Mybatis3详解(四)----SQL映射文件详解(XxxMapper.xml)
1、映射器元素
映射器是Mybatis中最复杂并且是最重要的组件。它由一个接口和xml映射文件(或者注解)组成。在映射器中我们可以配置各类SQL、动态SQL、缓存、存储过程、级联等复杂的内容。并且通过简易的映射规则映射到指定的POJO或者其它对象上,映射器能有效的消除JDBC的底层代码。在Mybatis的应用程序开发中,映射器的开发工作量占全部工作量的80%,可见其重要性。
映射文件的作用是用来配置SQL映射语句,根据不同的SQL语句性质,使用不同的标签,其中常用的标签有:<select>、<insert>、<update>、<delete>。下面列出了SQL 映射文件的几个顶级元素(按照应被定义的顺序列出):
| 元素 | 描述 |
|---|---|
| cache | 该命名空间的缓存配置(会在缓存部分进行讲解) |
| cache-ref | 引用其它命名空间的缓存配置 |
| resultMap | 描述如何从数据库结果集中加载对象,它是最复杂也是最强大的元素 |
| 定义参数映射。此元素已被废弃,并可能在将来被移除!请使用行内参数映射parameType。所以本文中不会介绍此元素 | |
| sql | 可被其它语句引用的可重用语句块 |
| select | 映射查询语句 |
| insert | 映射插入语句 |
| update | 映射更新语句 |
| delete | 映射删除语句 |
2、select元素
select元素表示 SQL 的 select 语句,用于查询,而查询语句是我们日常中用的最多的,使用的多就意味它有着强大和复杂的功能,所以我们先来看看select元素的属性有哪些(加粗为最常用的)。
select元素中的属性 |
属性描述 |
|---|---|
| id | 在命名空间中唯一的标识符,可以被用来引用这条语句 |
| parameterType | 将会传入这条语句的参数类的完全限定名或别名。这个属性是可选的,因为 MyBatis 可以通过类型处理器(TypeHandler) 推断出具体传入语句的参数,默认值为未设置(unset) |
| parameterMap | 这是引用外部 parameterMap 的已经被废弃的方法。请使用内联参数映射和 parameterType 属性 |
| resultType | 从这条语句中返回的期望类型的类的完全限定名或别名。 注意如果返回的是集合,那应该设置为集合包含的类型,而不是集合本身。可以使用 resultType 或 resultMap,但不能同时使用 |
| resultMap | 外部 resultMap 的命名引用。结果集的映射是 MyBatis 最强大的特性,如果你对其理解透彻,许多复杂映射的情形都能迎刃而解。可以使用 resultMap 或 resultType,但不能同时使用 |
| flushCache | 将其设置为 true 后,只要语句被调用,都会导致本地缓存和二级缓存被清空,默认值:false |
| useCache | 将其设置为 true 后,将会导致本条语句的结果被二级缓存缓存起来,默认值:对 select 元素为 true |
| timeout | 这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为未设置(unset)(依赖驱动) |
| fetchSize | 这是一个给驱动的提示,尝试让驱动程序每次批量返回的结果行数和这个设置值相等。 默认值为未设置(unset)(依赖驱动) |
| statementType | STATEMENT,PREPARED 或 CALLABLE 中的一个。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED |
| resultSetType | FORWARD_ONLY,SCROLL_SENSITIVE, SCROLL_INSENSITIVE 或 DEFAULT(等价于 unset) 中的一个,默认值为 unset (依赖驱动) |
| databaseId | 如果配置了数据库厂商标识(databaseIdProvider),MyBatis 会加载所有的不带 databaseId 或匹配当前 databaseId 的语句;如果带或者不带的语句都有,则不带的会被忽略 |
| resultOrdered | resultOrdered:这个设置仅针对嵌套结果 select 语句适用:如果为 true,就是假设包含了嵌套结果集或是分组,这样的话当返回一个主结果行的时候,就不会发生有对前面结果集的引用的情况。 这就使得在获取嵌套的结果集的时候不至于导致内存不够用。默认值:false |
| resultSets | 这个设置仅对多结果集的情况适用。它将列出语句执行后返回的结果集并给每个结果集一个名称,名称是逗号分隔的 |
看到有这么多的属性是不是有点害怕,但是在实际工作中用的最多的是id、parameterType、resultType、resultMap这四个。如果还要设置设置缓存的话,还会使用到flushCache和useCache,而其它的属性是不常用功能,反正我到现在还没有用过其它的。所以我们暂时熟练掌握id、parameterType、resultType、resultMap以及它们的映射规则就行,而flushCache和useCache会在后面的缓存部分进行介绍。
下面使用select元素来举一个例子,这个例子我们前面看到过,就是根据用户Id来查找用户的信息,代码如下:
<!-- 通过Id查询一个用户 -->
<select id="selectUserById" parameterType="int" resultType="com.thr.entity.User">
select * from t_user where id = #{id};
</select>
这条SQL语句非常的简单,但是现在的目的是为了举一个例子,看看在实际开发中如何使用映射文件,这个例子只是让我们认识select元素的常用属性及用法,而在以后的开发中我们所遇到的问题要比这条SQL复杂得多,可能有十几行甚至更长。
注意:没有设置的属性全都采用默认值,你不配置不代表这个属性没有用到。
3、insert元素
insert元素表示插入数据,它可以配置的属性如下。
insert元素中的属性 |
属性描述 |
|---|---|
| id | 在命名空间中唯一的标识符,可以被用来引用这条语句 |
| parameterType | 将会传入这条语句的参数的类全限定名或别名。这个属性是可选的,因为 MyBatis 可以通过类型处理器(TypeHandler)推断出具体传入语句的参数,默认值为未设置(unset) |
| 用于引用外部 parameterMap 的属性,目前已被废弃。请使用行内参数映射和 parameterType 属性 | |
| flushCache | 将其设置为 true 后,只要语句被调用,都会导致本地缓存和二级缓存被清空,默认值:(对 insert、update 和 delete 语句)true |
| timeout | 这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为未设置(unset)(依赖数据库驱动) |
| statementType | 可选 STATEMENT,PREPARED 或 CALLABLE。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED |
| useGeneratedKeys | (仅适用于 insert 和 update)这会令 MyBatis 使用 JDBC 的 getGeneratedKeys 方法来取出由数据库内部生成的主键(比如:像 MySQL 和 SQL Server 这样的关系型数据库管理系统的自动递增字段),默认值:false |
| keyProperty | (仅适用于 insert 和 update)指定能够唯一识别对象的属性,MyBatis 会使用 getGeneratedKeys 的返回值或 insert 语句的 selectKey 子元素设置它的值,默认值:未设置(unset)。如果生成列不止一个,可以用逗号分隔多个属性名称。不能和keyColumn连用 |
| keyColumn | (仅适用于 insert 和 update)设置生成键值在表中的列名,在某些数据库(像 PostgreSQL)中,当主键列不是表中的第一列的时候,是必须设置的。如果生成列不止一个,可以用逗号分隔多个属性名称。不能和keyProperty连用 |
| databaseId | 如果配置了数据库厂商标识(databaseIdProvider),MyBatis 会加载所有不带 databaseId 或匹配当前 databaseId 的语句;如果带和不带的语句都有,则不带的会被忽略 |
下面是insert元素的简单应用,在执行完SQL语句后,会返回一个整数来表示其影响的记录数。代码如下:
<!-- 添加用户-->
<insert id="insertUser" parameterType="com.thr.entity.User">
insert into t_user(username, age ,sex ,address) values (#{username},#{age},#{sex},#{address});
</insert>
3.1 主键回填
在insert元素中,有一个非常重要且常用的属性——useGeneratedKeys,它的作用的主键回填,就是将当前插入数据的主键返回。例如上面的插入语句中,我们并没有插入主键 Id 列,因为在mysql数据库中将它设置为自增主键,数据库会自动为其生成对应的主键,所以没必要插入这个列。但是有些时候我们还需要继续使用这个主键,用以关联其它业务,所以十分有必要获取它。比如在新增用户的时候,首先会插入用户的数据,然后插入用户和角色关系表,而插入用户时如果没办法取到用户的主键,那么就没有办法插入用户和角色关系表了,因此这个时候需要拿到对应的主键,以方便关联表的操作。
在JDBC中,使用Statement对象执行插入的SQL语句后,可以通过getGeneratedKeys方法来获取数据库生成的主键。而在insert元素中也设置了一个对应的属性useGeneratedKeys,它的默认值为false。当我们把这个属性设置为true时,还需要配置keyProperty或keyColumn(它二者不能同时使用),告诉系统把生成的主键放入哪个属性中,如果存在多个主键,就要用逗号隔开。
我们将上面xml配置文件中的insert语句进行更改,更改后代码如下:
<!-- 添加用户-->
<insert id="insertUser" parameterType="com.thr.entity.User" useGeneratedKeys="true" keyProperty="id">
insert into t_user(username, age ,sex ,address) values (#{username},#{age},#{sex},#{address});
</insert>
useGeneratedKeys设置为true表示将会采用jdbc的Statement对象的getGeneratedKeys方法返回主键,因为Mybatis的底层始终是jdbc的代码。设置keyProperty对于 id 表示用这个pojo对象的属性去匹配这个主键,它会将数据库返回的主键值赋值为这个pojo对象的属性。测试代码如下:
//添加一个用户数据
@Test
public void testInsertUser1(){
String statement = "com.thr.mapper.UserMapper.insertUser";
User user = new User();
user.setUsername("张三");
user.setAge(30);
user.setSex("男");
user.setAddress("中国北京");
sqlSession.insert(statement, user);
//提交插入的数据
sqlSession.commit();
sqlSession.close();
//输出返回的主键只
System.out.println("插入的主键值为:"+user.getId());
}
输出结果为:

通过结果可以发现我们已经获取到插入数据的主键了。
3.2 自定义主键
自定义主键,顾名思义就是我们自己定义返回的主键值。有时候我们的不想按照数据库自增的规则,例如每次插入主键+2,又或者随机生成数据。那么Mybatis对于这样的场景也提供了支持,它主要依赖于selectKey元素进行支持,它允许自定义键值的生成规则,如下代码:
<!-- 添加用户-->
<insert id="insertUser" parameterType="com.thr.entity.User">
<selectKey keyProperty="id" resultType="int" order="BEFORE">
select ROUND(RAND()*1000)
</selectKey>
insert into t_user(username, age ,sex ,address) values (#{username},#{age},#{sex},#{address});
</insert>
执行的流程是:首先通过select ROUND(RAND()*1000)得到主键值,然后将得到的值设置到 user 对象的 id 中,再最后进行 insert 操作。
下面再来介绍一下相关的标签:
keyProperty:将查询到的主键设置到parameterType 指定到对象的那个属性。select ROUND(RAND()*1000):得到一个随机主键的id值,ROUND()表示获取到小数点后几位(默认为0),RAND()*100表示获取[0 , 100 )之间的任意数字。resultType:指定select ROUND(RAND()*1000)的结果类型order:BEFORE,表示在SQL语句之前执行还之后执行,可以设置为 BEFORE或AFTER。这里是BEFORE,则表示先执行select ROUND(RAND()*1000)。
测试运行结果为:

4、update和delete元素
update元素和delete元素在使用上比较简单,所以这里把它们放在一起论述。它们和insert元素的属性差不多,执行完后也会返回一个整数,用来表示该SQL语句影响了数据库的记录行数。它们二者的使用代码如下所示:
<!-- 根据Id更新用户 -->
<update id="updateUser" parameterType="com.thr.entity.User">
update t_user set username = #{username},age = #{age},sex = #{sex},address = #{address} where id = #{id}
</update>
<!-- 根据Id删除用户 -->
<delete id="deleteUser" parameterType="int">
delete from t_user where id = #{id}
</delete>
由于在使用上比较简单,所以就不做多介绍了,具体可以参考前面select和insert元素。
5、sql元素
sql元素是用来定义可重用的 sql代码片段,这样在字段比较多的时候,以便在其它语句中使用。
<!--定义sql代码片段-->
<sql id="userCols">
id,username,age,sex,address
</sql>
<!-- 查询所有用户 -->
<select id="selectAllUser" resultType="com.thr.entity.User">
select <include refid="userCols"/> from t_user
</select>
<!-- 添加用户-->
<insert id="insertUser" parameterType="com.thr.entity.User">
<selectKey keyProperty="id" resultType="int" order="BEFORE">
select ROUND(RAND()*1000)
</selectKey>
insert into t_user(<include refid="userCols"/>) values (#{id},#{username},#{age},#{sex},#{address});
</insert>
sql元素还支持变量的传递,这种方式简单了解即可,代码如下。
<!--定义sql代码片段-->
<sql id="userCols">
${alias}.id,${alias}.username,${alias}.age,${alias}.sex,${alias}.address
</sql>
<!-- 查询所有用户 -->
<select id="selectAllUser" resultType="com.thr.entity.User">
select <include refid="userCols">
<property name="alias" value="u"/>
</include>
from t_user u
</select>
在include元素中定义了一个命名为alias的变量,其值是表t_user的别名u,然后sql元素就能自动识别到对于表的变量名,例如u.id、u.username、u.age。这种方式对于多表查询很有用,但也用的不多。
6、输入映射parameterType
6.1、映射基本数据类型(即八大基本数据类型,比如int,boolean,long等类型)
根据id查询一个用户:selectUserById,那么传入的就应该是int类型的值。所以使用别名int来映射传入的值。
<!-- 通过Id查询一个用户 -->
<select id="selectUserById" parameterType="int" resultType="com.thr.entity.User">
select * from t_user where id = #{id};
</select>
6.2、映射pojo类型(即普通的对象,比如user的javabean对象)
添加用户:insertUser。这里传入的就是一个pojo类型。
<!-- 添加用户-->
<insert id="insertUser" parameterType="com.thr.entity.User">
insert into t_user(id,username,age,sex,address) values (#{id},#{username},#{age},#{sex},#{address});
</insert>
6.3、包装pojo类型(即内部属性为对象引用,集合等)
那什么是包装pojo类型呢?比如如下的代码:
public class QueryVo {
//有个对象引用,可能是普通的pojo,也有可能是集合
private User user;
public User getUser() {
return user;
}
public void setUser(User user) {
this.user = user;
}
}
根据用户名和年龄查询用户信息:selectUserByUserNameAndAge。传入一个包装pojo类型,其内部有个属性是user的引用。
<!-- 通过username和age查询一个用户 -->
<select id="selectUserByUserNameAndAge" parameterType="com.thr.entity.QueryVo" resultType="com.thr.entity.User">
select * from t_user where username = #{user.username} and age = #{user.age};
</select>
测试代码:
@Test
public void testSelectUserByUserNameAndAge(){
String statement = "com.thr.mapper.UserMapper.selectUserByUserNameAndAge";
QueryVo vo = new QueryVo();
User user = new User();
user.setUsername("马保国");
user.setAge(30);
vo.setUser(user);
List<User> listUser = sqlSession.selectList(statement, vo);
for(User u : listUser){
System.out.println(u);
}
sqlSession.close();
}
注意:user.username这个属性的获取,因为QueryVO是一个包装pojo,其中有user的引用。而user中又有username的属性,那么这样一层层取过来用即可。
6.4、映射map集合
这个也很简单,理解了前面的,这个不难。就是通过map集合设置key和value的值,然后在映射文件中获取对应的key即可 #{key}。
<!-- 通过username和age查询一个用户 -->
<select id="selectUserByMap" parameterType="hashmap" resultType="com.thr.entity.User">
select * from t_user where username = #{username} and age = #{age};
</select>
测试代码:
@Test
public void testSelectUserByMap(){
String statement = "com.thr.mapper.UserMapper.selectUserByMap";
//创建HashMap对象
HashMap<String, Object> map = new HashMap<>();
//put值
map.put("username","马保国");
map.put("age",30);
List<User> listUser = sqlSession.selectList(statement, map);
for(User u : listUser){
System.out.println(u);
}
sqlSession.close();
}
注意:这里的hashmap使用的是别名,mybatis中内置了。
7、输出映射resultType
resultType为输出结果集类型,同样支持基本数据类型、pojo类型及map集合类型。SQL语句查询后返回的结果集会映射到配置标签的输出映射属性对应的Java类型上。
输出映射有两种配置,分别是resultType和resultMap,注意两者不能同时使用。
7.1、映射基本数据类型
<!-- 统计用户总数量 -->
<select id="countUsers" resultType="int">
select count(1) from t_user
</select>
7.2、映射pojo对象
<!-- 通过Id查询一个用户,resultType配置为PoJo类型 -->
<select id="selectUserById" parameterType="int" resultType="com.thr.entity.User">
select * from t_user where id = #{id};
</select>
7.3、映射pojo列表(映射多列数据)
映射单个pojo对象和映射pojo列表映射文件中的resultType都配置为pojo类型。区别只是返回单个对象是内部调用selectOne返回pojo对象,返回pojo列表时内部调用selectList方法。
<!-- 查询所有用户 -->
<select id="selectAllUser" resultType="com.thr.entity.User">
select * from t_user
</select>
7.4、映射hashmap
<!-- 查询所有用户, resultType为hashmap-->
<select id="selectAllUser" resultType="hashmap">
select * from t_user
</select>
测试代码:
//查询所有用户数据,通过HashMap
@Test
public void testSelectAllUser(){
String statement = "com.thr.mapper.UserMapper.selectAllUser";
List<HashMap<String, Object>> listUser = sqlSession.selectList(statement);
for (HashMap<String, Object> map: listUser) {
Iterator<Map.Entry<String, Object>> iterator = map.entrySet().iterator();
while (iterator.hasNext()){
Map.Entry<String, Object> entry = iterator.next();
System.out.println("key= "+entry.getKey()+" and value= "+entry.getValue());
}
}
sqlSession.close();
}
8、输出映射resultMap(重要)
我们在使用resultType的时候,前提是数据库表中的字段名和表对应实体类的属性名称一致才行(包括驼峰原则),但是在平时的开发中,表中的字段名和表对应实体类的属性名称往往不一定都是完全相同的,这样就会导致数据映射不成功,从而查询不到数据。那为了解决这个问题,我需要使用resultMap,通过resultMap将字段名和属性名作一个对应关系。
下面先来简单体验一下resultMap的使用,为了让例子更加好,我将数据库表User实体的属性进行了简单的修改,如下:
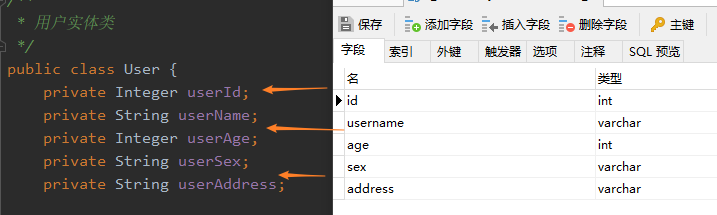
向表t_user中添加一些数据:
INSERT INTO `t_user` VALUES (1, '奥利给', 18, '男', '上海');
INSERT INTO `t_user` VALUES (2, '蔡徐坤', 18, '男', '北京');
INSERT INTO `t_user` VALUES (3, '黄飞鸿', 42, '男', '大清');
INSERT INTO `t_user` VALUES (4, '十三姨', 18, '女', '大清');
改完之后,数据库的字段与User实体的属性是不能在进行自动映射了。这种情况我们就可以使用resultMap进行映射。下面配置查询结果的列名和实体类的属性名的对应关系,修改xml配置文件。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.thr.mapper.UserMapper">
<!-- 配置查询结果的列名和实体类的属性名的对应关系 -->
<!--id:唯一标识,type:需要映射的java类型-->
<resultMap id="userMap" type="com.thr.entity.User">
<!-- 与主键字段的对应,property对应实体属性,column对应表字段 -->
<id property="userId" column="id"/>
<!-- 与非主键字段的对应,property对应实体属性,column对应表字段 -->
<result property="userName" column="username"/>
<result property="userAge" column="age"/>
<result property="userSex" column="sex"/>
<result property="userAddress" column="address"/>
</resultMap>
<!-- 查询所有用户,返回集为resultMap类型,resultMap的value上面配置的id=userMap要一致-->
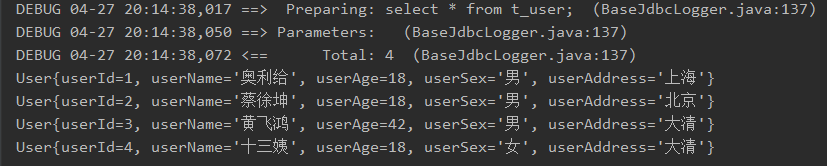
<select id="selectAllUser" resultMap="userMap">
select * from t_user
</select>
</mapper>
测试代码:
//查询所有用户数据
@Test
public void testSelectAllUser(){
String statement = "com.thr.mapper.UserMapper.selectAllUser";
List<User> listUser = sqlSession.selectList(statement);
for (User user : listUser) {
System.out.println(user);
}
sqlSession.close();
}
运行结果:
当然,还有一种方式可以不用resultMap元素,就是sql 查询取别名时与pojo属性一致即可,但是不推荐,这样sql的可读性差),举例代码如下。
<select id="selectAllUser" resultType="com.thr.entity.User">
select id userId,username userName,age userAge,sex userSex,address userAddress from t_user
</select>
8.1、resultMap元素中属性的简单介绍
额外,resultMap还有高级映射功能,还可以实现将查询结果映射为复杂类型的pojo类型,比如在查询结果映射对象中包括pojo和list实现一对一查询和一对多查询,这个会在后面单独进行详细的介绍,因为这个点非常非常非常重要,所以这里不多说。我们下面来详细介绍一下resultMap元素。
<resultMap id="" type="" extends="" autoMapping="">
<constructor><!--构造器注入属性值-->
<idArg/>
<arg/>
</constructor>
<id/><!--主键的映射规则-->
<result/><!--非主键的映射规则-->
<association/><!--高级映射-->
<collection /><!--高级映射-->
<discriminator>
<case/>
</discriminator><!--根据返回的字段的值封装不同的类型-->
</resultMap>
①、resultMap元素包含的属性:
- id:该封装规则的唯一标识。
- type:表示返回映射的类型,可以是基本数据类型,pojo和map类型。
- autoMapping:自动封装,如果数据库字段和javaBean的字段名一样,可以使用这种方式,但是不建议采取,还是老老实实写比较稳妥,如果非要使用此功能,那就在全局配置中加上mapUnderscoreToCamelCase=TRUE,它会使经典数据库字段命名规则翻译成javaBean的经典命名规则,如:a_column翻译成aColumn。
- extends:继承其他封装规则,和Java中的继承一样。
②、resultMap元素的子元素<constructor>
使用构造方法映射属性值,用的非常少。
<resultMap id="userConstructorMap" type="com.thr.entity.User">
<constructor>
<idArg column="id" name="userId" javaType="int"/>
<arg column="username" name="userName" javaType="string"/>
<arg column="age" name="userAge" javaType="int"/>
<arg column="sex" name="userSex" javaType="string"/>
<arg column="address" name="userAddress" javaType="string"/>
</constructor>
</resultMap>
③、resultMap元素的子元素<id>和<result>
<id>表示与主键字段的映射规则<result>表示与非主键字段的映射规则
它们二者的内部属性一致,如下:
- column:指定数据库字段名或者其别名(这个别名是数据库起的,如 username as name)
- property:指定javabean的属性名
- jdbcType:映射java的类型
- javaType:映射数据库类型
- typeHandler:数据库与Java类型匹配处理器(可以参考前面的TypeHandler部分)
④、<association>、<collection>和<discriminator>
<association>:高级映射一对一映射规则<collection>:高级映射一对多映射规则<discriminator>:负责根据返回的字段的值封装不同的类型
这些元素都是关于级联的问题比较复杂,所以这里就不探讨了,后面会介绍到。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号