Python|数据分析与网络爬虫
某农带专业Python课实验四
numpy数据分析
题目描述:利用numpy库完成2项编程任务。实验效果如图1-1所示。
(1)创建一个一维数组arr1,存放10个[10, 99]随机整数,计算其最大值,最小值和平均值。
(2)创建一个二维数组arr2,存放5行5列共25个[10, 99]随机整数,计算其最大值,最小值和平均值。
提示:使用numpy.array( )函数创建,通过列表生成数组对象。
# -*- coding: utf-8 -*-
"""
PROJECT_NAME: pythonProject_ lesson
FILE_NAME: numpy_analysis
AUTHOR: welt
E_MAIL: tjlwelt@foxmail.com
DATE: 2022/12/8
"""
import numpy as np
if __name__ == '__main__':
arr1 = np.random.randint(10, 99, 10)
arr1_max = arr1.max()
arr1_min = arr1.min()
arr1_mean = arr1.mean()
print("一维数组: ", arr1)
print("数据分析: 最大值={} 最小值={} 平均值={}".format(arr1_max, arr1_min, arr1_mean))
arr2 = np.random.randint(10, 99, (5, 5))
arr2_max = arr2.max()
arr2_min = arr2.min()
arr2_mean = arr2.mean()
print("二维数组: ", arr2)
print("数据分析: 最大值={} 最小值={} 平均值={}".format(arr2_max, arr2_min, arr2_mean))
pandas数据分析
题目描述:利用pandas库完成2项编程任务。
(1)利用列表、元组和字典分别创建3个一级索引的数据结构Series。
(2)利用字典和Series分别创建2个二级索引的数据结构DataFrame。
提示:使用pandas.Series( )和pandas.DataFrame( )分别创建一维Series和二维DataFrame数据结构;
# -*- coding: utf-8 -*-
"""
PROJECT_NAME: pythonProject_ lesson
FILE_NAME: pandas_analysis
AUTHOR: welt
E_MAIL: tjlwelt@foxmail.com
DATE: 2022/12/8
"""
import pandas as pd
if __name__ == '__main__':
print("创建3个一级索引的Series数据结构: ", end='\n')
obj_list = [98, 88, 78, 68]
obj_tuple = ("C++程序设计", "Python程序设计", "Java程序设计", "物联网工程")
obj_dict = {"201801": ["张珊", 18, "女", "计算机1801"],
"201802": ["李斯", 19, "男", "计算机1802"],
"201803": ["王武", 18, "男", "计算机1803"],
"201804": ["赵柳", 19, "女", "计算机1804"]}
series_list = pd.Series(obj_list, index=["No1", "No2", "No3", "No4"])
series_tuple = pd.Series(obj_tuple, index=["cId0001", "cId0002", "cId0003", "cId0004"])
series_dict = pd.Series(obj_dict)
print("(1)通过列表创建第一个Series数据结构: ")
print(series_list)
print("(2)通过元组创建第二个Series数据结构: ")
print(series_tuple)
print("(3)通过字典创建第三个Series数据结构: ")
print(series_dict)
print("(1)通过字典创建第一个DataFrame数据结构(学生信息): ")
print("创建2个二级索引的DataFrame数据结构:", end='\n')
stu = {"学号": ["201801", "201802", "201803", "201804", "201801"],
"姓名": ["张珊", "李斯", "王武", "赵柳", "周琪"],
"年龄": [18, 19, 19, 18, 18],
"性别": ["女", "男", "男", "女", "女"],
"班级": ["计算机1801", "计算机1802", "计算机1803", "计算机1804", "计算机1801"]
}
dataframe_stu = pd.DataFrame(stu)
print(dataframe_stu)
print("(2)通过Series创建第二个DataFrame数据结构(教师信息):")
obj_index = ["工号", "姓名", "年龄", "性别", "职称"]
series_list1 = pd.Series(["2001020", "张珊", 38, "女", "副教授"], index=obj_index)
series_list2 = pd.Series(["2001021", "李斯", 39, "男", "副教授"], index=obj_index)
series_list3 = pd.Series(["2001023", "王武", 39, "男", "副教授"], index=obj_index)
series_list4 = pd.Series(["2001024", "赵柳", 38, "女", "副教授"], index=obj_index)
series_list5 = pd.Series(["2001025", "周琪", 38, "女", "副教授"], index=obj_index)
dataframe_t = pd.DataFrame([series_list1, series_list2, series_list3, series_list4, series_list5])
print(dataframe_t)
matplotlib数据可视化
题目描述:利用csv、random、datetime、pandas和matplotlib库完成5项编程任务。
(1)利用csv、random和datetime创建1个WPF商店2018年营业额模拟数据文件data.csv,此文件中包含两列数据(日期date、销量amount)。模拟数据随机生成共365条,数据日期date起于2018-01-01止于2018-12-31,数据销量amount的取值范围为[300,600]之间。
(2)利用pandas读取文件data.csv中数据,创建1个行列索引的数据结构DataFrame,并删除其中的所有缺失值。
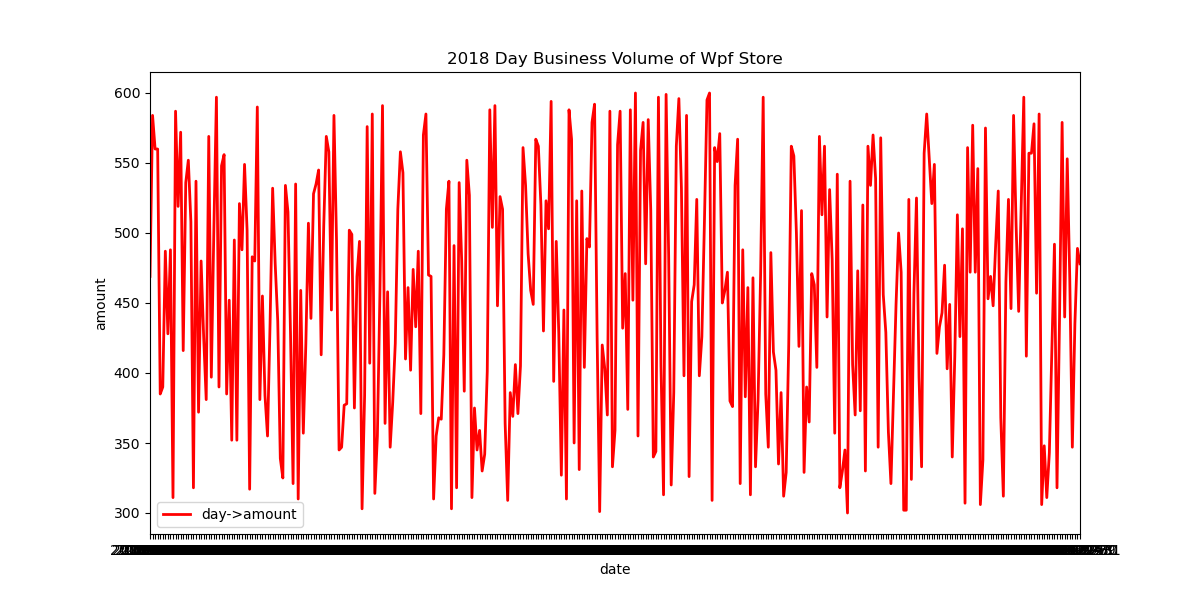
(3)利用matplotlib生成折线图,按每天进行统计,显示商店每天的销量情况,并把图形保存为本地文件day_amount_plot.png。实验效果如下图所示。
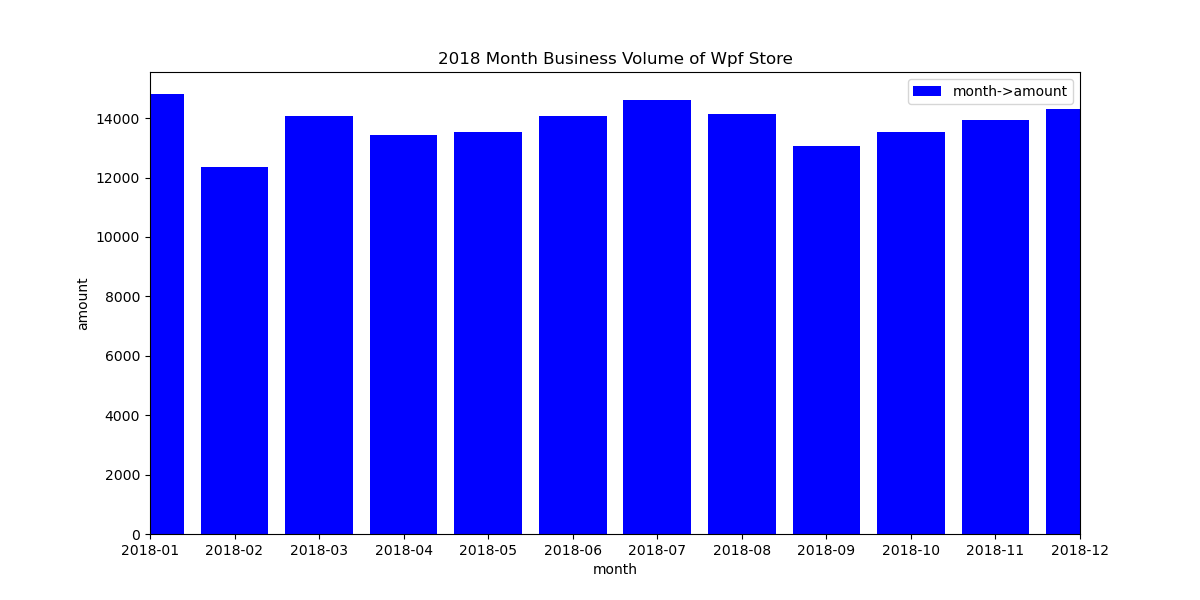
(4)利用matplotlib生成柱状图,按月份进行统计,显示商店每月的销量情况,并把图形保存为本地文件month_amount_bar.png。实验效果如下图所示。同时,找出相邻两个月最大涨幅,并把涨幅最大的月份写入到文件maxMonth.txt中。
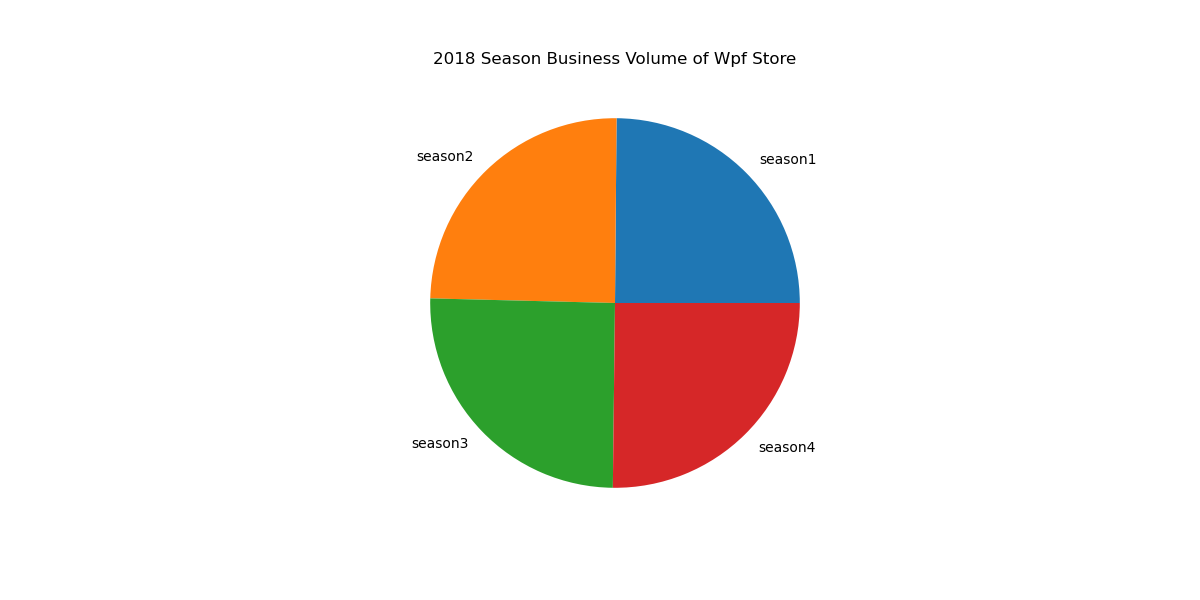
(5)利用matplotlib生成饼状图,按季度进行统计,显示商店4个季度的销量分布情况,并把图形保存为本地文件season_amount_pie.png。实验效果如下图所示。
提示:使用pandas.DataFrame( )创建二维DataFrame数据结构;使用matplotlib.pyplot库中的figure( )、plot( )、bar( )、pie( )、title( )、savefig( )和show( )等创建数据可视化图片,其功能分别设置图片大小、生成这线图、生成柱状图、生成饼状图、设置图片标题、保存图片和显示图片等。
# -*- coding: utf-8 -*-
"""
PROJECT_NAME: pythonProject_ lesson
FILE_NAME: plt_vis
AUTHOR: welt
E_MAIL: tjlwelt@foxmail.com
DATE: 2022/12/8
"""
import csv
import datetime
import random
import matplotlib.pyplot as plt
import pandas as pd
if __name__ == '__main__':
with open(r"data.csv", "w+", newline='') as csvfile:
wr = csv.writer(csvfile, dialect="excel")
wr.writerow(["date", "amount"])
startDate = datetime.date(2018, 1, 1)
for i in range(365):
amount = random.randint(300, 600)
wr.writerow([startDate, amount])
startDate = startDate + datetime.timedelta(days=1)
df = pd.read_csv("data.csv")
df = df.dropna()
fig = plt.figure(figsize=(12, 6))
ax = fig.add_subplot(1, 1, 1)
plt.plot(df["date"], df["amount"], label="day->amount", color="red", linewidth=2)
plt.legend(loc="best")
plt.title("2018 Day Business Volume of Wpf Store")
plt.xlabel("date")
plt.ylabel("amount")
plt.xlim("2018-01-01", "2018-12-31")
plt.savefig("day_amount_plot.png", )
plt.show()
df1 = df
df1["month"] = df1["date"].map(lambda x: x[:x.rindex('-')])
df1 = df1.groupby(by="month", as_index=False).sum()
plt.figure(figsize=(12, 6))
plt.bar(df1["month"], df1["amount"], label="month->amount", color="blue")
plt.title("2018 Month Business Volume of Wpf Store")
plt.xlabel("month")
plt.ylabel("amount")
plt.xlim("2018-01", "2018-12")
plt.legend(loc='best')
plt.savefig("month_amount_bar.png")
plt.show()
df2 = df1.drop("month", axis=1).diff()
m = df2["amount"].nlargest(1).keys()[0]
with open("max_month.txt", 'w') as txtfile:
txtfile.write(df1.loc[m, "month"])
txtfile.close()
season1 = df1[:3]['amount'].sum()
season2 = df1[3:6]['amount'].sum()
season3 = df1[6:9]['amount'].sum()
season4 = df1[9:12]['amount'].sum()
plt.figure(figsize=(12, 6))
plt.pie([season1, season2, season3, season4], labels=["season1", "season2", "season3", "season4"])
plt.title("2018 Season Business Volume of Wpf Store") # 设置图标题
plt.savefig('season_amount_pie.png')
plt.show()
csvfile.close() # 关闭文件
scipy数据分析
题目描述:利用scipy库完成2项编程任务。
(1)求解线性方程组。如下式所示。
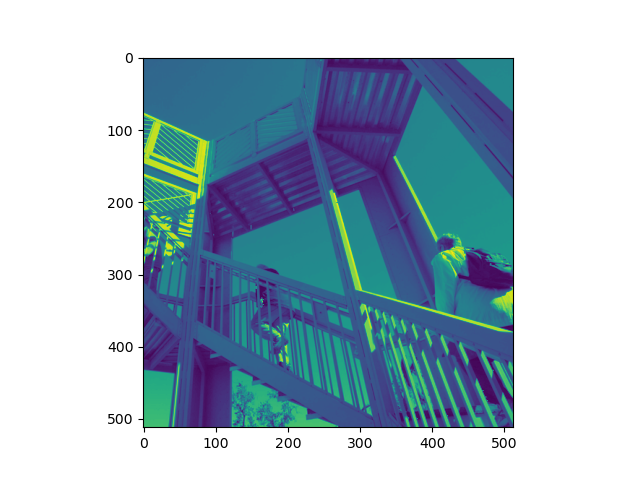
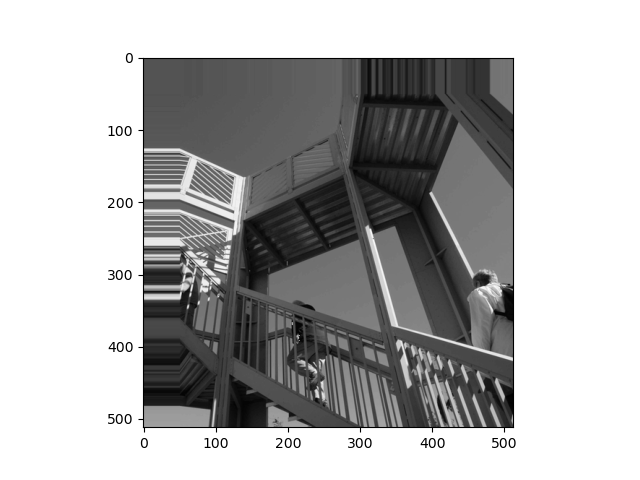
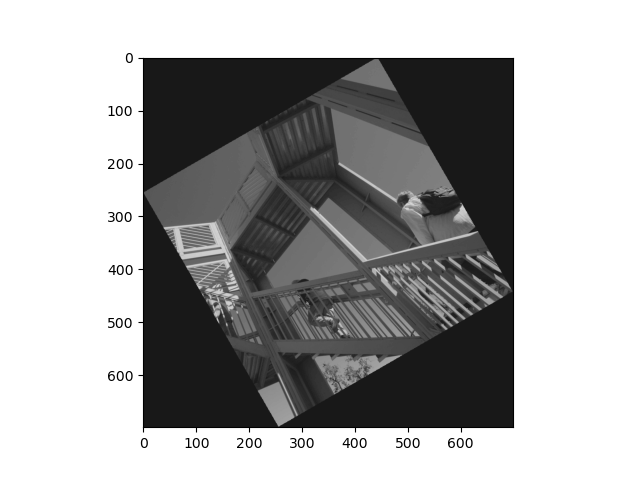
(2)图像处理。预处理灰度图片效果、平移处理未自动填充图片效果、平移处理自动填充图片效果、旋转处理图片效果如下图所示:

提示:使用scipy.mat( )和scipy.linalg.solve( )对线性方程求解;
使用scipy.ndimage和scipy.misc库对图像进行处理。使用pylab内部图库
# -*- coding: utf-8 -*-
"""
PROJECT_NAME: pythonProject_ lesson
FILE_NAME: scipy_analysis
AUTHOR: welt
E_MAIL: tjlwelt@foxmail.com
DATE: 2022/12/8
"""
import scipy
from scipy import ndimage
from scipy import misc
import pylab as pl
import numpy as np
if __name__ == "__main__":
print("方程求解的结果为: ", end='\n')
a = np.mat("[5 2 3; 2 3 -4; 3 -4 -5]")
b = np.mat("[6; 7; 8]")
result = scipy.linalg.solve(a, b)
print(result)
ascent = misc.ascent()
shifted_ascent = ndimage.shift(ascent, (50, 50))
shifted_ascent2 = ndimage.shift(ascent, (50, 50), mode="nearest")
rotated_ascent = ndimage.rotate(ascent, 30)
pl.imshow(ascent)
pl.figure()
pl.imshow(shifted_ascent, cmap='gray')
pl.figure()
pl.imshow(shifted_ascent2, cmap='gray')
pl.figure()
pl.imshow(rotated_ascent, cmap='gray')
pl.show()
requests爬取文本
题目描述:利用爬虫库requests、正则表达式解析库re和纯文本txt完成编程任务,任务是爬取豆瓣排行榜的电影名称。本爬虫实验分为三个步骤:
(1)第一步数据爬取,通过requests爬取豆瓣排行榜的电影名称数据;本步骤实验说明如下:
爬取网址url=”https://movie.douban.com/chart”
浏览器用户代理”User-Agent”:”Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebkit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39”
说明:不同机器安装的浏览器用户代理也不一样,需要打开网址后,通过F12键打开开发工具查看URL和User-Agent。
(2)第二步数据解析,通过正则表达式re解析豆瓣排行榜的电影名称数据;
本步骤解析数据参考正则表达式是:re.compile(’<a.?nbg.?title=”(.*?)”>’,re.S)
(3)第三步存储数据,通过纯文本存储豆瓣排行榜的电影名称数据。
代码实现:
# -*- coding: utf-8 -*-
"""
PROJECT_NAME: pythonProject_ lesson
FILE_NAME: douban_rank
AUTHOR: welt
E_MAIL: tjlwelt@foxmail.com
DATE: 2022/12/8
"""
from lxml import etree
import requests
import time
if __name__ == '__main__':
url = "https://movie.douban.com/chart"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/96.0.4664.93 Safari/537.36 '
}
data = requests.get(url, headers=headers).text
s = etree.HTML(data)
file = s.xpath('.//*[@id="content"]/div/div[1]/div/div/table/tr')
time.sleep(3)
Note = open('douban.txt', mode='w')
for div in file:
title = div.xpath("./td[1]/a/@title")[0]
print(title) # 输出爬取到的内容
Note.write(title+'\n')
requests爬取图片
题目描述:利用爬虫库requests、html提取库beautifulsoup4(简称bs4)、html解析库lxml和urllib库完成编程任务,任务是爬取wallhaven网站上的壁纸图片。
(1)第一步数据爬取,通过requests爬取wallhaven的html数据;本步骤实验说明如下:
爬取网址url=”https://wallhaven.cc/search?q=id:711&sorting=random&ref=fp”
浏览器用户代理”User-Agent”:”Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebkit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Mobile Safari/537.36”
说明:不同机器安装的浏览器用户代理也不一样,需要打开网址后,通过F12键打开开发工具查看URL和User-Agent。
(2)第二步数据解析,通过html提取库beautifulsoup4和html解析库lxml提取并解析wallhaven的html数据,本步骤提取并解析数据参考方法是:
res=requests.get(url,headers=headers)
html=res.text
info=BeautifulSoup(html,”lxml”)
data=info.select(”#thumbs > section > ul > li > figure > img”)
(3)第三步存储数据,通过目录./spider_picture存储wallhaven网站上的壁纸图片。实验效果如下图所示。
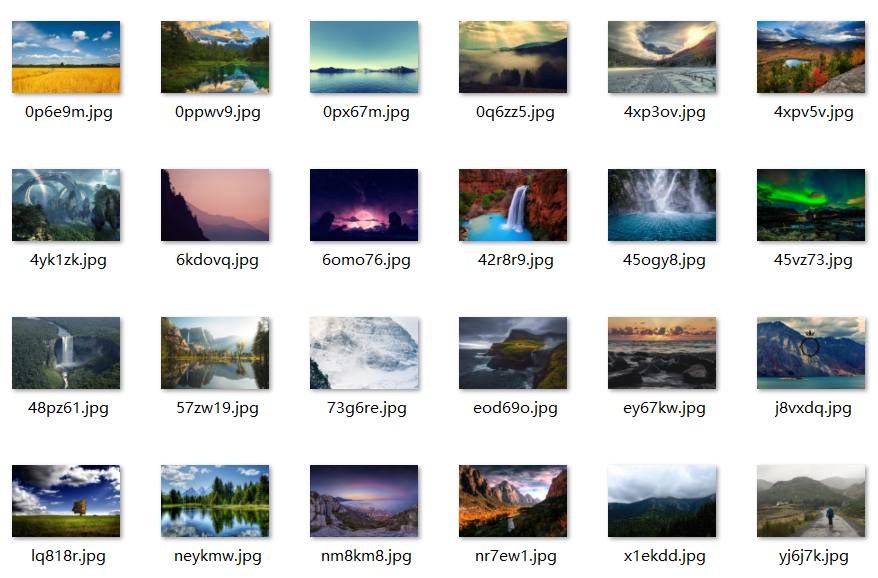
代码实现:
# -*- coding: utf-8 -*-
"""
PROJECT_NAME: pythonProject_ lesson
FILE_NAME: wallhaven_image
AUTHOR: welt
E_MAIL: tjlwelt@foxmail.com
DATE: 2022/12/8
"""
import requests
from bs4 import BeautifulSoup
import os
if __name__ == '__main__':
url = "https://wallhaven.cc/search?q=id:711&sorting=random&ref=fp"
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/96.0.4664.93 Safari/537.36 '
}
res = requests.get(url, headers=header)
html = res.text
info = BeautifulSoup(html, "lxml")
data = info.select("#thumbs section ul li figure img")
imagelist =[]
for i in data:
image = i.get("data-src")
imagelist.append(image)
if not os.path.exists('./wallpapers'):
os.mkdir('./wallpapers')
path = './wallpapers/'
for i in range(len(imagelist)):
img_url = imagelist[i]
img_data = requests.get(url=img_url, headers=header, timeout=20).content # 获取壁纸图片的二进制数据,加入timeout限制请求时间
img_name = img_url.split('/')[-1] # 生成图片名字
img_path = path + '/' + img_name
with open(img_path, 'wb') as fp:
fp.write(img_data)
