夯实Java基础(二十三)----Java8新特征之Stream API
1、Stream流的简介
Java8 中除了引入了Lambda表达式、新的Date API之外,另外还有一最大亮点就是引入了 Stream API,这也是值得所有Java开发人员学习的一个知识点,因为它的功能非常的强大,解放了程序员操作集合(Collection)时的生产力,尤其是和前面学习的Lambda表达式、函数式接口、方法引用共同使用时,才能发挥出Stream最强大的威力。
Stream流是数据渠道,像一个高级的迭代器,用于操作数据源所生成的元素序列,即操作集合、数组等等。其中集合和 Stream 的区别是:集合讲的是数据,而 Stream 讲的是计算(处理数据的过程)。Stream的API全部都位于java.util.stream这样一个包下,它能够帮助开发人员从更高的抽象层次上对集合进行一系列操作,就类似于使用SQL执行数据库查询,在流的过程中,对流中的元素执行一些操作,比如“过滤掉长度大于 10 的字符串”、“获取每个字符串的首字母”等。而借助java.util.stream包,我们可以简明的声明性的表达集合,数组和其他数据源上可能的并行处理。实现从外部迭代到内部迭代的改变。它含有高效的聚合操作、大批量的数据处理,同时也内置了许多运算方式,包括筛选、排序、聚合等等。简单来说,用Stream来操作集合——减少了代码量,增强了可读性,提高运行效率。
注意:听到 Stream 这个词大家可能会联想到 Java IO 中的Stream,例如InputStream 和 OutputStream,但是 Java 8 新增的 Stream 和 Java IO中的 Stream 是完全不同的两个东西,没有半毛钱关系。本文要讲解的 Stream 是能够对集合对象进行各种串行或并发聚集操作,而Java IO流用来处理设备之间的数据传输,它们两者截然不同。
Stream的主要特点有:
- Stream本身并不存储数据,数据是存储在对应的collection(集合)里,或者在需要的时候才生成的。
- Stream不会修改数据源,总是返回新的stream。
- Stream的操作是延迟(lazy)执行的:仅当最终的结果需要的时候才会执行,即执行到终止操作为止。
2、Stream流与传统方式对比
首先先使用传统方式的方法来对集合进行一些操作,代码示例如下:
要求:从集合中遍历出前五个元素,并且过滤掉为“two”的字符串
public class StreamTest {
public static void main(String[] args) {
//创建集合
ArrayList<String> list = new ArrayList<>();
list.add("one");
list.add("two");
list.add("three");
list.add("four");
list.add("five");
list.add("six");
list.add("seven");
//遍历数据,只遍历5个
for (int i = 0; i < 5; i++) {
//过滤掉字符串——two
if (!(list.get(i).contains("two"))) {
System.out.println(list.get(i));
}
}
}
}
我相信像上面这样的代码估计每个Java开发人员分分钟都可以实现。但是呢!有时要处理的逻辑较为再复杂,那么此时代码量就会大量增加,所以再通过特定的条件进行筛选并且将结果输出。这样的代码中或多或少会有缺点的:
- 代码量一多,维护肯定更加困难。可读性也会变差。
- 难以扩展,要修改为并行处理估计会花费很大的精力。
- 每一次操作集合中所有的元素都需要通过循环来遍历。
- 如果需要筛选后的结果,那么还需要定义一个新的集合来存储结果。
下面展示了用 Stream 流来实现相同的功能,代码非常的简洁,即使处理较为复杂的逻辑也非常的方便,因为Stream给我们提供了大量方法。
//使用filter,limit,forEach方法
list.stream().filter(s->!s.contains("two")).limit(4).forEach(System.out::println);
最终两种方式的代码运行结果是一样的:
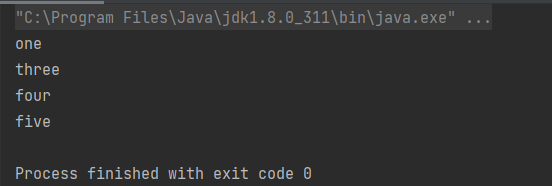
从上面使用 Stream 的情况下我们可以发现是Stream直接连接成了一个串,然后将stream过滤后的结果转为集合并返回输出。而至于转成哪种类型,这由JVM进行推断。整个程序的执行过程像是在叙述一件事,没有过多的中间变量,所以可以减小GC压力,提高效率。所以接下来开始探索Stream的功能吧。
3、Stream的三个步骤
Stream的原理是:将要处理的元素看做一种流,流在管道中传输,并且可以在管道的节点上进行处理,包括有过滤、筛选、去重、排序、映射等等。如果要想操作流,首先需要有一个数据源,可以是数组或者集合。元素在管道中经过中间操作的处理,每次操作都会返回一个新的流对象,方便进行链式操作,但原有的流对象会保持不变。最后由终止操作得到前面处理的结果。所以Stream的所有操作分为这三个部分:创建对象-->中间操作-->终止操作。
- 初始化操作:即创建Stream流的过程,我们要使用Stream流首先的创建流对象。
- 中间操作:一个中间操作链,可以有多个,每次返回一个新的流,它主要对数据源的数据进行处理。注:中间操作是延迟执行的(lazy),意思就是在终止操作开始的时候才中间操作才真正开始执行
- 终止操作,一个终止操作,只能有一个,每次执行完,这个流也就用完了,无法再执行下一个操作,此时会执行中间操作并且产生结果,因此只能放在最后。
Stream 提供的方法非常多,如下图:
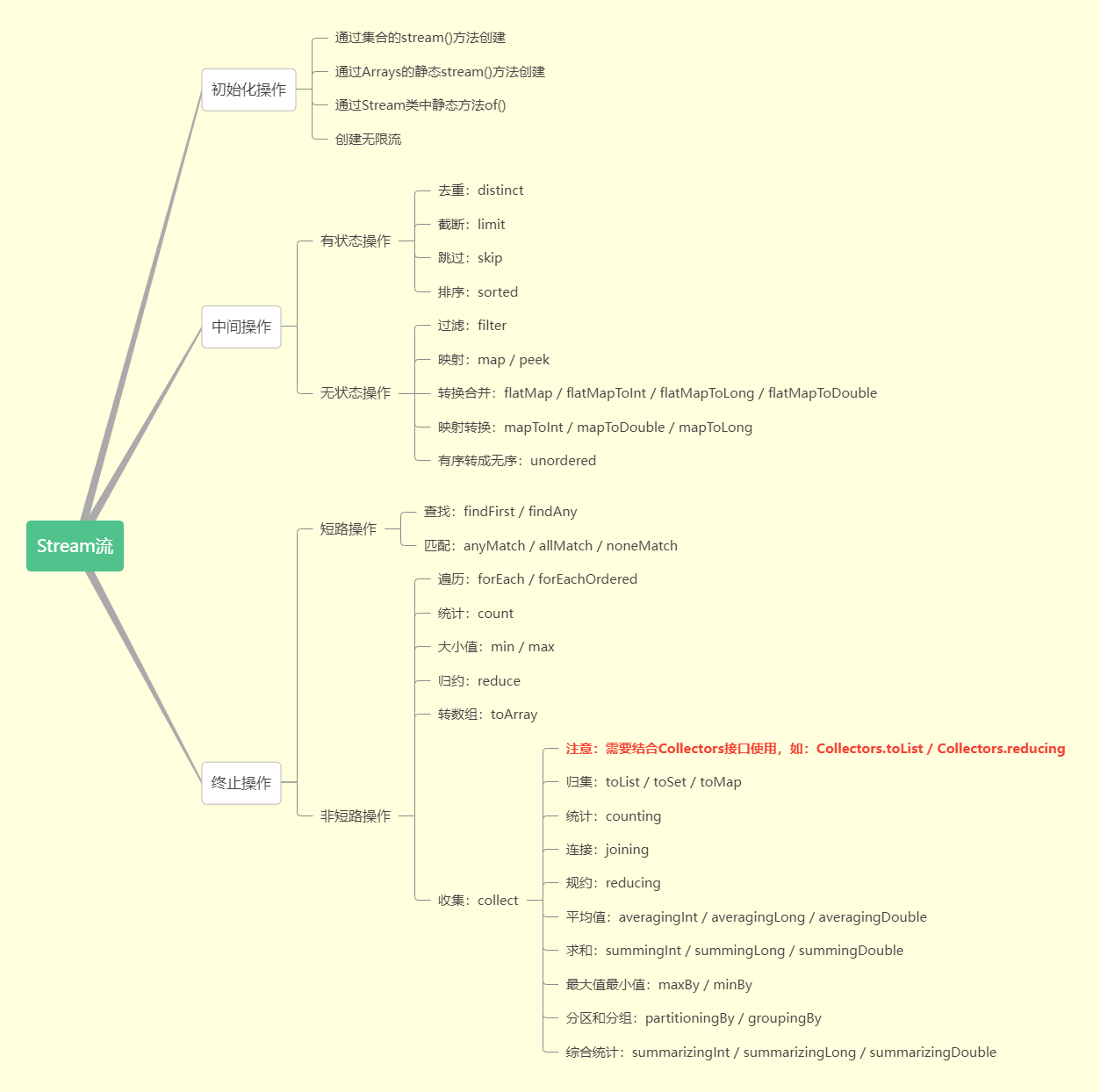
对于中间操作,又可以分为有状态的操作和无状态操作,具体如下:
- 有状态的操作是指当前元素的操作需要等所有元素处理完之后才能进行。
- 无状态的操作是指当前元素的操作不受前面元素的影响。
对于结束操作,又可以分为短路操作和非短路操作,具体如下:
- 短路操作是指不需要处理完全部的元素就可以结束。
- 非短路操作是指必须处理完所有元素才能结束。
4、Stream对象创建
[1]、使用Collection接口的扩展类,其中提供了两个获取流的方法:
default Stream<E> stream():返回一个数据流对象default Stream<E> parallelStream():返回一个并行流对象
//1、方法一:通过Collection
ArrayList<String> list=new ArrayList<>();
//获取顺序流,即有顺序的获取
Stream<String> stream = list.stream();
//获取并行流,即同时取数据,无序
Stream<String> stream1 = list.parallelStream();
[2]、通过数组,使用Arrays中的静态方法stream()获取数组流:
public static <T> Stream<T> stream(T[] array):返回一个流对象
//2、方法二:通过数组
String str[]=new String[]{"A","B","C","D","E"};
Stream<String> stream2 = Arrays.stream(str);
[3]、使用Stream类本身的静态方法of(),通过显式的赋来值创建一个流,它可以接受任意数量的参数:
public static<T> Stream<T> of(T... values):返回一个流
//3、方法三:通过Stream的静态方法of()
Stream<Integer> stream3 = Stream.of(1, 2, 3, 4, 5, 6);
[4]、创建无限流(迭代、生成)
public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f)public static<T> Stream<T> generate(Supplier<T> s)
//4.、方式四:创建无限流(迭代、生成)
//迭代(需要传入一个种子,也就是起始值,然后传入一个一元操作)
Stream.iterate(2, (x) -> x * 2).limit(10).forEach(System.out::println);
//生成(无限产生对象)
Stream.generate(() -> Math.random()).limit(10).forEach(System.out::println);
以上的四种方式学习前三中即可,第四种不常用。除了上面这些额外还有其他创建Stream对象的方式,如Stream.empty():创建一个空的流、Random.ints():随机数流等等。
5、Stream中间操作
中间操作的所有操作会返回一个新的流,它暂时不会修改原始的数据源,因为中间操作是延迟执行的(lazy),并不会立马启动,需要等待终止操作才会执行。意思就是在终止操作开始的时候才中间操作才真正开始执行。中间操作主要有以下方法:

为了更好地举例,先创建一个Employee类,后面会使用该类:
public class Employee implements Serializable {
private static final long serialVersionUID = 4326842796835565390L;
/** 编号 */
private String empNo;
/** 名字 */
private String empName;
/** 年龄 */
private Integer age;
/** 性别 */
private Integer sex;
/** 地址 */
private String address;
/** 薪资 */
private Integer salary;
// 无参、全参、getter、setter、toString、hashCode 省略,请自行添加...
}
下面开始介绍流的中间操作的方法使用。
5.1、有状态操作
有状态的操作是指当前元素的操作需要等所有元素处理完之后才能进行。

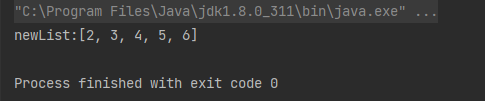
[1]、distinct
去重 - distinct():去除流中重复的元素。
案例 :去掉字符串数组中的重复字符串
String[] array = {"a", "a", "b", "b", "c", "c", "d", "d", "e", "e"};
List<String> newList = Arrays.stream(array).distinct().collect(Collectors.toList());
System.out.println("newList:" + newList);
运行结果:
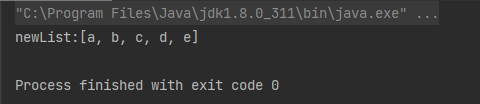
可以发现相同的元素被去除了,但是注意:使用 distinct 需要类中重写hashCode()和 equals()方法才可以使用,上面的String类中默认已经重写了。
[2]、limit
截断 - limit(long maxSize):从流中获取前 n 个元素。
案例:从数组中获取前 4 个元素
String[] array = { "a", "b", "c", "d", "e", "f", "g"};
List<String> newList = Arrays.stream(array).limit(4).collect(Collectors.toList());
System.out.println("newList:" + newList);
运行结果:
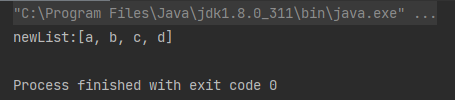
[3]、skip
跳过 - skip(long n):跳过流中前 n 个元素,若流中元素不足 n 个,则返回一个空流。它与 limit(n)互补。
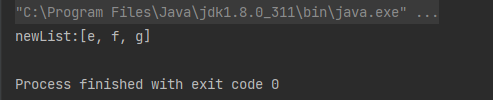
案例 :从数组中获取第 4 个元素之后的元素
String[] array = { "a", "b", "c", "d", "e", "f", "g"};
List<String> newList = Arrays.stream(array).skip(4).collect(Collectors.toList());
System.out.println("newList:" + newList);
运行结果:
[4]、sorted
对流中的数据进行排序。分为默认排序和定制排序。
- sort() - 默认排序:将流中的元素按默认的顺序排序。
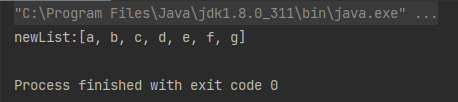
案例:对给定数组进行排序
String[] array = {"e", "b", "f", "d", "a", "g", "c"};
List<String> newList = Arrays.stream(array).sorted().collect(Collectors.toList());
System.out.println("newList:" + newList);
运行结果:
- sorted(Comparator<? super T> comparator) - 定制排序:按提供的比较符进行排序。
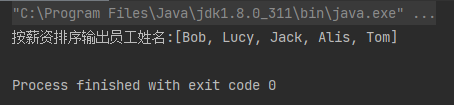
案例1:根据员工的薪资排序,并且输出员工的姓名
List<Employee> employees = new ArrayList<>();
employees.add(new Employee("1", "Jack", 23, 1, "深圳", 12000));
employees.add(new Employee("2", "Lucy", 19, 0, "上海", 7000));
employees.add(new Employee("3", "Tom", 28, 1, "北京", 32000));
employees.add(new Employee("4", "Alis", 24, 0, "纽约", 21000));
employees.add(new Employee("5", "Bob", 18, 1, "华盛顿", 5000));
List<String> nameList = employees.stream()
.sorted(Comparator.comparing(Employee::getSalary))
.map(Employee::getEmpName)
.collect(Collectors.toList());
System.out.println("按薪资排序输出员工姓名:" + nameList);
运行结果:
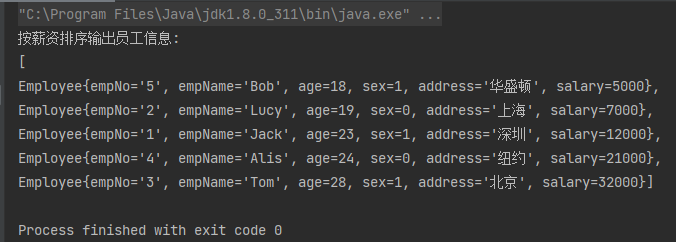
案例2:根据员工薪资排序,并且输出员工信息
List<Employee> employeeList = employees.stream()
.sorted((e1, e2) -> Integer.compare(e1.getSalary().compareTo(e2.getSalary()), 0))
.collect(Collectors.toList());
System.out.println("按薪资排序输出员工信息:\n" + employeeList);
注意这里的toString方法,前面加了个换行符'\n',不然都在一行不便观察结果:
@Override
public String toString() {
return "\nEmployee{" +
"empNo='" + empNo + '\'' +
", empName='" + empName + '\'' +
", age=" + age +
", sex=" + sex +
", address='" + address + '\'' +
", salary=" + salary +
'}';
}
运行结果:
5.2、无状态操作
无状态的操作是指当前元素的操作不受前面元素的影响。

[1]、filter
筛选 - filter(Predicate<? super T> predicate):按照一定的规则校验流中的元素,将符合条件的元素提取到新的流中的操作。即筛选出满足条件的数据。
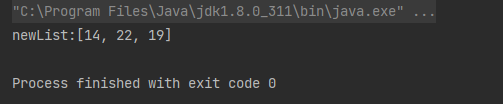
案例1:筛选出数组中大于10的元素
Integer[] array = {4, 9, 3, 14, 5, 22, 19};
List<Integer> newList = Arrays.stream(array).filter(integer -> integer > 10).collect(Collectors.toList());
System.out.println("newList:" + newList);
运行结果:
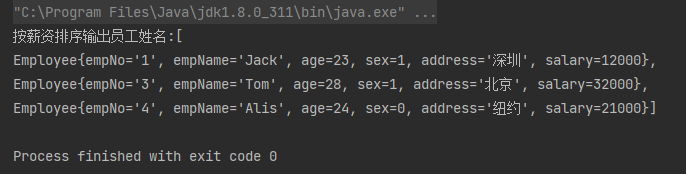
案例2:筛选出年龄大于19岁并且薪资大于等于12000的员工信息
List<Employee> employees = new ArrayList<>();
employees.add(new Employee("1", "Jack", 23, 1, "深圳", 12000));
employees.add(new Employee("2", "Lucy", 19, 0, "上海", 7000));
employees.add(new Employee("3", "Tom", 28, 1, "北京", 32000));
employees.add(new Employee("4", "Alis", 24, 0, "纽约", 21000));
employees.add(new Employee("5", "Bob", 18, 1, "华盛顿", 5000));
List<Employee> employeeList = employees.stream()
.filter(employee -> employee.getAge() > 19)
.filter(employee -> employee.getSalary() >= 12000)
.collect(Collectors.toList());
System.out.println("按薪资排序输出员工姓名:" + employeeList);
运行结果:
[2]、map
映射(转换) - map(Function<? super T, ? extends R> mapper):接收一个函数作为入参,将一个流的元素按照一定的映射规则映射到另一个流中,执行结果组成一个新的 Stream 返回。
案例1:对整数数组每个元素加 3
List<Integer> list = Arrays.asList(5, 2, 3, 1, 4);
List<Integer> newList = list.stream().map(x -> x + 3).collect(Collectors.toList());
System.out.println("newList:" + newList);
运行结果:

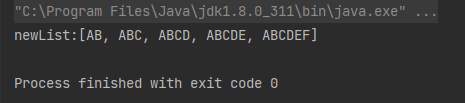
案例2:把字符串数组的每个元素转换为大写:
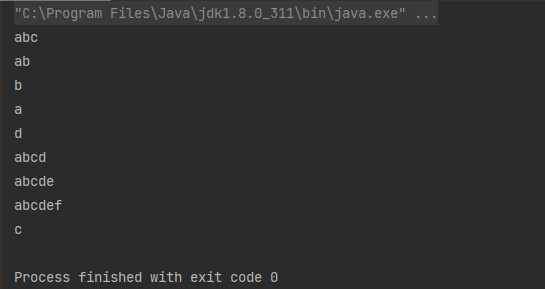
List<String> list = Arrays.asList("ab", "abc", "abcd", "abcde", "abcdef");
List<String> newList = list.stream().map(String::toUpperCase).collect(Collectors.toList());
System.out.println("newList:" + newList);
运行结果:
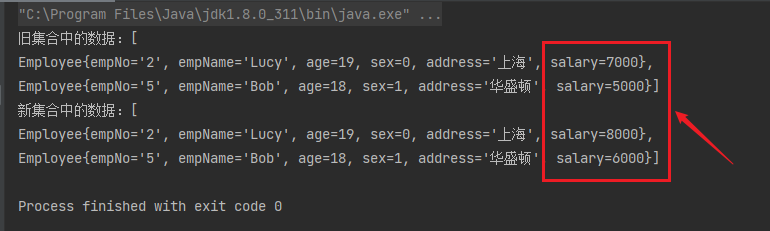
案例3:将薪资低于8000的员工全部增加1000。
List<Employee> employees = new ArrayList<>();
employees.add(new Employee("1", "Jack", 23, 1, "深圳", 12000));
employees.add(new Employee("2", "Lucy", 19, 0, "上海", 7000));
employees.add(new Employee("3", "Tom", 28, 1, "北京", 32000));
employees.add(new Employee("4", "Alis", 24, 0, "纽约", 21000));
employees.add(new Employee("5", "Bob", 18, 1, "华盛顿", 5000));
List<Employee> oldEmployeeList = employees.stream()
.filter(employee -> employee.getSalary() < 8000)
.collect(Collectors.toList());
System.out.println("旧集合中的数据:" + oldEmployeeList);
List<Employee> newEmployeeList = employees.stream()
.filter(employee -> employee.getSalary() < 8000)
.map(employee -> {
employee.setSalary(employee.getSalary() + 1000);
return employee;
}).collect(Collectors.toList());
System.out.println("新集合中的数据:" + newEmployeeList);
运行结果:
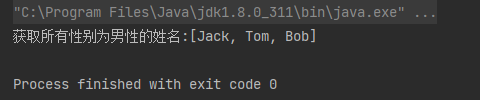
案例4:获取所有性别为男性的姓名
List<Employee> employees = new ArrayList<>();
employees.add(new Employee("1", "Jack", 23, 1, "深圳", 12000));
employees.add(new Employee("2", "Lucy", 19, 0, "上海", 7000));
employees.add(new Employee("3", "Tom", 28, 1, "北京", 32000));
employees.add(new Employee("4", "Alis", 24, 0, "纽约", 21000));
employees.add(new Employee("5", "Bob", 18, 1, "华盛顿", 5000));
List<String> nameList = employees.stream()
.filter(employee -> employee.getSex() == 1)
.map(Employee::getEmpName)
.collect(Collectors.toList());
System.out.println("获取所有性别为男性的姓名:" + nameList);
运行结果:
[3]、mapToXXX
- mapToInt:将元素转换成 int 类型,在 map方法的基础上进行封装。
- mapToLong:将元素转换成 Long 类型,在 map方法的基础上进行封装。
- mapToDouble:将元素转换成 Double 类型,在 map方法的基础上进行封装。
List<String> list = Arrays.asList("ab", "abc", "abcd", "abcde", "abcdef");
int[] newList = list.stream().mapToInt(r -> r.length()).toArray();
System.out.println("newList:" + Arrays.toString(newList));
运行结果:
[4]、peek
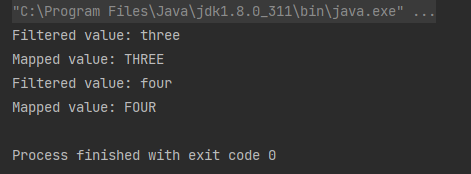
返回由 stream 中元素组成的新 stream,用给定的函数作用在新 stream 的每个元素上。传入的函数是一个 Consumer 类型的,没有返回值,因此并不会改变原 stream 中元素的值。peek 主要用是 debug,可以方便地查看流处理结果是否正确。
案例:过滤出 stream 中长度大于 3 的字符串并转为大写:
Stream.of("one", "two", "three", "four")
.filter(e -> e.length() > 3)
.peek(e -> System.out.println("Filtered value: " + e))
.map(String::toUpperCase)
.peek(e -> System.out.println("Mapped value: " + e))
.collect(Collectors.toList());
运行结果:
注:peek和map有点类似,所以来看一下它们之间的区别:
针对普通类型:
List<String> list = Arrays.asList("ab", "abc", "abcd", "abcde", "abcdef");
List<String> mapList = list.stream().map(String::toUpperCase).collect(Collectors.toList());
System.out.println("mapList:" + mapList);
List<String> list1 = Arrays.asList("ab", "abc", "abcd", "abcde", "abcdef");
List<String> peekList = list1.stream().peek(String::toUpperCase).collect(Collectors.toList());
System.out.println("peekList:" + peekList);
输出结果:
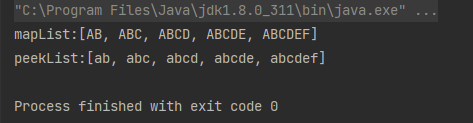
从结果可以看到使用map,流中的元素被转换成大写格式了。但是peek并没有被转换成大写格式。
解析:peek接收一个Consumer,而map接收一个Function。Consumer是没有返回值的,它只是对Stream中的元素进行某些操作,但是操作之后的数据并不返回到Stream中,所以Stream中的元素还是原来的元素。而Function是有返回值的,这意味着对于Stream的元素的所有操作都会作为新的结果返回到Stream中。
针对对象类型:
List<Employee> employees = new ArrayList<>();
employees.add(new Employee("1", "Jack", 23, 1, "深圳", 12000));
employees.add(new Employee("2", "Lucy", 19, 0, "上海", 7000));
employees.add(new Employee("3", "Tom", 28, 1, "北京", 32000));
employees.add(new Employee("4", "Alis", 24, 0, "纽约", 21000));
employees.add(new Employee("5", "Bob", 18, 1, "华盛顿", 5000));
// 简写
employees.stream().peek(employee -> {
employee.setEmpName("AAA");
}).forEach(System.out::println);
// 原生写法(通过看原生写法更好理解)
List<Employee> employeeList = employees.stream().peek(new Consumer<Employee>() {
@Override
public void accept(Employee employee) {
employee.setEmpName("AAA");
}
}).collect(Collectors.toList());
输出结果:
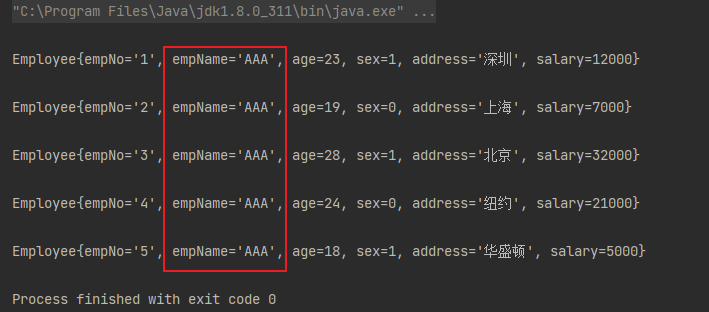
从结果可以看到如果是对象的话,实际的结果会被改变。这是因为我们操作的是对象的属性,只需改变属性值就成功了,并不需要返回,而此时原生的流中对象属性的值已经被改过了。
peek和map方法区别总结:
- 接收的参数不同:peek的入参为Consumer接口,没有返回值,而map的入参为Function接口,有返回值。
- 用途不全一样:peek一般用于打印,值修改等操作,而map一般用于更改流类型,例如List<Employee>转为List<String>
注:一般推荐使用map即可。有些时候IDEA编译会提示你可将map操作转换成peek,但最好不要这么做。
[5]、flatMap
转换合并 - flatMap(Function<? super T, ? extends Stream<? extends R>> mapper):扁平化处理,将流中的每个值都转换成另一个流,然后把所有流组合成一个流并且返回。
它和map有点类似。flatMap在接收到Stream后,会将接收到的Stream中的每个元素取出来放入另一个Stream中,最后将一个包含多个元素的Stream返回。这是用在一些比较特别的场景下,当你的 Stream 是以下这几种结构的时候,需要用到 flatMap方法,用于将原有二维结构扁平化。
Stream<String[]>Stream<Set<String>>Stream<List<String>>
以上这三类结构,通过 flatMap方法,可以将结果转化为 Stream<String>这种形式,方便之后的其他操作。
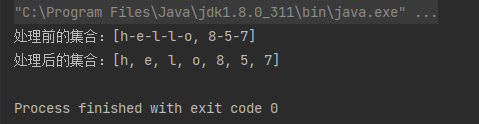
案例1:针对Stream<String[]>举例 -- 把一个字符串数组转成另一个字符串数组:
List<String> list = Arrays.asList("h-e-l-l-o", "8-5-7");
List<String> listNew = list.stream().flatMap(s -> {
// 将每个元素转换成一个stream
String[] split = s.split("-");
Stream<String> s2 = Arrays.stream(split).distinct();
return s2;
}).collect(Collectors.toList());
System.out.println("处理前的集合:" + list);
System.out.println("处理后的集合:" + listNew);
输出结果:
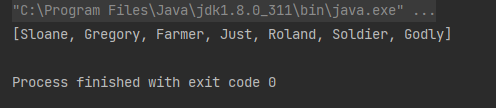
案例2:针对Stream<List<String>>举例 -- 把一个集合类型的集合转成另一个字符串数组:
List<List<String>> lists = new ArrayList<>();
lists.add(Arrays.asList("Sloane", "Gregory"));
lists.add(Arrays.asList("Farmer", "Just", "qq", "Roland"));
lists.add(Arrays.asList("Soldier", "Godly"));
List<String> collect4 = lists.stream().flatMap(Collection::stream)
.filter(str -> str.length() > 2)
.collect(Collectors.toList());
System.out.println(collect4);
输出结果:
[6]、flatMapToXXX
- flatMapToInt:用法参考 flatMap,将元素扁平为 int 类型,在 flatMap方法的基础上进行封装。
- flatMapToLong:用法参考 flatMap,将元素扁平为 Long 类型,在 flatMap方法的基础上进行封装。
- flatMapToDouble:用法参考 flatMap,将元素扁平为 Double 类型,在 flatMap方法的基础上进行封装。
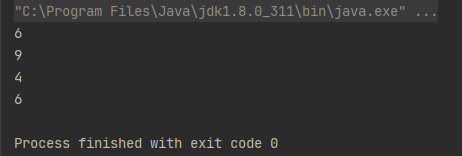
案例1:获取集合中字符串的长度
List<String> list = Arrays.asList("Stream", "IntStream", "List", "Arrays");
list.stream().flatMapToInt(str -> IntStream.of(str.length())).forEach(System.out::println);
输出结果:
案例2:对给定的二维整数数组求和:
int[][] data = {{1,2},{3,4},{5,6}};
IntStream intStream = Arrays.stream(data).flatMapToInt(row -> Arrays.stream(row));
System.out.println(intStream.sum());
输出结果:

[7]、unordered
有序转成无序 - unordered():把一个有序的 Stream 转成一个无序 Stream。注:只在并行流中起作用,而且并行流在处理有序数据结构时,性能会有很大影响。
案例:把一个有序数组转成无序
List<String> list = Arrays.asList("a", "b", "c", "d", "ab", "abc", "abcd", "abcde", "abcdef");
list.parallelStream().unordered().forEach(System.out::println);
运行结果:
6、Stream终止操作
终止操作主要有以下方法如图,下面只介绍一下常用的方法。注意:Stream流只要进行了终止操作后,就不能再次使用了,再次使用得重新创建流。

6.1、短路操作
短路操作是指不需要处理完全部的元素就可以结束。

[1]、findFirst
查找 - findFirst():返回 Stream 中的第一个元素。
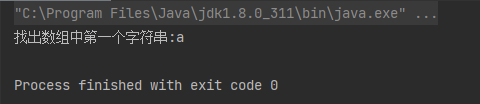
案例 1:找出数组中第一个字符串
String[] array = {"a", "b", "c", "d"};
String str = Arrays.stream(array).findFirst().get();
System.out.println("找出数组中第一个字符串:" + str);
运行结果:
案例 2:找出第一个年龄大于20岁的员工信息
List<Employee> employees = new ArrayList<>();
employees.add(new Employee("1", "Jack", 23, 1, "深圳", 12000));
employees.add(new Employee("2", "Lucy", 19, 0, "上海", 7000));
employees.add(new Employee("3", "Tom", 28, 1, "北京", 32000));
employees.add(new Employee("4", "Alis", 24, 0, "纽约", 21000));
employees.add(new Employee("5", "Bob", 18, 1, "华盛顿", 5000));
Employee employee1 = employees.stream().filter(employee -> employee.getAge() > 20).findFirst().orElse(null);
System.out.println("找出第一个年龄大于20岁的员工信息:" + employee1);
运行结果:

[2]、findAny
查找 - findAny():返回 Stream 中任何一个满足过滤条件的元素。注意:如果是串行情况下,一般都会返回第一个元素,并行情况下就不一定了。
案例:找出任何一个薪资高于 10000 的员工
Employee employee1 = employees.stream().filter(employee -> employee.getAge() > 20).findAny().orElse(null);
System.out.println("找出任何一个薪资高于 10000 的员工:" + employee1);
输出结果:

[3]、anyMatch
匹配 - anyMatch(Predicate<? super T> predicate):返回值为boolean,检查是否存在任意一个满足给定条件的元素。
案例:①、匹配是否存在薪资高于 20000 的员工。②、匹配是否存在薪资低于 3000 的员工。
boolean match1 = employees.stream().anyMatch(employee -> employee.getSalary() > 20000);
System.out.println("匹配是否存在薪资高于 20000 的员工:" + match1);
boolean match2 = employees.stream().anyMatch(employee -> employee.getSalary() < 3000);
System.out.println("匹配是否存在薪资低于 3000 的员工:" + match2);
运行结果:

[4]、allMatch
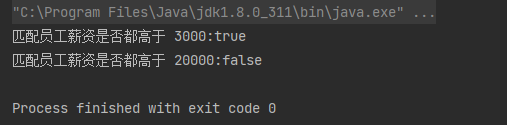
匹配 - allMatch(Predicate<? super T> predicate):返回值为boolean,检查是否至少匹配一个元素满足给定的条件,如果集合是空,则返回 true。
案例:①、匹配员工薪资是否都高于 3000。②、匹配员工薪资是否都高于 20000
boolean match1 = employees.stream().allMatch(employee -> employee.getSalary() > 3000);
System.out.println("匹配员工薪资是否都高于 3000:" + match1);
boolean match2 = employees.stream().allMatch(employee -> employee.getSalary() > 20000);
System.out.println("匹配员工薪资是否都高于 20000:" + match2);
运行结果:
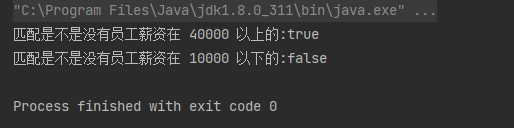
[5]、noneMatch
匹配 - anyMatch(Predicate<? super T> predicate):返回值为boolean,检查是否没有元素能匹配给定的条件,如果集合是空,则返回 true。
案例:①、匹配是不是没有员工薪资在 40000 以上的。②、匹配是不是没有员工薪资在 10000 以下的
boolean match1 = employees.stream().noneMatch(employee -> employee.getSalary() > 40000);
System.out.println("匹配是不是没有员工薪资在 40000 以上的:" + match1);
boolean match2 = employees.stream().noneMatch(employee -> employee.getSalary() < 10000);
System.out.println("匹配是不是没有员工薪资在 10000 以下的:" + match2);
运行结果:
6.2、非短路操作
非短路操作是指必须处理完所有元素才能结束。

[1]、forEach
遍历 - forEach(Consumer<? super T> action):接收Lambda表达式,遍历流中的所有元素。
forEach上面已经用的够多的了这里就不说了。
[2]、forEachOrdered
遍历 - forEachOrdered(Consumer<? super T> action):按照给定集合中元素的顺序输出。主要使用场景是在并行流的情况下,按照给定的顺序输出元素。
案例:用并行流遍历一个数组并按照给定数组的顺序输出结果
List<Integer> array = Arrays.asList(5, 2, 3, 1, 4);
array.parallelStream().forEachOrdered(System.out :: println);
[3]、count / max / min
- count():返回流中总数量
- max(Comparator<? super T> comparator):返回流中最大值
- min(Comparator<? super T> comparator):返回流中最小值
案例1:总数、最大值、最小值
List<Integer> list = Arrays.asList(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
// 总数:count
Long count = list.stream().count();
// 最大值:max
Integer max = list.stream().max(Integer::compareTo).get();
// 最小值:min
Integer min = list.stream().min(Integer::compareTo).get();
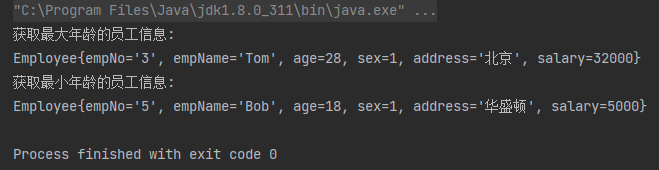
案例2:分别获取年龄最大的员工和年龄最小的员工信息
// 获取最大年龄的员工信息
Optional<Employee> max = employees.stream().max(Comparator.comparingInt(Employee::getAge));
System.out.println("获取最大年龄的员工信息:"+max.get());
// 获取最小年龄的员工信息
Optional<Employee> min = employees.stream().min(Comparator.comparingInt(Employee::getAge));
System.out.println("获取最小年龄的员工信息:"+min.get());
运行结果:
[4]、reduce
归约 - reduce:把一个流中的元素反复结合在一起,然后得到一个值。
Optional <T> reduce(BinaryOperator <T> accumulator):表示根据accumulator条件进行结合T reduce(T identity, BinaryOperator <T> accumulator):表示将identity作为起始值,然后根据accumulator条件进行结合
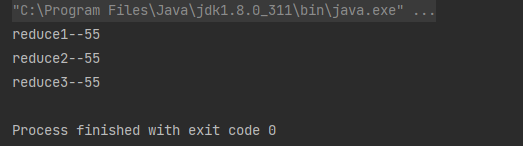
案例:从1累加到10
List<Integer> list = Arrays.asList(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
//1、Optional<T> reduce(BinaryOperator<T> accumulator);
Integer sum1 = list.stream().reduce(Integer::sum).get();
System.out.println("reduce1--" + sum1);
//2、T reduce(T identity, BinaryOperator<T> accumulator);
Integer sum2 = list.stream().reduce(0, Integer::sum);
System.out.println("reduce2--" + sum2);
//3、原生写法
Optional<Integer> sum3 = list.stream().reduce(new BinaryOperator<Integer>() {
@Override
public Integer apply(Integer integer1, Integer integer2) {
return Integer.sum(integer1, integer2);
}
});
System.out.println("reduce3--" + sum3.get());
运行结果:
[5]、toArray
转数组 - toArray() / toArray(IntFunction<A[]> generator):返回包括给定 Stream 中所有元素的数组。
案例:把给定字符串流转化成数组
Stream<String> stream = Stream.of("ab", "abc", "abcd", "abcde", "abcdef");
String[] newArray1 = stream.toArray(str -> new String[5]);
String[] newArray2 = stream.toArray(String[]::new);
Object[] newArray3 = stream.toArray();
[6]、collect
收集 - collect(Collector<? super T, A, R> collector):将流转换为其他形式。它接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法。由于这里主要跟Collectors接口有关,所以下面详细介绍。
7、Collectors的使用
Stream流与Collectors中的方法是非常好的搭档,通过组合来以更简单的方式来实现更加强大的功能,Collectors实用类提供了很多静态方法。

[1]、toList():将流转换成List。
案例:获取所有员工名称集合列表
List<Employee> employees = new ArrayList<>();
employees.add(new Employee("1", "Jack", 23, 1, "深圳", 12000));
employees.add(new Employee("2", "Lucy", 19, 0, "上海", 7000));
employees.add(new Employee("3", "Tom", 28, 1, "北京", 32000));
employees.add(new Employee("4", "Alis", 24, 0, "纽约", 21000));
employees.add(new Employee("5", "Bob", 18, 1, "华盛顿", 5000));
List<String> nameList = employees.stream().map(Employee::getEmpName).collect(Collectors.toList());
System.out.println("将流转换成List:" + nameList);
[2]、toSet():将流转换为Set。
案例:归纳不同薪资列表
List<Employee> employees = new ArrayList<>();
employees.add(new Employee("1", "Jack", 23, 1, "深圳", 12000));
employees.add(new Employee("2", "Lucy", 19, 0, "上海", 7000));
employees.add(new Employee("3", "Tom", 28, 1, "北京", 32000));
employees.add(new Employee("4", "Alis", 24, 0, "纽约", 21000));
employees.add(new Employee("5", "Bob", 18, 1, "华盛顿", 5000));
Set<Integer> salarySet = employees.stream().map(Employee::getSalary).collect(Collectors.toSet());
System.out.println("将流转换成Set:" + salarySet);
[3]、toMap():将流转换为Map。
案例:获取员工姓名对应的薪资集合
employees.add(new Employee("1", "Jack", 23, 1, "深圳", 12000));
employees.add(new Employee("2", "Lucy", 19, 0, "上海", 7000));
employees.add(new Employee("3", "Tom", 28, 1, "北京", 32000));
employees.add(new Employee("4", "Alis", 24, 0, "纽约", 21000));
employees.add(new Employee("5", "Bob", 18, 1, "华盛顿", 5000));
Map<String, Integer> toMap = employees.stream().collect(Collectors.toMap(Employee::getEmpName, Employee::getSalary));
System.out.println("将流转换成Map:" + toMap);
[4]、toCollection():将流转换为其他类型的集合。
TreeSet<String> toTreeSet = employees.stream().map(Employee::getEmpName).collect(Collectors.toCollection(TreeSet::new));
System.out.println("将流转换为其他类型的集合:" + toTreeSet);
[5]、counting():统计元素个数。
Long count = employees.stream().collect(Collectors.counting());
System.out.println("元素个数:" + count);
[6]、averagingInt() / averagingDouble() / averagingLong():求平均数。这三个方法都可以求平均数,不同之处在于传入得参数类型不同,但是返回值都为Double。
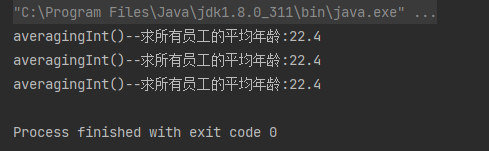
案例:求所有员工的平均年龄
/**
* Collectors.averagingInt()
* Collectors.averagingDouble()
* Collectors.averagingLong()
* 求平均数
*/
// 求所有员工的平均年龄
Double avgAge1 = employees.stream().collect(Collectors.averagingInt(employee -> employee.getAge()));
System.out.println("averagingInt()--求所有员工的平均年龄:" + avgAge1);
Double avgAge2 = employees.stream().collect(Collectors.averagingDouble(employee -> employee.getAge()));
System.out.println("averagingInt()--求所有员工的平均年龄:" + avgAge2);
Double avgAge3 = employees.stream().collect(Collectors.averagingLong(employee -> employee.getAge()));
System.out.println("averagingInt()--求所有员工的平均年龄:" + avgAge3);
运行结果:
[7]、summingDouble() / summingDouble() / summingLong():求和。这三个方法都可以求和,不同之处在于传入得参数类型不同,返回值为Integer, Double, Long。
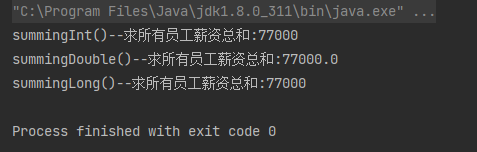
案例:求所有员工薪资总和。
/**
* Collectors.summingInt()
* Collectors.summingDouble()
* Collectors.summingLong()
* 求和
*/
// 求所有员工薪资总和。
Integer integer = employees.stream().collect(Collectors.summingInt(employee -> employee.getAge()));
System.out.println("summingInt()--求所有员工薪资总和:" + integer);
Double aDouble3 = employees.stream().collect(Collectors.summingDouble(employee -> employee.getAge()));
System.out.println("summingDouble()--求所有员工薪资总和:" + aDouble3);
Long aLong1 = employees.stream().collect(Collectors.summingLong(employee -> employee.getAge()));
System.out.println("summingLong()--求所有员工薪资总和:" + aLong1);
运行结果:
[8]、maxBy() / minBy():求最大值和最小值。
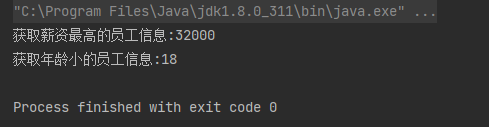
案例:①、获取薪资最高的员工信息。②、获取年龄小的员工信息
// 获取薪资最高的员工信息。
Optional<Integer> collect1 = employees.stream().map(Employee::getSalary).collect(Collectors.maxBy(Integer::compare));
System.out.println("获取薪资最高的员工信息:"+collect1.get());
// 获取年龄小的员工信息
Optional<Integer> collect2 = employees.stream().map(Employee::getAge).collect(Collectors.minBy(Integer::compare));
System.out.println("获取年龄小的员工信息:"+collect2.get());
运行结果:
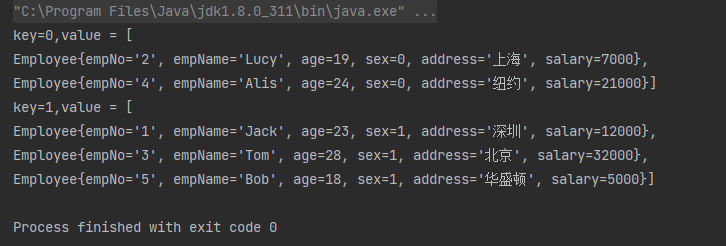
[9]、groupingBy():分组 ,返回一个map。
案例1:根据性别分组获取员工信息
List<Employee> employees = new ArrayList<>();
employees.add(new Employee("1", "Jack", 23, 1, "深圳", 12000));
employees.add(new Employee("2", "Lucy", 19, 0, "上海", 7000));
employees.add(new Employee("3", "Tom", 28, 1, "北京", 32000));
employees.add(new Employee("4", "Alis", 24, 0, "纽约", 21000));
employees.add(new Employee("5", "Bob", 18, 1, "华盛顿", 5000));
// 根据性别分组获取员工信息
Map<Integer, List<Employee>> map = employees.stream().collect(Collectors.groupingBy(Employee::getSex));
Set<Map.Entry<Integer, List<Employee>>> entrySet = map.entrySet();
for (Map.Entry<Integer, List<Employee>> entry : entrySet) {
System.out.println("key=" + entry.getKey() + ",value = " + entry.getValue());
}
运行结果:
其中Collectors.groupingBy()还可以实现多级分组,如下:
案例2:根据性别分组然后得出每组的员工数量
//根据性别分组然后得出每组的员工数量,使用重载的groupingBy方法,第二个参数是分组后的操作
Map<String, Long> stringLongMap = employees.stream().collect(Collectors.groupingBy(Employee::getEmpName, Collectors.counting()));
System.out.println("groupingBy()多级分组-根据性别分组然后得出每组的员工数量:"+stringLongMap);
运行结果:

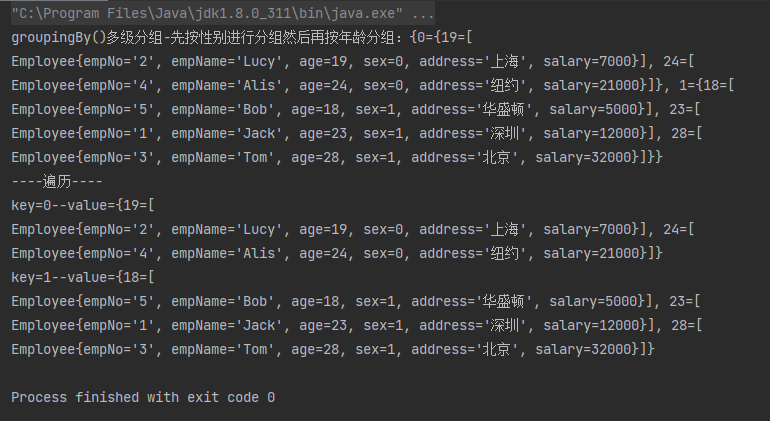
案例3:先按性别进行分组然后再按年龄分组
//先按性别进行分组然后再按年龄分组
Map<Integer, Map<Integer, List<Employee>>> integerMapMap = employees.stream().collect(Collectors.groupingBy(Employee::getSex, Collectors.groupingBy(Employee::getAge)));
System.out.println("groupingBy()多级分组-先按性别进行分组然后再按年龄分组:" + integerMapMap);
System.out.println("----遍历----");
//遍历
Iterator<Map.Entry<Integer, Map<Integer, List<Employee>>>> iterator = integerMapMap.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, Map<Integer, List<Employee>>> entry = iterator.next();
System.out.println("key=" + entry.getKey() + "--value=" + entry.getValue());
}
运行结果:
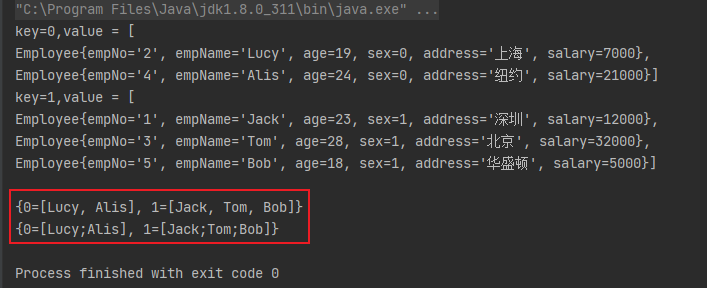
补充:分组之后我们获取的结果是一个对象的集合,但是如果有时候我们只需要对象中的某一个字段的数据呢,当然我们可以直接通过遍历的方式获取,但是Java也给我们提供了解决方案——Collectors.mapping()。
// 根据性别分组获取员工信息
Map<Integer, List<Employee>> map = employees.stream().collect(Collectors.groupingBy(Employee::getSex));
Set<Map.Entry<Integer, List<Employee>>> entrySet = map.entrySet();
for (Map.Entry<Integer, List<Employee>> entry : entrySet) {
System.out.println("key=" + entry.getKey() + ",value = " + entry.getValue());
}
System.out.println();
// 根据性别分组,并且只获取员工的名字
Map<Integer, List<String>> collect = employees.stream().collect(Collectors.groupingBy(Employee::getSex, Collectors.mapping(Employee::getEmpName, Collectors.toList())));
System.out.println(collect);
// 根据性别分组,并且只获取员工的名字,更换拼接方式
Map<Integer, String> collect1 = employees.stream().collect(Collectors.groupingBy(Employee::getSex, Collectors.mapping(Employee::getEmpName, Collectors.joining(";", "[", "]"))));
System.out.println(collect1);
运行结果:
[10]、partitioningBy():分区 ,返回两个map。按true和false分成两个区。
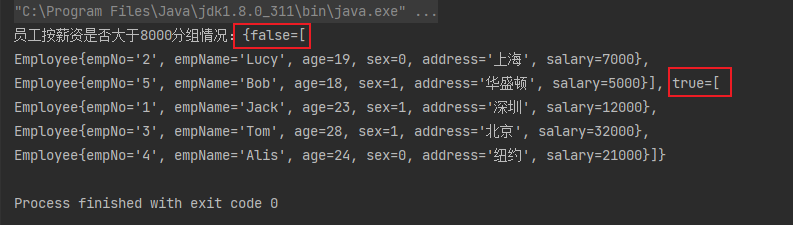
案例:将员工按薪资是否高于8000分为两部分
List<Employee> employees = new ArrayList<>();
employees.add(new Employee("1", "Jack", 23, 1, "深圳", 12000));
employees.add(new Employee("2", "Lucy", 19, 0, "上海", 7000));
employees.add(new Employee("3", "Tom", 28, 1, "北京", 32000));
employees.add(new Employee("4", "Alis", 24, 0, "纽约", 21000));
employees.add(new Employee("5", "Bob", 18, 1, "华盛顿", 5000));
// 案例:将员工按薪资是否高于8000分为两部分
Map<Boolean, List<Employee>> part = employees.stream().collect(Collectors.partitioningBy(x -> x.getSalary() > 8000));
System.out.println("员工按薪资是否大于8000分组情况:" + part);
运行结果:
[11]、joining():拼接。按特定字符将数据拼接起来。
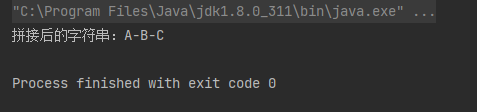
案例1:将字符串用 - 拼接
List<String> list = Arrays.asList("A", "B", "C");
String string = list.stream().collect(Collectors.joining("-"));
System.out.println("拼接后的字符串:" + string);
运行结果:
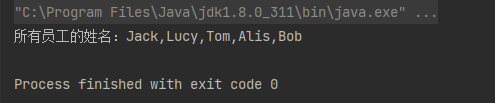
案例2:将所有员工的姓名用逗号分隔
String names = employees.stream().map(employee -> employee.getEmpName()).collect(Collectors.joining(","));
System.out.println("所有员工的姓名:" + names);
运行结果:
[12]、summarizingInt / summarizingLong / summarizingDouble:综合统计。返回的结果包含了总数,最大值,最小值,总和,平均值。
List<Integer> list = Arrays.asList(5, 2, 3, 1, 4);
IntSummaryStatistics statistics = list.stream().collect(Collectors.summarizingInt(r -> r));
System.out.println("综合统计结果:" + statistics.toString());
运行结果:

[13]、reducing:规约。前面已经介绍过了,这里的规约支持更强大的自定义规约
案例:数组中每个元素加 1 后求总和
List<Integer> list = Arrays.asList(5, 2, 3, 1, 4);
int listSum = list.stream().collect(Collectors.reducing(0, x -> x + 1, (sum, b) -> sum + b));
System.out.println("数组中每个元素加 1 后总和:" + listSum);
输出结果:

8、结束语
Java8中的Stream提供的功能非常强大,用它们来操作集合会让我们用更少的代码,更快的速度遍历出集合。而且在java.util.stream包下还有个类Collectors,它和stream是好非常好的搭档,通过组合来以更简单的方式来实现更加强大的功能。虽然上面介绍的都是Stream的一些基本操作,但是只要大家勤加练习就可以灵活使用,很快的可以运用到实际应用中。
拓展:Stream流的原理
这是我在微信公众看到的,觉得写的挺好的。
参考资料:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· 因为Apifox不支持离线,我果断选择了Apipost!