Python|遥感影像语义分割:常用精度指标及其Python实现
深度学习中的常用精度指标:
基本概念
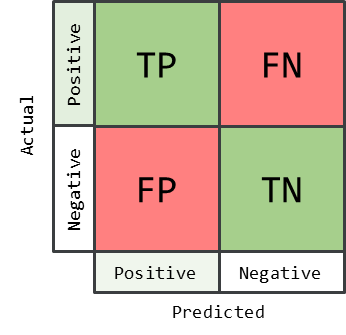
在介绍精度指标前我们先来明确以下几个概念,对应的示意图如下图所示:
TP(True Positive):分类准确的正类,意思是预测结果为正类,实际上是正类。
FP(False Positive):被错分类为正类的负类,意思是实际为负类,但是却被预测为正类。
TN(True Negative):分类准确的负类,意思是预测结果为负类,实际上是负类。
FN(False Negative):被错分类为负类的正类,意思是实际为正类,但是却被预测为负类。
精度评价指标
1. 准确率
准确率(Accuracy),是评估分类模型性能的一种基本指标。准确率衡量的是模型正确预测的样本数与总样本数之间的比例。准确率的具体计算公式如下:
$$
\text { Accuracy }=\frac{T P+T N}{T P+F P+F N+T N}
$$
2. 精确率
精确率(Precision)的含义是正确预测为正样本的占全部预测为正样本的比例,高的精确率意味着模型的现有预测结果尽可能不出错,但同时漏检的比例也大大增加,精确率的计算公式如下:
$$
\text { Precision }=\frac{T P}{T P+F P}
$$
3. 召回率
召回率(Recall)是针对原样本而言的,其含义是在实际为正的样本中被预测为正样本的概率。召回率的计算公式如下:
$$
\text { Recall }=\frac{T P}{T P+F N}
$$
4. F1分数
在理想状态下,希望模型的精确率和召回率都尽可能高。然而这两个指标往往存在相互制约的关系,提高一个指标可能会导致另一个指标下降。为了平衡精确率和召回率,通常使用F1分数(F1 Score)作为评价指标。F1分数是精确率和召回率的调和平均数,能够有效地反映模型的精确性和鲁棒性,是评估分类模型性能的重要指标。其计算公式如下:
$$
F_1=\frac{2 \times \text { Precision } \times \text { Recall }}{\text { Precision }+ \text { Recall }}
$$
5. 交并比
交并比(Intersection over union,IoU)是某一类别预测结果和真实值的交集与并集的比值,是语义分割中常用的评价指标,其计算公式如下:
$$
I o U=\frac{T P}{T P+F N+F P}
$$
python实现
使用sklearn提供的计算各项精度指标的包来计算精度指标
# -*- coding: utf-8 -*-
# 直接使用sklearn计算精度指标
import numpy as np
from sklearn.metrics import confusion_matrix, f1_score, recall_score, precision_score, accuracy_score
def one_hot_to_integer(labels):
"""将one-hot编码的标签转换为整数标签"""
return np.argmax(labels, axis=1).astype(int)
def accuracy_evaluate(label, pred):
pred = one_hot_to_integer(pred)
label = one_hot_to_integer(label)
pred = pred.reshape(-1)
label = label.reshape(-1)
Acc = accuracy_score(label, pred)
precision = precision_score(label, pred, average='micro')
recall = recall_score(label, pred, average='micro')
F1 = f1_score(label, pred, average='micro')
conf_mat = confusion_matrix(label, pred)
intersection = np.diag(conf_mat)
union = np.sum(conf_mat, axis=1) + np.sum(conf_mat, axis=0) - np.diag(conf_mat)
IoU = intersection / union
return Acc, precision, recall, F1, IoU[0]
