff=d_ff, d_k=d_k, d_v=d_v, n_heads=n_heads, device=device) 193 self.layers.append(decoder_layer) 194 self.layers = nn.ModuleList(self.layers) 195 196 def forward(self, dec_inputs, enc_inputs, enc_outputs): 197 dec_outputs = self.tgt_emb(dec_inputs) 198 dec_outputs = self.pos_emb(dec_outputs) 199 200 dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs, self.pad_index) 201 dec_self_attn_subsequent_mask = get_attn_subsequent_mask(dec_inputs) 202 dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0) 203 dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs, self.pad_index) 204 205 dec_self_attns, dec_enc_attns = [], [] 206 for layer in self.layers: 207 dec_outputs, dec_self_attn, dec_enc_attn = layer( 208 dec_inputs=dec_outputs, 209 enc_outputs=enc_outputs, 210 dec_self_attn_mask=dec_self_attn_mask, 211 dec_enc_attn_mask=dec_enc_attn_mask) 212 dec_self_attns.append(dec_self_attn) 213 dec_enc_attns.append(dec_enc_attn) 214 dec_self_attns = torch.stack(dec_self_attns) 215 dec_enc_attns = torch.stack(dec_enc_attns) 216 217 dec_self_attns = dec_self_attns.permute([1, 0, 2, 3, 4]) 218 dec_enc_attns = dec_enc_attns.permute([1, 0, 2, 3, 4]) 219 220 return dec_outputs, dec_self_attns, dec_enc_attns 221 222 223 class MaskedDecoderLayer(nn.Module): 224 225 def __init__(self, d_model, d_ff, d_k, d_v, n_heads, device): 226 super(MaskedDecoderLayer, self).__init__() 227 self.dec_self_attn = MultiHeadAttention(d_model=d_model, d_k=d_k, d_v=d_v, n_heads=n_heads, device=device) 228 self.pos_ffn = PoswiseFeedForwardNet(d_model=d_model, d_ff=d_ff) 229 230 def forward(self, dec_inputs, dec_self_attn_mask): 231 dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask) 232 dec_outputs = self.pos_ffn(dec_outputs) 233 return dec_outputs, dec_self_attn 234 235 236 class MaskedDecoder(nn.Module): 237 238 def __init__(self, vocab_size, d_model, d_ff, d_k, 239 d_v, n_heads, n_layers, pad_index, device): 240 super(MaskedDecoder, self).__init__() 241 self.pad_index = pad_index 242 self.tgt_emb = nn.Embedding(vocab_size, d_model) 243 self.pos_emb = PositionalEncoding(d_model=d_model, dropout=0) 244 245 self.layers = [] 246 for _ in range(n_layers): 247 decoder_layer = MaskedDecoderLayer( 248 d_model=d_model, d_ff=d_ff, 249 d_k=d_k, d_v=d_v, n_heads=n_heads, 250 device=device) 251 self.layers.append(decoder_layer) 252 self.layers = nn.ModuleList(self.layers) 253 254 def forward(self, dec_inputs): 255 dec_outputs = self.tgt_emb(dec_inputs) 256 dec_outputs = self.pos_emb(dec_outputs) 257 258 dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs, self.pad_index) 259 dec_self_attn_subsequent_mask = get_attn_subsequent_mask(dec_inputs) 260 dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0) 261 dec_self_attns = [] 262 for layer in self.layers: 263 dec_outputs, dec_self_attn = layer( 264 dec_inputs=dec_outputs, 265 dec_self_attn_mask=dec_self_attn_mask) 266 dec_self_attns.append(dec_self_attn) 267 dec_self_attns = torch.stack(dec_self_attns) 268 dec_self_attns = dec_self_attns.permute([1, 0, 2, 3, 4]) 269 return dec_outputs, dec_self_attns 270 271 272 class BertModel(nn.Module): 273 274 def __init__(self, vocab_size, d_model, d_ff, d_k, d_v, n_heads, n_layers, pad_index, device): 275 super(BertModel, self).__init__() 276 self.tok_embed = nn.Embedding(vocab_size, d_model) 277 self.pos_embed = PositionalEncoding(d_model=d_model, dropout=0) 278 self.seg_embed = nn.Embedding(2, d_model) 279 280 self.layers = [] 281 for _ in range(n_layers): 282 encoder_layer = EncoderLayer( 283 d_model=d_model, d_ff=d_ff, 284 d_k=d_k, d_v=d_v, n_heads=n_heads, 285 device=device) 286 self.layers.append(encoder_layer) 287 self.layers = nn.ModuleList(self.layers) 288 289 self.pad_index = pad_index 290 291 self.fc = nn.Linear(d_model, d_model) 292 self.active1 = nn.Tanh() 293 self.classifier = nn.Linear(d_model, 2) 294 295 self.linear = nn.Linear(d_model, d_model) 296 self.active2 = GELU() 297 self.norm = nn.LayerNorm(d_model) 298 299 self.decoder = nn.Linear(d_model, vocab_size, bias=False) 300 self.decoder.weight = self.tok_embed.weight 301 self.decoder_bias = nn.Parameter(torch.zeros(vocab_size)) 302 303 def forward(self, input_ids, segment_ids, masked_pos): 304 output = self.tok_embed(input_ids) + self.seg_embed(segment_ids) 305 output = self.pos_embed(output) 306 enc_self_attn_mask = get_attn_pad_mask(input_ids, input_ids, self.pad_index) 307 308 for layer in self.layers: 309 output, enc_self_attn = layer(output, enc_self_attn_mask) 310 311 h_pooled = self.active1(self.fc(output[:, 0])) 312 logits_clsf = self.classifier(h_pooled) 313 314 masked_pos = masked_pos[:, :, None].expand(-1, -1, output.size(-1)) 315 h_masked = torch.gather(output, 1, masked_pos) 316 h_masked = self.norm(self.active2(self.linear(h_masked))) 317 logits_lm = self.decoder(h_masked) + self.decoder_bias 318 319 return logits_lm, logits_clsf, output 320 321 322 class GPTModel(nn.Module): 323 324 def __init__(self, vocab_size, d_model, d_ff, 325 d_k, d_v, n_heads, n_layers, pad_index, 326 device): 327 super(GPTModel, self).__init__() 328 self.decoder = MaskedDecoder( 329 vocab_size=vocab_size, 330 d_model=d_model, d_ff=d_ff, 331 d_k=d_k, d_v=d_v, n_heads=n_heads, 332 n_layers=n_layers, pad_index=pad_index, 333 device=device) 334 self.projection = nn.Linear(d_model, vocab_size, bias=False) 335 336 def forward(self, dec_inputs): 337 dec_outputs, dec_self_attns = self.decoder(dec_inputs) 338 dec_logits = self.projection(dec_outputs) 339 return dec_logits, dec_self_attns 340 341 342 class Classifier(nn.Module): 343 344 def __init__(self, vocab_size, d_model, d_ff, 345 d_k, d_v, n_heads, n_layers, 346 pad_index, device, num_classes): 347 super(Classifier, self).__init__() 348 self.encoder = Encoder( 349 vocab_size=vocab_size, 350 d_model=d_model, d_ff=d_ff, 351 d_k=d_k, d_v=d_v, n_heads=n_heads, 352 n_layers=n_layers, pad_index=pad_index, 353 device=device) 354 self.projection = nn.Linear(d_model, num_classes) 355 356 def forward(self, enc_inputs): 357 enc_outputs, enc_self_attns = self.encoder(enc_inputs) 358 mean_enc_outputs = torch.mean(enc_outputs, dim=1) 359 logits = self.projection(mean_enc_outputs) 360 return logits, enc_self_attns 361 362 363 class Translation(nn.Module): 364 365 def __init__(self, src_vocab_size, tgt_vocab_size, d_model, 366 d_ff, d_k, d_v, n_heads, n_layers, src_pad_index, 367 tgt_pad_index, device): 368 super(Translation, self).__init__() 369 self.encoder = Encoder( 370 vocab_size=src_vocab_size, # 5 371 d_model=d_model, d_ff=d_ff, # 128 256 372 d_k=d_k, d_v=d_v, n_heads=n_heads, # 64 64 8 373 n_layers=n_layers, pad_index=src_pad_index, # 4 0 374 device=device) 375 self.decoder = Decoder( 376 vocab_size=tgt_vocab_size, # 5 377 d_model=d_model, d_ff=d_ff, # 128 256 378 d_k=d_k, d_v=d_v, n_heads=n_heads, # 64 64 8 379 n_layers=n_layers, pad_index=tgt_pad_index, # 4 0 380 device=device) 381 self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False) 382 383 # def forward(self, enc_inputs, dec_inputs, decode_lengths): 384 # enc_outputs, enc_self_attns = self.encoder(enc_inputs) 385 # dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs) 386 # dec_logits = self.projection(dec_outputs) 387 # return dec_logits, enc_self_attns, dec_self_attns, dec_enc_attns, decode_lengths 388 389 def forward(self, enc_inputs, dec_inputs): 390 enc_outputs, enc_self_attns = self.encoder(enc_inputs) 391 dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs) 392 dec_logits = self.projection(dec_outputs) 393 return dec_logits, enc_self_attns, dec_self_attns, dec_enc_attns 394 395 396 if __name__ == '__main__': 397 enc_input = [ 398 [1, 3, 4, 1, 2, 3], 399 [1, 3, 4, 1, 2, 3], 400 [1, 3, 4, 1, 2, 3], 401 [1, 3, 4, 1, 2, 3]] 402 dec_input = [ 403 [1, 0, 0, 0, 0, 0], 404 [1, 3, 0, 0, 0, 0], 405 [1, 3, 4, 0, 0, 0], 406 [1, 3, 4, 1, 0, 0]] 407 enc_input = torch.as_tensor(enc_input, dtype=torch.long).to(torch.device('cpu')) 408 dec_input = torch.as_tensor(dec_input, dtype=torch.long).to(torch.device('cpu')) 409 model = Translation( 410 src_vocab_size=5, tgt_vocab_size=5, d_model=128, 411 d_ff=256, d_k=64, d_v=64, n_heads=8, n_layers=4, src_pad_index=0, 412 tgt_pad_index=0, device=torch.device('cpu')) 413 414 logits, _, _, _ = model(enc_input, dec_input) 415 print(logits)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号