
spark
批处理步骤
1构建spark环境 2数据处理 3存储计算结果
hbase key value数据库
hive 结构化数据库
实现spark一致性语义 需要spark自己管理kafka的offset
redis 存offset 再把offset取出来

hmaster 协调者用于通信 hregionserver 工作者 dataNode 存储的部分



在conf文件中连接hadoop和zookeeper




spark streaming具备天然的eos ss checkpoint机制来保证kafka数据不丢失
tail -f 等同于--follow=descriptor,根据文件描述符进行追踪,当文件改名或被删除,追踪停止
tail -F 等同于--follow=name --retry,根据文件名进行追踪,并保持重试,即该文件被删除或改名后,如果再次创建相同的文件名,会继续追踪
tailf 等同于tail -f -n 10(貌似tail -f或-F默认也是打印最后10行,然后追踪文件),与tail -f不同的是,如果文件不增长,它不会去访问磁盘文件,所以tailf特别适合那些便携机上跟踪日志文件,因为它减少了磁盘访问,可以省电
最好用tail-F

把任务提交到spark上 分为几种模式 mesos(Apache项目 国外用的多) standalone(spark自己实现的资源调度平台) yarn(国内用的多)
为什么用yarn hadoop flink spark都用的是yarn 方便集中管理
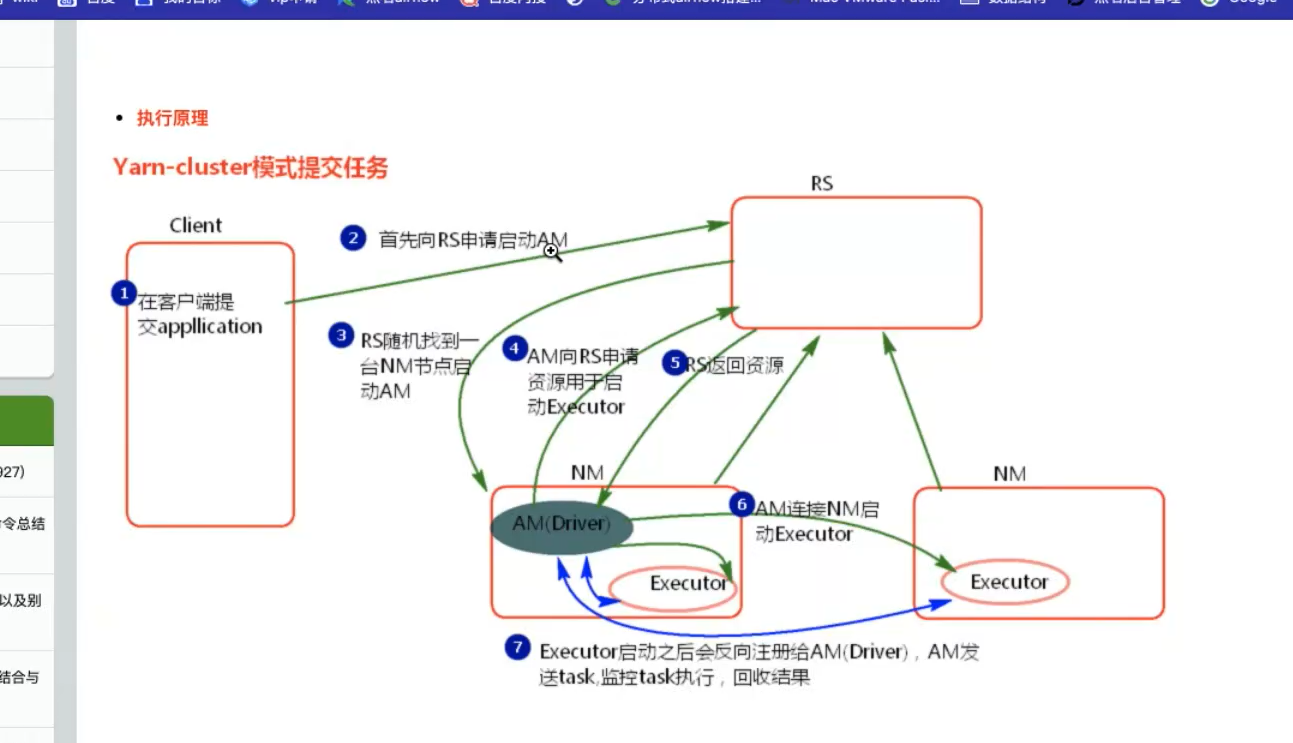
spark计算平台 yarn资源调度平台
client端在driver里面 的 am applicationMaster spark和yarn之间的代理人 rs rresourcemanager

先把hadoop下载下来

vim core-site.yml
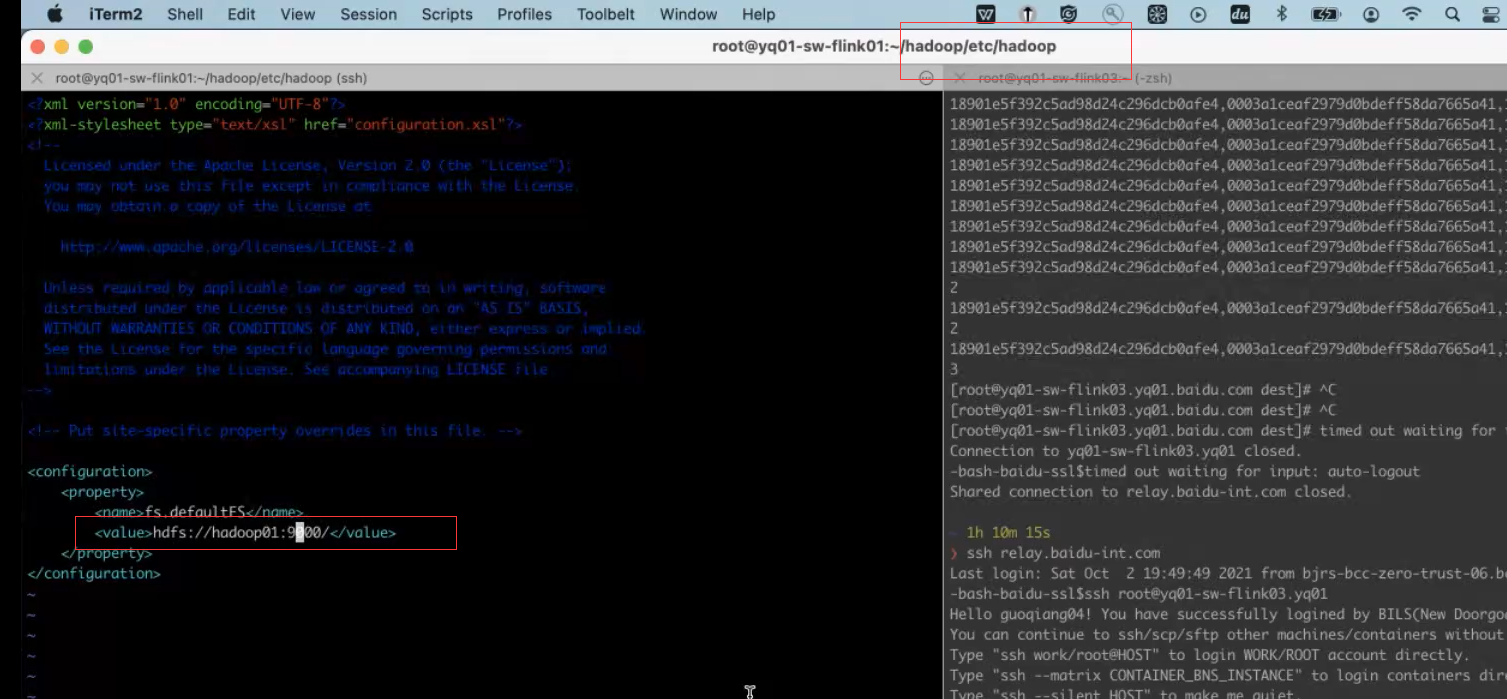

通过xsync hadoop把hadoop分发到另外两个集群上

启动
./sbin/start-dfs.sh
再通过start-all.sh全部启动起来
hdfs 分布式的文件系统

resource manager nodeManager yarn中的节点 以 进程的形式存在
secondarynamenode hdfs中做元数据同步的节点
datanode namenode hdfs里面的节点
hadoop安装好就意味着yarn安装好
master和worker都启动好了代表spark启动成功 从节点也是一样
spark 也可以通过xsync 同步集群 再通过start-all.sh启动

s
临时环境


context


flume 日志收集 消息中间件 kafka 缓存 流式处理 消费收集的gps数据 储存 redis
flume 将日志输送到kafka的工具

flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力 。
Client:Client生产数据,运行在一个独立的线程。
Event: 一个数据单元,消息头和消息体组成。(Events可以是日志记录、 avro 对象等。)
Flow: Event从源点到达目的点的迁移的抽象。
Agent: 一个独立的Flume进程,包含组件Source、 Channel、 Sink。(Agent使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含
多个sources和sinks。)
Source: 数据收集组件。(source从Client收集数据,传递给Channel)
Channel: 中转Event的一个临时存储,保存由Source组件传递过来的Event。(Channel连接 sources 和 sinks ,这个有点像一个队列。)(Memory Channel、JDBC Chanel、File Channel,etc)
Sink: 从Channel中读取并移除Event, 将Event传递到FlowPipeline中的下一个Agent(如果有的话)(Sink从Channel收集数据,运行在一个独立线程。)
cd /conf
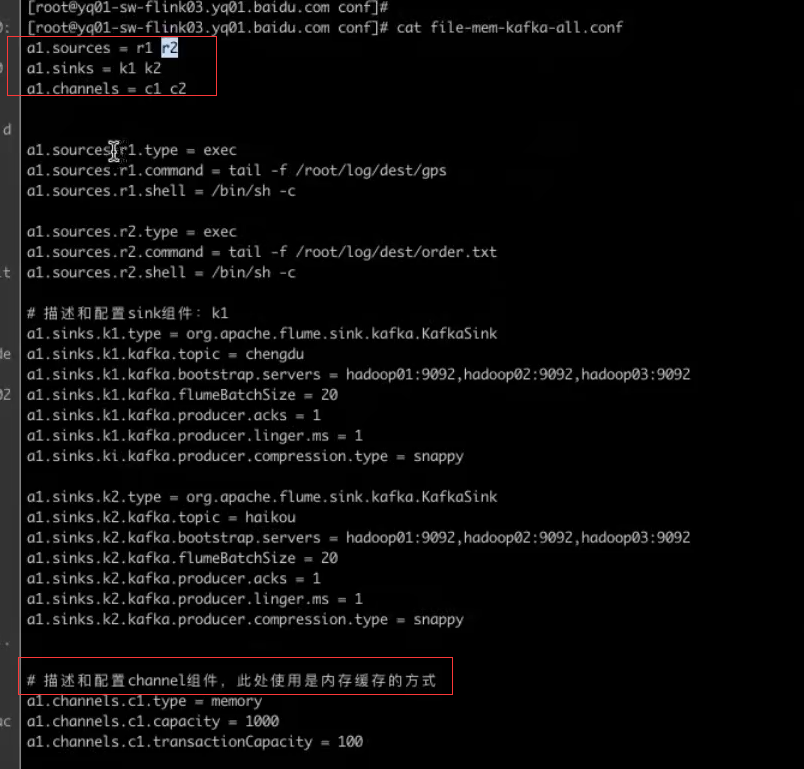
启动flume


将gps文件(1.4g)实时放到另一个文件中 flume实时监听到有哪些文件过来
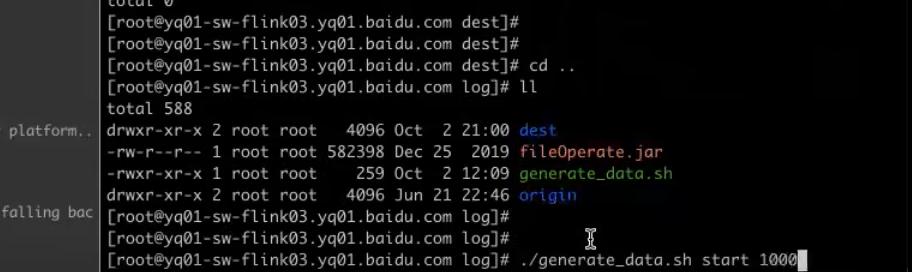

发送到kafka的问题

1 producer 设置ack=-1 broker清理日志 避免follower没有跟上leader的数据
2pid topic partition --seqnum 键值对 seqnum没变,传到broker的数据不变 如果pid在重启之后product id改变了 则为一条新数据
producer broker sparkstreaming consumer
(用1+2)
消费者 --保证事务不丢失,在broker--consumer之后消费

broker还没有到consumer消息就丢失了

checkpoint没有从kafka拿数据 checkpoint有从checkpoint拿数据
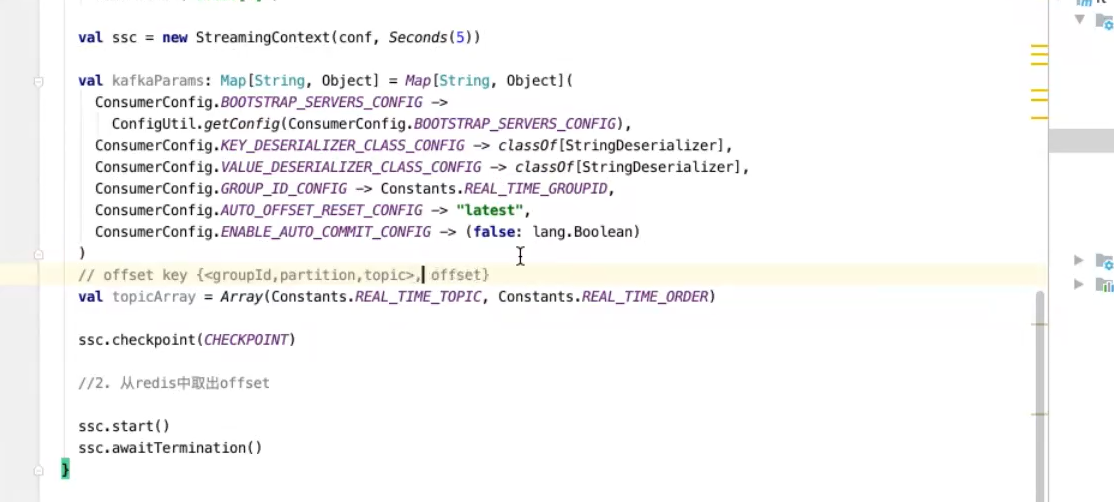
app
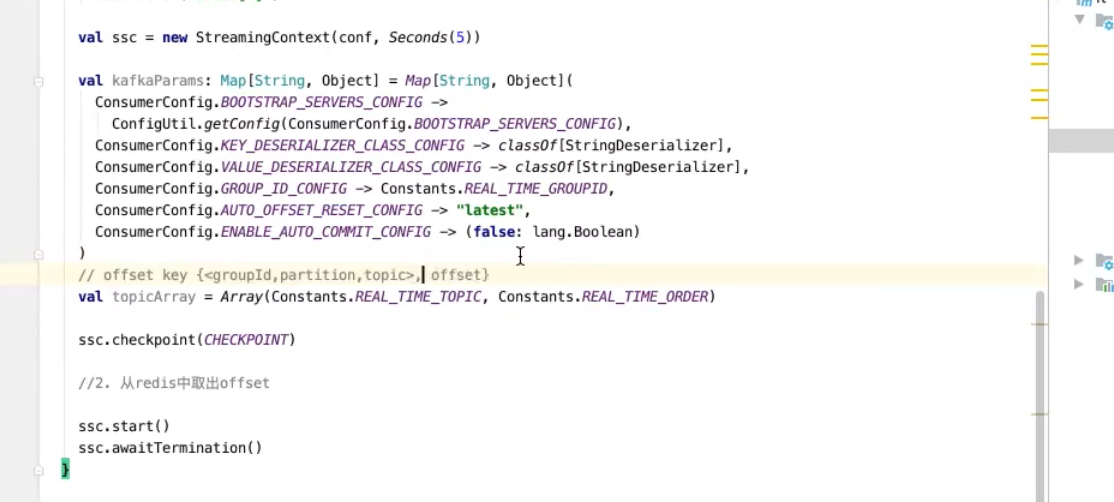

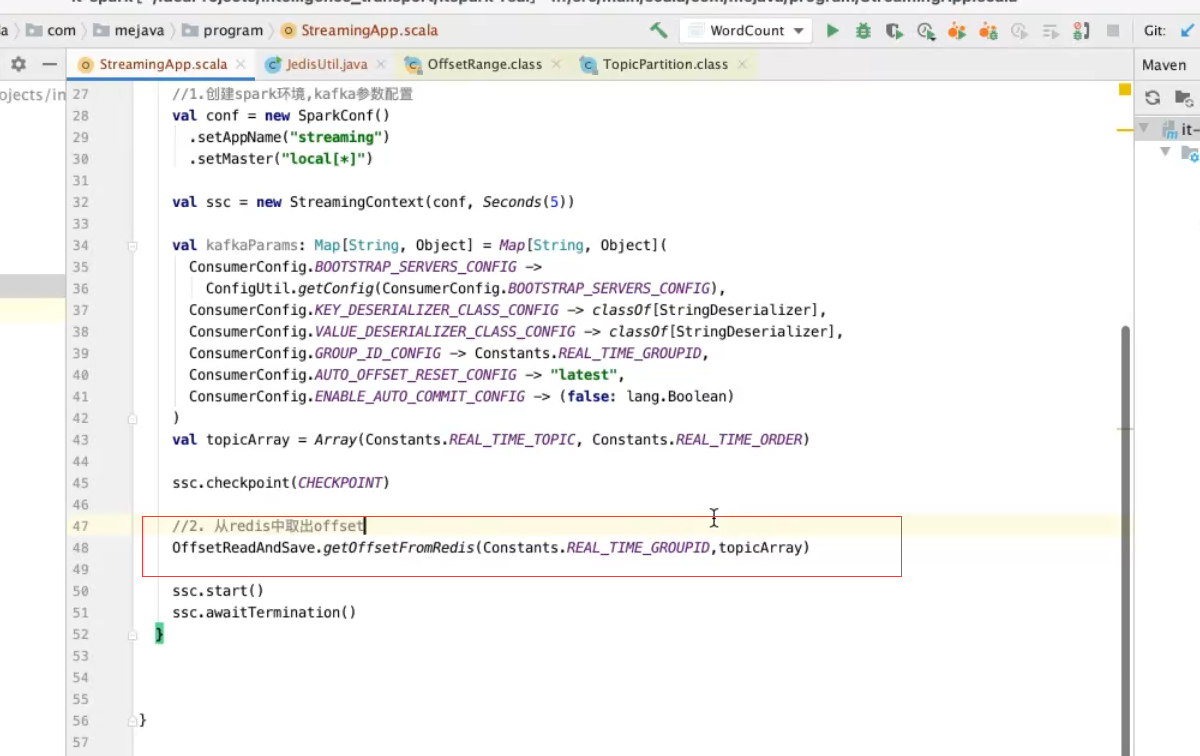
拿到redis数据后 kafka初始化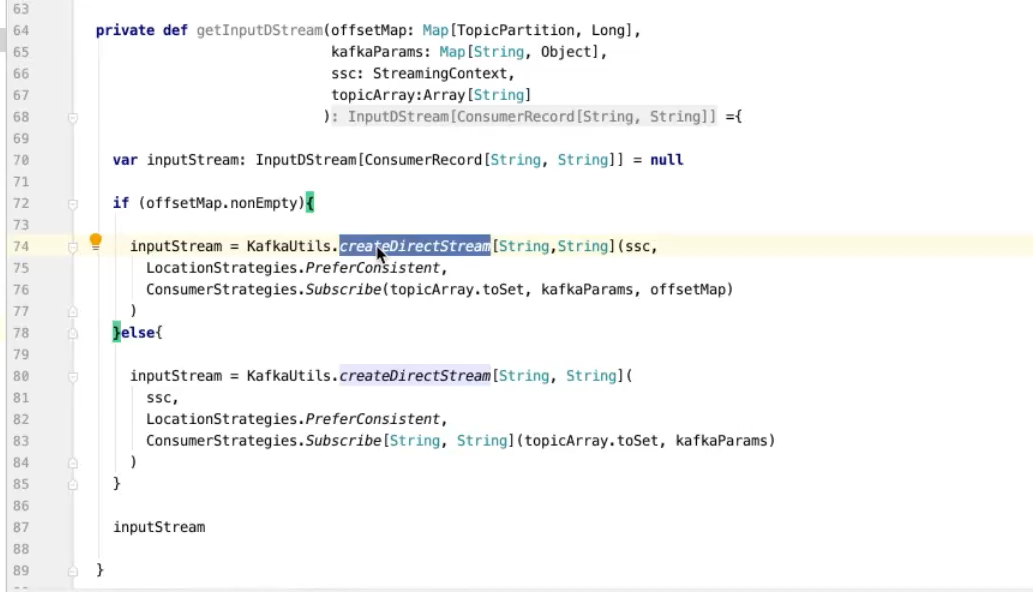
----

-----------------
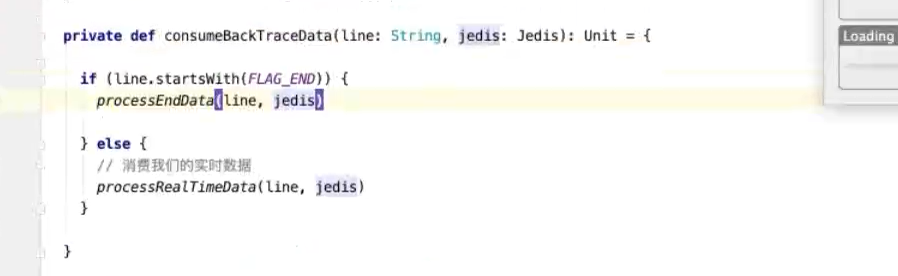

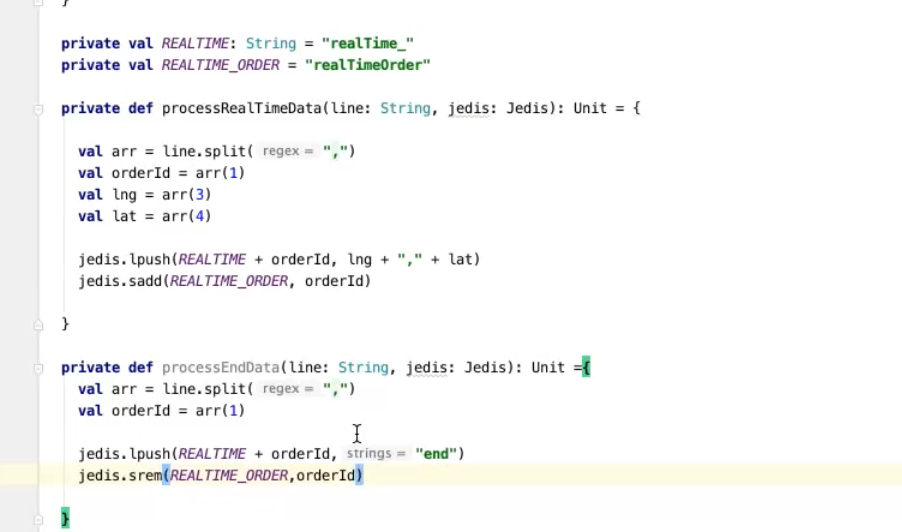
------------------------------------------------------------------------
编译出现问题 -版本问题



