数据库连接池的使用
1、连接池的介绍
我们知道,在前面JDBC的知识中我们在连接数据库的时候,每次创建连接完成操作后再关闭连接。如果当一个程序有大量访问数据库操作的时候,此时就要不停的建立连接,关闭连接。而建立一个数据库连接是一件非常耗时(消耗时间)耗力(消耗资源)的事情,极大的浪费数据库的资源,并且极易造成数据库服务器内存溢出、拓机。之所以会这样,是因为连接到数据库服务器需要经历几个漫长的过程:建立物理通道(例如套接字或命名管道),与服务器进行初次握手,分析连接字符串信息,由服务器对连接进行身份验证,运行检查以便在当前事务中登记等等。我们先不管为什么会有这样的机制,存在总是有它的道理。既然新建一条连接如此痛苦,那么为什么不重复利用已有的连接呢?所以就有了数据库连接池。
数据库连接池:用来负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个。
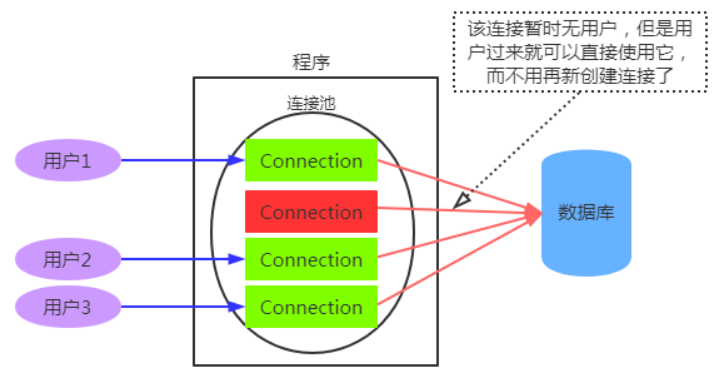
数据库连接池在初始化时将创建一定数量的数据库连接放到连接池中,这些数据库连接的数量是由最小数据库连接数来设定的。无论这些数据库连接是否被使用,连接池都将一直保证至少拥有这么多的连接数量。连接池的最大数据库连接数量限定了这个连接池能占有的最大连接数,当应用程序向连接池请求的连接数超过最大连接数量时,这些请求将被加入到等待队列中。
数据库连接池的最小连接数和最大连接数的设置要考虑到以下几个因素:
- 最小连接数:是连接池一直保持的数据库连接,所以如果应用程序对数据库连接的使用量不大,将会有大量的数据库连接资源被浪费。
- 最大连接数:是连接池能申请的最大连接数,如果数据库连接请求超过次数,后面的数据库连接请求将被加入到等待队列中,这会影响以后的数据库操作。
- 最小连接数与最大连接数差距:那么最先连接请求将会获利,之后超过最小连接数量的连接请求等价于建立一个新的数据库连接.不过,这些大于最小连接数的数据库连接在使用完不会马上被释放,他将被放到连接池中等待重复使用或是空间超时后被释放。
现在市面上常用的开源数据库连接池有DBCP、C3P0、Druid和Hikari连接池等等。其中DBCP和C3P0好像已经淘汰了,用的最多的是后面两个:Druid和Hikari连接池。
2、连接池的原理
我们早期对数据的操作是这样的:①、加载数据库驱动程序;②、通过 jdbc 建立数据库连接;③、访问数据库,执行 sql 语句;④、断开数据库连接。但是这种方式对于大量请求存在很多问题。因为每次web请求都会建立一次数据库连接,而建立连接是一个费时的过程。所以为了保障网站的正常使用,应该对其进行妥善管理。其实我们查询完数据库后,不要关闭连接,而是暂时存放起来,当别人使用时,把这个连接给他们使用。就避免了一次建立数据库连接和断开的操作时间消耗。
连接池的工作原理主要由三部分组成,分别为:①、连接池的建立;②、连接池中连接的使用管理;③、连接池的关闭。
①、连接池的建立。一般在系统初始化时,连接池会根据系统配置建立,并在池中创建了几个连接对象,以便使用时能从连接池中获取。连接池中的连接不能随意创建和关闭,这样避免了连接随意建立和关闭造成的系统开销。Java中提供了很多容器类可以方便的构建连接池,例如例如 Vector(线程安全类),LinkedList等
②、连接池的管理。连接池管理策略是连接池机制的核心,连接池内连接的分配和释放对系统的性能有很大的影响。其管理策略是:
- 当客户请求数据库连接时,首先查看连接池中是否有空闲连接,如果存在空闲连接,则将连接分配给客户使用;如果没有空闲连接,则查看当前所开的连接数是否已经达到最大连接数,如果没达到就重新创建一个连接给请求的客户;如果达到就按设定的最大等待时间进行等待,如果超出最大等待时间,则抛出异常给客户。
- 当客户释放数据库连接时,先判断该连接的引用次数是否超过了规定值,如果超过了就从连接池中删除该连接,并判断当前连接池内总的连接数是否小于最小连接数,若小于就将连接池充满;如果没超过就将该连接标记为开放状态,可供再次复用。该策略保证了数据库连接的有效复用,避免频繁的建立、释放连接所带来的系统资源开销。
③、连接池的关闭。当应用程序退出时,关闭连接池中所有的连接,释放连接池相关的资源,该过程正好与创建相反。
使用连接池的主要优点:
- 减少连接的创建时间。连接池中的连接是已准备好的,可以重复使用的,获取后可以直接访问数据库,因此减少了连接创建的次数和时间。
- 更快的系统响应速度。数据库连接池在初始化过程中,往往已经创建了若干数据库连接置于池中备用。此时连接的初始化工作均已完成。对于业务请求处理而言,直接利用现有可用连接,避免了数据库连接初始化和释放过程的时间开销,从而缩减了系统整体响应时间。
- 统一的连接管理。如果不使用连接池,每次访问数据库都需要创建一个连接,这样系统的稳定性受系统的连接需求影响很大,很容易产生资源浪费和高负载异常。连接池能够使性能最大化,将资源利用控制在一定的水平之下。连接池能控制池中的链接数量,增强了系统在大量用户应用时的稳定性。
3、DBCP连接池
DBCP:DBCP(DataBase connection pool)连接池是一个依赖Jakarta commons-pool对象池机制的数据库连接池,现在的版本是DBCP2,但是现在很久没有更新了。DBCP可以直接的在应用程序中使用。要使用DBCP数据源,需要应用程序应在系统中增加如下三个 jar 包(logging可以不要):
注意下载的是二进制包。
- commons-dbcp.jar:连接池的实现 。下载地址:http://commons.apache.org/proper/commons-dbcp/download_dbcp.cgi
- commons-pool.jar:连接池实现的依赖库。下载地址:http://commons.apache.org/proper/commons-pool/download_pool.cgi
- commons-logging.jar:连接池的日志。下载地址:http://commons.apache.org/proper/commons-logging/download_logging.cgi
下载后解压文件,将去导入到项目中去:
DBCP连接池的使用举例:
①、在src目录下加入dbcp的配置文件:dbcp.properties。
dbcp.properties的配置信息如下:
########DBCP配置文件##########
#驱动名
driverClassName=com.mysql.jdbc.Driver
#url
url=jdbc:mysql://localhost:3306/user?characterEncoding=utf8&useSSL=false
#用户名
username=root
#密码
password=root
#连接池的配置信息
#初始连接数,启动时创建的数量
initialSize=30
#最大活跃数 或 最大连接数(DBCP2中maxActive改成 maxTotal)
maxTotal=30
#最大空闲连接数
maxIdle=10
#最小空闲连接数
minIdle=5
#最长等待时间(毫秒),dbcp2由maxWait该成maxWaitMillis
maxWaitMillis=1000
想要了解更详细的配置信息可以参考:https://blog.csdn.net/brushli/article/details/80413461
②、测试DBCP数据源代码如下:
package com.dbcp;
import javax.sql.DataSource;
import java.io.IOException;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Properties;
import org.apache.commons.dbcp2.BasicDataSourceFactory;
/**
* @author tanghaorong
* @date 2020-05-29
* @desc DBCP数据库连接池的使用
*/
public class DBCPTest {
public static void main(String[] args) {
//数据库连接对象
Connection con = null;
//数据库操作对象
PreparedStatement ps = null;
//数据库结果集对象
ResultSet rs = null;
//数据源对象
DataSource ds = null;
//properties配置文件对象
Properties properties = new Properties();
//读取dbcp.properties文件
InputStream in = DBCPTest.class.getClassLoader().getResourceAsStream("dbcp.properties");
try {
//从输入流中读取配置文件
properties.load(in);
//获取数据源,设置连接池参数。在createDataSource中设置连接池的参数
ds = BasicDataSourceFactory.createDataSource(properties);
//通过数据源来获取连接对象
con = ds.getConnection();
//编译并且执行SQL
ps = con.prepareStatement("select * from t_user");
rs = ps.executeQuery();
System.out.println("查询的数据为:");
//读取数据
while (rs.next()){
System.out.println(rs.getString(2)+":"+rs.getString(3));
}
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
} finally {
//关闭连接
if (rs!=null){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (ps!=null){
try {
ps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (con!=null){
try {
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
}
4、C3P0连接池
C3P0:是一个开放源代码的JDBC连接池,它包括了实现JDBC3和JDBC2扩展规范说明的Connection 和Statement 池的DataSources 对象。虽然C3P0的功能简单易用,稳定性好这是它的优点,但是性能上的缺点却让它彻底淘汰了,因为现在的系统架构对性能的要是比较的高的,所以随着国内互联网大潮的涌起,性能有硬伤的c3p0彻底的退出了历史舞台。
要使用C3P0连接池,需要应用程序应在系统中增加如下两个 jar 包如下:
- c3p0-0.9.5.2.jar
- mchange-commons-0.2.12.jar
百度网盘下载链接:https://pan.baidu.com/s/1o9cBkMVb_kZmAksZjjoZYg 密码:c7pr
①、导入jar包之后新建一个c3p0-config.xml文件
注意:命名必须为c3p0-config.xml。必须放在src目录下,c3p0包会默认加载src目录下的c3p0-config.xml文件。
配置c3p0-config.xml文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<c3p0-config>
<!-- 默认读的c3p0配置文件,在代码中用“ComboPooledDataSource ds = new ComboPooledDataSource();”来获取 -->
<default-config>
<!--mysql数据库连接的各项参数-->
<property name="driverClass">com.mysql.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql://127.0.0.1:3306/user?characterEncoding=utf-8</property>
<property name="user">root</property>
<property name="password">root</property>
<!--配置数据库连接池的最小链接数、最大连接数、初始连接数-->
<property name="maxPoolSize">15</property>
<property name="minPoolSize">5</property>
<property name="initialPoolSize">5</property>
</default-config>
<!--按名称的配置文件,可用于配置其它数据库,比如oracle -->
<!--在代码中用“ComboPooledDataSource ds = new ComboPooledDataSource("mydb");”来获取
这样写就表示使用的是name为mydb的配置信息来创建数据源-->
<named-config name="mydb">
<property name="driverClass">com.mysql.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql://192.168.200.200:3306/user?characterEncoding=utf-8</property>
<property name="user">root</property>
<property name="password">root</property>
<property name="maxPoolSize">15</property>
<property name="minPoolSize">5</property>
<property name="initialPoolSize">5</property>
</named-config>
</c3p0-config>
②、测试c3p0连接池
package com.c3p0;
import com.mchange.v2.c3p0.ComboPooledDataSource;
import java.sql.*;
/**
* @author tanghaorong
* @date 2020-05-30
* @desc C3P0连接池的使用
*/
public class C3P0Test {
public static void main(String[] args) {
//数据库连接对象
Connection con = null;
//数据库操作对象
PreparedStatement ps = null;
//数据库结果集对象
ResultSet rs = null;
//创建数据库连接池对象,读取默认的
ComboPooledDataSource cpds = new ComboPooledDataSource();
//获取名称为mydb的配置文件内容
//ComboPooledDataSource cpds = new ComboPooledDataSource("mydb");
try {
//从数据库连接池中获取连接对象
con = cpds.getConnection();
ps = con.prepareStatement("select * from t_user");
rs = ps.executeQuery();
while (rs.next()){
System.out.println(rs.getString(2)+":"+rs.getString(3));
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
//关闭连接
if (rs!=null){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (ps!=null){
try {
ps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (con!=null){
try {
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
}
5、HikariCP连接池
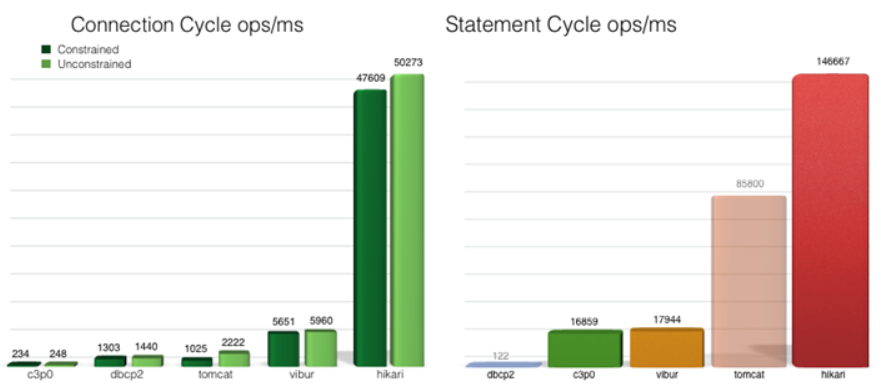
HikariCP连接池:HikariCP是由日本程序员开源的一个数据库连接池组件,代码非常轻量。它号称“性能杀手”(It’s Faster),所以其速度是非常的快,而且稳定性也很好。先来看下官网提供的数据:在i7CPU中,开启32个线程32个连接的情况下,进行随机数据库读写操作,HikariCP的速度是现在常用的C3P0数据库连接池的数百倍。在SpringBoot2.0中,官方也是推荐使用HikariCP。
那它是怎么做到如此强劲的呢?官网给出的说明如下:
- 字节码精简:优化代码,直到编译后的字节码最少,这样,CPU缓存可以加载更多的程序代码;
- 优化代理和拦截器:减少代码,例如HikariCP的Statement proxy只有100行代码;
- 自定义数组类型(FastStatementList)代替ArrayList:避免每次get()调用都要进行range check,避免调用remove()时的从头到尾的扫描;
- 自定义集合类型(ConcurrentBag):提高并发读写的效率;
其他缺陷的优化,比如对于耗时超过一个CPU时间片的方法调用的研究(但没说具体怎么优化)。
要使用HikariCP就需要导入对应的包,如下(HikariCP的jar包不好找,所以直接贴Maven坐标了):
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>3.4.5</version>
</dependency>
使用HikariCP简单举例:
package com.hikaricp;
import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
import java.sql.*;
/**
* @author tanghaorong
* @date 2020-05-31
* @desc HikariCP连接池的使用
*/
public class HikariCPTest {
public static void main(String[] args) {
//数据库连接对象
Connection con = null;
//数据库操作对象
PreparedStatement ps = null;
//数据库结果集对象
ResultSet rs = null;
try {
//表示连接池的配置文件对象
HikariConfig hikariConfig = new HikariConfig();
//连接池的基本配置
hikariConfig.setJdbcUrl("jdbc:mysql://localhost:3306/user?characterEncoding=utf8&useSSL=false");
hikariConfig.setUsername("root");
hikariConfig.setPassword("root");
//连接池的配置信息
hikariConfig.setMaximumPoolSize(20);
hikariConfig.setMinimumIdle(15);
hikariConfig.setMaxLifetime(2000000);
hikariConfig.setConnectionTimeout(5000);
//创建连接池数据源对象
HikariDataSource ds = new HikariDataSource(hikariConfig);
con = ds.getConnection();
ps = con.prepareStatement("select * from t_user");
rs = ps.executeQuery();
while (rs.next()){
System.out.println(rs.getString(2)+":"+rs.getString(3));
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
//关闭连接代码省略
}
}
}
关于HikariCP更多详细的配置信息可以参考:https://blog.csdn.net/Maskkiss/article/details/82115149
6、Druid连接池
Druid连接池想必大家都非常的熟悉,可能在座的大家都使用过,它是由阿里巴巴公司开发的一个开源项目。它支持所有JDBC兼容的数据库,包括Oracle、MySql、Derby、Postgresql、SQL Server、H2等。Druid除了提供性能卓越的连接池功能外,还集成了SQL监控,黑名单拦截等功能,用它自己的话说,Druid是“为监控而生”。其实Druid不仅是一个数据库连接池,还包含一个ProxyDriver、一系列内置的JDBC组件库、一个SQL Parser。所以Druid是Java语言中最好的数据库连接池是当之无愧的。
Druid 相对于其他数据库连接池的优点在于:
- 性能高。它比dbcp、c3p0的性能高很多很多,除了HikariCp。
- 提供了强大的监控特性,通过Druid提供的监控功能,可以清楚知道连接池和SQL的工作情况。
- 监控SQL的执行时间、ResultSet持有时间、返回行数、更新行数、错误次数、错误堆栈信息
- 方便扩展。Druid提供了Filter-Chain模式的扩展API,可以自己编写Filter拦截JDBC中的任何方法,可以在上面做任何事情,比如说性能监控、SQL审计、用户名密码加密、日志等等。
Druid与HikariCP的对比:因为HikariCP时性能之王,所以Hikari在性能上是完全秒杀阿里巴巴的Druid连接池的。对此,阿里的工程师也做了一定的回应,说Druid的性能稍微差点是锁机制的不同,并且Druid提供了更丰富的功能,两者的侧重点不一样。所以选择哪一款连接池就见仁见智了,不过两款都是开源产品,阿里的Druid有中文的开源社区,交流起来更加方便,并且经过阿里多个系统的实验,想必也是非常的稳定,而Hikari是SpringBoot2.0默认的连接池,全世界使用范围也非常广,对于大部分业务来说,使用哪一款都是差不多的,毕竟性能瓶颈一般都不在连接池。大家可根据自己的喜好自由选择。
Druid的使用:添加druid的依赖、数据库驱动:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.8</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.19</version>
</dependency>
①、纯Java代码方式
//数据源配置
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl("jdbc:mysql://localhost:3306/user?characterEncoding=utf8&useSSL=false");
dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver"); //这个可以缺省的,会根据url自动识别
dataSource.setUsername("root");
dataSource.setPassword("root");
//下面都是可选的配置
dataSource.setInitialSize(10); //初始连接数,默认0
dataSource.setMaxActive(30); //最大连接数,默认8
dataSource.setMinIdle(10); //最小闲置数
dataSource.setMaxWait(2000); //获取连接的最大等待时间,单位毫秒
dataSource.setPoolPreparedStatements(true); //缓存PreparedStatement,默认false
dataSource.setMaxOpenPreparedStatements(20); //缓存PreparedStatement的最大数量,默认-1(不缓存)。大于0时会自动开启缓存PreparedStatement
//获取连接
Connection connection = dataSource.getConnection();
String sql = "insert into t_user (username,password) values ('tom','123456')";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
preparedStatement.execute();
//关闭连接
connection.close();
②、配置文件方式
在项目中创建一个druid.properties的配置文件。
url=jdbc:mysql://localhost:3306/user?characterEncoding=utf8&useSSL=false
#这个可以缺省的,会根据url自动识别
driverClassName=com.mysql.cj.jdbc.Driver
username=root
password=abcd
##初始连接数,默认0
initialSize=10
#最大连接数,默认8
maxActive=30
#最小闲置数
minIdle=10
#获取连接的最大等待时间,单位毫秒
maxWait=2000
#缓存PreparedStatement,默认false
poolPreparedStatements=true
#缓存PreparedStatement的最大数量,默认-1(不缓存)。大于0时会自动开启缓存PreparedStatement
maxOpenPreparedStatements=20
测试代码如下:
public class DruidTest {
public static void main(String[] args) throws Exception {
//数据源配置
Properties properties=new Properties();
//通过当前类的class对象获取资源文件
InputStream is = DruidTest.class.getResourceAsStream("/druid.properties");
properties.load(is);
//返回的是DataSource,不是DruidDataSource
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);
//获取连接
Connection connection = dataSource.getConnection();
String sql = "insert into t_user (username,password) values ('tom','123456')";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
preparedStatement.execute();
//关闭连接
connection.close();
}
}
③、与Spring整合
同样需要使用到上面的druid.properties配置文件,然后在Spring的配置文件配置如下:
<!--引入druid配置文件-->
<context:property-placeholder location="classpath:druid.properties" />
<!--druid连接池-->
<bean name="druidDataSource" class="com.alibaba.druid.pool.DruidDataSource">
<property name="url" value="${druid.url}" />
<property name="driverClassName" value="${druid.driverClassName}" />
<property name="username" value="${druid.username}" />
<property name="password" value="${druid.password}" />
<property name="initialSize" value="${druid.initialSize}"/>
<property name="maxActive" value="${druid.maxActive}" />
<property name="minIdle" value="${druid.minIdle}" />
<property name="maxWait" value="${druid.maxWait}" />
<property name="poolPreparedStatements" value="${druid.poolPreparedStatements}" />
<property name="maxOpenPreparedStatements" value="${druid.maxOpenPreparedStatements}" />
</bean>
测试Spring整合Druid连接池:
@@component
public class SpringWithDruid {
//注入Druid数据源
@Resource
private DruidDataSource dataSource;
public void add() throws SQLException {
//获取连接
Connection connection = dataSource.getConnection();
String sql = "insert into t_user (username,password) values ('tom','123456')";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
preparedStatement.execute();
System.out.println(“执行成功…”);
//关闭连接
connection.close();
}
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· 因为Apifox不支持离线,我果断选择了Apipost!