ElasticSearch的基础概念介绍
1、ElasticSearch简介
1.1、简介
Elasticsearch(简称ES)是一个基于Apache Lucene构建的开源、分布式、RESTful接口的全文搜索引擎,Elasticsearch通过对Lunece的封装,隐藏了复杂性,提供了使用简单的RESTful Api。Elasticsearch还是一个分布式文档数据库,其中每个字段均可被索引,而且每个字段的数据均可被搜索,因为对文档进行了分词处理。ES能够横向扩展至数以百计的服务器存储以及处理PB级的数据,可以在极短的时间内存储、搜索和分析大量的数据。Elasticsearch 是用 Java 开发的,并作为 Apache 许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
Tip: ElasticSearch 底层的全文检索是基于 Lucene 实现的。
1.2、为什么要使用它
在业务开发中,基于ES的特性,通常有下面这些场景需要使用它:
- 存储大量数据。通过在使用mysql存储的时候,数据的单位是
G。使用ES的时候,数据的单位是T。由此可以看出ES使用于大数据量的存储场景,基于分布式特性,它也支持备份和容灾,并且可以很容易水平扩展容量。 - 分词搜索引擎。ES具有强大的分词能力,可以支持高性能的实时搜索。
- 高效数据分析。ES提供的聚合分析功能,可实现对保存的大量数据的近实时统计分析。
1.3、特性
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 分布式的实时分析搜索引擎
- 可以扩展到成百上千台服务器,处理PB级结构化或非结构化数据。
1.4、使用场景
- 搜索领域: 如百度、谷歌,全文检索等。
- 门户网站: 访问统计、文章点赞、留言评论等。
- 广告推广: 记录员工行为数据、消费趋势、员工群体进行定制推广等。
- 信息采集: 记录应用的埋点数据、访问日志数据等,方便大数据进行分析。
1.5、ElasticSearch与Solr的比较
- ES和Solr都是是基于Lucene的,它们都是成熟的产品,拥有强大而广泛的用户社区;
- Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;
- Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式;
- Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供;
- Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch
2、ElasticSearch的基本概念
ES 和传统的关系型数据库有这么一种关系👇:
| RDMS | Elasticsearch |
|---|---|
| 数据库(database) | 索引(index) |
| 表(table) | 类型(type) |
| 行(row) | 文档(document) |
| 列(column) | 字段(field) |
| 表结构 | 映射 |
| 索引 | 全文索引 |
| SQL | 查询DSL |
| SELECT * FROM tablename | GET http://... |
| UPDATE table SET | PUT http://... |
| DELETE | DELETE http://... |
先说Elasticsearch的文件存储,Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面这条用户数据:
{
"name": "John",
"sex": "Male",
"age": 25,
"birthDate": "1990/05/01",
"about": "I love to go rock climbing",
"interests": ["sports","music"]
}
2.1、索引index
类似于MySQL数据库中的数据库概念,索引是 Elasticsearch 对逻辑数据的逻辑存储,所以它可以分为更小的部分,索引的结构是为快速有效的全文索引准备的,特别是它不存储原始值。Elasticsearch 可以把索引存放在一台机器或者分散在多台服务器上,每个索引由一或多个分片(shard),分布在不同的 node,每个分片可以有多个副本(replica)。Elasticsearch的索引原理是通过倒排索引来实现的。

2.2、类型type
这里指的是文档的类型,而不是字段的类型。type类似于MySQL数据库中 表 的概念。而ES中没有表的概念,这是ES和数据库的一个区别。在6.0版本之前,ES中有Type的概念,但是后来官方说这是一个设计上的失误。所以这个 type 从 7.x 开始就被移除了!系统默认使用_doc(现在8.x 版本就也不再支持修改这个类型了), 因为这个设计会降低 Lucene 压缩数据的能力,导致数据稀疏。我们都知道elasticsearch是基于Lucene开发的搜索引擎,而ES中不同type下名称相同的filed最终在Lucene中的处理方式是一样的。举个例子,两个不同type下的两个user_name,在ES同一个索引下其实被认为是同一个filed,你必须在两个不同的type中定义相同的filed映射。否则,不同type中的相同字段名称就会在处理中出现冲突的情况,导致Lucene处理效率下降。从本质上来看,这个 Type是对索引进行逻辑分区,使用文档类型_type 和文档_id 组成_uid ,形成文档的唯一ID,对索引进行细分。而在 Lucene 中,我们这个字段域在索引中是唯一的,所以原本的字段也会被细分,导致字段域增多的同时,数据的密度也就降低了,压缩效率也就降低了,导致ES查询效率的降低。
5.0 开始,强制跨单个类型共享同一名称的字段具有兼容的映射
6.0 开始,禁止新索引具有多个类型,并弃用了 _default_映射
7.0 开始,弃用了类型的API,引入了新的无类型(_doc)的API,并且移除了 _default_映射的支持
8.0开始,将移除接受类型的API
移除 Type 的具体原因可以看官网的解释 :Removal of mapping types | Elasticsearch Guide [7.17]
2.3、文档document
文档在ES中相当于传统数据库中的行的概念,即每一行的数据,ES中的数据都以JSON的形式来表示,在MySQL中插入一行数据和ES中插入一个JSON文档是一个意思。文档是Elasticsearch中的最小单位,每个索引都是有数量众多的文档组成的。文档由多个字段组成,每个字段的类型由mapping定义,每个字段的类型,可以是文本、数值、日期等。字段类型也可以是复杂类型,一个字段包含其他子文档或者数组,但 Elasticsearch 的文档中,相同字段必须有相同类型。下面的JSON数据表示一个包含7个字段的文档。
{
"_index": "user",
"_type": "_doc",
"_id": "qbuOs4AB1VH6WaY_OsFW",
"_version": 1,
"_score": 1,
"_source": {
"name": "张三",
"address": "广东省深圳市",
"remark": "他是一个程序员",
"age": 28,
"salary": 8800,
"birthDate": "1991-10-05",
"createTime": "2019-07-22T13:22:00.000Z"
}
}
上图为 ES 一条文档数据,而一个文档不只有基础数据,它还包含了元数据(metadata)——关于文档的信息,也就是用下划线开头的字段,它是官方提供的字段:
- _index :文档所属索引名称,即文档存储的地方。
- _type :文档所属类型名(此处已默认为_doc)。
- _id :文档的唯一标识。在写入的时候,可以指定该 Doc 的 ID 值,如果不指定,则系统自动生成一个唯一的 UUID 值。
- _score :顾名思义,得分,也可称之为相关性,在查询是 ES 会 根据一些规则计算得分,并根据得分进行倒排。除此之外,ES 支持通过 Function score query 在查询时自定义 score 的计算规则。
- _source :文档的原始 JSON 数据。
2.4、字段Field
相当于是数据表的字段,字段在ES中可以理解为JSON数据的键,是文档中的基本单位,以键值对的形式存在。在下面的JSON数据中,键都是一个字段。
{
"name": "张三",
"address": "广东省深圳市",
"remark": "他是一个程序员",
"age": 28,
"salary": 8800,
"birthDate": "1991-10-05",
"createTime": "2019-07-22T13:22:00.000Z"
}
2.5、映射mapping
相当于数据库中的schema,用来约束字段的数据类型,每一种数据类型都有对应的使用场景。mapping 中定义了一个文档所包含的所有 field 信息,每个文档都有映射,但是在大多数使用场景中,我们并不需要显示的创建映射,因为ES中实现了动态映射。我们在索引中写入一个下面的JSON文档:
{
"name":"jack",
"age":18,
"birthDate": "1991-10-05"
}
在动态映射的作用下,name会映射成text类型,age会映射成long类型,birthDate会被映射为date类型,映射的索引信息如下。
{
"mappings": {
"_doc": {
"properties": {
"age": {
"type": "long"
},
"birthDate": {
"type": "date"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}
自动判断的规则如下:
| JSON Type | Field Type |
|---|---|
| Boolean:true、flase | boolean |
| Whole number:123、456、876 | long |
| Floating point:123.43、234.534 | double |
| String,valid date:"2022-05-15" | date |
| String:"Hello Elasticsearch" | string |
常见的ELasticSearch数据类型如下:
| 数据类型 | 具体类型 |
|---|---|
| 字符串类型 | string,text,keyword |
| 整数类型 | integer,long,short,byte |
| 浮点类型 | double,float,half_float,scaled_float |
| 逻辑类型 | boolean |
| 日期类型 | date |
| 范围类型 | range |
| 二进制类型 | binary |
| 数组类型 | array |
| 对象类型 | object |
| 嵌套类型 | nested |
| 地理坐标类型 | geo_point |
| 地理地图 | geo_shape |
| IP类型 | ip |
| 令牌计数类型 | token_count |
注意事项关于字符串类型:
- string类型: 在ElasticSearch 旧版本中使用较多,从ElasticSearch 5.x开始不再支持string,由text和keyword类型替代。
- text类型的字段不用于排序,很少用于聚合,需要分词设置text类型
- keyword类型适用于索引结构化的字段,keyword类型的字段只能通过精确值搜索到。不需要分词设置keyword类型
补充:对text类型的字段,会先使用分词器分词,生成倒排索引,用于之后的搜索。对keyword类型的字段,不会分词,搜索时只能精确查找
2.6、集群Cluster
ElasticSearch 是一个分布式的搜索引擎,所以一般由多台物理机组成。而在这些机器上通过配置一个相同的cluster name,让其互相发现从而把自己组织成一个集群。
2.7、节点Node
ElasticSearch 是以集群的方式运行的,而节点是组成ES集群的基本单位,所以每个 ElasticSearch 实例就是一个节点,每个物理机器上可以有多个节点,使用不同的端口和节点名称。
节点按主要功能可以分为三种:主节点(Master Node),协调节点(Coordianting Node)和数据节点(Data Node)。下面简单介绍下:
- 主节点:处理创建,删除索引等请求,维护集群状态信息。可以设置一个节点不承担主节点角色
- 协调节点:负责处理请求。默认情况下,每个节点都可以是协调节点。
- 数据节点:用来保存数据。可以设置一个节点不承担数据节点角色
2.8、分片
为了将数据添加到 Elasticsearch,我们需要索引(index)——一个存储关联数据的地方。实际上,索引只是一个用来指向一个或多个分片(shards)的 逻辑命名空间 (logical namespace).
分片分为:主分片(Primary shard)和副本分片(Replica shard):
- 主分片Primary shard:用于解决数据水平扩展的问题,通过主分片,可以将数据分布到集群内的所有节点之上,将一份索引数据划分为多小份的能力,允许水平分割和扩展容量。多个分片可以响应请求,提高性能和吞吐量。一个节点(Node)一般会管理多个分片,分片有两种,主分片和副本分片。
- 副本分片Replica shard:副本分片只是一个主分片的拷贝。 副本分片作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服务。
- 一个Index数据在物理上被分布在多个主分片中,每个主分片只存放部分数据,每个主分片可以有多个副本。
- 主分片的作用是对索引的扩容,使一个索引的容量可以突破单机的限制。
- 副本分片是对数据的保护,每个主分片对应一个或多个副本分片,当主分片所在节点宕机时,副本分片会被提升为对应的主分片使用。
- 一个主分片和它的副本分片,不会分配到同一个节点上。
- 一个分片就是一个Lucene实例,并且它本身就是一个完整的搜索引擎。应用程序不会和它直接通信。
- 当索引创建完成的时候,主分片的数量就固定了,如果要修改需要重建索引,代价很高,如果要修改则需Reindex,但是复制分片的数量可以随时调整。
文档路由到对应的分片的公式如下 👇
shard = hash(routing) % number_of_primary_shards
分片的设定:
- 对于生产环境中分片的设定,需要提前做好容量规划,主分片数是在索引创建的时候预先设定,事后无法修改
- 分片数设置过小
- 导致后续无法增加节点实现水平扩展
- 单个分片的数据量太大,导致数据重新分配耗时
- 分片数设置过大,7.0开始,默认主分片设置成1,解决了over-sharding的问题
- 影响搜索结果的相关性打分,影响统计结果的准确性
- 单个节点上过多的分片,会导致资源浪费,同时也会影响性能
- 分片数设置过小
用图形表示出来可能是这样子的:
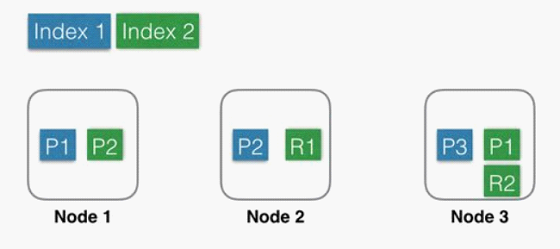
- Index 1:蓝色部分,有3个shard,分别是P1,P2,P3,位于3个不同的Node中,这里没有Replica。
- Index 2:绿色部分,有2个shard,分别是P1,P2,位于2个不同的Node中。并且每个shard有一个replica,分别是R1和R2。基于系统可用性的考虑,同一个shard的primary和replica不能位于同一个Node中。这里Shard1的P1和R1分别位于Node3和Node2中,如果某一刻Node2发生宕机,服务基本不会受影响,因为还有一个P1和R2都还是可用的。因为是主备架构,当主分片发生故障时,需要切换,这时候需要选举一个副本作为新主,这里除了会耗费一点点时间外,也会有丢失数据的风险。
3、ElasticSearch中索引原理
我们知道ES的搜索是非常快的,并且比MySQL快很多,所以来看下两者的索引原理:
- MySQL的索引原理:B+Tree索引
- ElasticSearch的索引原理:倒排索引
倒排索引:也叫反向索引,首先对文档数据按照id进行索引存储,然后对文档中的数据分词,记录对词条进行索引,并记录词条在文档中出现的位置。这样查找时只要找到了词条,就找到了对应的文档。概括来讲是先找到词条,然后看看哪些文档包含这些词条。通俗地来讲,正向索引是通过key找value,倒排索引则是通过value找key。跟MySQL中的索引回表查询有点类似。
下面倒排索引简单实例
假设我们有如下几篇文档:
- Doc1:乔布斯去了中国。
- Doc2:苹果今年仍能占据大多数触摸屏产能。
- Doc3:苹果公司首席执行官史蒂夫·乔布斯宣布,iPad2将于3月11日在美国上市。
- Doc4:乔布斯推动了世界,iPhone、iPad、iPad2,一款一款接连不断。
- Doc5:乔布斯吃了一个苹果。
这五个文档中的数字代表文档的ID,比如"Doc1"中的“1”。通过这5个文档建立简单的倒排索引:
| 单词ID(WordID) | 单词(Word) | 倒排列表(DocID) |
|---|---|---|
| 1 | 乔布斯 | 1,3,4,5 |
| 2 | 苹果 | 2,3,5 |
| 3 | iPad2 | 3,4 |
| 4 | 宣布 | 3 |
| 5 | 了 | 1,4,5 |
| … | … | … |
首先要用分词系统将文档自动切分成单词序列,这样就让文档转换为由单词序列构成的数据流,并对每个不同的单词赋予唯一的单词编号(WordID),并且每个单词都有对应的含有该单词的文档列表即倒排列表。如上表所示,第一列为单词ID,第二列为单词ID对应的单词,第三列为单词对应的倒排列表。如第一个单词ID“1”对应的单词为“乔布斯”,单词“乔布斯”的倒排列表为{1,3,4,5},即文档1、文档3、文档4、文档5都包含有单词“乔布斯”。所以当我们搜索的关键字中含有乔布斯的关键字时,此时就能找到文档Doc1,Doc3,Doc4,Doc5。
这上面的列表是最简单的倒排索引,下面介绍一种更加复杂,包含信息更多的倒排索引。
| 单词ID(WordID) | 单词(Word) | 倒排列表(DocID;TF;<Pos>) |
|---|---|---|
| 1 | 乔布斯 | (1;1;<1>),(3;1;<6>),(4;1;<1>),(5;1;<1>) |
| 2 | 苹果 | (2;1;<1>),(3;1;<1>),(5;1;<5>) |
| 3 | iPad2 | (3;1;<8>),(4;1;<7>) |
| 4 | 宣布 | (3;1;<7>) |
| 5 | 了 | (1;1;<3>),(4;1;<3>)(5;1;<3>) |
| … | … | … |
- TF(term frequency): 单词在文档中出现的次数。
- Pos: 单词在文档中出现的位置。
这个表格展示了更加复杂的倒排索引,前两列不变,第三列倒排索引包含的信息为(文档ID,单词频次,<单词位置>),比如单词“乔布斯”对应的倒排索引里的第一项(1;1;<1>)意思是,文档1包含了“乔布斯”,并且在这个文档中只出现了1次,位置在第一个。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)
2020-06-12 Maven工具学习(五)----Maven的核心概念和依赖管理