
软件工程第一次作业
 软件工程第一次作业
软件工程第一次作业要求0:作业要求博客地址:
https://edu.cnblogs.com/campus/nenu/2016CS/homework/2110
要求1:git仓库地址:
https://git.coding.net/tangjh563/wf.git
要求2:
1. PSP阶段表格
| SP2.1 | 任务内容 | 计划需要时间(min) | 实际完成时间(min) |
| Planning | 计划 | 50 | 40 |
| Estimate | 估计开发所需要的时间,需要的工作步骤,需要的思路和方法 | 50 | 40 |
| Development | 开发 | 800 | 1000 |
| Analysis | 需求分析(软件,语言工具等) | 150 | 200 |
| Design Spec | 生成设计文档 | 20 | 40 |
| Design Reviewe | 设计复审(和同事审核设计文档) | 10 | 10 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 20 | 50 |
| Desgin | 具体设计 | 200 | 250 |
| Desgin | 具体编码 | 200 | 250 |
| Code Review | 代码复审 | 50 | 50 |
| Test | 测试(自我测试,修改代码,提交修改) | 150 | 150 |
| Record Time Spent | 记录用时 | 120 | 150 |
| Test Report | 测试报告 | 20 | 30 |
| Size Measurement | 计算工作量 | 20 | 40 |
| Postmortem & Process Improvement Plan | 事后总结和提出过程改进计划 | 80 | 80 |
| 功能模块 | 具体阶段 | 预计时间 (min) | 实际时间 (min) |
| 功能1 | 具体设计 | 40 | 50 |
| 具体编码 | 120 | 150 | |
| 测试完善 | 40 | 50 | |
| 功能2 | 具体设计 | 40 | 50 |
| 具体编码 | 110 | 150 | |
| 测试完善 | 50 | 50 | |
| 功能3 | 具体设计 | 30 | 40 |
| 具体编码 | 140 | 120 | |
| 测试完善 | 30 | 40 |
2. 预估耗时与实际耗时的差距原因:
1、不够熟练C语言,C++,还需要查书,百度来帮助写代码,需要加强训练。
2、每天都凑空出来写,不是每次都直接进入工作状态,外界有干扰,自己注意力还是不够集中,要改正。
3代码敲的不够熟练,与想象中有差距,要加强。
要求3:
1. 解题思路描述:
首先拿到题以后先看样例和要求要我做什么,第一个是单词计数,先找到特殊的点,不重复计数,大小写不区分都是同一个单词,不能用数值开头,在心中想好判定的if语句。
然后想函数框架,设计一个主函数,其下用一个统计函数来计算字符串,一个输出函数,输出函数中想好怎么读取路径,路径转换。
2.代码展示和中间的困难:
遇到很多麻烦,其中单词分割,我采用了string的方法来解决,尴尬的是我还不小心忘记了大小写,希望以后能更注意。
代码展示:
我的代码还有个经典就是加空格来分割首尾的两个单词
void Read_Txt(string filename) { ifstream file; file.open(filename.c_str());//类型转化 string s; while(getline(file, s)) { zfc = s + ' ' + zfc;//特别强调用空格分割首尾单词 } transform(zfc.begin() , zfc.end() , zfc.begin() , ::tolower);//大小写转化 file.close(); }/*读取文件的功能*/
然后用getchar();来防止回车吞字符的影响:
getchar();/*防止回车的影响*/
其中我遇到几个问题:
第一就是怎么读取路径。我就上网寻求帮助。来源:https://blog.csdn.net/hjl240/article/details/47132477
#include <stdio.h> int main() { //下面是写数据,将数字0~9写入到data.txt文件中 FILE *fpWrite=fopen("data.txt","w"); if(fpWrite==NULL) { return 0; } for(int i=0;i<10;i++) fprintf(fpWrite,"%d ",i); fclose(fpWrite); //下面是读数据,将读到的数据存到数组a[10]中,并且打印到控制台上 int a[10]={0}; FILE *fpRead=fopen("data.txt","r"); if(fpRead==NULL) { return 0; } for(int i=0;i<10;i++) { fscanf(fpRead,"%d ",&a[i]); printf("%d ",a[i]); } getchar();//等待 return 1; }
第二就是我不知道用那种方法来存储方便,怎么排序方便,然后我在一个博客中看到vector、map、、hash_map三种方式的比较。来源:https://blog.csdn.net/i_chaoren/article/details/78673641
//WordFrequency.cpp #include "WordFrequency.h" #include "StringUtil.h" #include <algorithm> #include <stdexcept> #include <stdlib.h> #include <fstream> using namespace std; using namespace stringutil; WordFrequency::WordFrequency(const std::string &filename, const std::string &stopFile) :filename_(filename),stopFile_(stopFile) { } void WordFrequency::ReadStopFile() { ifstream in(stopFile_.c_str()); if( !in ) throw runtime_error("open file failure"); string word; while(in >> word) { stopList_.push_back(word); } in.close(); } void WordFrequency::ReadWordFile() { ifstream infile(filename_.c_str()); if( !infile ) throw runtime_error("open file failure!"); string word; while(infile >> word) { erasePunct(word); if( isAllDigit(word)) continue; stringToLower(word); if( !isStopWord(word)) addWordToDict(word); } infile.close(); } bool WordFrequency::isStopWord(const string &word)const { vector<string>::const_iterator it = stopList_.begin(); while( it != stopList_.end()) { if( *it == word) break; it ++; } return (it != stopList_.end()); } void WordFrequency::addWordToDict(const string &word) { Wordit it = words_.begin(); while( it != words_.end()) { if( it->first == word) { ++ it->second ; break; } it ++; } if(it == words_.end()) words_.push_back(make_pair(word, 1)) ; } bool cmp(const pair<string, int> &a, const pair<string, int>&b) { return a.second > b.second; } void WordFrequency::sortWordByFrequency() { sort(words_.begin(), words_.end(), cmp); } void WordFrequency::printWordFrequency()const { Wordkit it = words_.begin(); while(it != words_.end()) { printf("words: %s, frequency: %d\n",it->first.c_str(),it->second); it ++; } }
//WordFrequency.cpp #include "WordFrequency.h" #include "StringUtil.h" #include <fstream> #include <algorithm> #include <stdio.h> #include <stdexcept> using namespace std; using namespace stringutil; WordFrequency::WordFrequency(const string &filename, const string &stopfile) :filename_(filename),stopfile_(stopfile) { } void WordFrequency::ReadStopFile() { ifstream infile(stopfile_.c_str()); if( !infile ) throw runtime_error("open file failure"); string word; while(infile >> word) StopList_.insert(word); infile.close(); } void WordFrequency::ReadWordFile() { ifstream infile(filename_.c_str()); if( !infile ) throw runtime_error("open file failure"); words_.clear(); string word; while(infile >> word) //读取单词 { erasePunct(word); //去除标点 stringToLower(word);//转为小写 if(isAllDigit(word))//去除数字 continue; if( StopList_.count(word) == 0) //set中 count 标识 word这个单词是否存在 words_[word]++; //如果存在,int++, 如果不存在,增添至 map中 //words_[word]= cnt(词频数) } infile.close(); } void WordFrequency::copyWordToVector() { copyWords_.clear(); //back_inserter(copyWords_) //front_inserter copy(words_.begin(),words_.end(),back_inserter(copyWords_)); } bool cmp(const pair<string, int> &a, const pair<string, int> &b) { return a.second > b.second; } void WordFrequency::sortWordByFrequency() { sort(copyWords_.begin(), copyWords_.end(),cmp); //排序 } void WordFrequency::printFrequency() const { for(vector<pair<string, int> >::const_iterator it = copyWords_.begin(); it != copyWords_.end(); ++it) { printf("word :%s, frequency: %d\n", it->first.c_str(), it->second); //打印 } }
//WordFrequency.h #ifndef WORDFREQUENCY_H_ #define WORDFREQUENCY_H_ #include <vector> #include <unordered_map> #include <unordered_set> #include <string> class WordFrequency { public: WordFrequency(const std::string &filename, const std::string &stopfile); void ReadStopFile(); void ReadWordFile(); void copyWordToVector(); void sortWordByFrequency(); void printFrequency()const; private: std::string filename_; std::string stopfile_; std::unordered_set<std::string> StopList_; std::unordered_map<std::string, int> words_; std::vector< std::pair<std::string,int> > copyWords_; }; #endif
通过研究这三种算法,我决定用我更能理解的map方法来完成。
测试结果:
功能1:
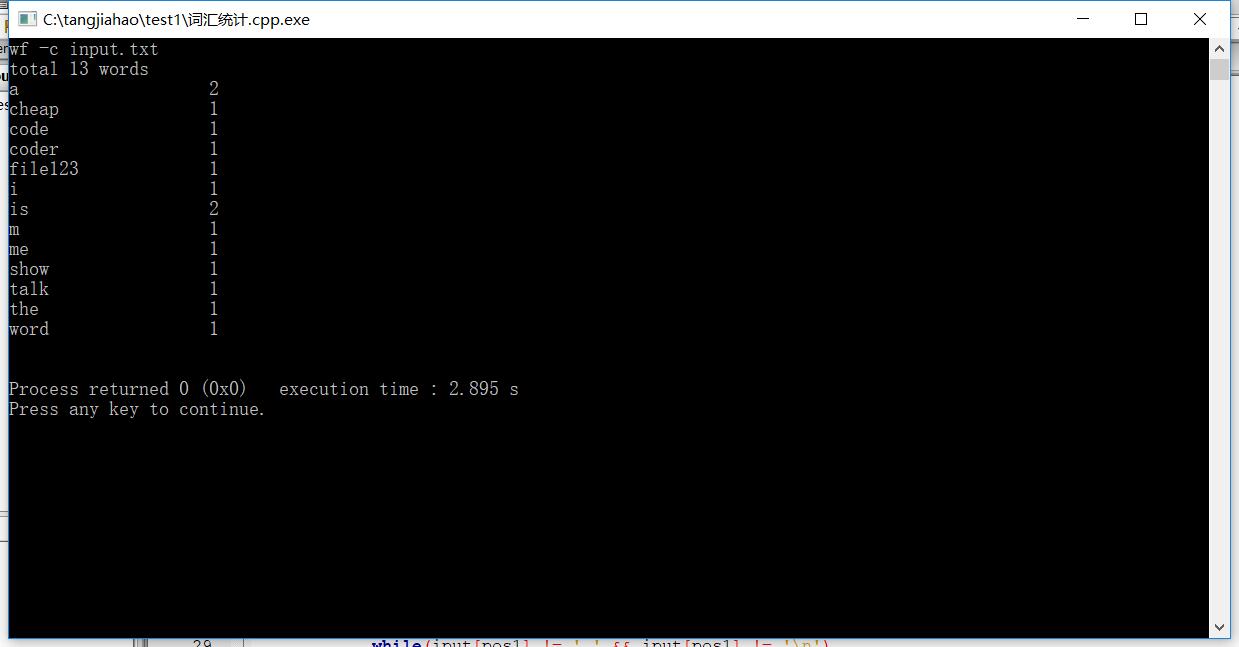
功能2:

功能3:

3总结:
我觉得以后完成项目不仅仅要合理安排好时间,学会管理时间,学会管理自我,也要学会网上寻求帮助,认真研究资料书籍等,这样才能更好学习中成长,成长中学习。
在代码中也学会规范代码,让自己以后更加严谨,代码风格更加让人眼前一亮,让人更愉快。
自从看了我博客里面写的别人用三种方法的比较,然后我发现自己的思路想法也太简单了,希望以后能更有远见和想法,加油!

