

OCR辅助网络游戏中的知识问答(附GitHub链接)
2020-05-17 20:17 唐建威 阅读(1154) 评论(0) 编辑 收藏 举报项目背景
我目前在玩一款叫做《剑网三》的网络游戏。这款游戏里有一个叫做“科举”的活动,是一个问答交互,回答正确后获得游戏奖励。
科举的问题大多与中国古代文化相关,比如:“孔子的姓氏是什么”,“《青岩诗钞•卷三》中诗词的作者是谁”。作为一名普通玩家,很难的回答出所有问题。这时玩家们通常都使用搜索引擎进行辅助。
然而,遇到下面这条科举试题,玩家搜索时的输入量便成了负担。游戏里的文本并不允许复制,并且许多玩家对于搜索引擎的使用也停留在入门水平。
单选题:伟伟,房子,和粽子为试验对毒物的抵抗力,决定各选一种毒物服食,他们三人分别吃下了鹤顶红,断肠草和一钩吻,他们即将中毒死去了,这是粽子从怀里掏出了六种解毒药物,炭灰,碱水,催吐汤,绿豆,金银花,甘草,他们之中谁不会死?,
答案:房子。
那么,我们该如何简化这个过程呢? 如果玩家只需要截一下图就好了。项目就从这里开始。。
项目介绍
项目处理数据的流程为:收到图片---识别上传---识别接收---题库查找---返回结果----发送到QQ
这里演示下项目的成果:
图片接收
首先我需要读取QQ的图片,这里我使用的软件叫酷Q:https://cqp.cc/t/23253
通过这款软件我可以利用web服务和QQ进行交互。下图为酷Q收到信息时,我们能获取到的信息。

我对图里的信息进行简单的讲解。
第一行表示我收到了一条私聊信息(private message)。
第二行的 "self: 1442982809” 是机器人的QQ号, 然后 "message 299" 则是信息的id,“from 695513761” 是说 信息来自与695513761这个qq号。接下来的一长串则是内容,它由 ‘科举’ 和 ‘图片信息’ 组成。
第三行开始,程序对信息内容进行解读。
接下来内容我一起说,我预设了“科举”这个词作为指令,作为接下来操作的触发条件。它对信息内容进行split的时候,发现了“科举”这个词,与之绑定的则是一个叫做“exam”的function。这个function根据信息里的图片链接,把图片下载了下来,保存在question.jpg这个路径。这样,我们本地就拥有了这个图片。bam!接受图片成功!
图片上传-OCR识别-识别文字接收
虽然我是一名硬核的NLP选手,喜欢自己训练模型。但是这里我还是使用了百度的API,毕竟简单快捷。百度的API里有更好的图文资料:https://ai.baidu.com/ai-doc/OCR/dk3iqnq51,我就不多做介绍了。
题库查找
题库构建
网络游戏的题库一般在网上可以找到,剑网三也不例外。
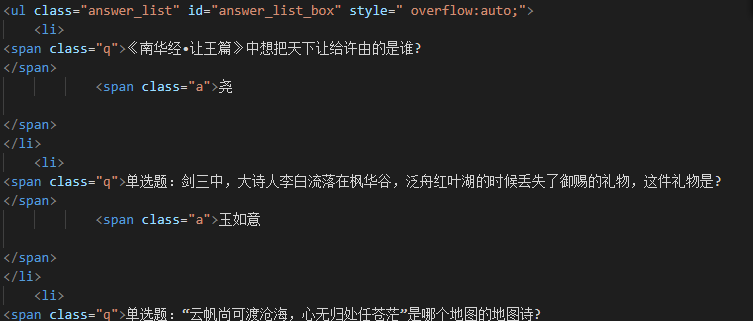
我直接把网页HTML里答案的部分复制了下来,通过正则表达式轻松获取干净整洁的 【问题-答案】 们,保存为qa.csv。

题库检索
接下来我们使用whoosh https://whoosh.readthedocs.io/en/latest/intro.html,一个python库来帮我们搭建这个检索功能。
首先,我们要把整理好的题库,创建为index。这个过程中,我们需要把每一条数据进行分词处理,好在jieba分词能帮我们很方便的完成这个操作。
from whoosh.index import create_in from whoosh.fields import * import os import csv from jieba.analyse import ChineseAnalyzer my_analyzer = ChineseAnalyzer() # chinese analyzer schema = Schema(question=TEXT(stored=True,analyzer=my_analyzer,field_boost=3.0), answer=TEXT(stored=True,analyzer=my_analyzer)) if not os.path.exists("indexdir"): os.mkdir("indexdir") ix = create_in("indexdir",schema) writer = ix.writer() with open('qa.csv', encoding='utf-8') as qa: reader = csv.reader(qa) for row in reader: writer.update_document(question=row[0],answer=row[1]) writer.commit()
我们从jieba.analyse里引入的ChineseAnalyzer可以直接在whoosh里使用。
我们也把schema简单的设置下。考虑到用户截图时会把答案部分也截进去,这里我把科举的问题和答案,都加入到了检索功能中,他们在这里被称为field。我对科举的“问题”部分进行了一个boost - “field_boost=3.0”。这意味着问题的匹配度拥有更高的权重。
接下来就是把qa.csv里的数据一条条的update到index里。
有了index之后,我们就可以开始检索了。我们定义一个search() 方法,输入文字,输出答案。
from whoosh.fields import * from whoosh import qparser from whoosh.qparser import QueryParser,MultifieldParser from whoosh.index import create_in import whoosh.index as index ix = index.open_dir("indexdir") def search(query_text): with ix.searcher() as searcher: og = qparser.OrGroup.factory(0.8) parser = MultifieldParser(["question","answer"], ix.schema,group=og) # parser.add_plugin(qparser.FuzzyTermPlugin()) query = parser.parse(query_text) print(f'Search for: {query_text}') results = searcher.search(query, limit=1) # runtime = results.runtime answer = '' for passage in results: answer = passage['answer'] return answer
这里可以注意的一个地方就是,results = searcher.search(query, limit=1)这里的 Limit =1。也就是我们只要相关度最高的一个搜索结果。原因是,OCR对于游戏字体的识别度很高,几乎无差错,只要玩家对于科举题目的截图比较完整,我们一定能找到题库里对应的答案。
答案以字符串的形式直接输出。接下来我们只需要把这个字符串作为qq的回复就好。
发送QQ
这里我直接贴上代码,接收信息和发送信息的部分都包含在里面。
from nonebot import on_command, CommandSession import glob import os import re from nonebot.command.argfilter.extractors import extract_image_urls import urllib.request from ocr_search import run # on_command 装饰器将函数声明为一个命令处理器 # 这里 exam 为命令的名字,同时允许使用别名「科举」「科举考试」 @on_command('科举', only_to_me=False, aliases=('科举考试','exam')) async def exam(session: CommandSession): # 从会话状态(session.state)中获取问题名称(question),如果当前不存在,则询问用户 question = session.get('question', prompt='把题目截图给我看看') # 问题的答案 exam_report = await get_answer_of_question(question) # 向用户发送答案 await session.send(exam_report) # exam.args_parser 装饰器将函数声明为 exam 命令的参数解析器 # 命令解析器用于将用户输入的参数解析成命令真正需要的数据 @exam.args_parser async def _(session: CommandSession): stripped_arg = session.current_arg_images if session.is_first_run: # 该命令第一次运行(第一次进入命令会话) if stripped_arg: # 第一次运行参数不为空,意味着用户直接将城市名跟在命令名后面,作为参数传入 # 例如用户可能发送了:科举 [图片] session.state['question'] = stripped_arg return if not stripped_arg: # 用户没有发送有效的问题截图(而是发送了空白字符),则提示重新输入 # 这里 session.pause() 将会发送消息并暂停当前会话(该行后面的代码不会被运行) session.pause('要查询的题目不能为空呢,请重新输入') # 如果当前正在向用户询问更多信息(例如本例中的要查询的问题),且用户输入有效,则放入会话状态 session.state[session.current_key] = stripped_arg async def get_answer_of_question(question: str) -> str: # 这里简单返回答案 urllib.request.urlretrieve(question[0], "question.jpg") answer = run('question.jpg') if len(answer.strip())<1: return '对不起,没有找到答案' return f'{answer}'
结语
项目到这里就结束了。很感谢《一个基于OCR识别的剑网三科举智能答题器》的作者,这里是他的GitHub链接: https://github.com/Moying-moe/jx3_exam_auto_answer
项目总共耗时大概10小时,其中9个小时都在折腾与qq交互。百度OCR的API很快就申请好,whoosh部分我之前写过英文的检索可以直接拿来用。最难的部分在于获取qq群图片,我在没有仔细阅读文档的时候不断尝试且失败。比如:我尝试获取QQ图片缓存路径里最新添加的一张图片。。。
我相信这类应用的价值,不止在《剑网三》,它可以很容易的被移植到其他游戏上。它就像一个游戏百科,不仅仅是回答科举问题,还可以回答各式各样的其他问题,比如:任务攻略,物品价格,赛事新闻。它是一个可交互的媒体。
剑网三目前也已经有了这样的应用,叫做“球球”,是个讨人喜欢的机器人小家伙,我的游戏好友群也订阅了这个服务。今天和他们的创作人员分享了这个项目后,他们也很热情的与我交流,发现他们也尝试过做OCR识别,后来因为一些其他原因而放弃掉了。
非常感谢你能看到这里。 我留下GitHub链接:https://github.com/tangermi/OCR_QQ_JX3
