
redis
------------恢复内容开始------------
aof
redis 数据持久化 aof方式 - 我俩绝配 - 博客园 (cnblogs.com)




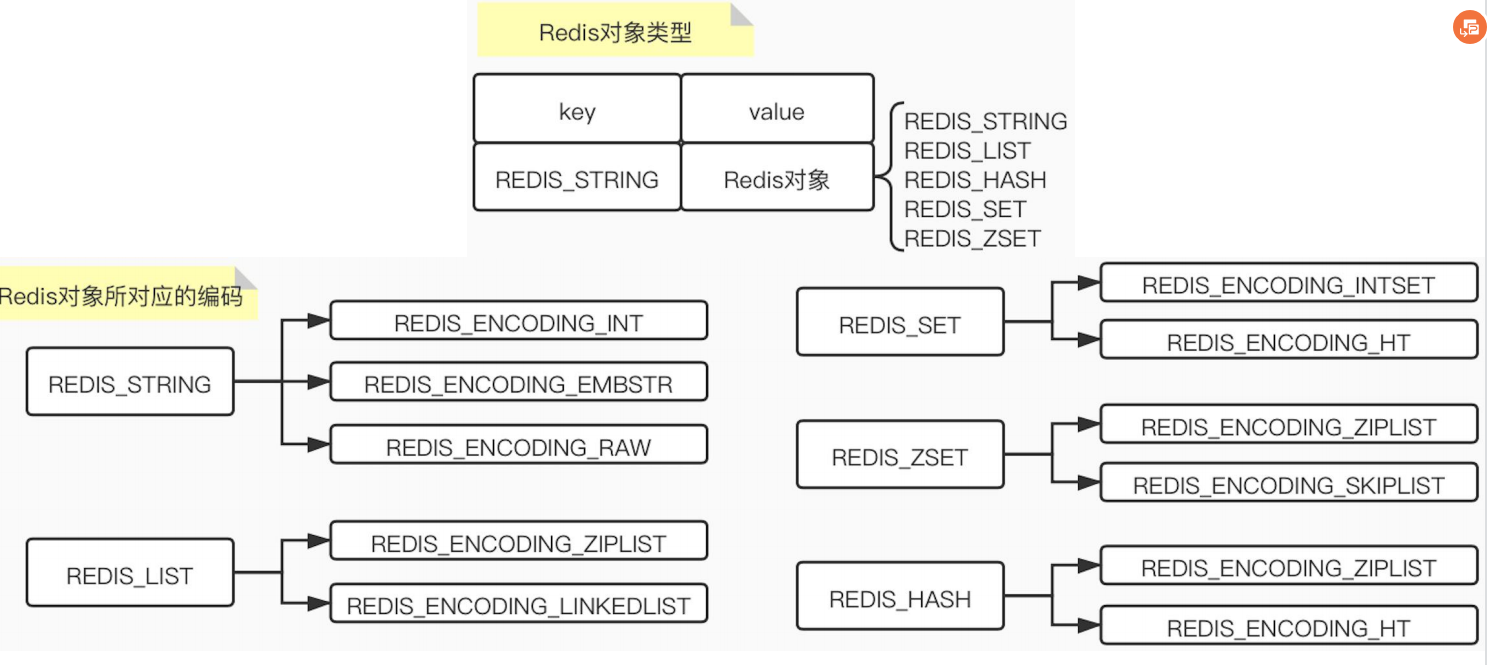
对象类型:5种类型
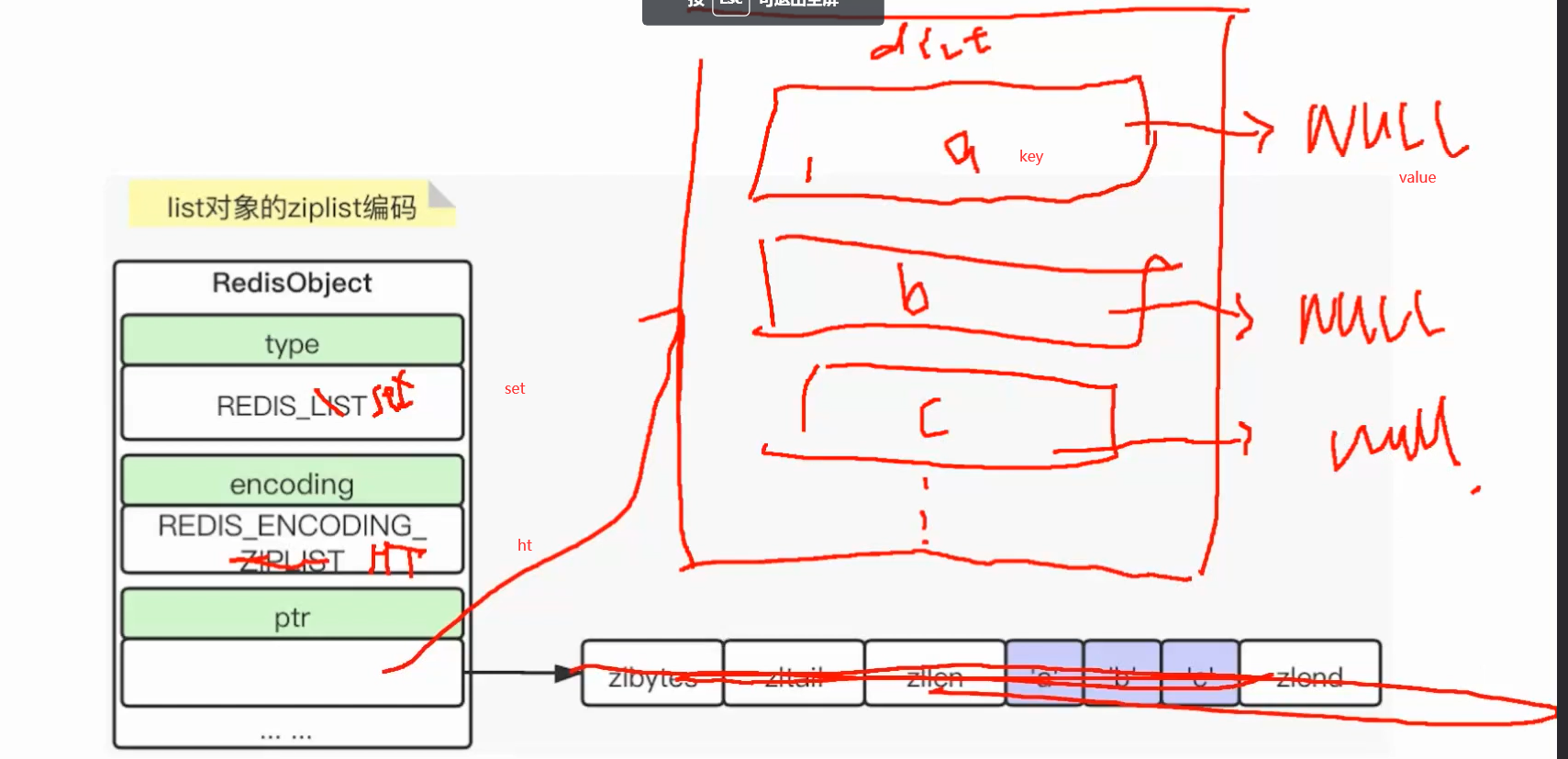
对象编码:类型对应的数据结构 上面5中类型基本对应两种以上的数据结构
指针:通过指针指向int string 压缩表 跳表

-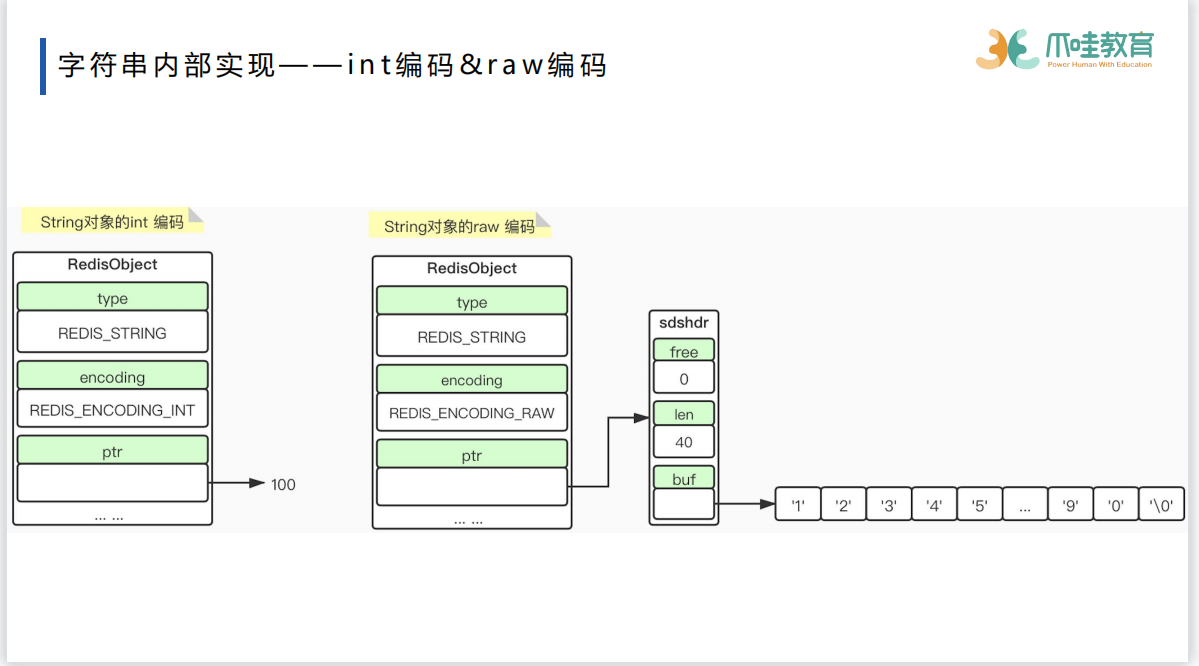
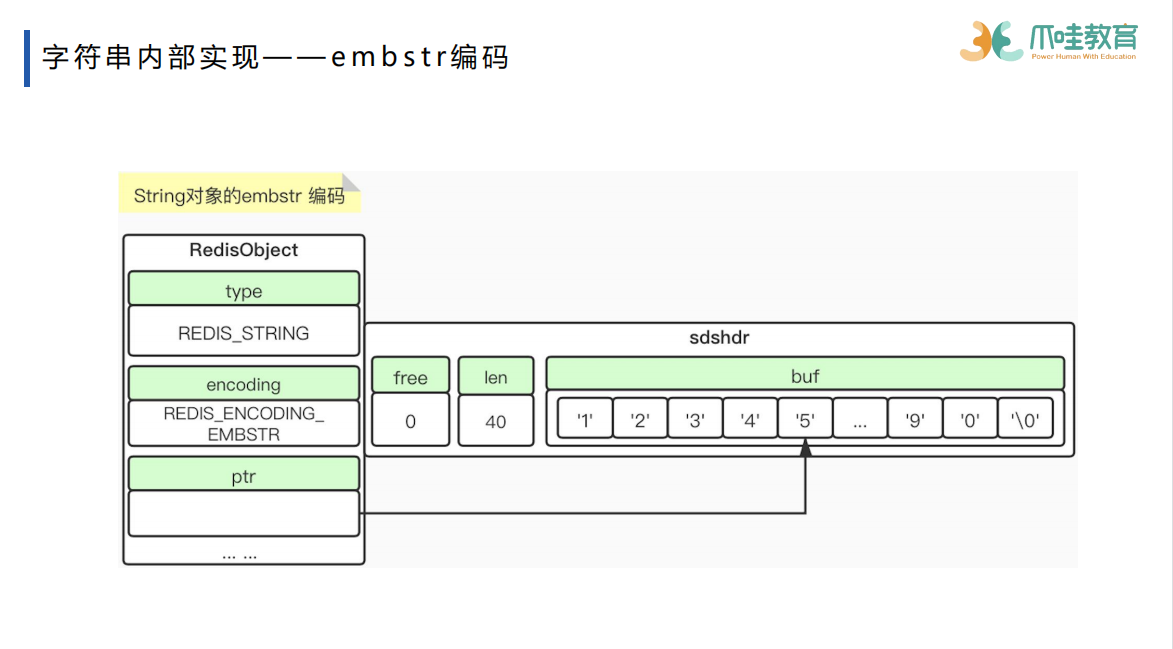
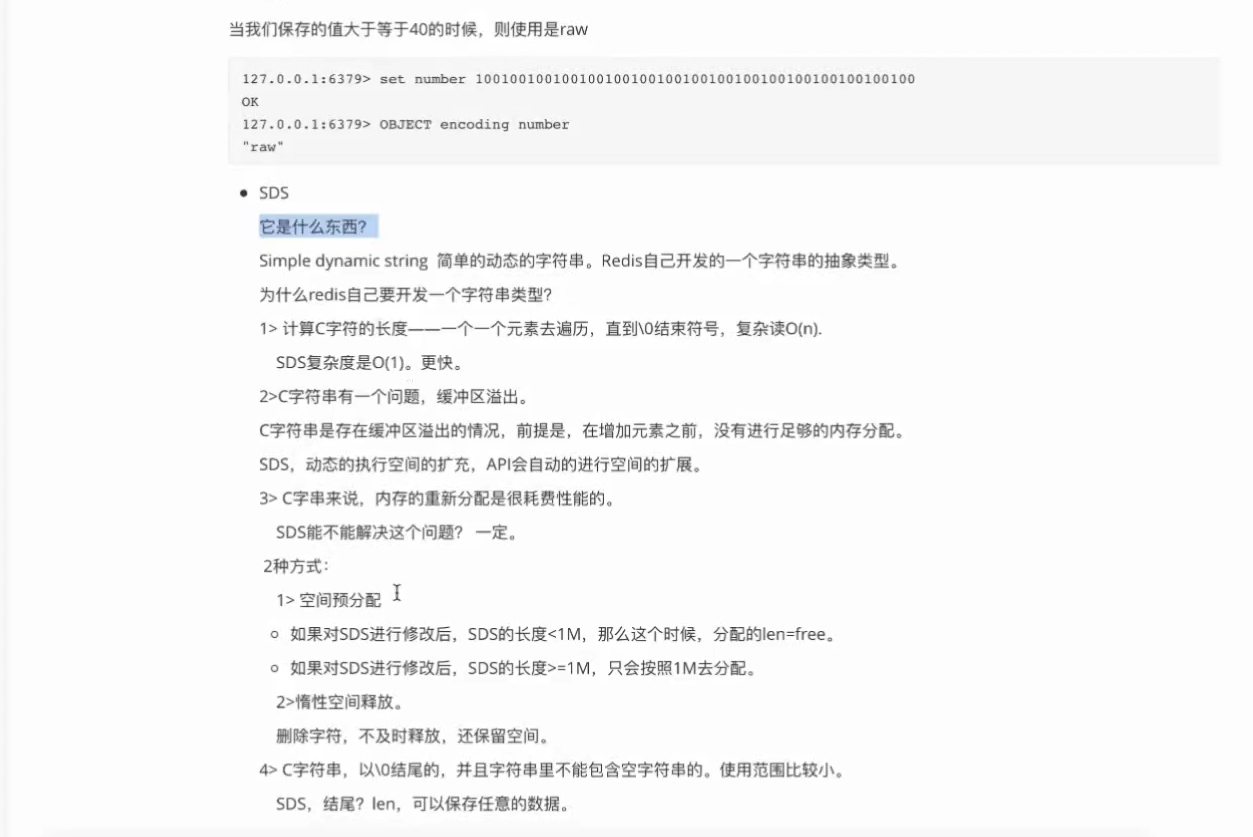
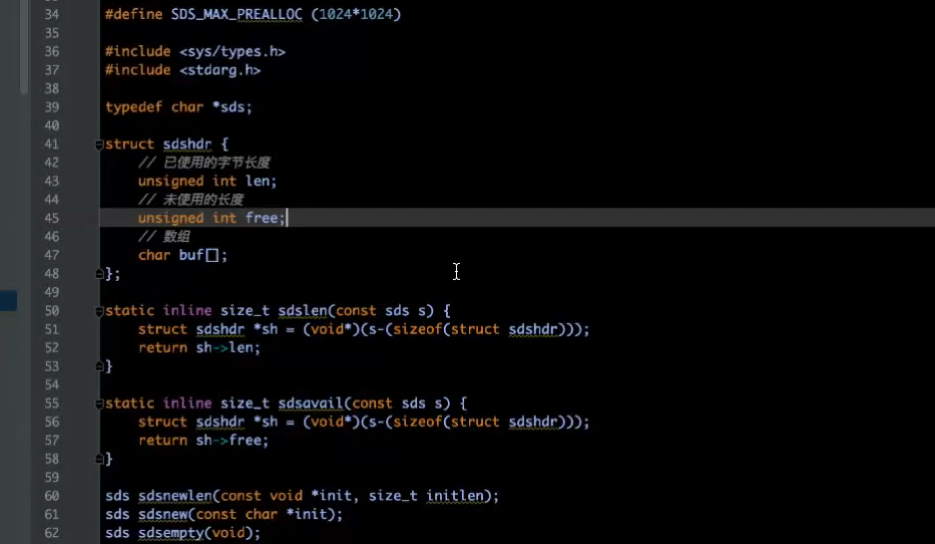
row编码与embstr编码是sds embstr直接指向字符数组,row需要指针

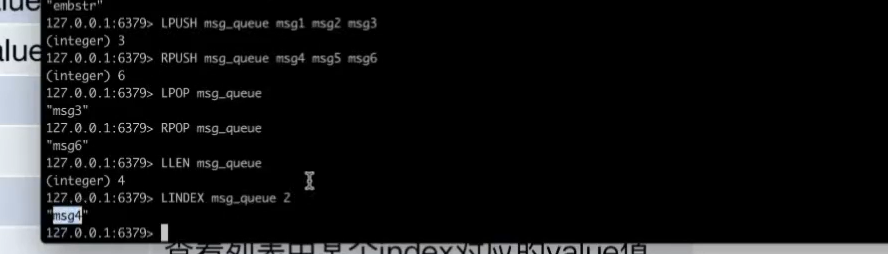
list
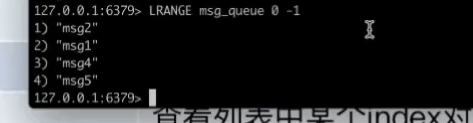
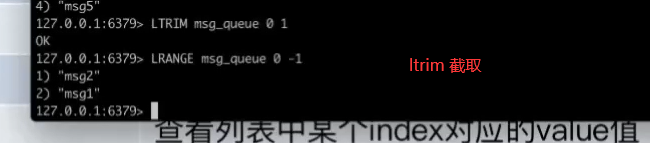
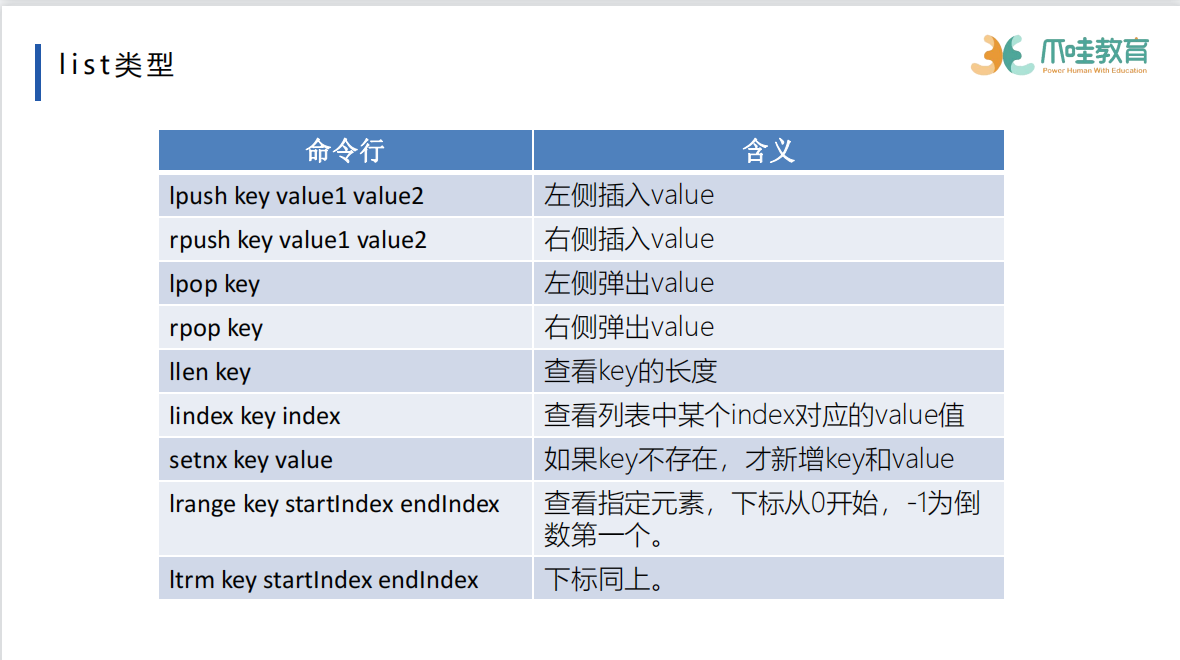
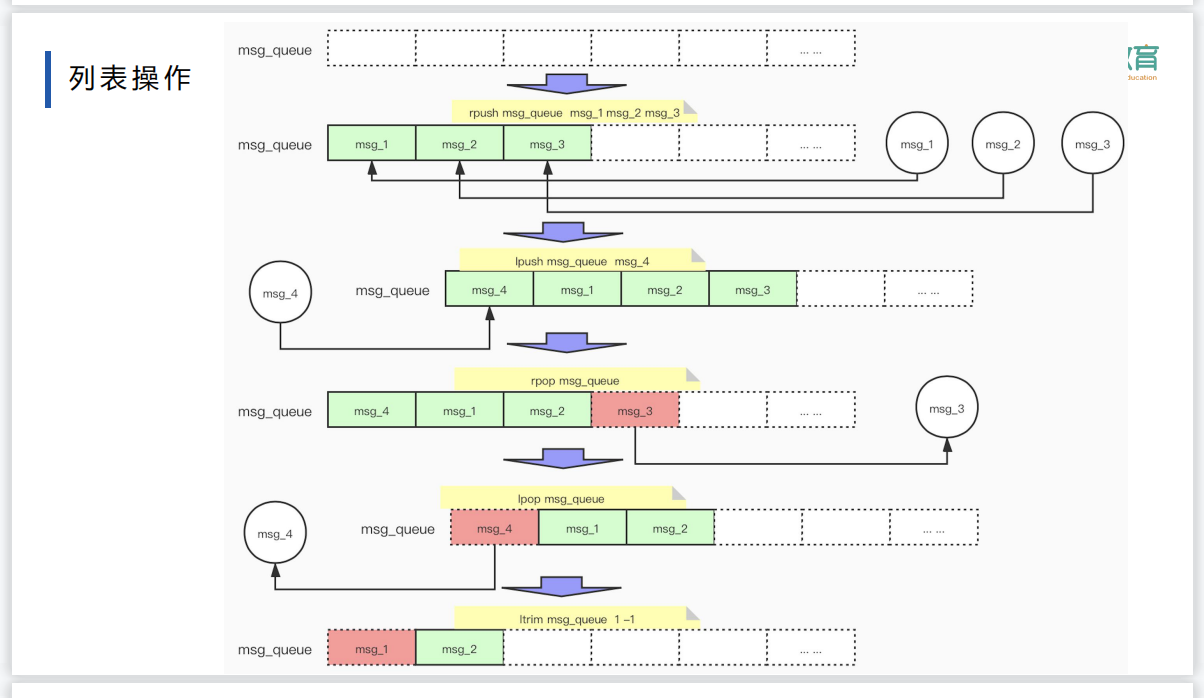
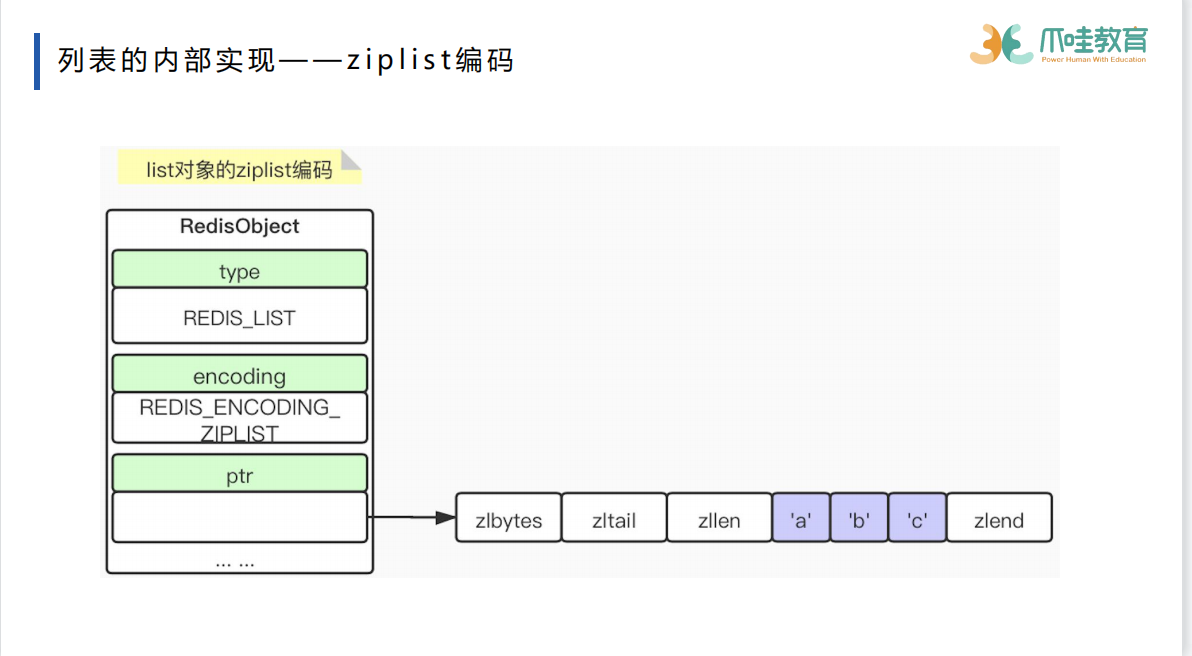
压缩的方式来进行快速的访问
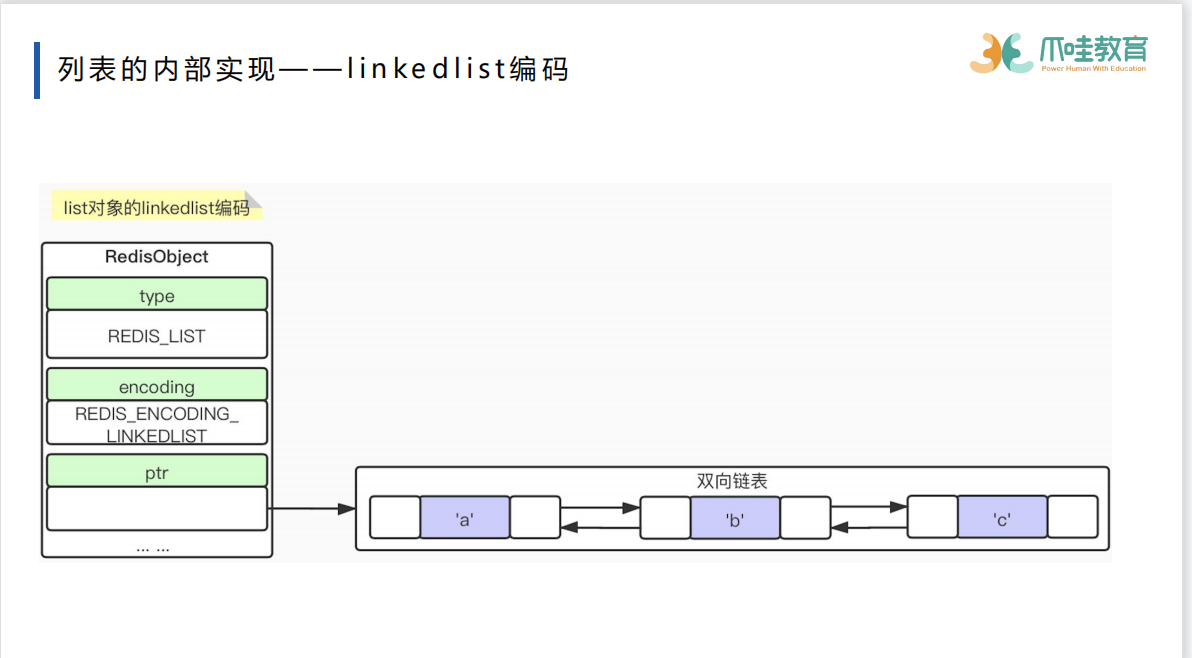
双向列表 前后指针作为元素的关联
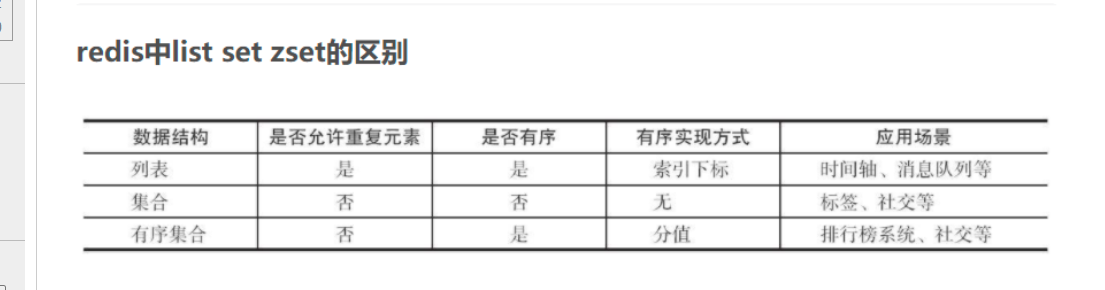
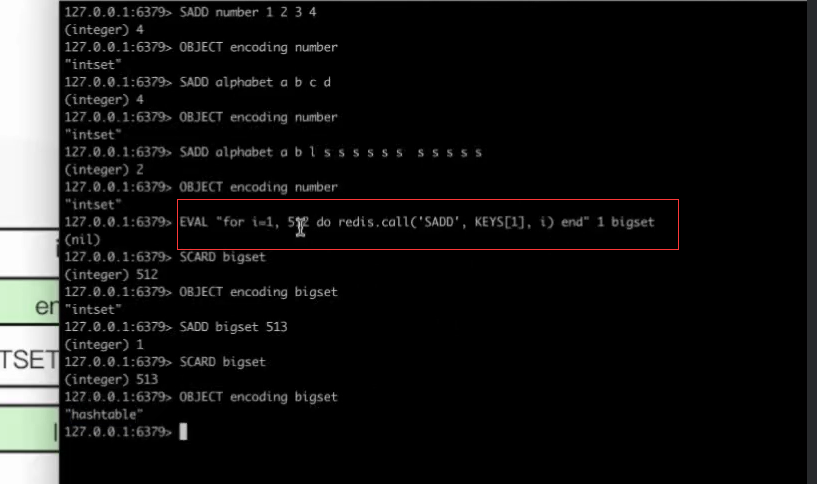
set
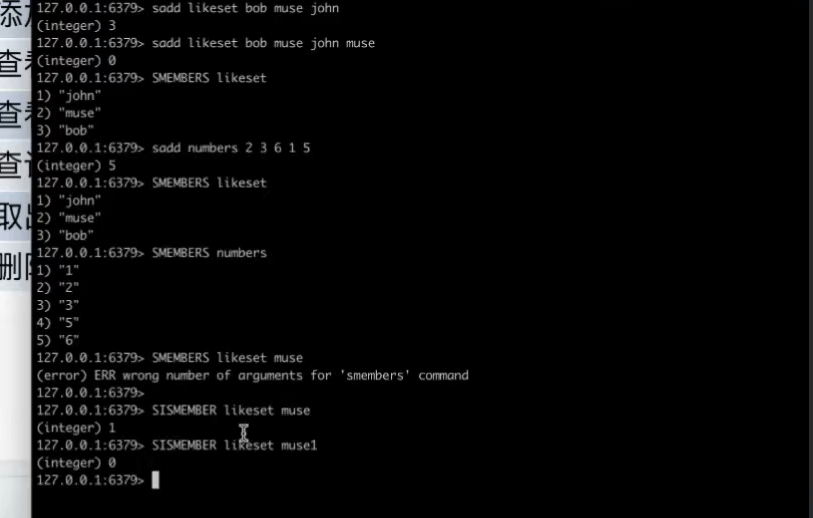
存数字的时候是有序的

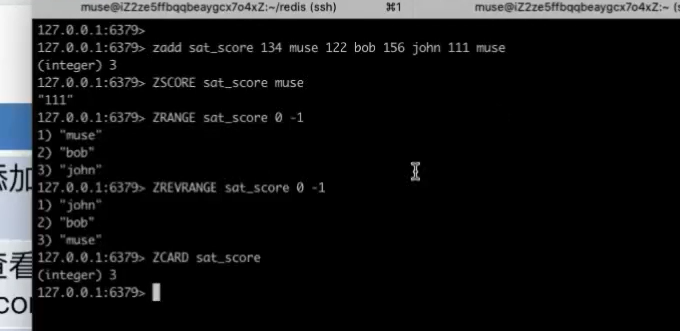
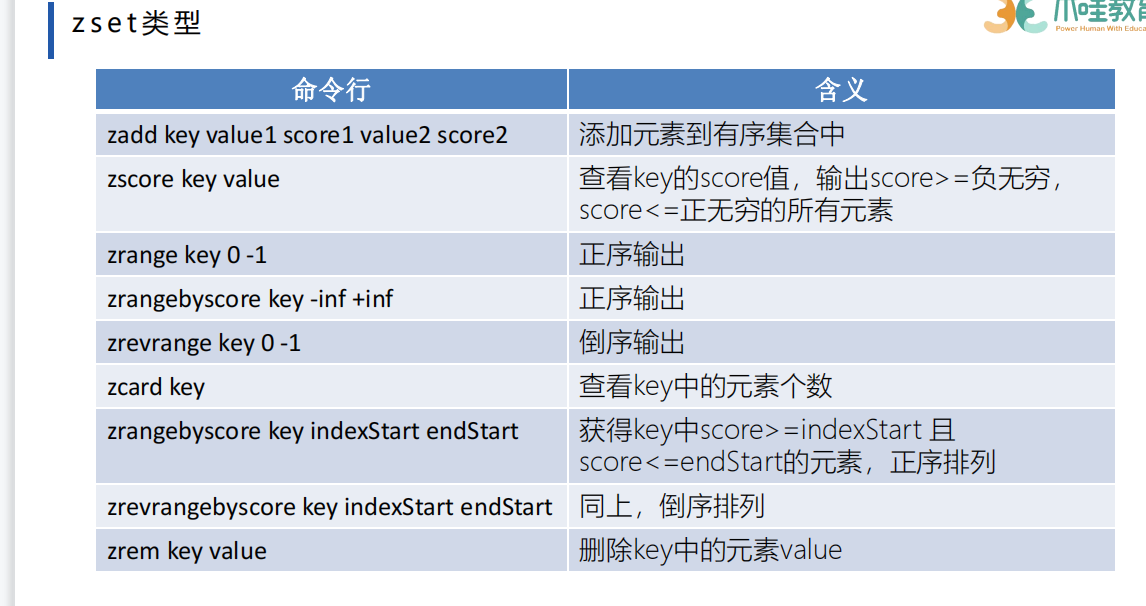
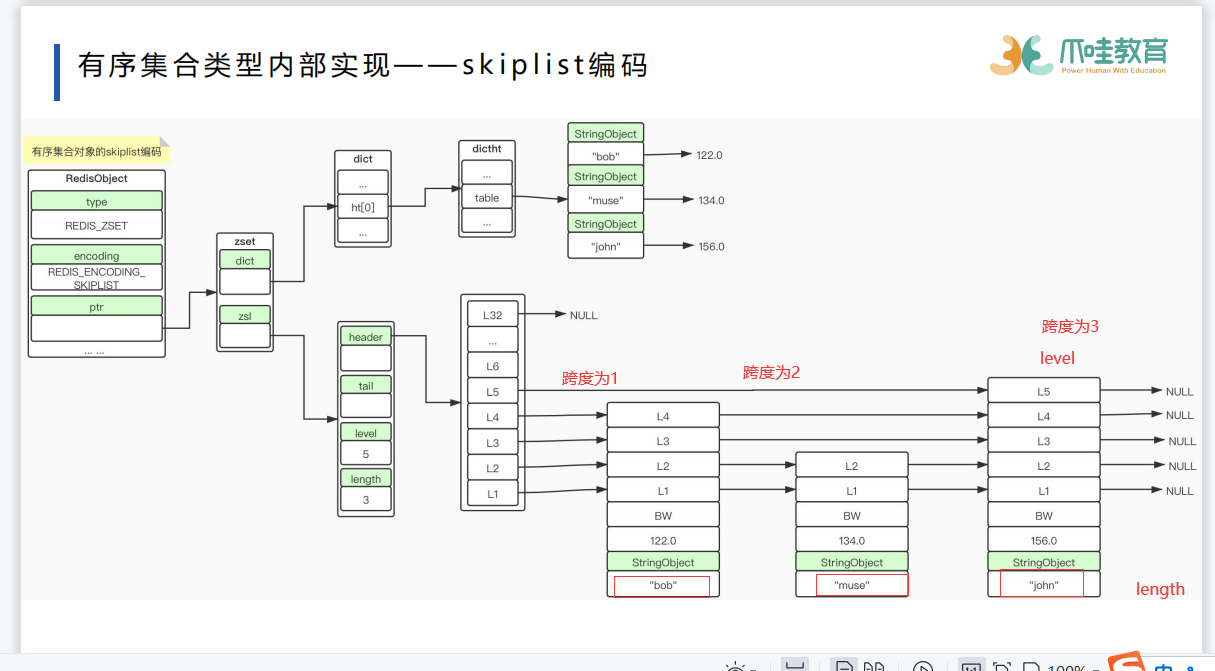
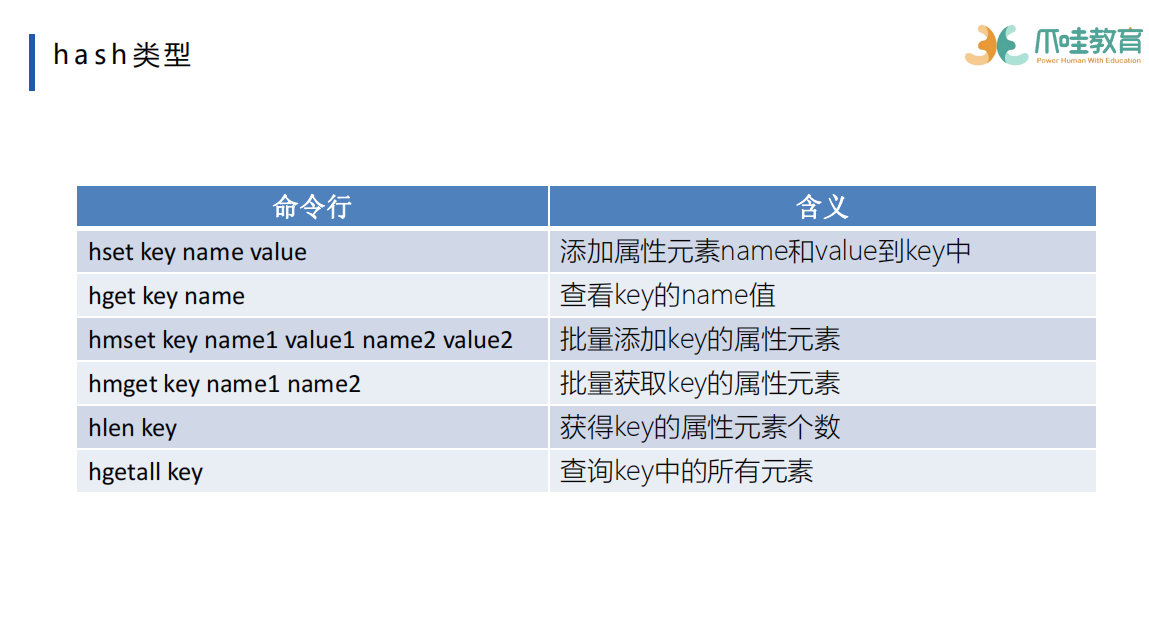
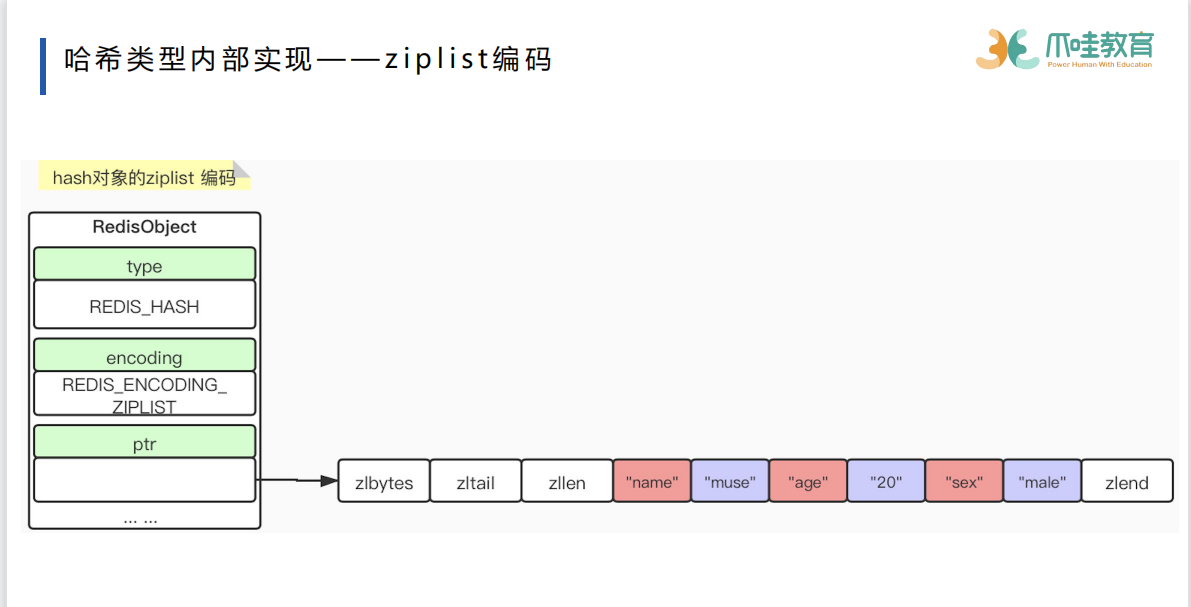
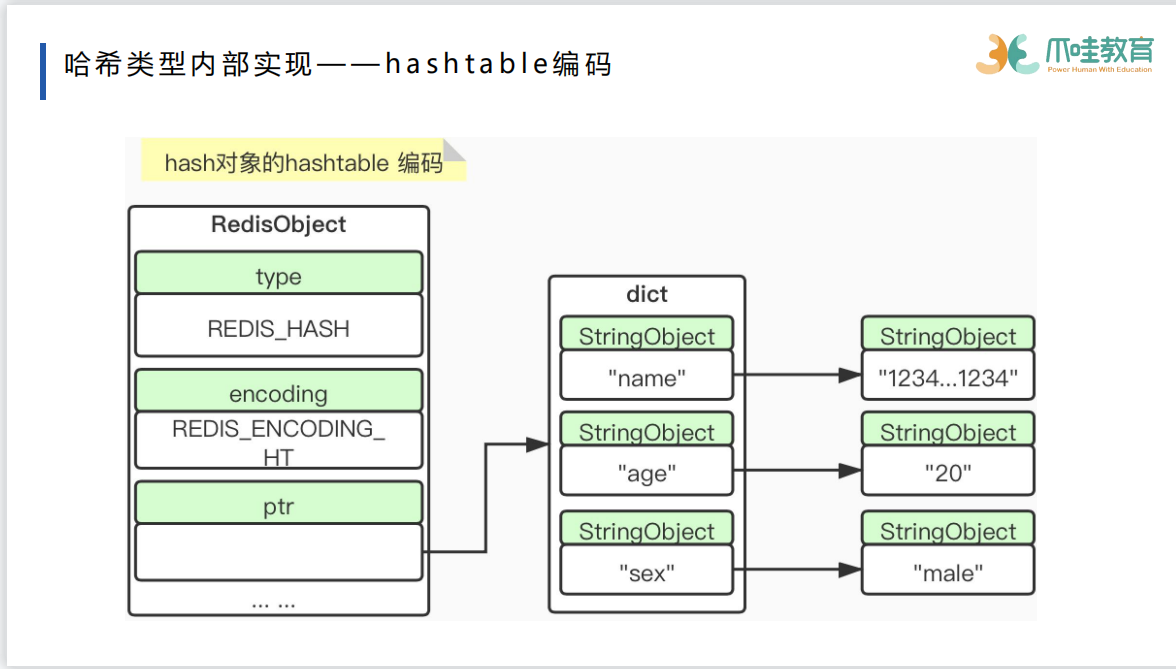
zset



1.增加过期时间
2.value值加入唯一标识
3.主节点加锁,然后主节点挂掉,但是信息并没有同步到从节点上,导致另外的线程抢到了锁 redlock算法
缓存穿透、击穿、雪崩
- 缓存穿透:key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会到数据源,从而可能压垮数据源。比如用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。
- 缓存击穿:key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
- 缓存雪崩:当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,也会给后端系统(比如DB)带来很大压力。
有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。另外也有一个更为简单粗暴的方法(我们采用的就是这种),如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
缓存击穿解决方案
key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题。
使用互斥锁(mutex key)
业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
缓存雪崩解决方案
大多数系统设计者考虑用加锁或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。还有一个简单方案就时讲缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
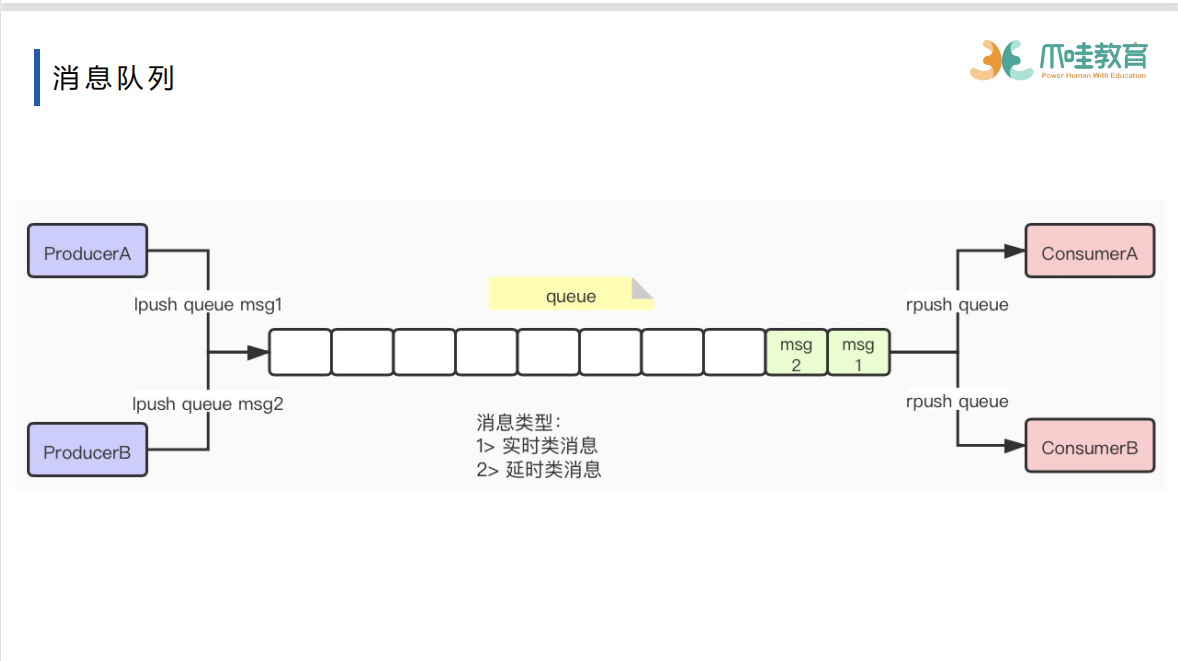
blpop brpop阻塞队列 当队列为空,阻塞队列时,先抛出异常,再建立第二次连接

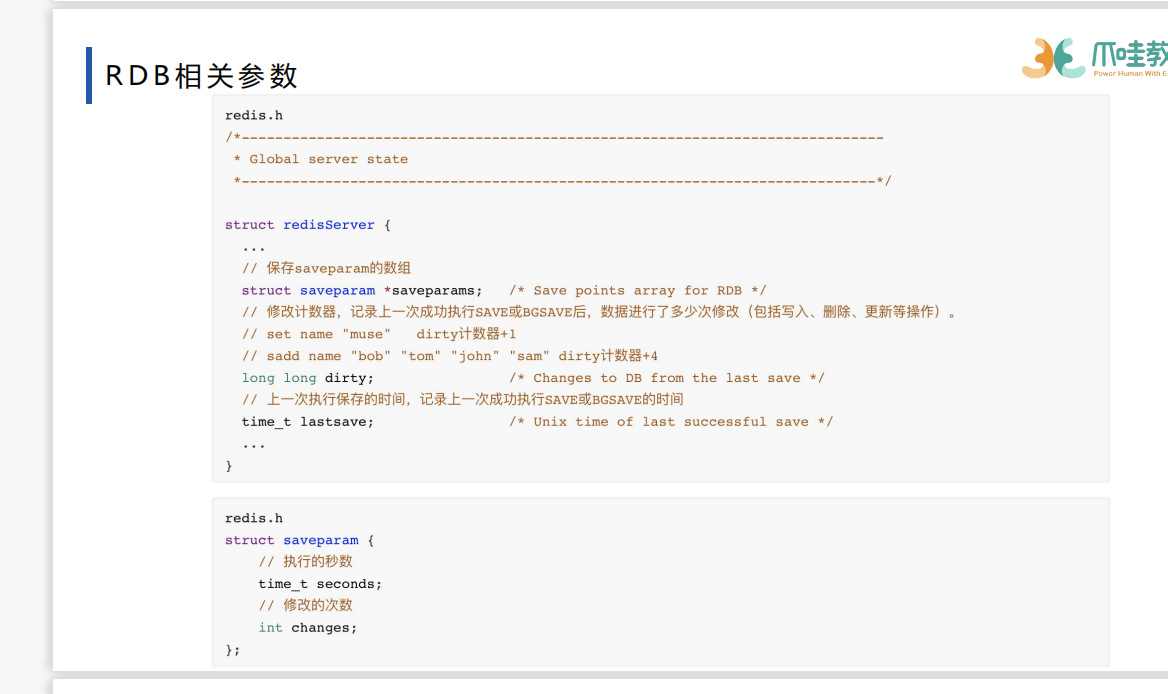
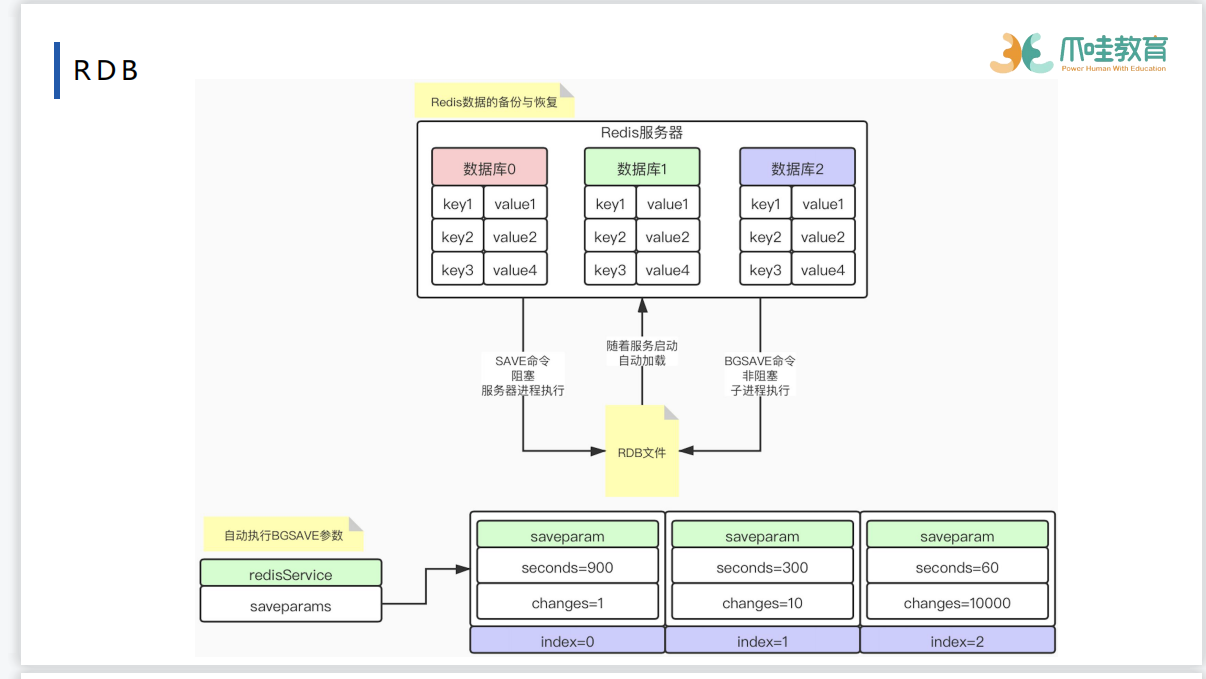
saveParam可否执行rdb操作的定时的标准 saveParam可看做配置表,超过配置表的时间和修改次数就会进行bgsave的操作
save和bgsave的区别 save阻塞线程,不会执行客户端的命令 bgsave 开了子进程 主进程执行客户端的命令
手动执行
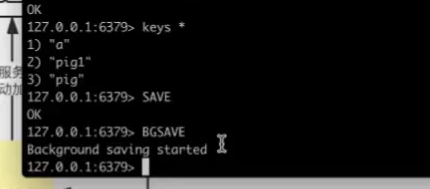
客户端可以通过 LASTSAVE 命令查看相关信息,判断 BGSAVE 命令是否执行成功。
服务器开启了aof持久化,先加载aof,aof备份频率比rdb要高,因为aof不是基于命令操作 所以默认是rdb
server cron 条件检测器 100ms执行一次条件验证


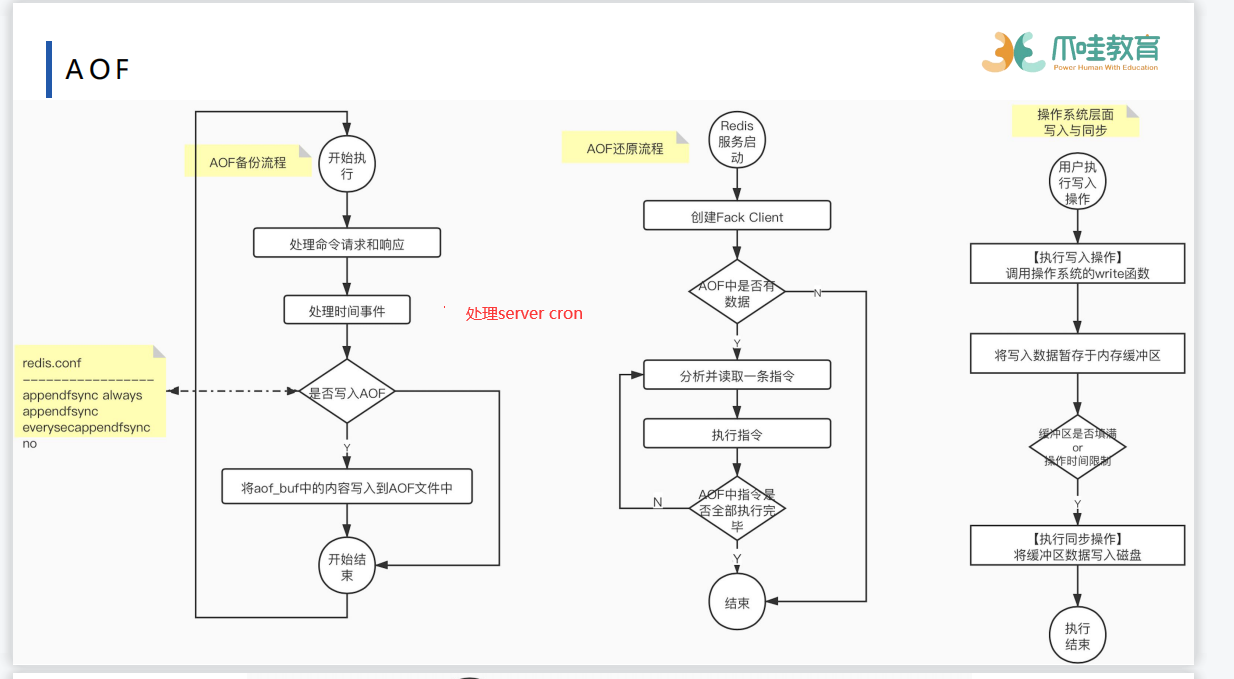
文件事件:处理请求 时间事件:server cron 每次循环结束后调用flush depend only flle函数将aof_buffer写入到aof中
aof还原 fake client 不接收网络请求 从aof文件中读取 不需要经过网络

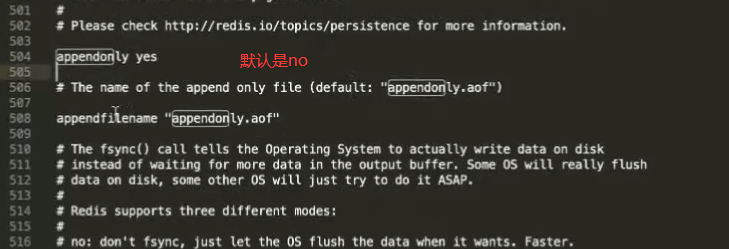
redis默认是everysec

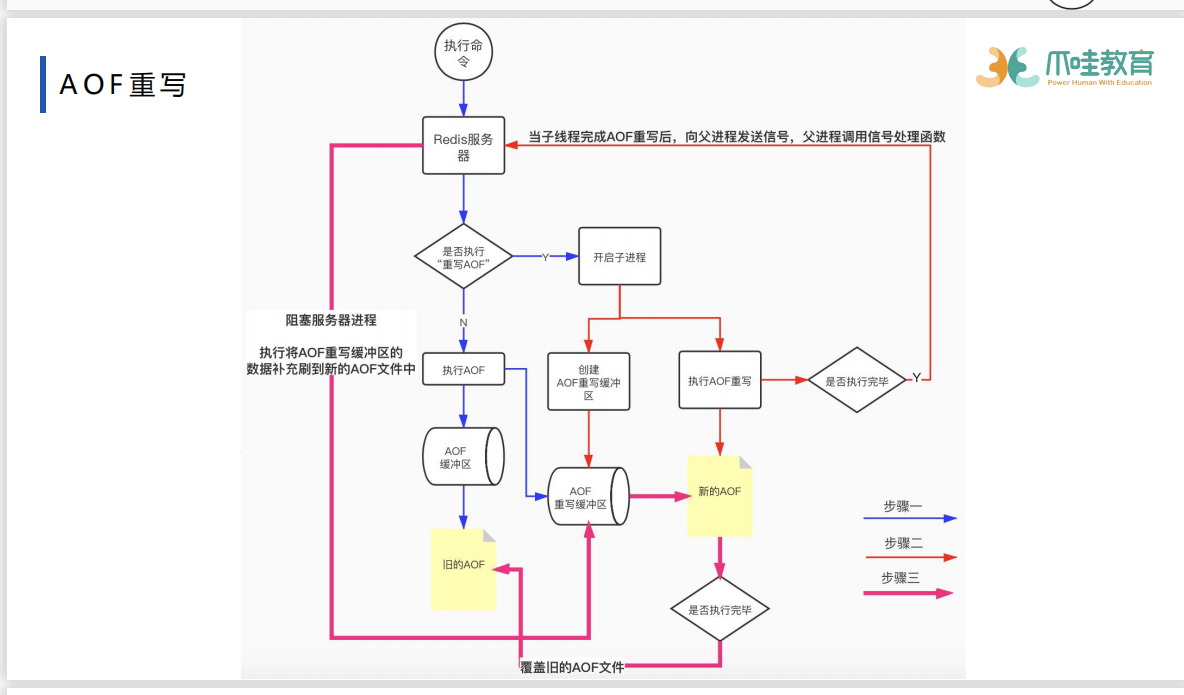
触发重写:64和100

- AOF重写并不需要对原有AOF文件进行任何的读取,写入,分析等操作,这个功能是通过读取服务器当前的数据库状态来实现的。
子进程执行完重写之后,告诉父进程阻塞整个进程,父进程将aof重写缓冲区的数据读到aof中,
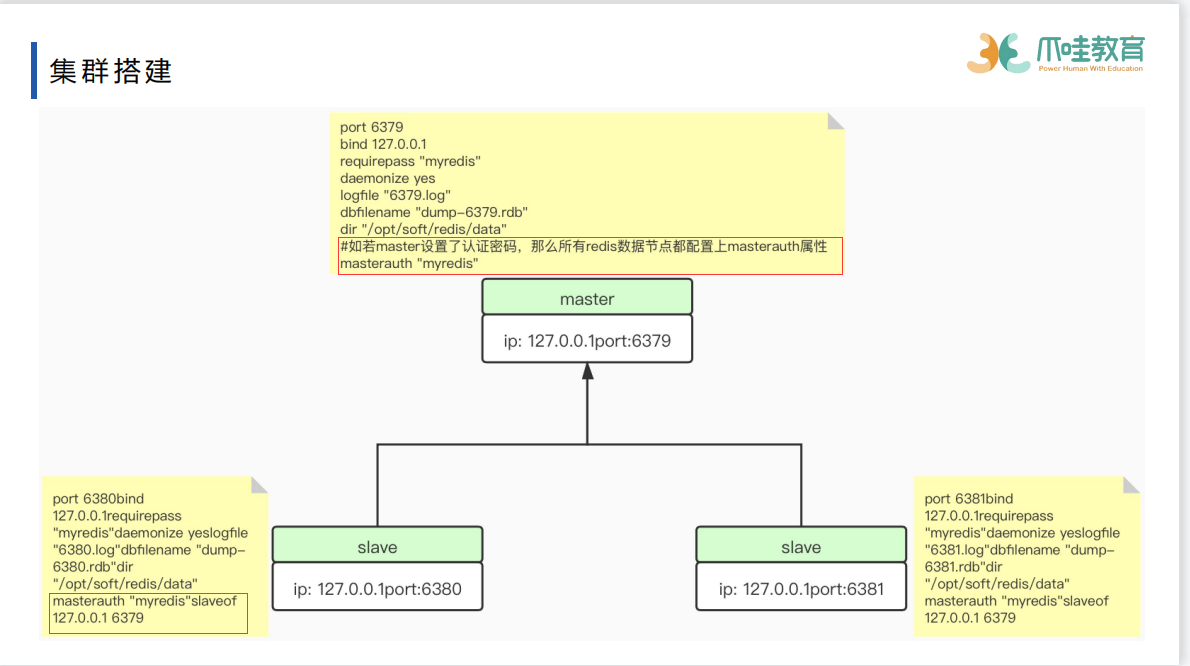
没有sentinel哨兵,需要手动将slave改为master
2、二者的区别
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。

AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。
RDB持久化配置
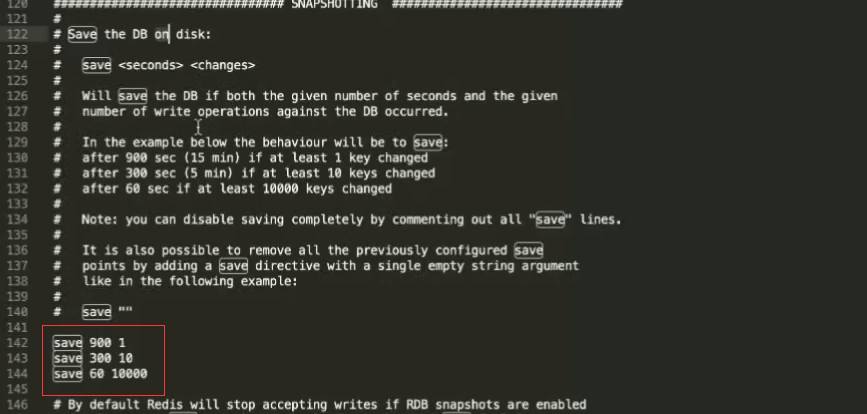
Redis会将数据集的快照dump到dump.rdb文件中。此外,我们也可以通过配置文件来修改Redis服务器dump快照的频率,在打开6379.conf文件之后,我们搜索save,可以看到下面的配置信息:
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,则dump内存快照。
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,则dump内存快照。
save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,则dump内存快照。
AOF持久化配置
在Redis的配置文件中存在三种同步方式,它们分别是:
appendfsync always #每次有数据修改发生时都会写入AOF文件。
appendfsync everysec #每秒钟同步一次,该策略为AOF的缺省策略。
appendfsync no #从不同步。高效但是数据不会被持久化。


