表、栈和队列
抽象数据类型(abstract data type, ADT)是带有一组操作的一些对象的集合。对于集合ADT, 可以有像添加(add)、删除(remove)以及包含(contain)这样一些操作。
ArrayList:插入和 删除的花费存在潜在开销。最坏的情况下,在位置0的插入,首先需要将整个数组后移一个位置以空出空间来,而删除第一个元素则需要将表中的所有元素前移一个位置,因此这两种操作最坏的情况是O(N)。
优势: 查询高效(可以直接find数组的index)
缺陷:插入删除开销大(需要将全部数组移位)
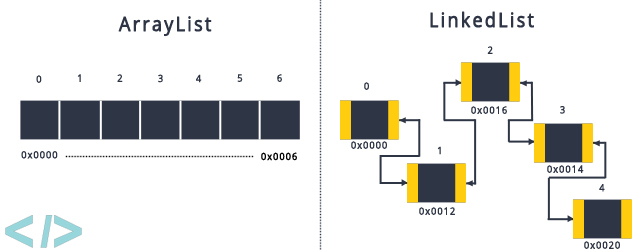
因此,为了避免插入和删除的线性开销,就引入了不连续存储,增删不需要整体移动的链表。
链表(LinkedList):链表由一系列节点组成,这些节点不必在内存中相连。每一个节点均含有表元素和包含该元素后继元的节点的链(Link)。称其为next链。最后一单元的next链引用null。
删除 (remove)方法可以通过修改一个next引用来实现。插入(insert)方法需要使用new操作符从系统取得一个新节点,再修改next引用。
优势: 查询效率低(需要从头开始遍历)
缺陷:插入删除高效(不需要全盘移位)
*删除最后一项比较复杂,因为必须找出指向最后节点的项,把它的next链改成null,然后在更新持有最后节点的链。
for循环和迭代器Iterator对比:
采用ArrayList对随机访问比较快,而for循环中的get()方法,采用的即是随机访问的方法,因此在ArrayList里,for循环较快
采用LinkedList则是顺序访问比较快,iterator中的next()方法,采用的即是顺序访问的方法,因此在LinkedList里,使用iterator较快
从数据结构角度分析,for循环适合访问顺序结构,可以根据下标快速获取指定元素.而Iterator 适合访问链式结构,因为迭代器是通过next()和Pre()来定位的.可以访问没有顺序的集合.
而使用 Iterator 的好处在于可以使用相同方式去遍历集合中元素,而不用考虑集合类的内部实现(只要它实现了 java.lang.Iterable 接口),如果使用 Iterator 来遍历集合中元素,一旦不再使用 List 转而使用 Set 来组织数据,那遍历元素的代码不用做任何修改,如果使用 for 来遍历,那所有遍历此集合的算法都得做相应调整,因为List有序,Set无序,结构不同,他们的访问算法也不一样.(还是说明了一点遍历和集合本身分离了)
栈(stack)是限制插入和删除只能在一个位置上进行的表,该位置是表的末端,叫作栈的顶(top)。对栈的基本操作有push(进栈)和pop(出栈),前者相当于插入,后者则是删除最后出入元素。栈又是又叫作LIFO(后进先出)表。(实现计算的过程)

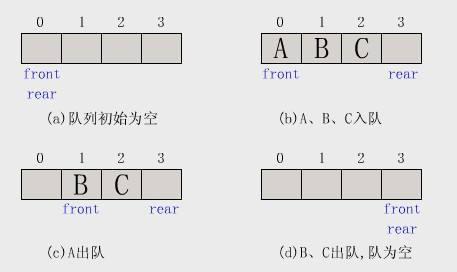
队列(queue)也是表。队列的基本操作是enqueue(入队),它是在表的末端(rear)插入一个元素,和dequeue(出队),它是删除在表的开头的元素。
队列操作:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号