Python|使用Sklearn实现多元线性回归
实验目的
分析地面采集的光谱和LiDAR结构信息估计由于病虫害引起的失叶率。
实验要求
- 仅通过由光谱信息建立模型
- 仅仅通过由结构信息建立模型
- 由光谱信息和结构信息相结合建立模型
- 分别画训练数据和验证数据散点图,计算R2和RMSE
实验步骤
数据的预处理
(1)缺失数据处理
数据清洗(Tidy Data),是对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性。数据中里字段值为NaN的为缺失数据,不代表0而是说没有赋值数据。数据的缺失有很多原因,缺失不是错误、无效,需要对缺失的数据进行必要的技术处理,以便后续的计算与统计。这里使用Python库Pandas的 dropna函数删除数据中有NaN的行。
(2)数据分布分析
利用python库matplotlib中的boxplot()函数绘制箱线图,展现数据的分布(如上下四分位值、中位数等)
- 光谱信息的箱线图
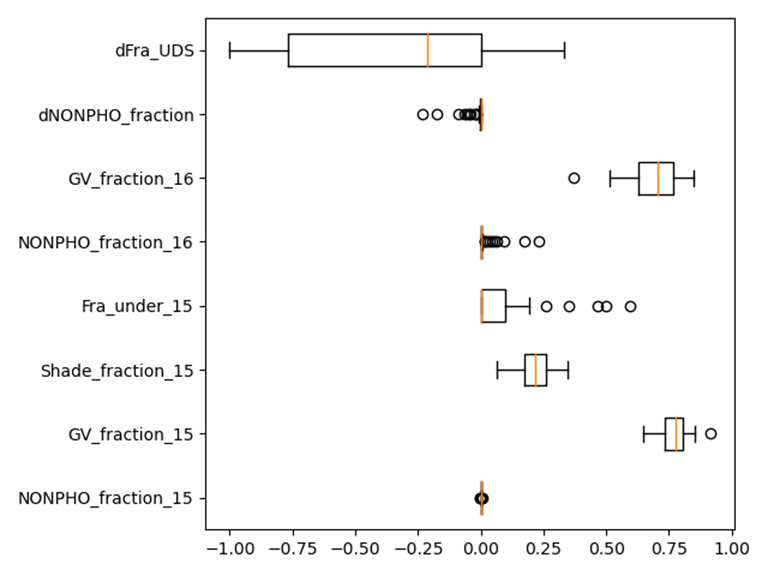
-
结构信息的箱线图
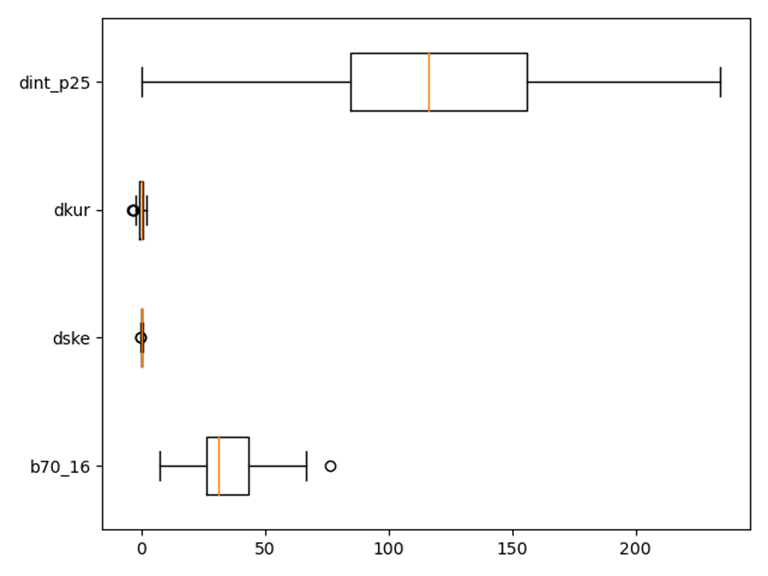
仅通过由光谱信息建立模型
利用Python的sklearn库对实验数据利用多元线性回归建立模型,使用的实验数据集包括88个样本,每个样本有8个特征值,标签值为失叶率。同时将数据集进行拆分,训练集用于模型训练,测试集用于测试,利用训练集训练出的模型对测试集进行模型预测。这里利用sklearn的train_test_split函数将20%的样本随机划分为测试集,80%为训练集,即test_size=0.2。并输出模型的回归系数与截距,利用测试集计算模型的MSE、RMSE与R-squared来评估模型。
【模型训练结果】
模型各变量的回归系数为:
[ 5.88849179e+09 1.24350016e+01 7.25992894e+01 -2.30475995e+01 -5.88848883e+09 9.64231529e+01 -5.88848868e+09 6.33932298e+01]
截距为:
-12.949615736092838
【分析】
这里可以发现,第一个,第五个,第七个变量的回归回归系数非常大,观察数据发现,这是由于这些变量的范围要远小于其他变量,因此导致其系数远大于其他变量。
【模型评估】
利用测试集的数据计算之前建立模型的各项评价指标,并输出各项评价指标,具体如下:
MSE: 212.7952942533906
RMSE: 14.58750473019257
R-squared: 0.8002298432796855
MSE:为212.80,RMSE为14.59,R-squared为0.80,模型的拟合度较高。
【预测结果与真实值的可视化对比】
- 为了更加直观,这里通过可视化查看训练后的预测和真实值之间的差异:
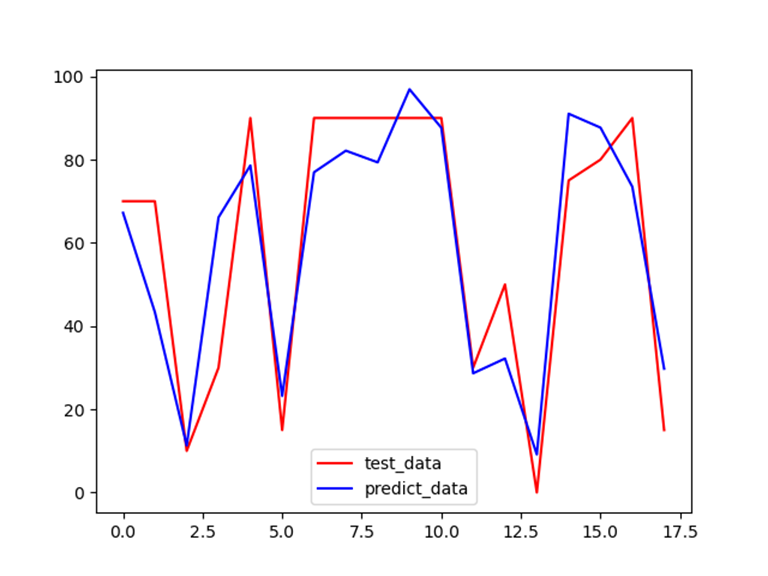
-
使用散点图来更直观地查看模型的拟合效果:
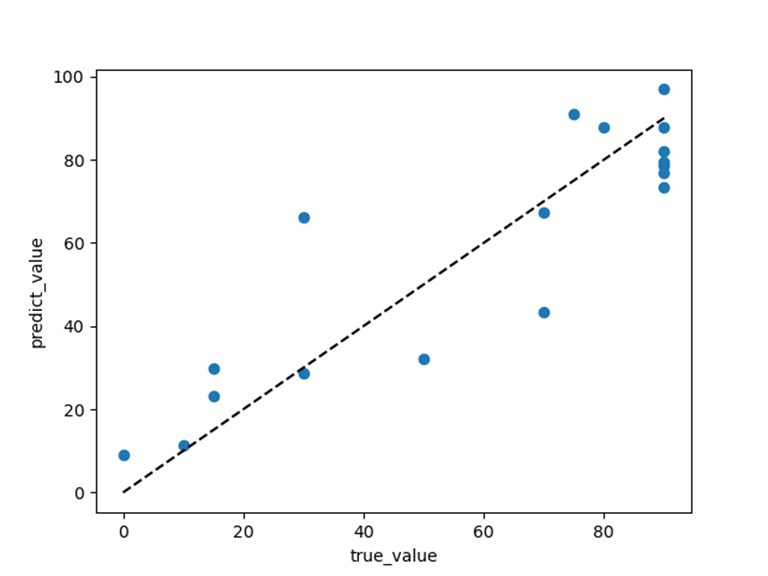
由结构信息建立模型
利用Python的sklearn库对实验数据利用多元线性回归建立模型,使用的实验数据集包括88个样本,每个样本有4个特征值,标签值为失叶率。同样将20%的样本随机划分为测试集,80%为训练集,即test_size=0.2。并输出模型的回归系数与截距,利用测试集计算模型的MSE、RMSE与R-squared来评估模型。
【模型训练结果】
模型各变量的回归系数为:
[-1.35196065 24.02382866 2.18823079 -0.17665905]
截距为:
122.83398957973037
【模型评估】
利用测试集的数据计算之前建立模型的各项评价指标,并输出各项评价指标,具体如下:
MSE: 189.60968255495263
RMSE: 13.769883171434412
R-squared: 0.8219962704880706
MSE为189.61,RMSE为13.77,低于仅使用光谱信息建立模型时的MSE与RMSE,R-squared为0.82,高于仅使用光谱信息建立模型时的R-squared,模型的拟合度较仅使用光谱信息建立模型时得到了提高。
【预测结果与真实值的可视化对比】
通过matplotlib可视化的展示预测和真实值之间的差异,便于我们直观地查看模型的拟合效果:
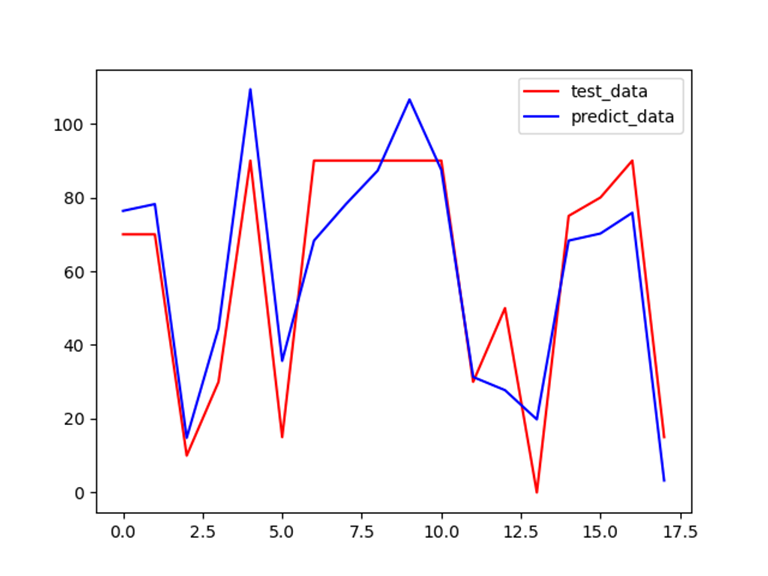
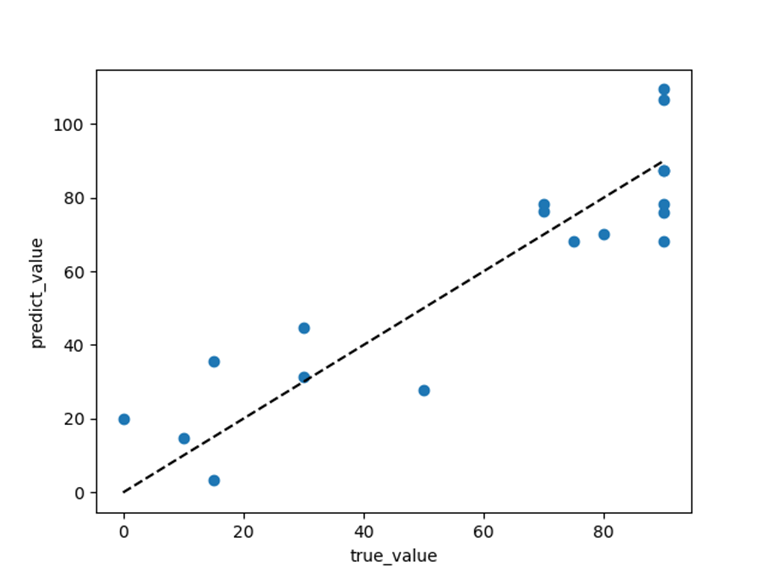
利用真实值与预测值绘制散点图查看模型的拟合效果:
由光谱信息和结构信息相结合建立模型
利用Python的sklearn库对实验数据利用多元线性回归建立模型,使用的实验数据集包括88个样本,每个样本有12个特征值,标签值为失叶率。同样将20%的样本随机划分为��试集,80%为训练集。并输出模型的回归系数与截距,利用测试集计算模型的MSE、RMSE与R-squared等指标来评估模型。
【模型训练结果】
模型各变量的回归系数为:
[ 4.72359996e+09 -3.17128108e+01 4.02986302e+01 -5.92449533e+00
-4.72359754e+09 1.00475691e+02 -4.72359760e+09 3.77783272e+01
-8.73478672e-01 2.03618398e+01 -4.46510285e-01 -1.09840890e-01]
截距为:
55.61060345492193
【分析】
在这里我也思考是否需要去掉部分变量来使得模型的拟合程度更高,但思考后觉得不应该去掉,因为我们是有先验知识表明这些变量和失叶率有关的,去掉某些不显著的变量虽然可以帮助模型更好的拟合我们自己的数据集,但可能造成模型的泛化能力弱等问题,因此我选择保留全部变量。
【模型评估】
利用测试集的数据计算之前建立模型的各项评价指标,并输出各项评价指标,具体如下:
MSE: 145.70792243385878
RMSE: 12.070953667124185
R-squared: 0.863210816751698
MSE为145.71,RMSE为12.07,低于仅使用光谱信息建立模型时和仅使用结构信息建立模型的MSE与RMSE,R-squared为0.86,高于此前的R-squared,模型的拟合度较之前得到了提高。
【预测结果与真实值的可视化对比】
预测和真实值之间的差异,便于我们直观地查看模型的拟合效果:
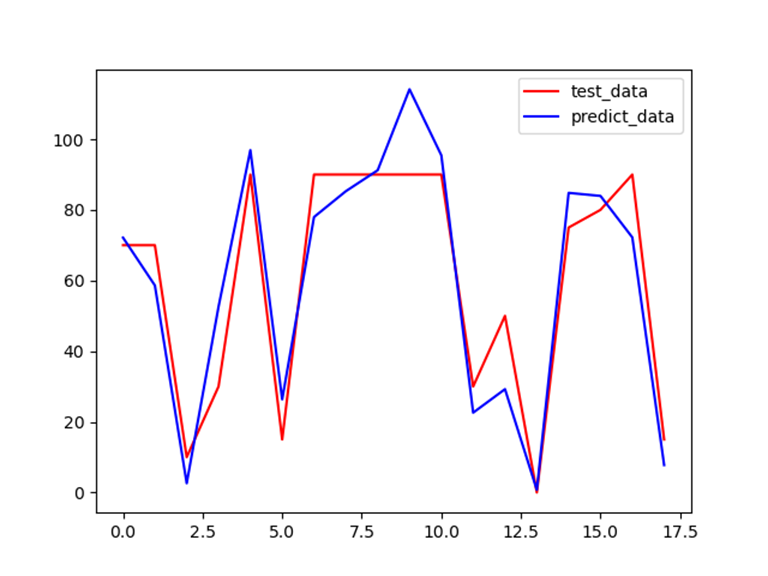
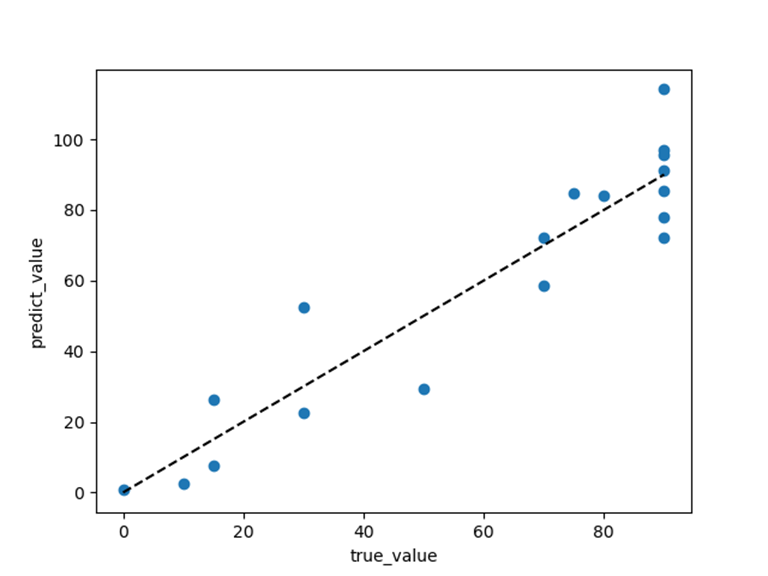
利用真实值与预测值绘制散点图查看模型的拟合效果:
总结
在加入更多的特征后,模型的拟合程度得到了提高,证明过多的相关特征更容易拟合。但关于特征纬度和过拟合的关系,只有从所解决问题的复杂度、样本多样性、算法复杂度等方面综合考量才知道是否会过拟合。本次实验中,因为实验数据量较少,因此实际上存在过拟合的可能。这里我也想过使用其他的方法来尽可能提高模型的拟合程度,但询问老师后与思考后认为,采用线性回归模型能尽可能提高模型的泛化能力,减少模型过拟合的可能。
使用的代码
使用python的matplotlib库绘制箱线图代码:
# -*- coding: utf-8 -*-
"""
PROJECT_NAME: Data_Analysis
FILE_NAME: Box_plot
AUTHOR: welt
E_MAIL: tjlwelt@foxmail.com
DATE: 2022/12/23
"""
import pandas as pd # 导入pandas
import matplotlib.pyplot as plt
dt = pd.read_csv('D:\实验一\实验数据\guangpu.csv')
# 使用matplotlib来画出箱型图
# fig = plt.figure(figsize=(13,8))
plt.boxplot(x=dt.values, labels=dt.columns, whis=1.5, vert=False) # columns列索引,values所有数值
plt.tight_layout()
plt.show()
使用python的scikit-learn库实现线性回归代码:
# -*- coding: utf-8 -*-
"""
PROJECT_NAME: Data_Analysis
FILE_NAME:LinearRegression
AUTHOR: welt
E_MAIL: tjlwelt@foxmail.com
DATE: 2022/12/23
"""
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import r2_score
from sklearn import metrics
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_predict, train_test_split
data = pd.read_csv('D:\实验一\实验数据\data.csv')
data = pd.DataFrame(data)
X = data[['NONPHO_fraction_15', 'GV_fraction_15', 'Shade_fraction_15', 'Fra_under_15', 'NONPHO_fraction_16',
'GV_fraction_16', 'dNONPHO_fraction', 'dFra_UDS']]
# X = data[['b70_16','dske','dkur','dint_p25']]
'''X = data[['NONPHO_fraction_15', 'GV_fraction_15', 'Shade_fraction_15', 'Fra_under_15', 'NONPHO_fraction_16',
'GV_fraction_16', 'dNONPHO_fraction', 'dFra_UDS', 'b70_16', 'dske', 'dkur', 'dint_p25']]'''
y = data['Average.Defol..Status.x']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=10)
'''
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
'''
lr = LinearRegression()
lr.fit(X_train, y_train)
print(lr.coef_)
print(lr.intercept_)
y_pred = lr.predict(X_test)
MSE = metrics.mean_squared_error(y_test, y_pred)
RMSE = np.sqrt(metrics.mean_squared_error(y_test, y_pred))
RS = r2_score(y_test, y_pred)
print('MSE:', MSE)
print('RMSE:', RMSE)
print('R-squared:', RS)
# plt.figure(figsize=(15,5))
plt.plot(range(len(y_test)), y_test, 'r', label='test_data')
plt.plot(range(len(y_test)), y_pred, 'b', label='predict_data')
plt.legend()
plt.show()
plt.scatter(y_test, y_pred)
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'k--')
plt.xlabel('true_value')
plt.ylabel('predict_value')
plt.show()
