
出行项目1----scala简介

数据生产--传输到日志平台--数据存储--数据计算--数据应用

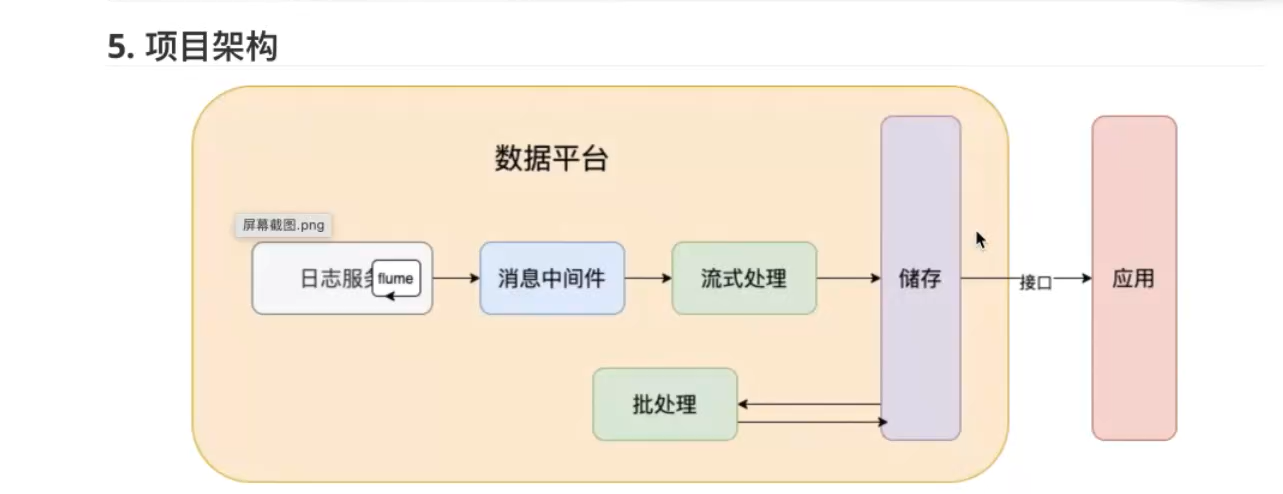
flume 日志服务 消息中间件 kafka 流式处理 flink和spark streaming 批处理 spark 储存 hdfs和hadoop
scala语法
* `val`定义的是**不可重新赋值**的变量(值不可修改)
* `var`定义的是**可重新赋值**的变量(值可以修改)
方法
说明
- 参数列表的参数类型不能省略
- 返回值类型可以省略,由scala编译器自动推断
- 返回值可以不写return,默认就是{}块表达式的值
注意
* 如果定义递归方法,不能省略返回值类型
#### **方法的参数**
默认参数:在定义方法时可以给参数定义一个默认值。
带名参数:在调用方法时,可以指定参数的名称来进行调用。
集合类
https://zhuanlan.zhihu.com/p/25512292
数组-变长数组(声明泛型)
- ArrayBuffer是变长数组,类似java的ArrayList
val arr2 = ArrayBuffer[Int]()也是使用的apply方法构建对象




scala是sparrk的 前身
mapreduce启动的是进程,spark启动的是线程
sparrk属于微批次处理 flink属于真正的流计算
MapReduce慢,慢在磁盘存储 还有shuffle优化
在java里面调用一些shell脚本 会缩短连接时间
linux执行的时候,kernel套着shell,shell上层是jvm,jvm上层是java程序
调shell的时候 损失的是kernel调shell 以及jvm调kernel api的过程
直接调c语言(原生) 要损失的是compile和link的过程
------------------------------------------------
spark部分
spark是在Hadoop基础上的改进,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架, Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
spark是基于内存计算框架,计算速度非常之快,但是它仅仅只是涉及到计算,并没有涉及到数据的存储,后期需要使用spark对接外部的数据源,比如hdfs。
相对于hadoop来说 运行速度提高100倍
spark比mapreduce快的2个主要原因
**基于内存**
mapreduce任务后期再计算的时候,每一个job的输出结果会落地到磁盘,后续有其他的job需要依赖于前面job的输出结果,这个时候就需要进行大量的磁盘io操作。性能就比较低。
spark任务后期再计算的时候,job的输出结果可以保存在内存中,后续有其他的job需要依赖于前面job的输出结果,这个时候就直接从内存中获取得到,避免了磁盘io操作,性能比较高
**进程与线程**
mapreduce任务以进程的方式运行在yarn集群中,比如程序中有100个MapTask,一个task就需要一个进程,这些task要运行就需要开启100个进程。
spark任务以线程的方式运行在进程中,比如程序中有100个MapTask,后期一个task就对应一个线程,
这里就不在是进程,这些task需要运行,这里可以极端一点:只需要开启1个进程,在这个进程中启动100个线程就可以了。
进程中可以启动很多个线程,而开启一个进程与开启一个线程需要的时间和调度代价是不一样。 开启一个进程需要的时间远远大于开启一个线程。
spark框架不在是一个简单的框架,可以把spark理解成一个**生态系统**,它内部是包含了很多模块,基于不同的应用场景可以选择对应的模块去使用
**sparksql**
通过sql去开发spark程序做一些离线分析
**sparkStreaming**
主要是用来解决公司有实时计算的这种场景
**Mlib**
它封装了一些机器学习的算法库
**Graphx** 图计算
兼容性
spark程序就是一个计算逻辑程序,这个任务要运行就需要计算资源(内存、cpu、磁盘),哪里可以给当前这个任务提供计算资源,就可以把spark程序提交到哪里去运行
**standAlone**
它是spark自带的集群模式,整个任务的资源分配由spark集群的老大Master负责
**yarn**
可以把spark程序提交到yarn中运行,整个任务的资源分配由yarn中的老大ResourceManager负责
**mesos**
它也是apache开源的一个类似于yarn的资源调度平台。
spark与yarn结合
https://www.cnblogs.com/LHWorldBlog/p/8414342.html
- **Driver**
它会执行客户端写好的main方法,它会构建一个名叫SparkContext对象
- **Task**
spark任务是以task线程的方式运行在worker节点对应的executor进程中
spark是调用了yarn的接口,将任务提交给yarn来执行计算,实际的计算逻辑就是我们driver中的代码
生产环境
in/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--executor-memory 10G \s
examples/jars/spark-examples_2.12-3.1.1.jar \
10
##参数说明
--class:指定包含main方法的主类
--master:指定spark集群master地址
--executor-memory:指定任务在运行的时候需要的每一个executor内存大小
--total-executor-cores: 指定任务在运行的时候需要总的cpu核数

