基于pytorch框架对神经网络权重初始化(inite_weight)方法详解
今天重新研究了一下pytorch如何自定义权重,可以根据条件筛选赋值,也可以根据自定义某个张量赋值,还可以根据pth文件部分赋值等情况,
我总结了三种方法(self.modules(),self.state_dict(),self.named_parameters()),每种方法有约2种情况,希望对大家有所帮助,
然具体各自函数代表什么,可自行查阅,如self.parameters函数,我给出具体实现权重的初始化方法(已使用代码验证),具体实现如下:
code模块:
import torch
import torch.nn as nn
class MYMODEL(nn.Module):
def __init__(self, val):
super(MYMODEL, self).__init__()
self.val = val
self.layer1 = self.layer1()
self.layer2 = self.layer2()
self.layer3 = self.layer3()
# self.inite_weight_1()
# self.inite_weight_2()
self.inite_weight_3()
''' 权重修改方法 '''
''' 方法一 使用self.modules() 修改'''
def inite_weight_1(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
# 修改方法一
m.weight.data=torch.ones(m.weight.data.shape)*300 # 这样是可以修改的
# 修改方法二
# nn.init.kaiming_normal_(m.weight.data, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1.)
m.bias.data.fill_(1e-4)
elif isinstance(m, nn.Linear):
m.weight.data.normal_(0.0, 0.0001)
m.bias.data.zero_()
print('[finishing]:assign weight by inite_weight_1')
''' 方法二 使用state_dict() 修改'''
def inite_weight_2(self): # value 可以赋值
t=self.state_dict()
'''赋值方法一'''
for key, value in self.state_dict().items():
if 'layer1' in key: # 筛选条件
a=torch.ones(t[key].shape)*99 # 可以自己修改权重值
t[key].copy_(a)
'''赋值方法二'''
# for name, value in self.state_dict().items():
# if 'layer1' in name:
# nn.init.constant_(value, 40)
print('[finishing]:assign weight by inite_weight_2')
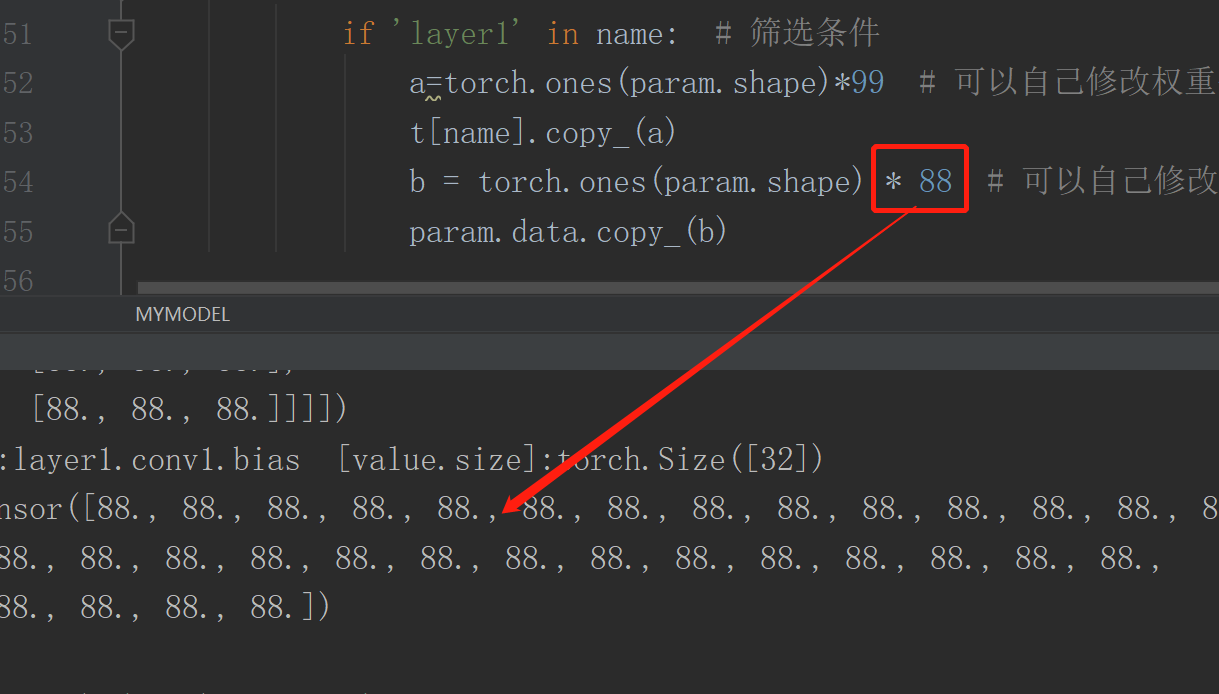
''' 方法三 self.named_parameters() 修改'''
def inite_weight_3(self):
t = self.state_dict()
'''方法一'''
for name, param in self.named_parameters():
if 'layer1' in name: # 筛选条件
a=torch.ones(param.shape)*99 # 可以自己修改权重值
t[name].copy_(a)
b = torch.ones(param.shape) * 88 # 可以自己修改权重值
param.data.copy_(b)
def layer1(self):
layer1 = torch.nn.Sequential()
layer1.add_module('conv1', torch.nn.Conv2d(3, 32, 3, 1, padding=1))
layer1.add_module('relu1', torch.nn.ReLU(True))
layer1.add_module('pool1', torch.nn.MaxPool2d(2, 2)) # b, 32, 16, 16 //池化为16*16
return layer1
def layer2(self):
layer2 = torch.nn.Sequential()
layer2.add_module('conv2', torch.nn.Conv2d(32, 64, 3, 1, padding=1))
# b, 64, 16, 16 //处理成64维, 16*16
layer2.add_module('relu2', torch.nn.ReLU(True))
layer2.add_module('pool2', torch.nn.MaxPool2d(2, 2)) # b, 64, 8, 8
return layer2
def layer3(self):
layer3 = torch.nn.Conv2d(64, 32, 1, 1)
return layer3
def forward(self, x):
layer1 = self.layer1(x)
layer2 = self.layer2(layer1)
layer3 = self.layer3(layer2) * self.val
return layer3
if __name__ == '__main__':
batch_size = (4, 6, 8, 3)
input_features = 8
state_size = 9
X = torch.randn((4, 64, 64, 3))
model = MYMODEL(4)
# model.inite_weight_2() # 也可以调用这个函数进行赋值
for params, value in model.state_dict().items():
if 'layer1' in params:
print('[params]:{} [value.size]:{}\n value{}'.format(params, value.shape, value))
结果显示模块:
self.modules()实现展示效果:

self.state_dict()展示效果:

self.named_parameters()展示效果:
以下是我2020年9月份写的,我现在将主要介绍核心代码提出来,如下所示:
b=torch.ones(m.weight.size())*15
b=torch.Tensor(b)
m.weight=torch.nn.Parameter(b)
可知,以下代码也是用self.modules()赋值,但主要是用m.weight赋值与
我今天所有m.weight.data赋值手法,有些差异,请仔细阅读。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
# 定义模型
class TheModelClass(nn.Module):
def __init__(self):
super(TheModelClass, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
for m in self.modules():
if isinstance(m,nn.Conv2d):
m.weight.data.fill_(7)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 初始化模型
model = TheModelClass()
# 初始化优化器
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# 模型自定义初始化
for m in model.modules():
if isinstance(m,nn.Conv2d):
b=torch.ones(m.weight.size())*15
b=torch.Tensor(b)
m.weight=torch.nn.Parameter(b)
print(m.weight)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号