

数据库
数据库
存储引擎(ENGINE)
数据库在程序中扮演的角色:存储数据
DBMS 数据库管理系统
RDBMS mysql(软件) 关系型数据库管理系统
sql语句 结构化查询语句,指令
数据data 描述事物的符号记录称为数据
数据库(db)database 存放数据的仓库
表table 即文件,用来存放多行内容/多条记录
数据库管理系统DBMS 组织,存储数据,高效获取和维护数据的系统软件
数据库管理员DBA 管理数据库的人
数据库服务器 一台计算机,运行数据库管理软
数据库分类:
关系型:关系型数据库模型是把复杂的数据结构归结为简单的二元关系,每个字段之间关系紧密,通过任何一个字段都可以查到该组数据,速度相对慢,数据之间关联紧密
非关系型:非关系型数据库以键值对存储,只能通过key,去获取value,存储数据快,数据之间关联较弱
数据库的优势:
1. 程序稳定性 :这样任意一台服务所在的机器崩溃了都不会影响数据和另外的服务。
2. 数据一致性 :所有的数据都存储在一起,所有的程序操作的数据都是统一的,就不会出现数据不一致的现象
3. 并发 :数据库可以良好的支持并发,所有的程序操作数据库都是通过网络,而数据库本身支持并发的网络操作,不需要我们自己写socket
4. 效率 :使用数据库对数据进行增删改查的效率要高出我们自己处理文件很多
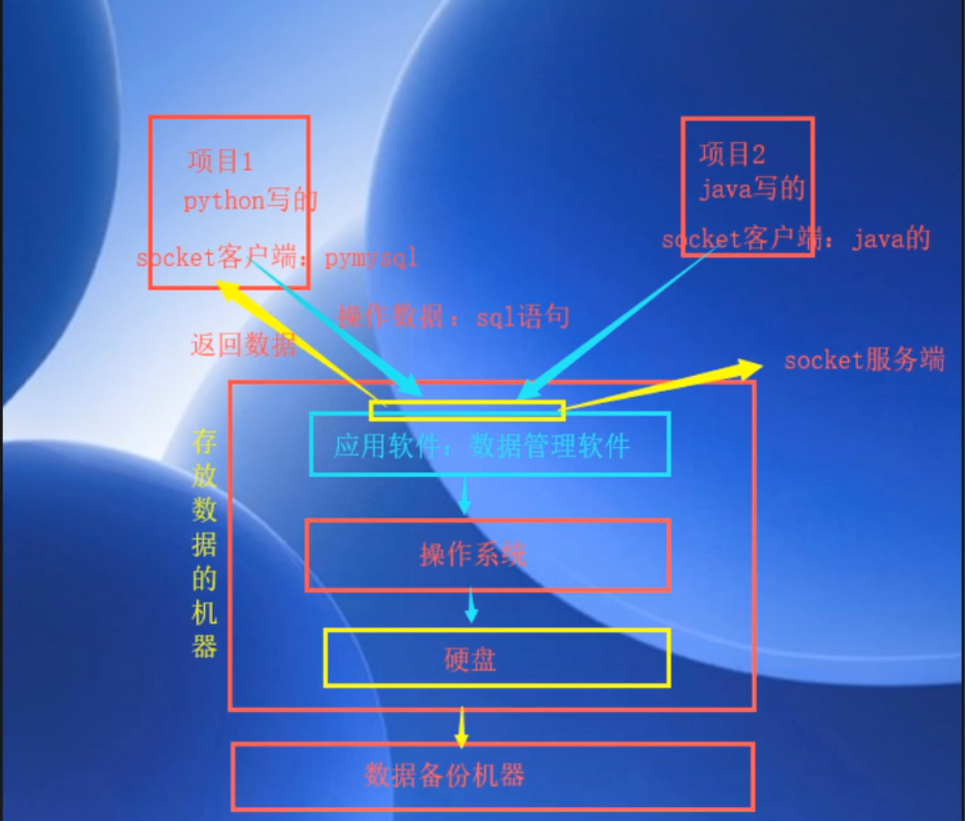
通过你自己的电脑上的程序来操作服务器上的数据,通过socket发送数据/接收数据,数据库管理系统本身就是一个c/s架构的软件,软件提供给我们的服务端来操作这些数据,所有得有一个客户端.
硬盘来存放数据,没有操作系统根本玩不了,DBMS是应用级别的软件,应用级别的软件想操作硬盘必须通过操作系统完成调用,要把数据库管理系统服务端运行起来,所以肯定还需要一个客户端给数据库管理系统的服务端发送指令(sql语句),DBMS 服务端接收到这条指令之后,根据指令要求去磁盘中找出来,在发送回给客户端
mysql 在 cmd 中的操作命令
库:
查看数据库:show databases;
创建数据库:create database db1(数据库名字);
使用数据库:use db1(库名);
删除库:drop database 库名;(慎用!!!!)
表:
查看当前库下的所有表:show tables;
查看表的记录信息:select * from stu(表名);
查看刚刚创建的那一张表:show create table stu;
查看一张表的基本信息(结构):desc stu(表名);
创建表:create table stu(id int,name char(16));
新增一条记录:insert into stu values(1,'海狗'),(2,'八戒');
在原来表的基础上添加一列性别:alter table classinfo add colum(sex varchar(2) comment '性别');
设置默认值:create table stu(id int,bith char(10),sex char(10) NULL DEFAULT '男');(sex默认为男)
在新建数据时需要默认值就写default 不需要默认值就该写啥写啥
修改表名:rename table test(旧名) to test1(新名);
修改字段名:alter table 表名 change 旧字段名 新字段名 数据类型;(能修改字段名和数据类型)
alter table 表名 modify 数据类型;(只能修改数据类型)
更新数据:update 表名 set 字段 = 值 where 条件;(把满足条件的字段内容改了)
update 表名 set 字段 = 值;(把这个字段的内容都改)
删除字段:alter table 表名 drop 字段名;
删除数据:delete from 表名 where 条件;(清空满足条件的数据)
清空表中数据:delete from 表名;
删除表:drop table 表名称;
#Mysql字段类型:
整数:int bigint
小数:float double decimal
日期:date datetime
字符串:char varchar text
二进制:blob
sum(字段) --求和
max(字段) --求最大值
min(字段) --求最小值
avg(字段) --求平均值
count(字段) --求个数
select 函数名(字段) from 表名;
#where 筛选条件:
比较:
=, !=, >, <, >=, <=
in(在什么范围之内), not in(不在什么范围之内)
Between(类似于 >= and <=)
逻辑
and 同时满足多个条件
or 满足任意一个条件
模糊筛选:
like '模糊关键字%' --以模糊关键字开头的
like '%模糊关键字' --以模糊关键字结尾的
like '%模糊关键字%' --只要保护模糊关键字的
MySQL客户端连接服务端时的完整指令
mysql -h 127.0.0.1 -P 3306 -u root -p
忘记密码的解决办法以及修改密码的三种方式
忘记密码的解决办法
1 停掉MySQL服务端(net stop mysql)
2 切换到MySQL安装目录下的bin目录下,然后手动指定启动程序来启动mysql服务端,指令: mysqld.exe --skip-grant-tables
3 重新启动一个窗口,连接mysql服务端,
4 修改mysql库里面的user表里面的root用户记录的密码:
update user set password = password('666') where user='root';
5 关掉mysqld服务端,指令:
tasklist|findstr mysqld
taskkill /F /PID 进程号
6 正常启动服务端(net start mysql)
修改密码的三种方式
方法1: 用SET PASSWORD命令
首先登录MySQL,使用mysql自带的那个客户端连接上mysql。
格式:mysql> set password for 用户名@localhost = password('新密码');
例子:mysql> set password for root@localhost = password('123');
方法2:用mysqladmin (因为我们将bin已经添加到环境变量了,这个mysqladmin也在bin目录下,所以可以直接使用这个mysqladmin功能,使用它来修改密码)关于mysqladmin的介绍:是一个执行管理操作的客户端程序。它可以用来检查服务器的配置和当前状态、创建和删除数据库、修改用户密码等等的功能,虽然mysqladmin的很多功能通过使用MySQL自带的mysql客户端可以搞定,但是有时候使用mysqladmin操作会比较简单。
格式:mysqladmin -u用户名 -p旧密码 password 新密码
例子:mysqladmin -uroot -p123456 password 123
方法3:用UPDATE直接编辑那个自动的mysql库中的user表 首先登录MySQL,连接上mysql服务端。
mysql> use mysql;
use mysql的意思是切换到mysql这个库,这个库是所有的用户表和权限相关的表都在这个库里面,我们进入到这个库才能修改这个库里面的表。
mysql> update user set password=password('123') where user='root' and host='localhost'; 其中password=password('123') 前面的password是变量,后面的password是mysql提供的给密码加密用的,我们最好不要明文的存密码,对吧,其中user是一个表,存着所有的mysql用户的信息。
mysql> flush privileges; 刷新权限,让其生效,否则不生效,修改不成功
存储引擎(ENGINE)
存储引擎:把数据存储到磁盘上的规则,数据的存储方式,针对表
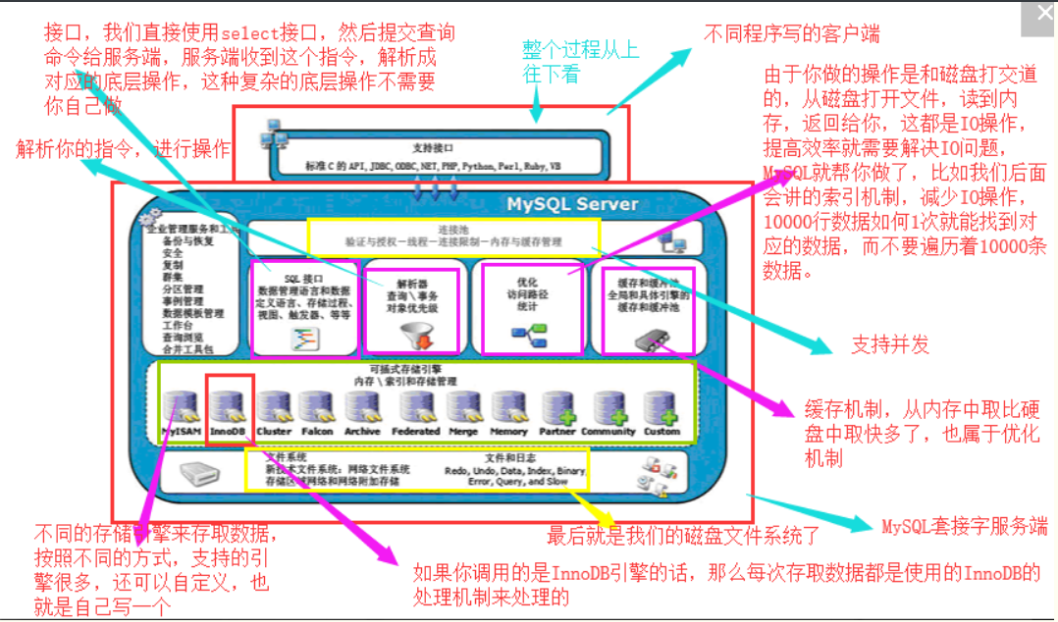
服务端开启,客户端连接服务端的接口,进入连接池(包括权限,线程,连接限制),客户端发送指令给mysql的服务端,服务端接收到这个指令,解析成对应的底层操作,然后解析器解析接受到的指令,进行操作,然后优化(包括查询速度加快等),解析完后,要去磁盘中拿数据,在这个过程中要经过存储引擎,.找自己指定的存储引擎,然后进入磁盘文件系统,在发送给客户端.
查看表的存储引擎指令:
create table myisam_t (id int,name char(18)) engine = myisam;
create table memory_t (id int,name char(18)) engine = memory;
#存储引擎的分类
1.MYISAM
MyISAM引擎特点:
1.不支持事务
事务是指逻辑上的一组操作,组成这组操作的各个单元,要么全成功要么全失败。
2.表级锁定
数据更新时锁定整个表:其锁定机制是表级锁定,也就是对表中的一个数据进行操作都会将这个表锁定,其他人不能操作这个表,这虽然可以让锁定的实现成本很小但是也同时大大降低了其并发性能。
3.读写互相阻塞
不仅会在写入的时候阻塞读取,MyISAM还会再读取的时候阻塞写入,但读本身并不会阻塞另外的读。
4.只会缓存索引
MyISAM可以通过key_buffer_size的值来提高缓存索引,以大大提高访问性能减少磁盘IO,但是这个缓存区只会缓存索引,而不会缓存数据。
5.读取速度较快
占用资源相对较少
6.不支持外键约束,但只是全文索引
7.MyISAM引擎是MySQL5.5版本之前的默认引擎,是对最初的ISAM引擎优化的产物。
2.InnoDB
InnoDB引擎特点:
1.支持事务:支持4个事务隔离界别,支持多版本读。
2.行级锁定(更新时一般是锁定当前行):通过索引实现,全表扫描仍然会是表锁,注意间隙锁的影响。
3.读写阻塞与事务隔离级别相关(有多个级别,这就不介绍啦~)。
4.具体非常高效的缓存特性:能缓存索引,也能缓存数据。
5.整个表和主键与Cluster方式存储,组成一颗平衡树。(了解)
6.所有SecondaryIndex都会保存主键信息。(了解)
7.支持分区,表空间,类似oracle数据库。
8.支持外键约束,不支持全文索引(5.5之前),以后的都支持了。
9.和MyISAM引擎比较,InnoDB对硬件资源要求还是比较高的。
小结:三个重要功能:Supports transactions,row-level locking,and foreign keys
3.Memory
正如其名,Memory 存储引擎中的数据都存放在内存中,数据库重 启或发生崩溃,表中的数据都将消失。它非常适合于存储 OLTP 数据库应用中临时数据的临时表,也可以作为 OLAP 数据库应用中数据仓库的维度表。Memory 存储引擎默认使用哈希 索引,而不是通常熟悉的 B+ 树索引。
4.BLACKHOLE
黑洞存储引擎,可以应用于主备复制中的分发主库
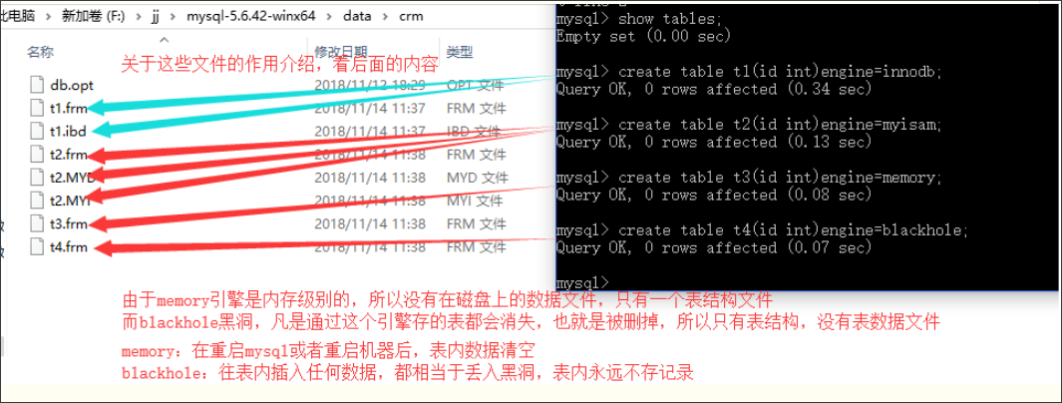
不同引擎在创建表的时候生成文件的不同
create table t1(id int)engine=innodb; 生产的文件有两个,包括树形结构(数据+树)+表结构
create table t2(id int)engine=myisam; 生产三个文件包括(树形结构 + 数据 + 表结构)
create table t3(id int)engine=memory;
create table t4(id int)engine=blackhole;
表的数据类型
表的介绍

创建表

表的数据类型
支持4种数据类型
1.数值
create table int_t(ti tinyint,i int,tiun tinyint unsigned,iun int unsigned);
unsigned符号(-,+....)设置为无符号;
tinytint:如果输入的数有多大,只能存规定的数
int:int(11)这个11没啥用,显示作用!
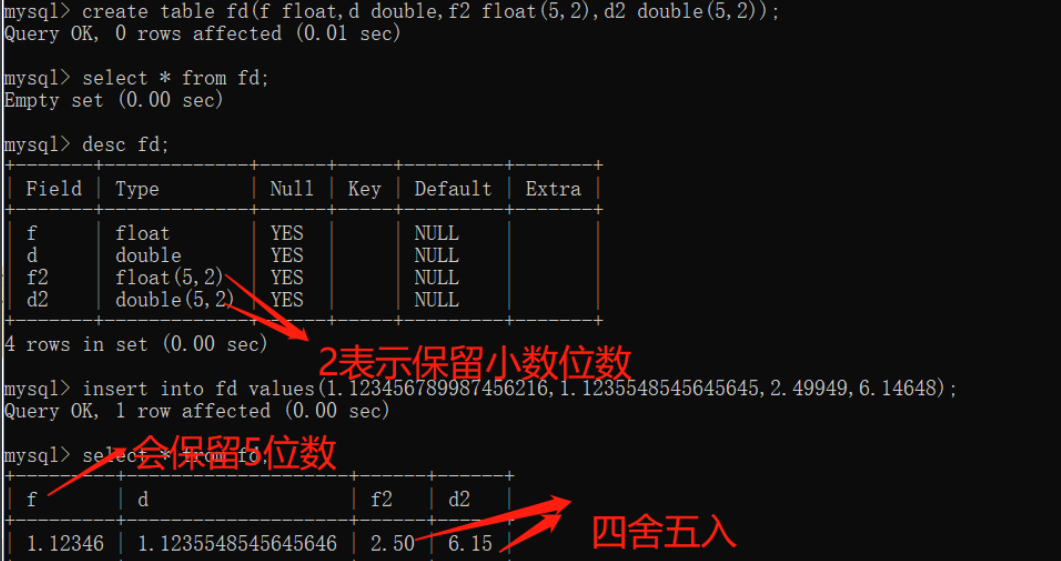
float(浮点) double(双精度)
float(5,2) double 5表示整数部分+小数部分 所以括号爱前面的数要比后面的数大
2.时间
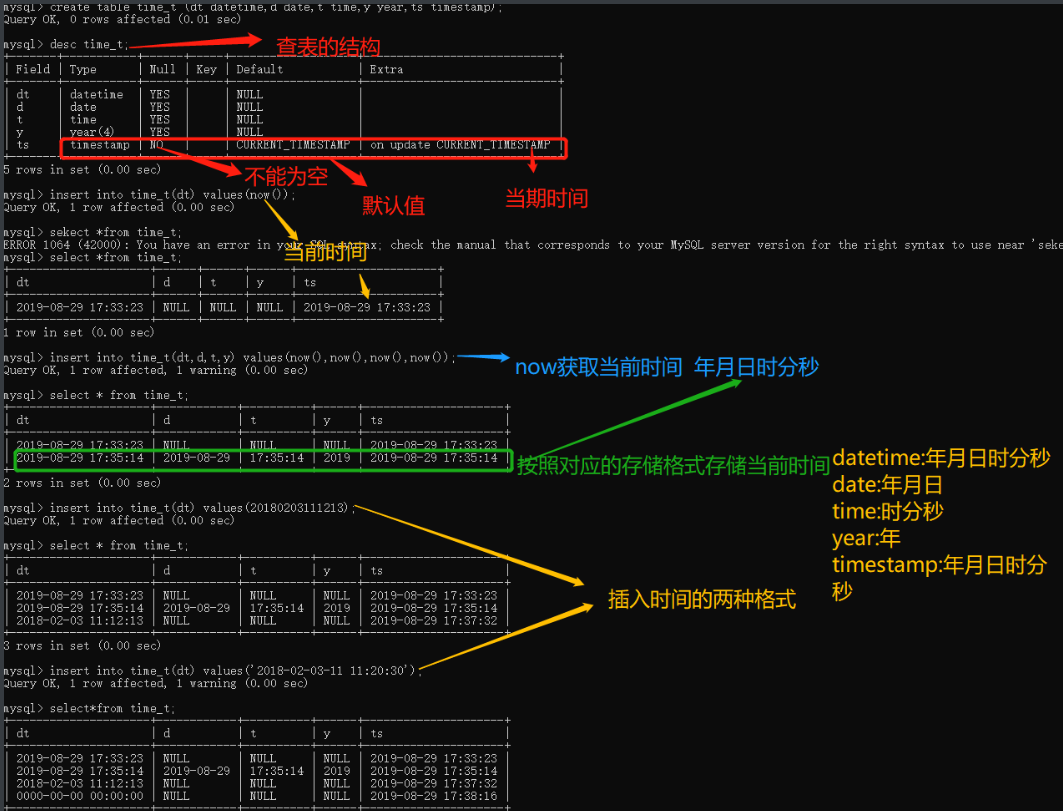
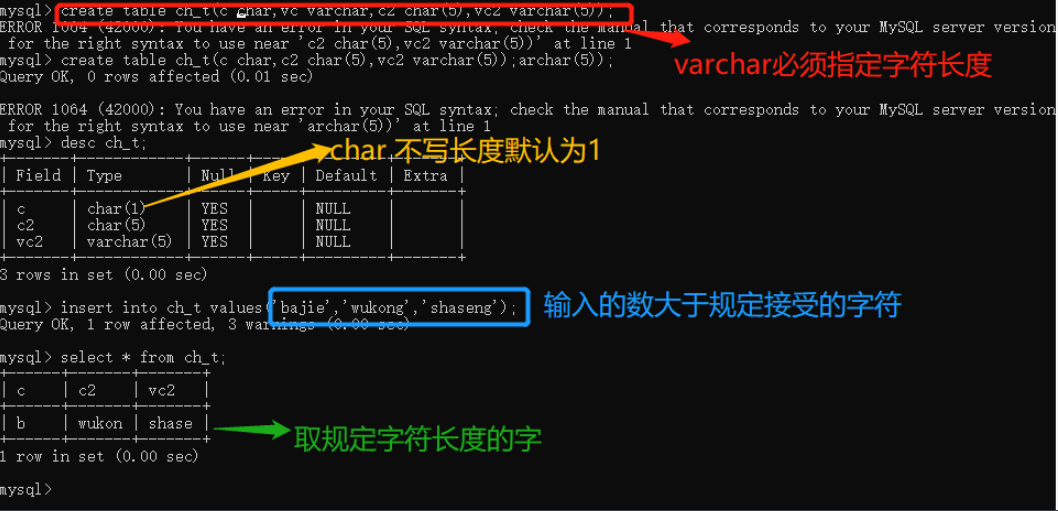
3.字符串
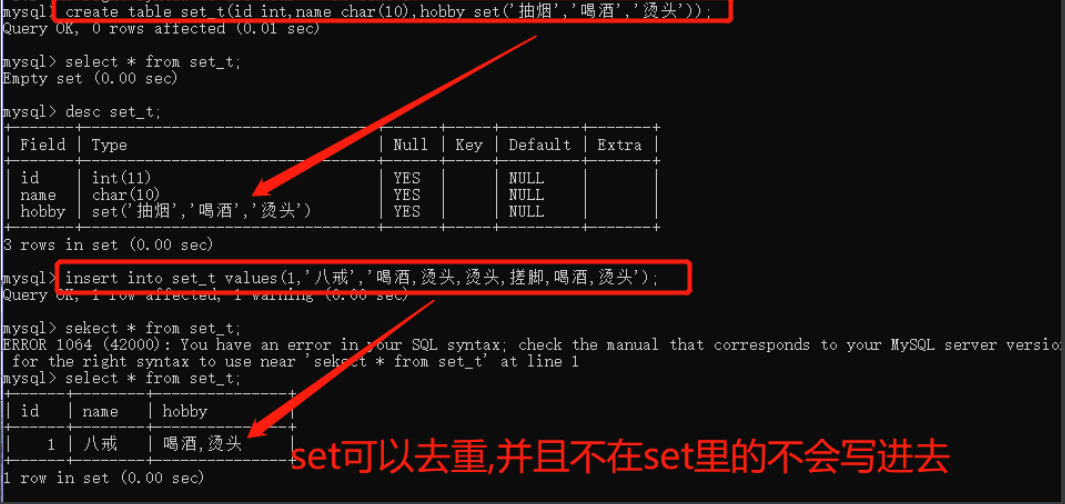
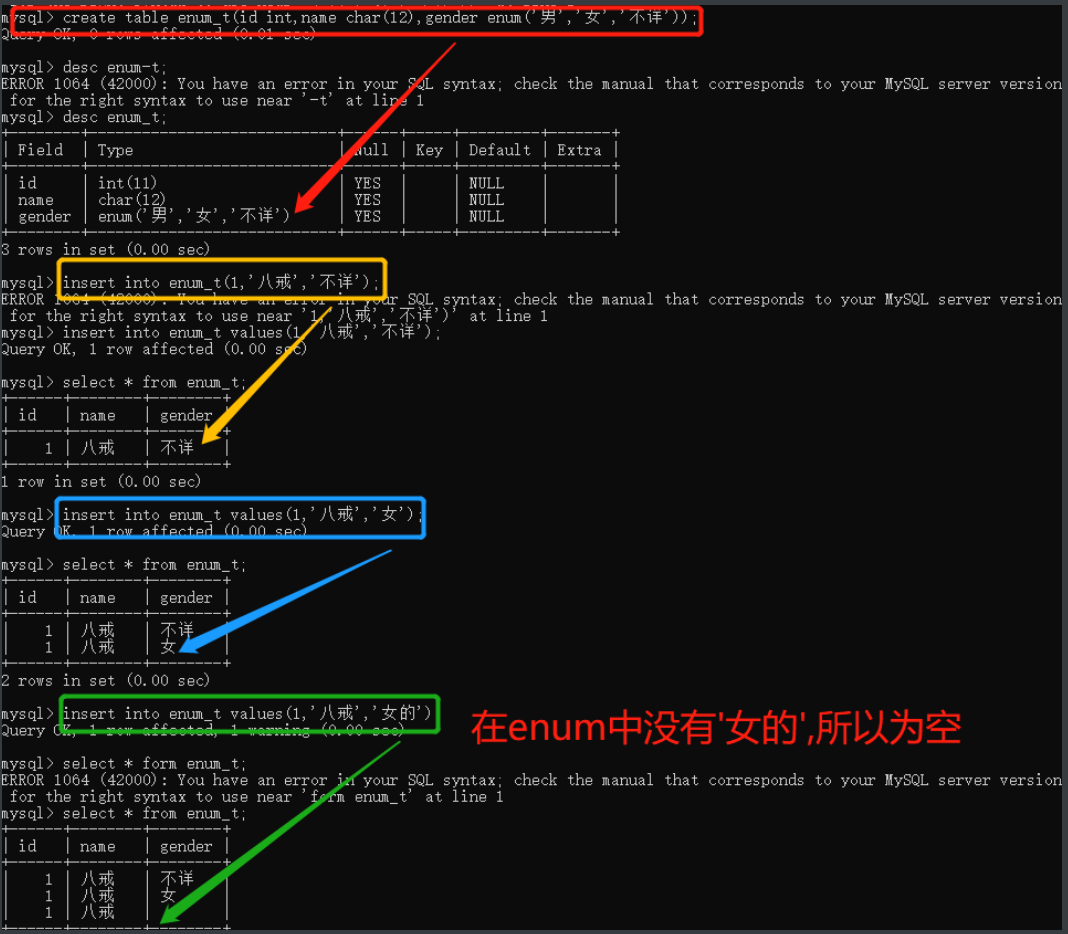
4.set 和 枚举
set
enum
表的完整性约束
一对多
举例:多个员工同属于一个部门,不同的书来自同一个出版社,部门和出版社代表 一,员工和书代表 多.以出版社和书为例,在建立表时,建立出版社和书两个表,这两个表没有任何联系,但想查出某本书来自哪个出版社,或者这个出版社出了哪几本书,就需要让这两个表产生联系.如何关联,即foreign key,添加外键(字段)
1.先创建'一'对应的出版社表.设置主键
2.创建'多'对应的表.添加外键
#创建出版社表,设置id为主键
mysql> create table press(id int primary key,name char(10),addr char(10));
mysql> desc press;
+-------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+----------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | char(10) | YES | | NULL | |
| addr | char(10) | YES | | NULL | |
+-------+----------+------+-----+---------+-------+
#在出版社添加数据
mysql> insert into press values(1,'xx出版社','沙河'),(2,'清华出版社','北京'),(3,'红浪漫出版社','伊拉克');
mysql> select * from press;
+----+--------------------+-----------+
| id | name | addr |
+----+--------------------+-----------+
| 1 | xx出版社 | 沙河 |
| 2 | 清华出版社 | 北京 |
| 3 | 红浪漫出版社 | 伊拉克 |
+----+--------------------+-----------+
#创建书的表
create table book(id int primary key,name char(10),price int,pid int,foreign key(pid) references press(id));
mysql> desc book;
+-------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+----------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | char(10) | YES | | NULL | |
| price | int(11) | YES | | NULL | |
| pid | int(11) | YES | MUL | NULL | |
+-------+----------+------+-----+---------+-------+
一对一
举例:一个学生想去学习,一开始只是学校的一个客户,考虑过后交了学费就成为了学校学生,客户表里存放了客户信息,学生表里存放了客户转换为学生的信息,一个客户信息只对应了一个学生信息,要建立关联,如果在客户表里面加外键关联学生表的话,那说明你的学生表必须先被创建出来,这样肯定是不对的,因为你的客户表先有的,才能转换为学生.所以在学生里添加关联
#创建客户表
create table customer(id int primary key,name char(10),qq char(18));
mysql> desc customer;
+-------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+----------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | char(10) | YES | | NULL | |
| qq | char(18) | YES | | NULL | |
+-------+----------+------+-----+---------+-------+
#客户表中添加信息
mysql> insert into customer values(1,'八戒','134782662'),(2,'悟空','7418525653'),(3,'唐僧','7414454845'),(4,'沙僧','1253862');
mysql> select * from customer;
+----+--------+------------+
| id | name | qq |
+----+--------+------------+
| 1 | 八戒 | 134782662 |
| 2 | 悟空 | 7418525653 |
| 3 | 唐僧 | 7414454845 |
| 4 | 沙僧 | 1253862 |
+----+--------+------------+
#创建学生表
mysql> create table student(id int primary key,name char(10),score int,cid int,foreign key(cid) references customer(id));
mysql> desc student;
+-------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+----------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | char(10) | YES | | NULL | |
| score | int(11) | YES | | NULL | |
| cid | int(11) | YES | MUL | NULL | |
+-------+----------+------+-----+---------+-------+
多对多
举例:出版社和书
站在不同的角度讲,一个出版社可以出版多本书,一本书可以来自多个出版社,不管站在谁的角度来讲,都是一对多的关系.不能给两个表都加上foreign key,两个表谁先创建?所以需要创建第三个表来建立两个表之间的联系.
#1.创建书籍表
mysql> create table newbook(id int primary key,name char(10),price int);
mysql> desc newbook;
+-------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+----------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | char(10) | YES | | NULL | |
| price | int(11) | YES | | NULL | |
+-------+----------+------+-----+---------+-------+
#2.添加信息
insert into newbook values(1,'九阴真经 ',100),(2,'python入门到放弃',50),(3,'西游记 ',20);
mysql> select * from newbook;
+----+------------+-------+
| id | name | price |
+----+------------+-------+
| 1 | 九阴真经 | 100 |
| 2 | python入门到放弃 | 50 |
| 3 | 西游记 | 20 |
+----+------------+-------+
#3.创建出版社表
mysql> create table newpress(id int primary key,name char(10),addr char(10));
mysql> desc newpress;
+-------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+----------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | char(10) | YES | | NULL | |
| addr | char(10) | YES | | NULL | |
+-------+----------+------+-----+---------+-------+
#4.添加信息
mysql> insert into press values(1,'xx出版社','沙河'),(2,'清华出版社','北京'),(3,'红浪漫出版社','伊拉克');
mysql> select* from newpress;
+----+--------------------+-----------+
| id | name | addr |
+----+--------------------+-----------+
| 1 | xx出版社 | 沙河 |
| 2 | 清华出版社 | 北京 |
| 3 | 红浪漫出版社 | 伊拉克 |
+----+--------------------+-----------+
#5.创建第三个表,建立联系
mysql> create table press_book(id int primary key,press_id int,book_id int,foreign key(press_id) references newpress(id),foreign key(book_id) references newbook(id));
mysql> desc press_book;
+----------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+---------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| press_id | int(11) | YES | MUL | NULL | |
| book_id | int(11) | YES | MUL | NULL | |
+----------+---------+------+-----+---------+-------+
单表查询
查询数据的本质:mysql会到你本地的硬盘上找到对应的文件,然后打开文件,按照你的查询条件来找出你需要的数据
-> ('唐僧','male',18,'20170301','形象大使',7300.33,401,1),
-> ('八戒','male',78,'20150302','teacher',1000000.31,401,1),
-> ('悟空','male',81,'20130305','teacher',8300,401,1),
-> ('小白','male',73,'20140701','teacher',3500,401,1),
-> ('莎莎','male',28,'20121101','teacher',2100,401,1),
-> ('成龙','male',48,'20101111','teacher',10000,401,1);
-> ('歪歪','female',48,'20150311','sale',3000.13,402,2),
-> ('丫丫','female',38,'20101101','sale',2000.35,402,2),
-> ('丁丁','female',18,'20110312','sale',1000.37,402,2),
-> ('星星','female',18,'20160513','sale',3000.29,402,2),
-> ('格格','female',28,'20170127','sale',4000.33,402,2),
-> ('张野','male',28,'20160311','operation',10000.13,403,3),
-> ('程咬金','male',18,'19970312','operation',20000,403,3),
-> ('程咬银','female',18,'20130311','operation',19000,403,3),
-> ('程咬铜','male',18,'20150411','operation',18000,403,3),
-> ('程咬铁','female',18,'20140512','operation',17000,403,3);
mysql> select * from employee;
+----+-----------+--------+-----+------------+--------------+--------------+------------+--------+-----------+
| id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id |
+----+-----------+--------+-----+------------+--------------+--------------+------------+--------+-----------+
| 1 | 唐僧 | male | 18 | 2017-03-01 | 形象大使 | NULL | 7300.33 | 401 | 1 |
| 2 | 八戒 | male | 78 | 2015-03-02 | teacher | NULL | 1000000.31 | 401 | 1 |
| 3 | 悟空 | male | 81 | 2013-03-05 | teacher | NULL | 8300.00 | 401 | 1 |
| 4 | 小白 | male | 73 | 2014-07-01 | teacher | NULL | 3500.00 | 401 | 1 |
| 5 | 莎莎 | male | 28 | 2012-11-01 | teacher | NULL | 2100.00 | 401 | 1 |
| 6 | 成龙 | male | 48 | 2010-11-11 | teacher | NULL | 10000.00 | 401 | 1 |
| 7 | 歪歪 | female | 48 | 2015-03-11 | sale | NULL | 3000.13 | 402 | 2 |
| 8 | 丫丫 | female | 38 | 2010-11-01 | sale | NULL | 2000.35 | 402 | 2 |
| 9 | 丁丁 | female | 18 | 2011-03-12 | sale | NULL | 1000.37 | 402 | 2 |
| 10 | 星星 | female | 18 | 2016-05-13 | sale | NULL | 3000.29 | 402 | 2 |
| 11 | 格格 | female | 28 | 2017-01-27 | sale | NULL | 4000.33 | 402 | 2 |
| 12 | 张野 | male | 28 | 2016-03-11 | operation | NULL | 10000.13 | 403 | 3 |
| 13 | 程咬金 | male | 18 | 1997-03-12 | operation | NULL | 20000.00 | 403 | 3 |
| 14 | 程咬银 | female | 18 | 2013-03-11 | operation | NULL | 19000.00 | 403 | 3 |
| 15 | 程咬铜 | male | 18 | 2015-04-11 | operation | NULL | 18000.00 | 403 | 3 |
| 16 | 程咬铁 | female | 18 | 2014-05-12 | operation | NULL | 17000.00 | 403 | 3 |
+----+-----------+--------+-----+------------+--------------+--------------+------------+--------+-----------+
select * from,这个select * 指的是要查询所有字段的数据
select distinct 字段1,字段2... from 库名.表名
#from后面是说从库的某个表中去找数据,mysql会去找到这个库对应的文件夹下去找到你表名对应的那个数据文件,找不到就直接报错了,找到了就继续后面的操作,可以在进入mysql时直接操作
mysql> insert into employee(name,sex,age,hire_date,post,salary,office,depart_id) values
1.查询职位,正常查询职位这个字段,会把整个字段内容打印出来,会有很多重复,重复内容是没用的,用distinct避免重复.
mysql> select distinct post from employee;
+--------------+
| post |
+--------------+
| 形象大使 |
| teacher |
| sale |
| operation |
+--------------+
mysql> select distinct post,salary from employee;
+--------------+------------+
| post | salary |
+--------------+------------+
| 形象大使 | 7300.33 |
| teacher | 1000000.31 |
| teacher | 8300.00 |
| teacher | 3500.00 |
| teacher | 2100.00 |
| teacher | 10000.00 |
| sale | 3000.13 |
| sale | 2000.35 |
| sale | 1000.37 |
| sale | 3000.29 |
| sale | 4000.33 |
| operation | 10000.13 |
| operation | 20000.00 |
| operation | 19000.00 |
| operation | 18000.00 |
| operation | 17000.00 |
+--------------+------------+
select distinct post,salary from employee; 这样写并没有达到避免重复的效果,因为你的去重条件变成了post和salary两个字段的数据,只有他俩合起来是一个重复记录的时候才会去重
通过四则运算查询
查询每个人的姓名及对应年薪,employee没有年薪,只有月薪,可以用月薪*12计算年薪.
mysql> select name,salary*12 from employee;
+-----------+-------------+
| name | salary*12 |
+-----------+-------------+
| 唐僧 | 87603.96 |
| 八戒 | 12000003.72 |
| 悟空 | 99600.00 |
| 小白 | 42000.00 |
| 莎莎 | 25200.00 |
| 成龙 | 120000.00 |
| 歪歪 | 36001.56 |
| 丫丫 | 24004.20 |
| 丁丁 | 12004.44 |
| 星星 | 36003.48 |
| 格格 | 48003.96 |
| 张野 | 120001.56 |
| 程咬金 | 240000.00 |
| 程咬银 | 228000.00 |
| 程咬铜 | 216000.00 |
| 程咬铁 | 204000.00 |
+-----------+-------------+
年薪的字段变成了salary*12,肯定不是想要的结果.是因为我们通过查询语句查询出来的也是一张表,但是这个表是不是内存当中的一个虚拟表,并不是我们硬盘中存的那个完整的表,对吧,虚拟表是不是也有标题和记录啊,既然是一个表,我们是可以指定这个虚拟表的标题的,通过as+新字段名来指定
mysql> select name,salary*12 as '年薪' from employee;
+-----------+-------------+
| name | 年薪 |
+-----------+-------------+
| 唐僧 | 87603.96 |
| 八戒 | 12000003.72 |
| 悟空 | 99600.00 |
| 小白 | 42000.00 |
| 莎莎 | 25200.00 |
| 成龙 | 120000.00 |
| 歪歪 | 36001.56 |
| 丫丫 | 24004.20 |
| 丁丁 | 12004.44 |
| 星星 | 36003.48 |
| 格格 | 48003.96 |
| 张野 | 120001.56 |
| 程咬金 | 240000.00 |
| 程咬银 | 228000.00 |
| 程咬铜 | 216000.00 |
| 程咬铁 | 204000.00 |
+-----------+-------------+
#自定义显示格式,自己规定查询结果的显示格式
mysql> select concat('姓名:',name, ' 年薪:',salary*12) as '薪资表' from employee;
+------------------------------------+
| 薪资表 |
+------------------------------------+
| 姓名:唐僧 年薪:87603.96 |
| 姓名:八戒 年薪:12000003.72 |
| 姓名:悟空 年薪:99600.00 |
| 姓名:小白 年薪:42000.00 |
| 姓名:莎莎 年薪:25200.00 |
| 姓名:成龙 年薪:120000.00 |
| 姓名:歪歪 年薪:36001.56 |
| 姓名:丫丫 年薪:24004.20 |
| 姓名:丁丁 年薪:12004.44 |
| 姓名:星星 年薪:36003.48 |
| 姓名:格格 年薪:48003.96 |
| 姓名:张野 年薪:120001.56 |
| 姓名:程咬金 年薪:240000.00 |
| 姓名:程咬银 年薪:228000.00 |
| 姓名:程咬铜 年薪:216000.00 |
| 姓名:程咬铁 年薪:204000.00 |
+------------------------------------+
concat()函数用于连接字符串
SELECT CONCAT('姓名: ',name,' 年薪: ', salary*12) AS Annual_salary,CONCAT('性别:',sex) from employee;也可以分两列
可以通过concat...cash结合用对查询的结果进行操作
mysql> select(
-> case
-> when name = '唐僧' then name
-> when name = '八戒' then concat(name,'dsb')
-> else concat(name,'sb')
-> end) as new_name,sex from employee;
+-------------+--------+
| new_name | sex |
+-------------+--------+
| 唐僧 | male |
| 八戒dsb | male |
| 悟空sb | male |
| 小白sb | male |
| 莎莎sb | male |
| 歪歪sb | female |
| 丫丫sb | female |
| 丁丁sb | female |
| 星星sb | female |
| 格格sb | female |
| 张野sb | male |
| 程咬金sb | male |
| 程咬银sb | female |
| 程咬铜sb | male |
| 程咬铁sb | female |
+-------------+--------
select concat('<姓名:',name,'>' ' <年薪:',salary,'>') as '薪资表' from employee;
where约束
1. 比较运算符:> < >= <= <> !=
2. between 80 and 100 值在80到100之间
3. in(80,90,100) 值是80或90或100
4. like 'egon%'
pattern可以是%或_,
%表示任意多字符
_表示一个字符
5. 逻辑运算符:在多个条件直接可以使用逻辑运算符 and or not
#单条件查询
mysql> select name from employee where post = 'sale';
+--------+
| name |
+--------+
| 歪歪 |
| 丫丫 |
| 丁丁 |
| 星星 |
| 格格 |
+--------+
where 的优先级大于select
根据优先级,先查post='sale'的条件,再查对应的name
#多条件查询
mysql> select name,salary from employee where post = 'teacher' and salary > 1000;
+--------+------------+
| name | salary |
+--------+------------+
| 八戒 | 1000000.31 |
| 悟空 | 8300.00 |
| 小白 | 3500.00 |
| 莎莎 | 2100.00 |
+--------+------------+
查找post>1000,职位是老师的数据,用and连接
#关键字BETWEEN AND 写的是一个区间
mysql> select name,salary from employee where post = 'teacher' and salary between 1000 and 5000;
+--------+---------+
| name | salary |
+--------+---------+
| 小白 | 3500.00 |
| 莎莎 | 2100.00 |
查找5000>post>1000,职位是老师的数据,用and连接
#关键字IS NULL(判断某个字段是否为NULL不能用等号,需要用IS) 判断null只能用is
mysql> select name,post_comment from employee where post_comment is null;
+-----------+--------------+
| name | post_comment |
+-----------+--------------+
| 唐僧 | NULL |
| 八戒 | NULL |
| 悟空 | NULL |
| 小白 | NULL |
| 莎莎 | NULL |
| 歪歪 | NULL |
| 丫丫 | NULL |
| 丁丁 | NULL |
| 星星 | NULL |
| 格格 | NULL |
| 张野 | NULL |
| 程咬金 | NULL |
| 程咬银 | NULL |
| 程咬铜 | NULL |
| 程咬铁 | NULL |
+-----------+--------------+
#关键字IN集合查询
mysql> select name,salary from employee where salary in (3000,3500,4000,9000);
+--------+---------+
| name | salary |
+--------+---------+
| 小白 | 3500.00 |
+--------+---------+
#关键字LIKE模糊查询,模糊匹配,可以结合通配符来使用
mysql> select * from employee where name like '程咬%';
+----+-----------+--------+-----+------------+-----------+--------------+----------+--------+-----------+
| id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id |
+----+-----------+--------+-----+------------+-----------+--------------+----------+--------+-----------+
| 13 | 程咬金 | male | 18 | 1997-03-12 | operation | NULL | 20000.00 | 403 | 3 |
| 14 | 程咬银 | female | 18 | 2013-03-11 | operation | NULL | 19000.00 | 403 | 3 |
| 15 | 程咬铜 | male | 18 | 2015-04-11 | operation | NULL | 18000.00 | 403 | 3 |
| 16 | 程咬铁 | female | 18 | 2014-05-12 | operation | NULL | 17000.00 | 403 | 3 |
+----+-----------+--------+-----+------------+-----------+--------------+----------+--------+-----------+

