并发编程补充
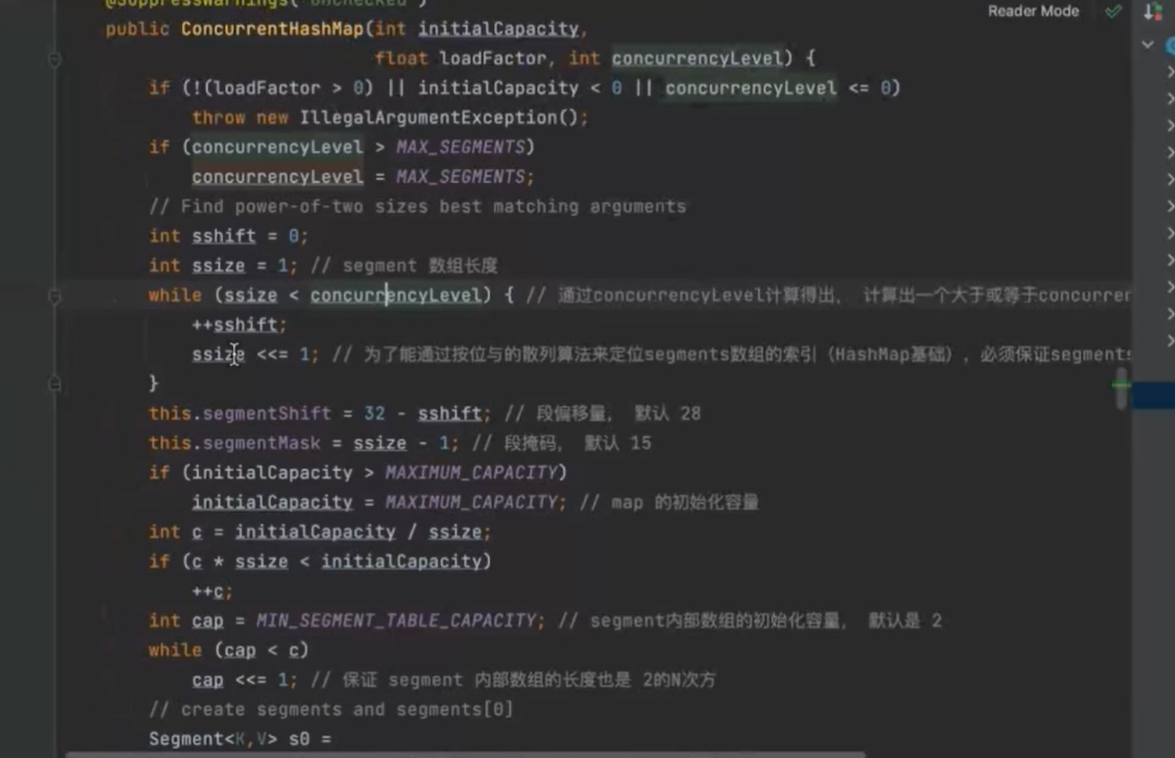
concurrenthashmap第一步,初始化segment数组
hashentry的数组
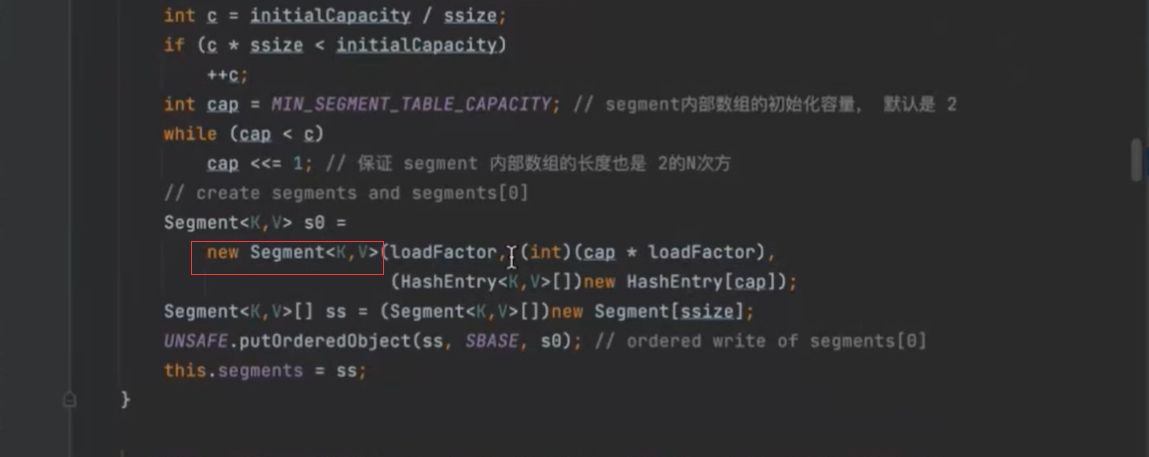
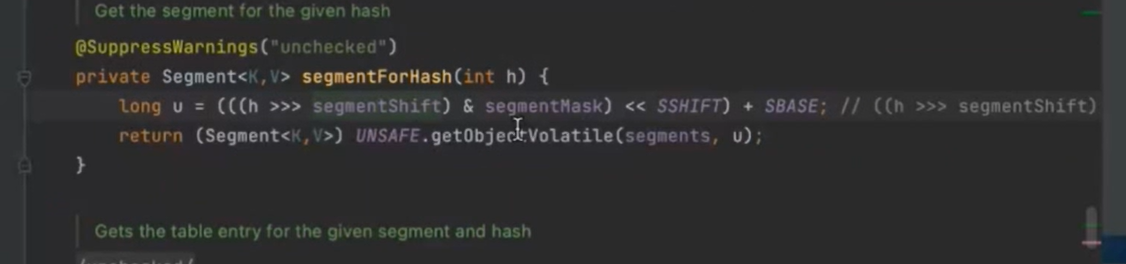
定位segment元素的位置 用段偏移量 和段掩码 concurrentcysize默认值16
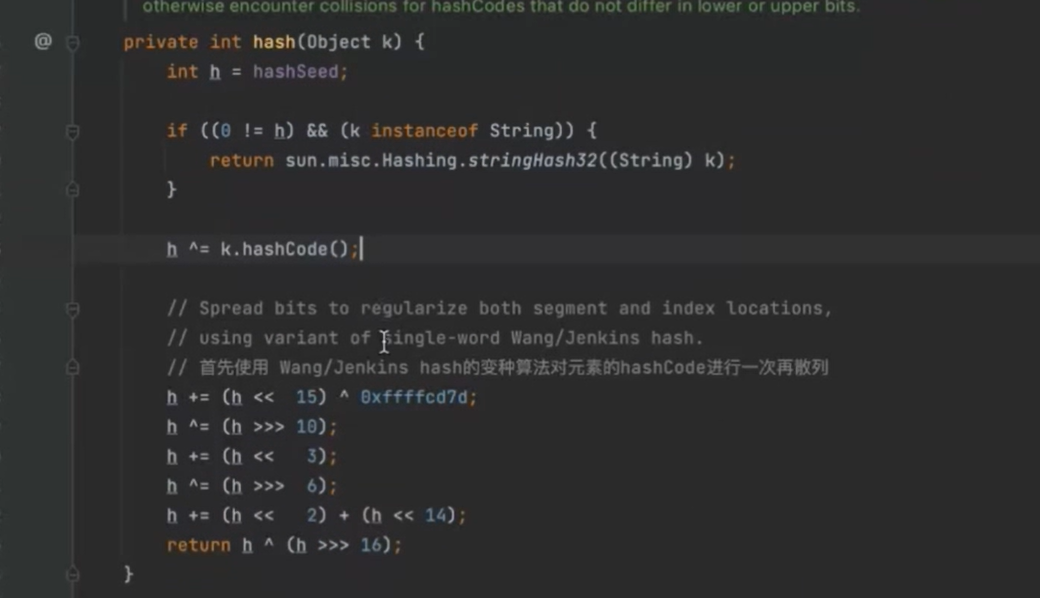
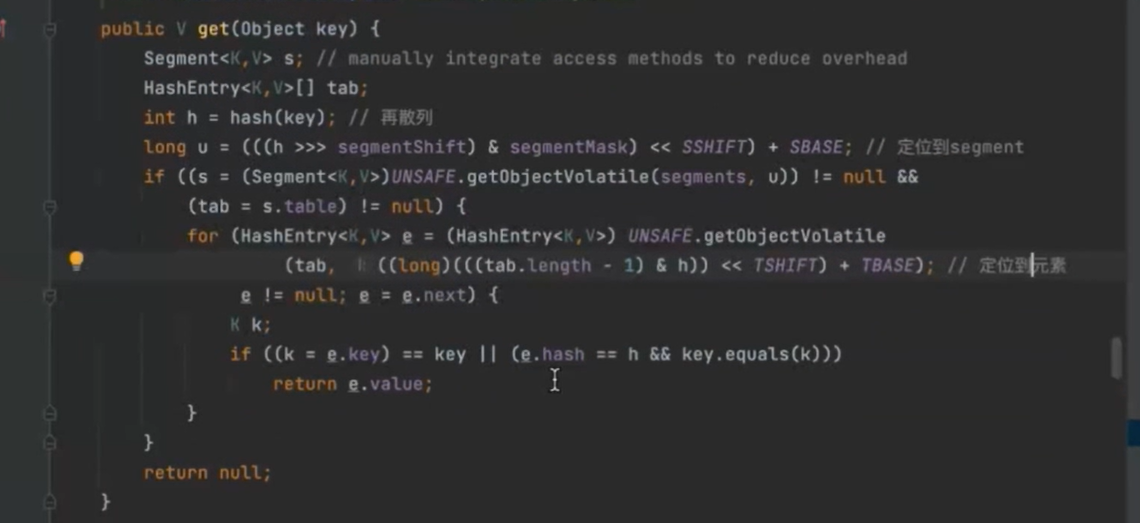
先拿到hash值,再散列算法,减少散列冲突 让元素均匀分布在segment上面 从而提高容器的存储效率 不进行再散列的话所有元素都会放到一个segment中
定义成volatile 多线程同时读,保证不会读到过期的值 单线程的写 happens before规则 写在读之前 所以volatile每次都能拿到最新的值
定位到segment用的是高四位 定位元素用的是全部的值 为了避免两次散列的值一样(元素在segment散列开,但没有在hashentry散列开)
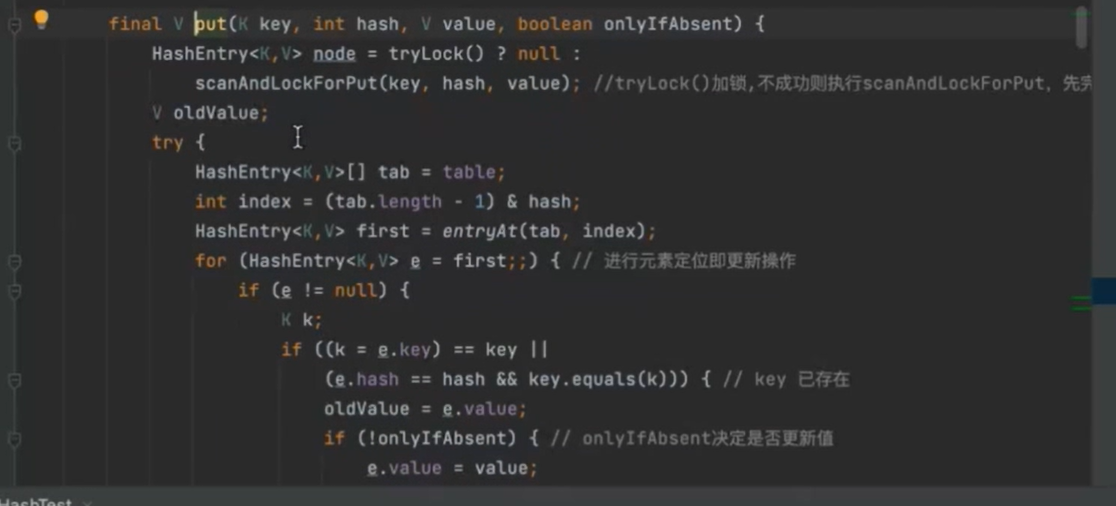
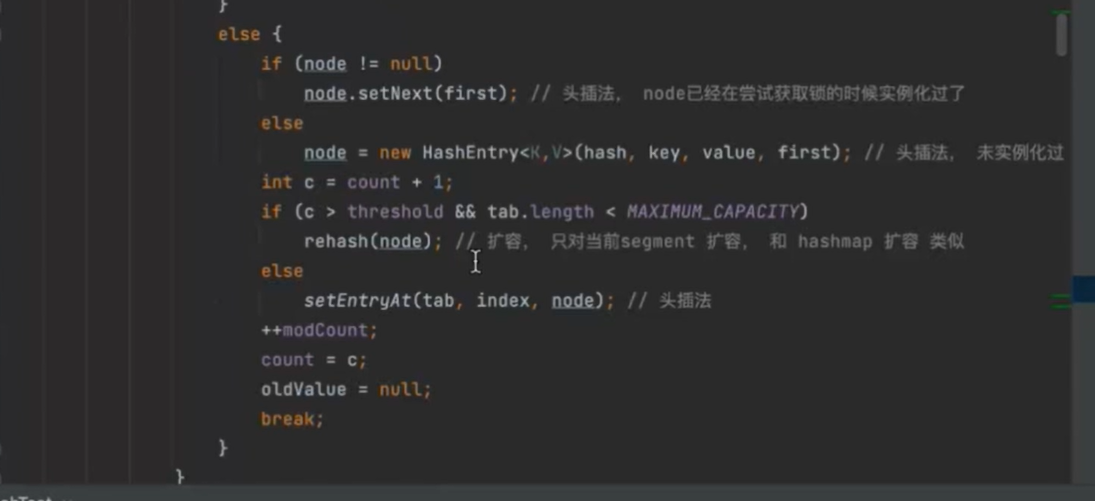
put 扩容成原数组的两倍,再将原数组散列插入到新数组中
size统计元素个数 先尝试两次不加锁的方案 ,如果两次线程数有变化,说明有其他线程修改 加锁获取size

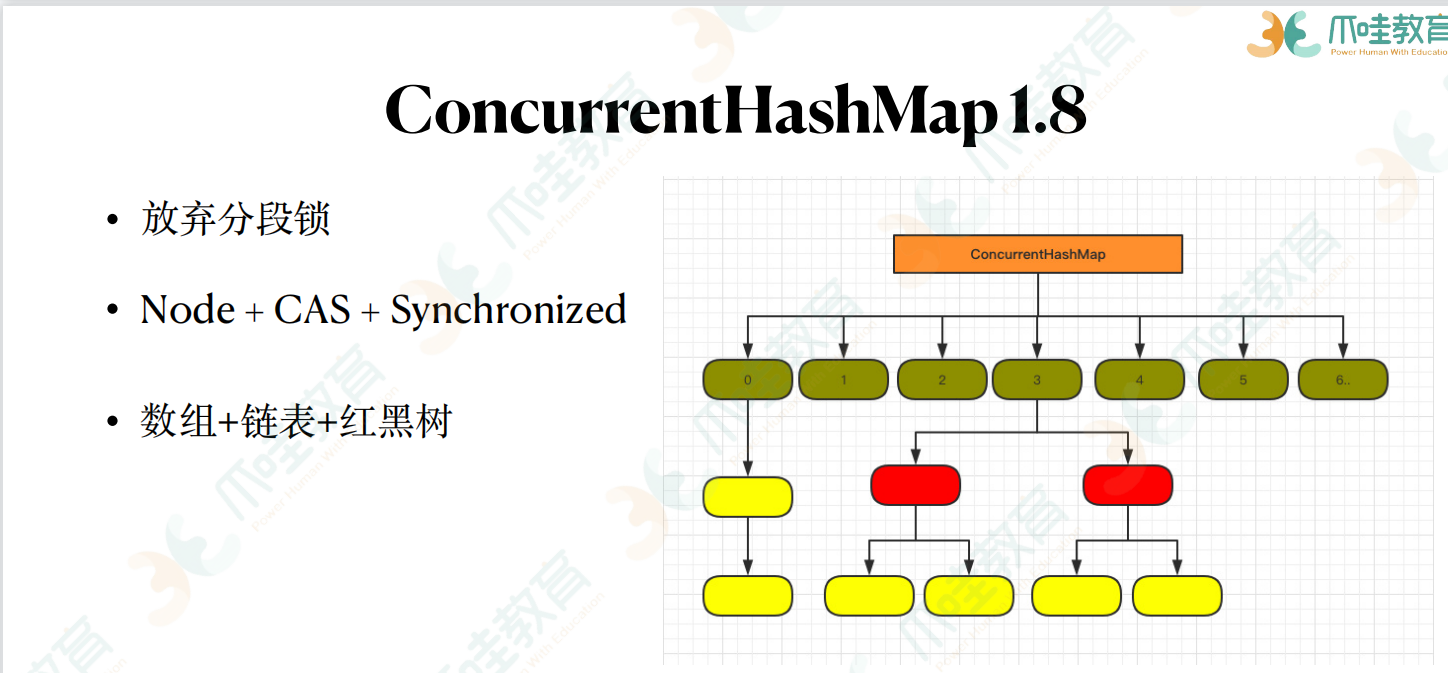
concurrentHashMap1.8 红黑树:优化底层链表的遍历效率 怎样在很短的时间内把大量数据插入到concurrenthashmap

增加一个元素,加载队列的尾部,获取一个元素的时候会返回队列头部的元素
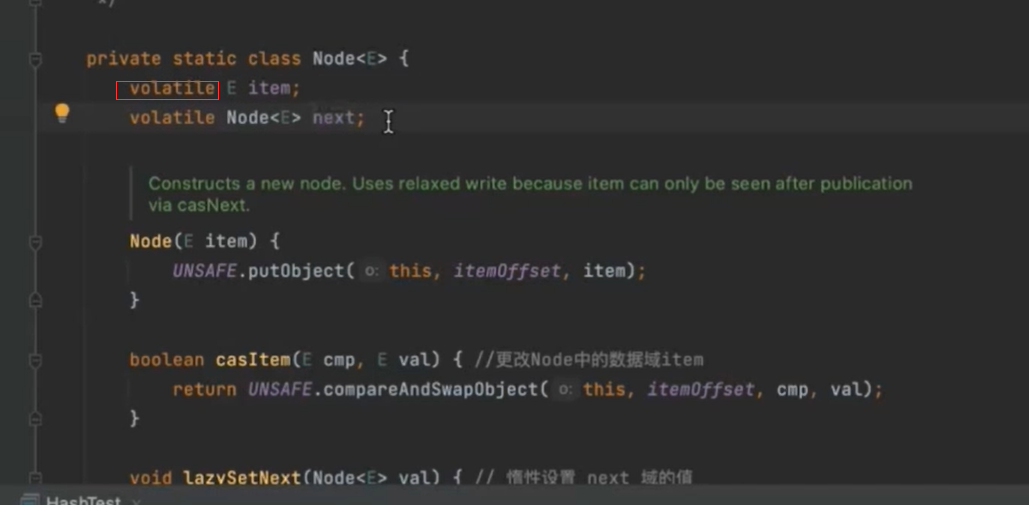
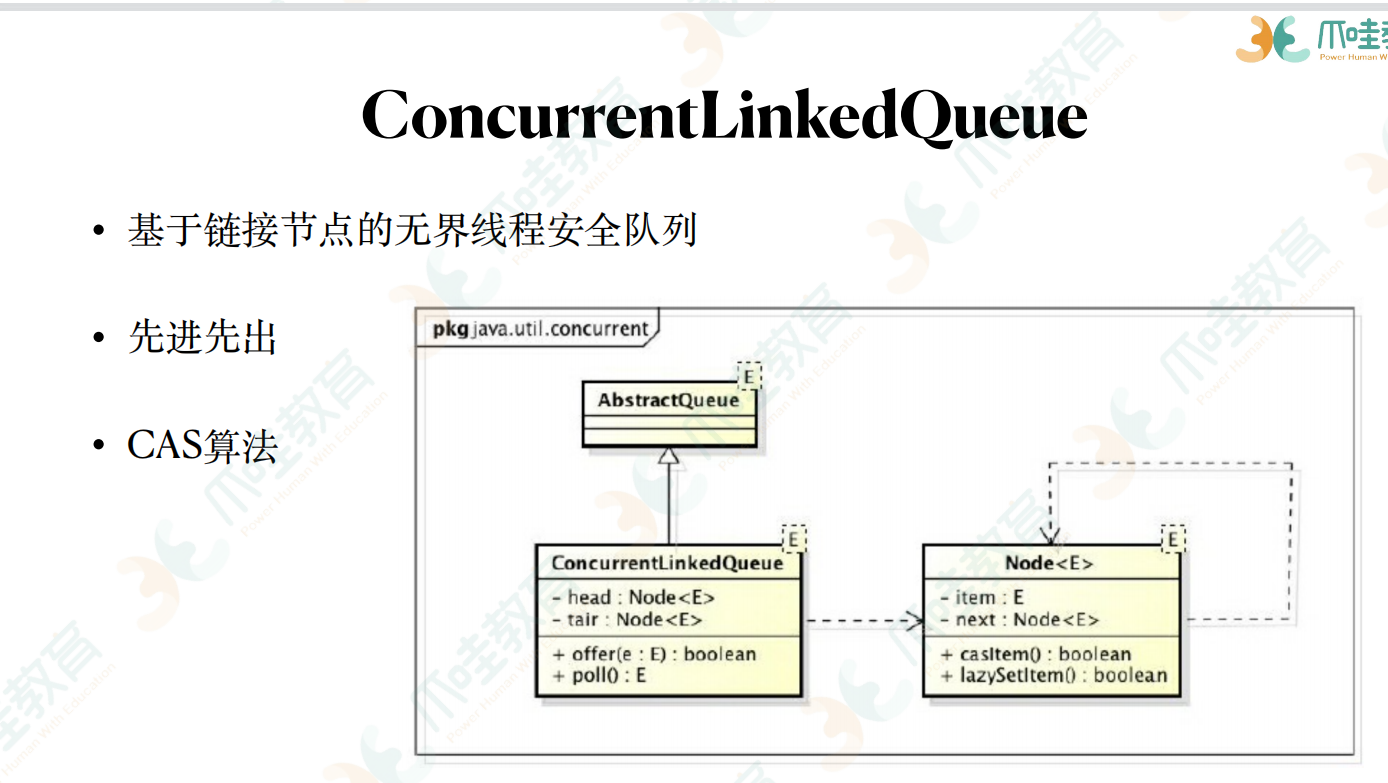
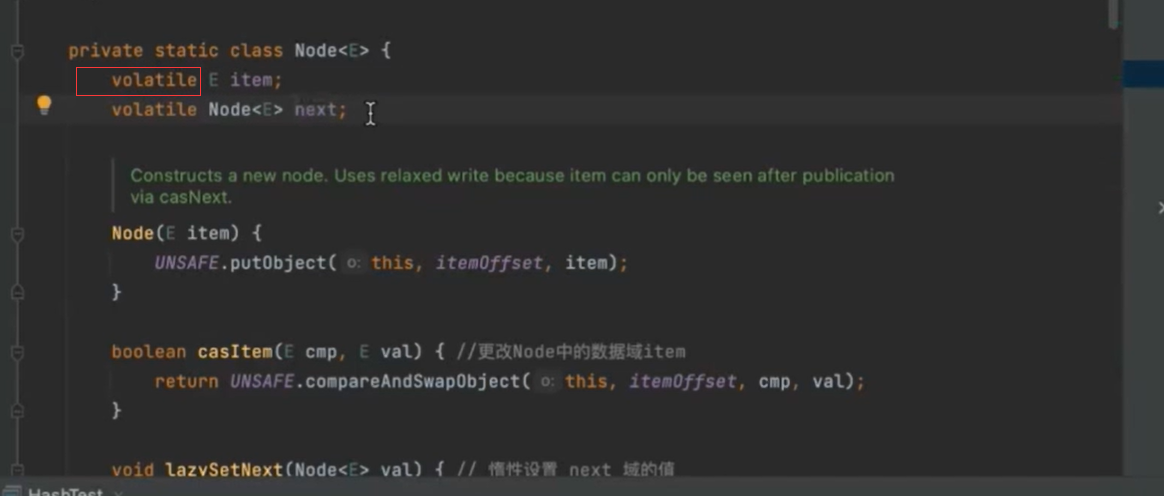
e 数据域 next next指针,指向下一个节点
构造函数初始化
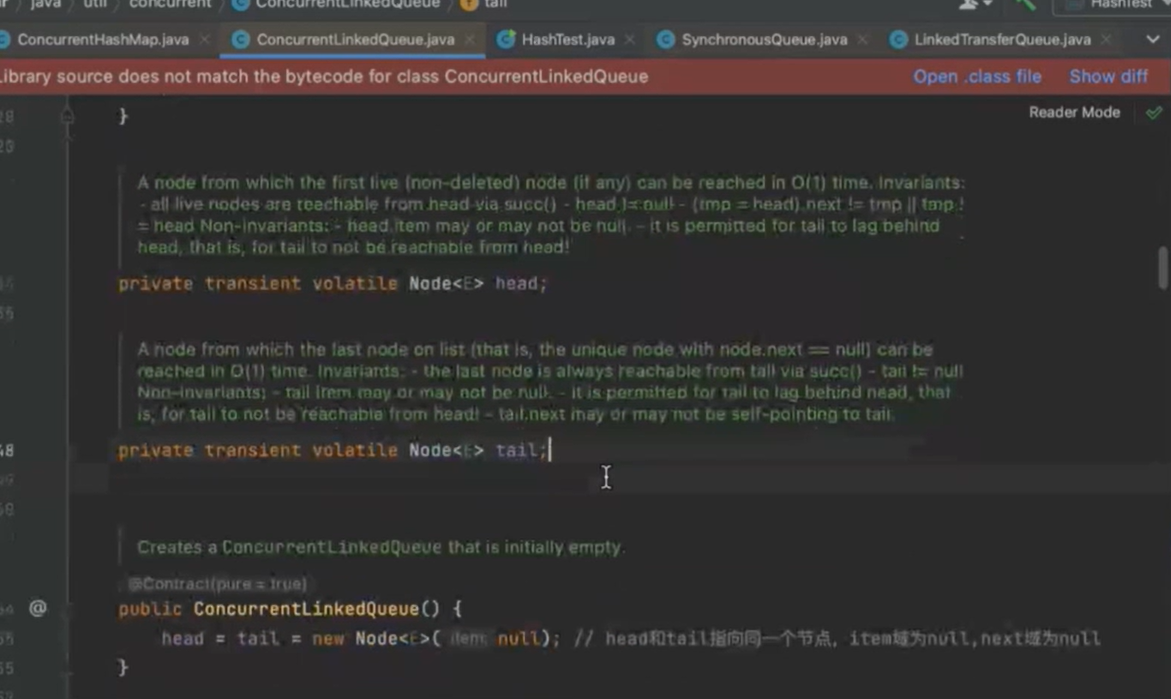
node的cas操作避免线程安全问题
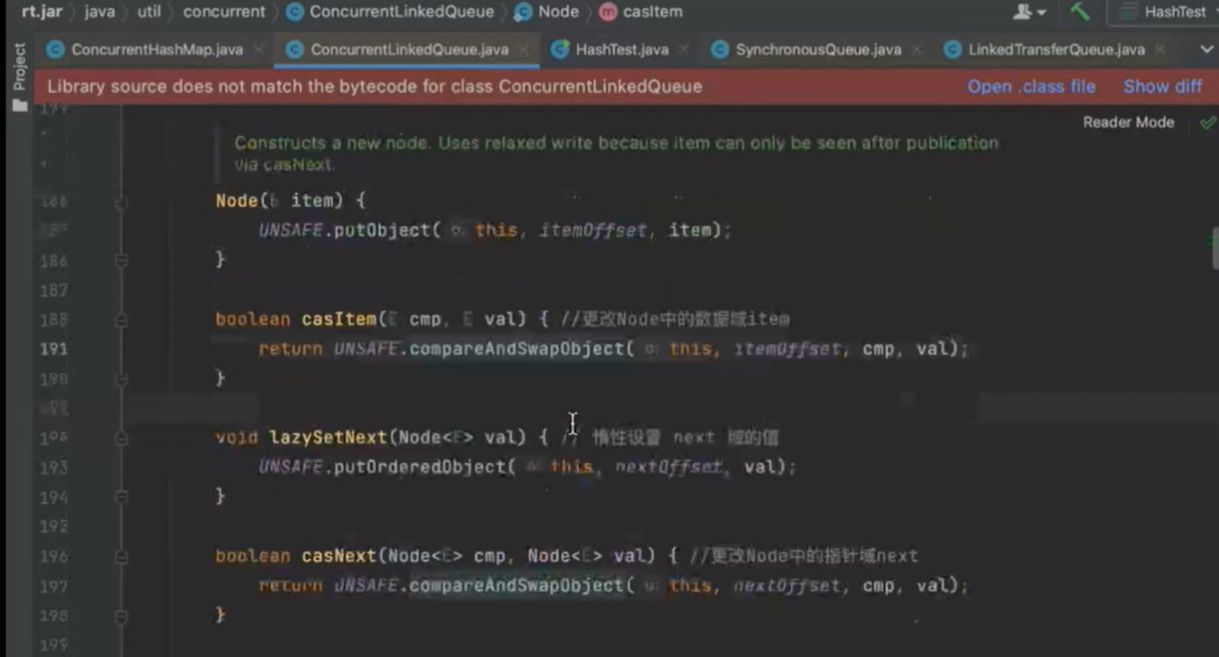
将节点加到队列尾部
1.将入队节点设置为当前节点的下一个节点 2.更新tail节点(如果tail节点的next节点不为空,就将入队节点置为tail节点
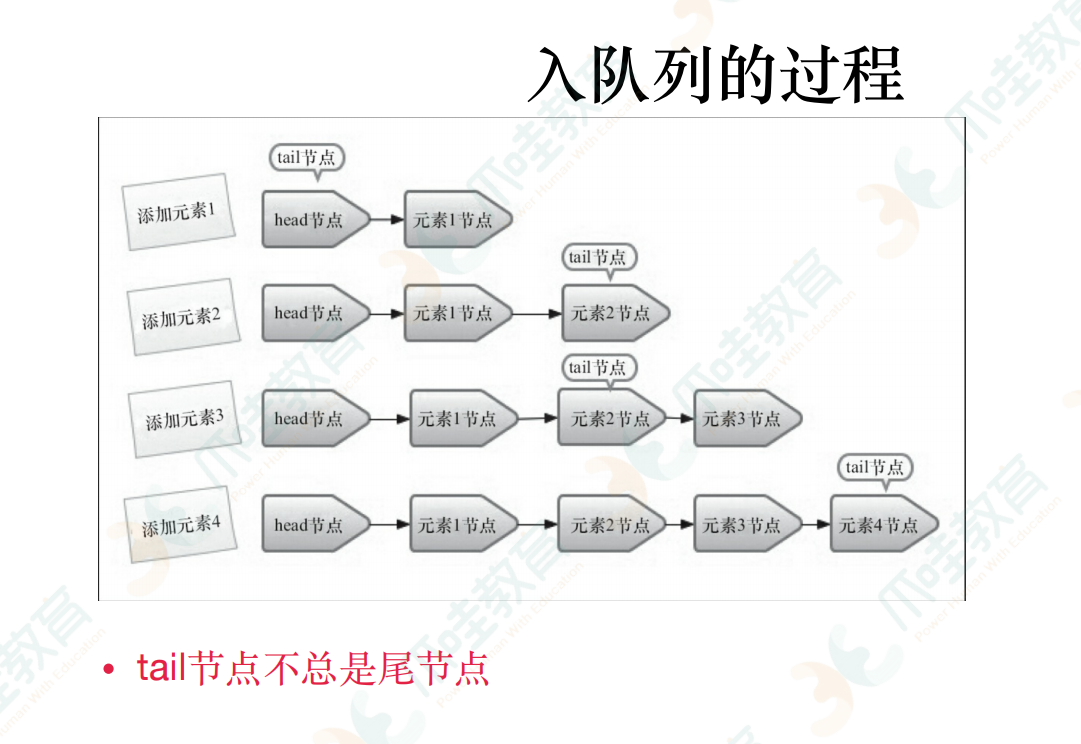
多线程入队列 offer ----如果-----且更新tail成功 p=next还没有越过两个节点的情况,会不断更新
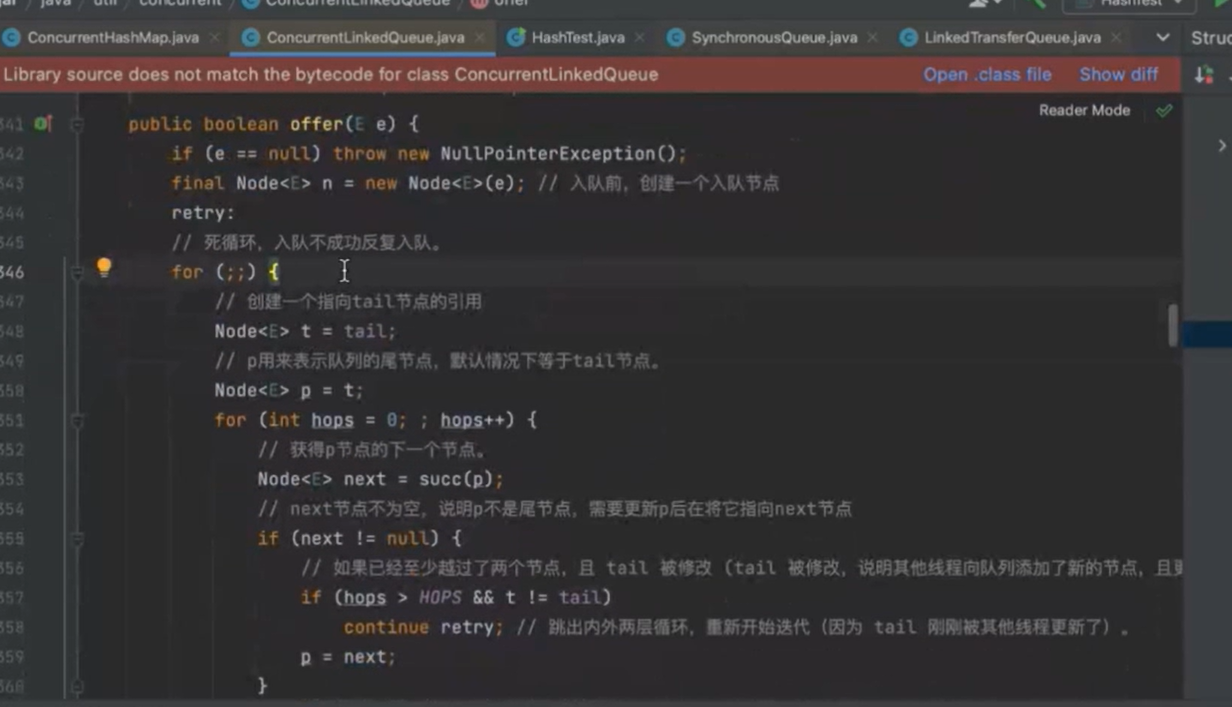
失败了表示有其他线程成功更新了tail节点
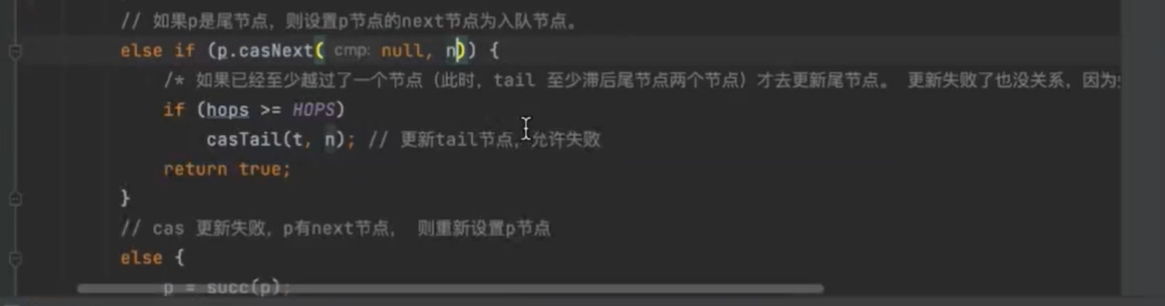
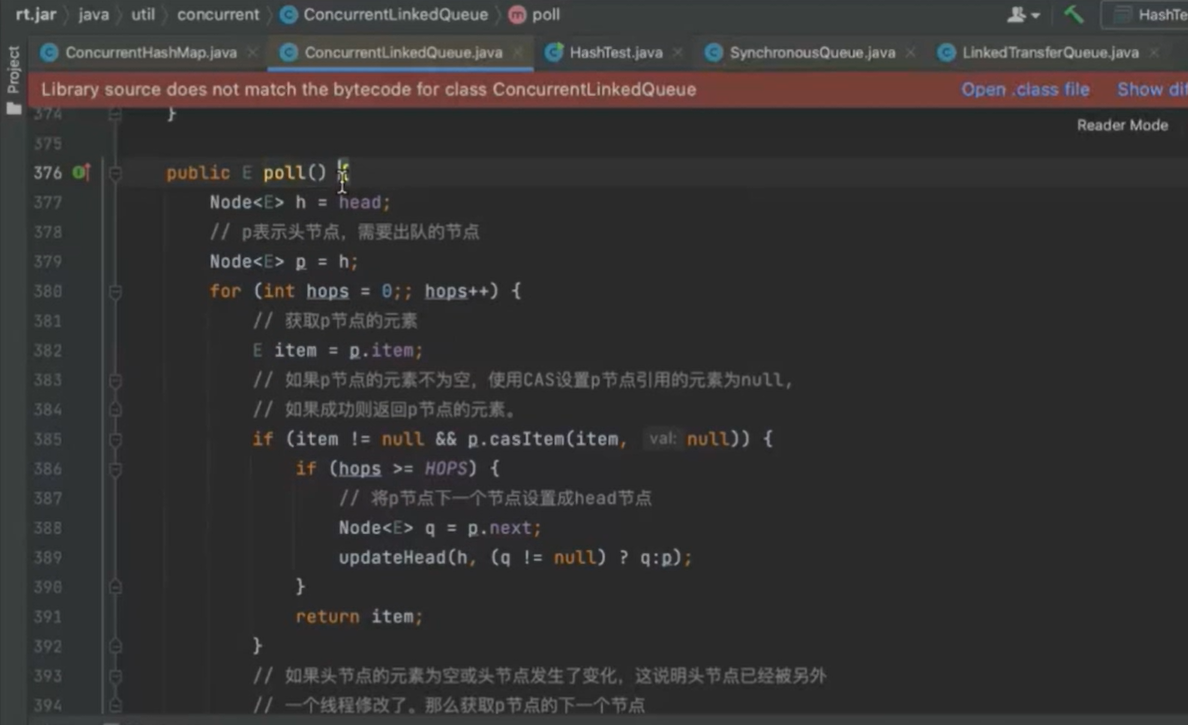
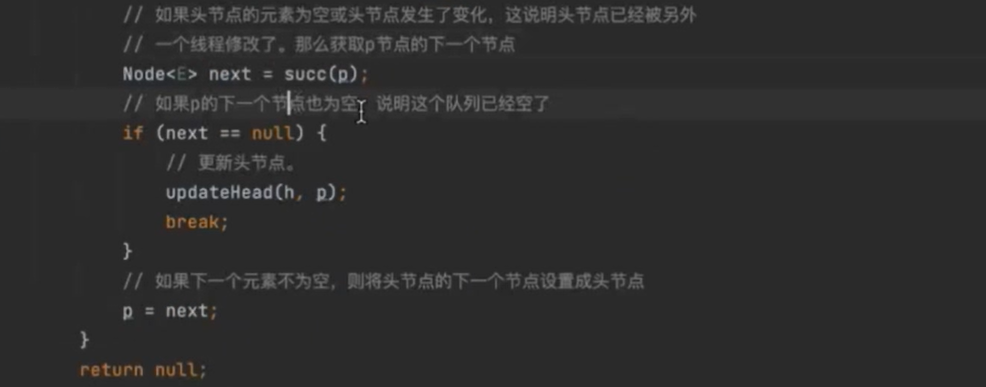
总共做了两件事情 定位出尾结点 p 用CAS算法 把入队节点设置成尾结点的next节点,如果不成功,就不断重试 p=succ(p)
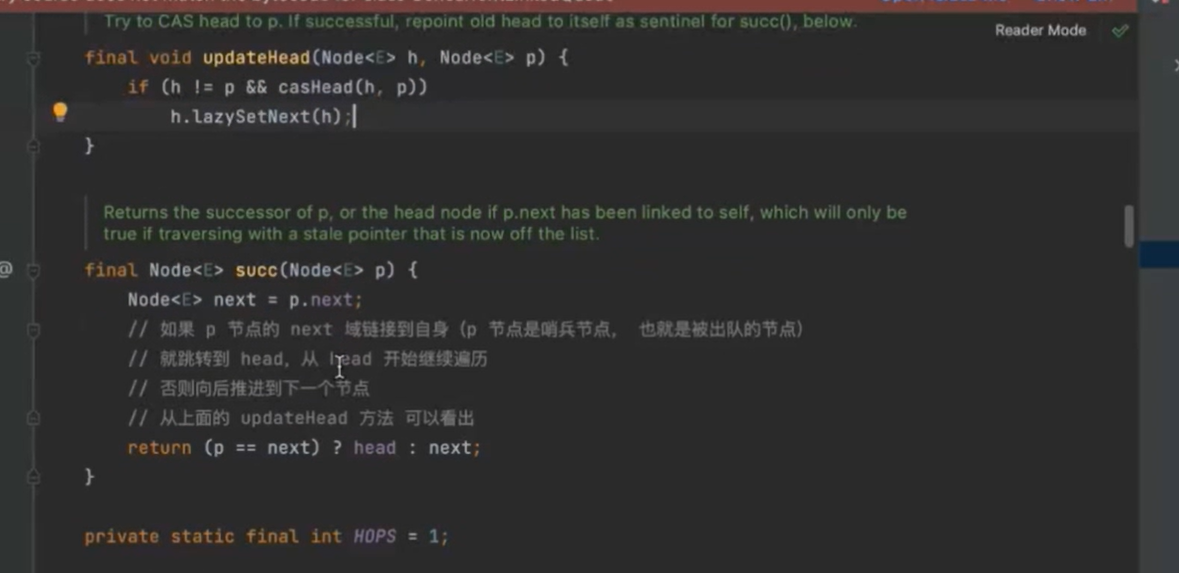
hops变量减少tail节点的更新频率,提高入队效率 tail节点与尾结点距离越长,则cas使用越少 每次循环很长时间才能定位到尾结点
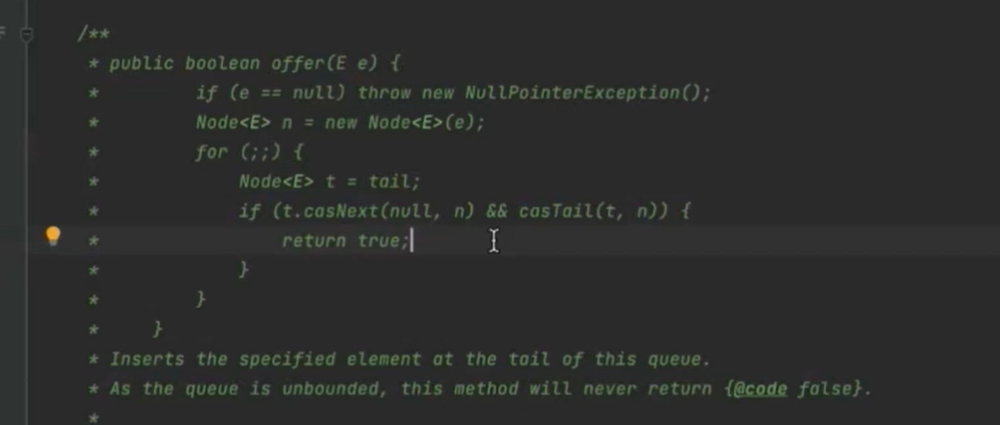
增加tail变量的读操作 减少写操作,因为volatile写操作的开销远远大于读操作
出队列:从队列中返回一个节点元素并且清空节点对元素的引用
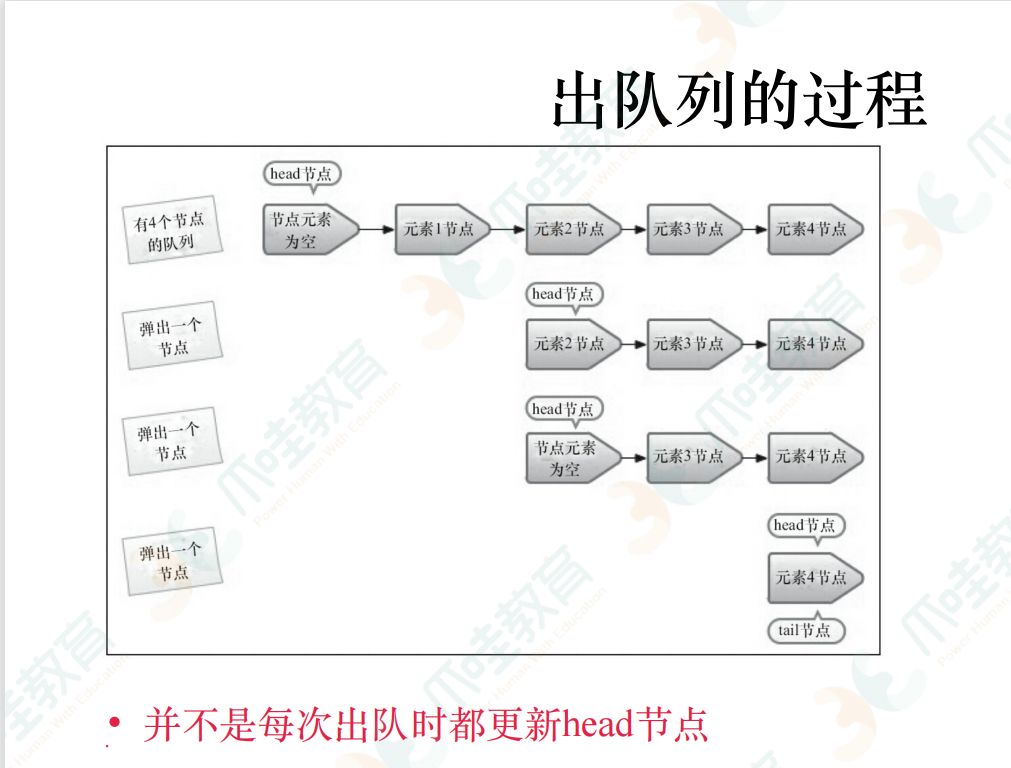
当head节点有元素,直接弹出head中的元素,而不会去更新head节点
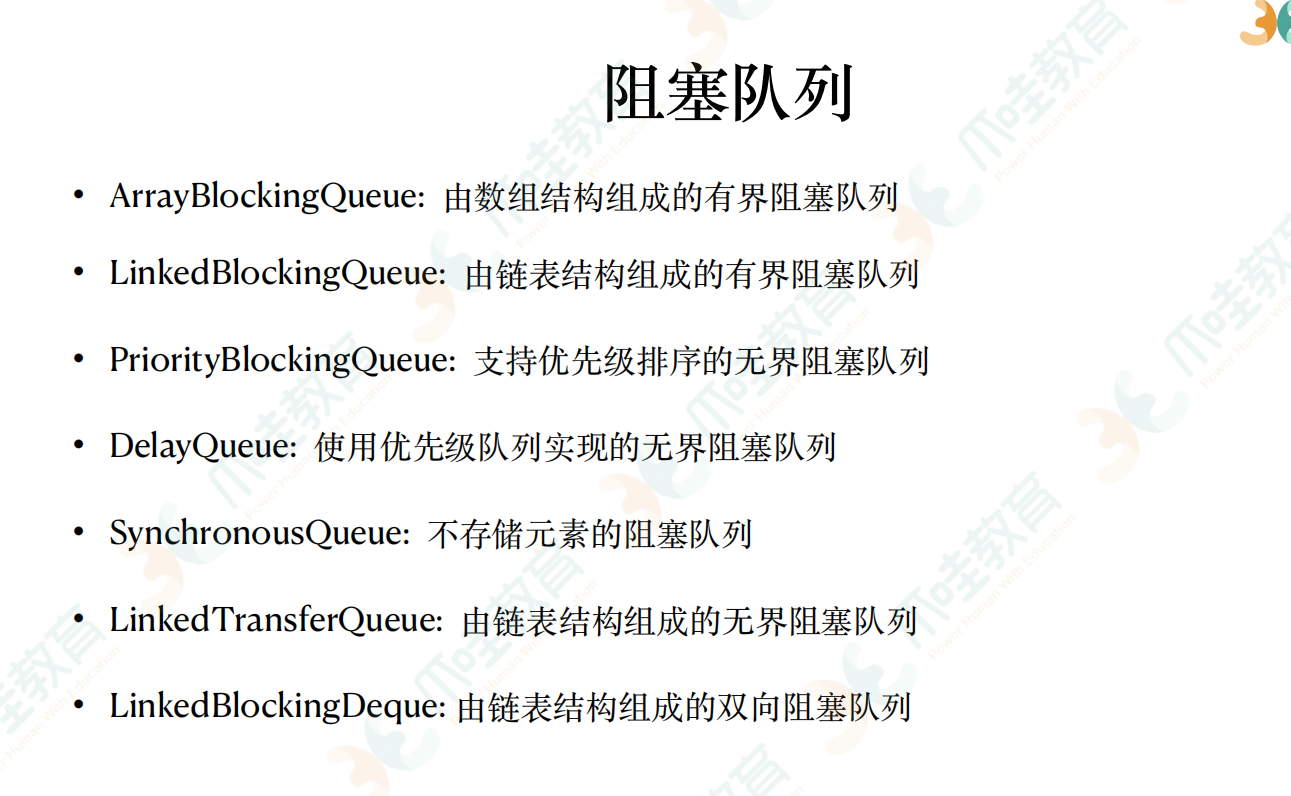
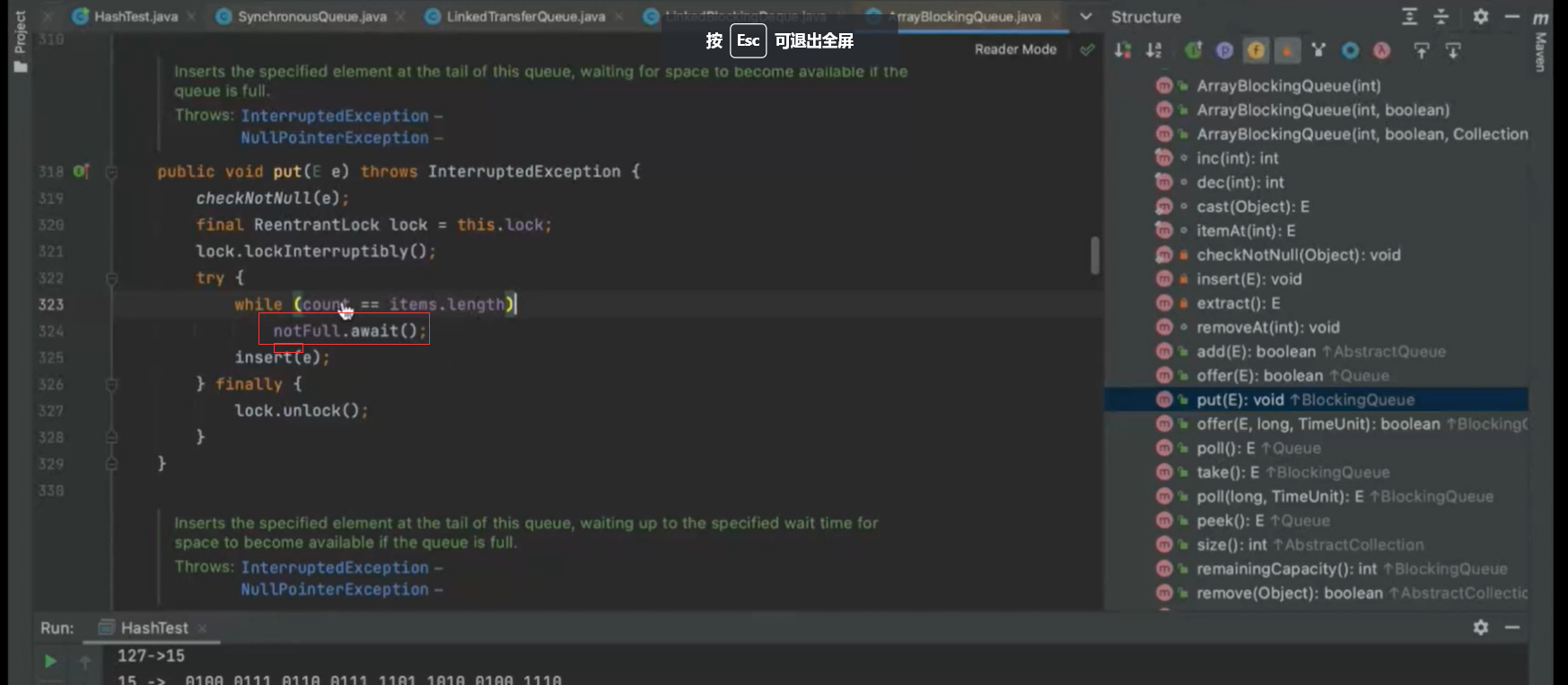
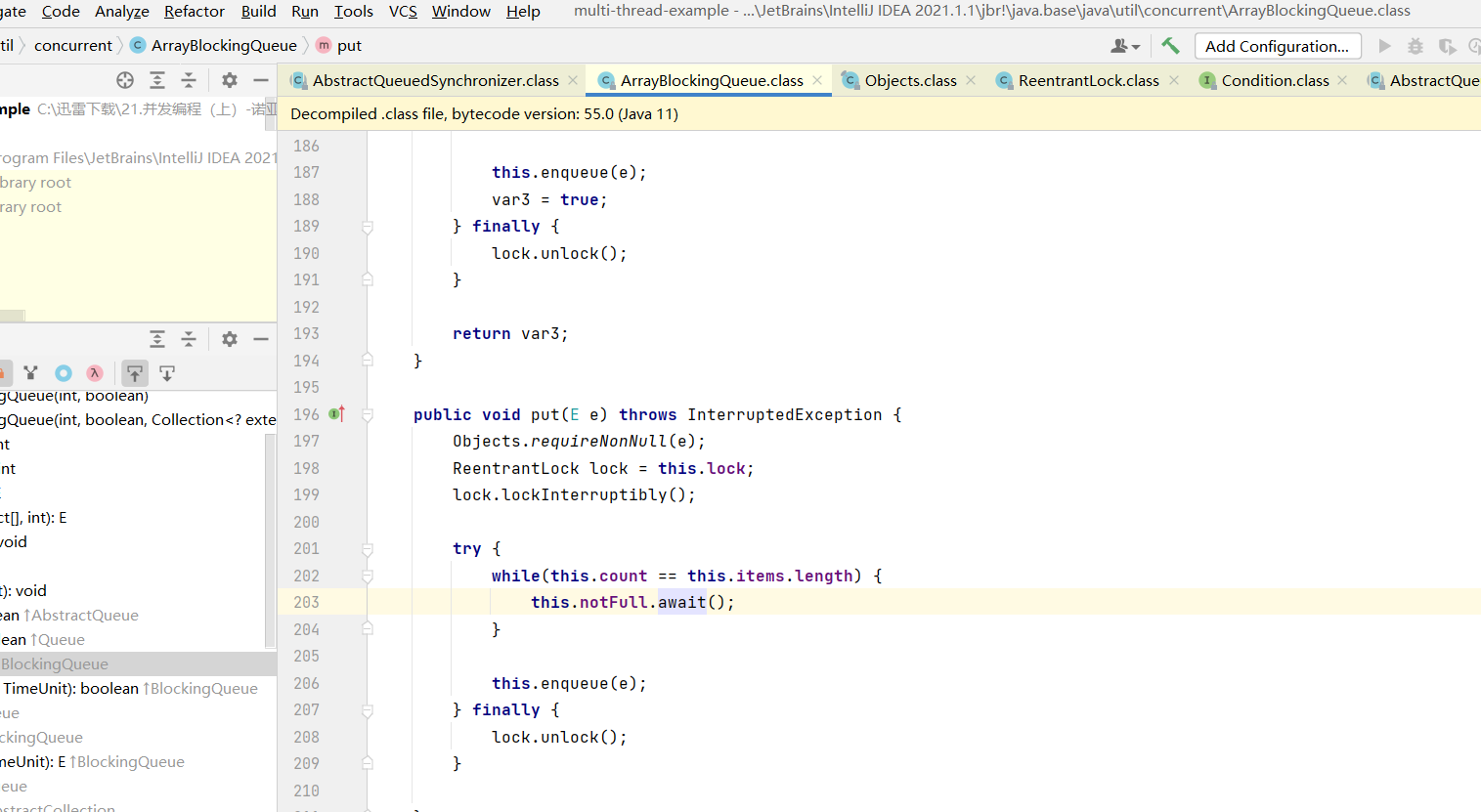
阻塞队列 condition实现

队列满的时候,生产者线程put元素,队列会一直阻塞生产者的线程 ,直到队列可用或响应中断退出了
队列空的时候,消费者线程从队列take元素,队列会阻塞消费者线程,直到队列不为空

超时退出 阻塞队列满的时候,生产者线程往队列插入元素,队列会阻塞生产者一段时间,过了这段时间,生产者线程会退出
无界阻塞队列 用 put offer方法 永远不会被阻塞

公平:阻塞的线程可以按照阻塞的先后顺序访问队列
delayqueue proirity 延迟期满的时候才能从队列获取元素
保存缓存元素的有效期 使用一个线程循环查询delayqueue,一旦能从delayqueue获取元素说明缓存期到了
syncronazedqueue 默认情况下非公平,支持公平访问队列 不存储元素的阻塞队列 每一个put操作必须要等一个take操作,否则就不能添加元素
直接把生产者线程的数据传给消费者线程 不存储元素,吞吐量比其他阻塞队列大
linkedtransferqueue 比其他阻塞队列多了transfer方法
------------恢复内容开始------------
concurrenthashmap第一步,初始化segment数组
hashentry的数组
定位segment元素的位置 用段偏移量 和段掩码 concurrentcysize默认值16
先拿到hash值,再散列算法,减少散列冲突 让元素均匀分布在segment上面 从而提高容器的存储效率 不进行再散列的话所有元素都会放到一个segment中
定义成volatile 多线程同时读,保证不会读到过期的值 单线程的写 happens before规则 写在读之前 所以volatile每次都能拿到最新的值
定位到segment用的是高四位 定位元素用的是全部的值 为了避免两次散列的值一样(元素在segment散列开,但没有在hashentry散列开)
put 扩容成原数组的两倍,再将原数组散列插入到新数组中
size统计元素个数 先尝试两次不加锁的方案 ,如果两次线程数有变化,说明有其他线程修改 加锁获取size
concurrentHashMap1.8 红黑树:优化底层链表的遍历效率 怎样在很短的时间内把大量数据插入到concurrenthashmap
增加一个元素,加载队列的尾部,获取一个元素的时候会返回队列头部的元素
e 数据域 next next指针,指向下一个节点
构造函数初始化
node的cas操作避免线程安全问题
将节点加到队列尾部
1.将入队节点设置为当前节点的下一个节点 2.更新tail节点(如果tail节点的next节点不为空,就将入队节点置为tail节点
多线程入队列 offer ----如果-----且更新tail成功 p=next还没有越过两个节点的情况,会不断更新
失败了表示有其他线程成功更新了tail节点
总共做了两件事情 定位出尾结点 p 用CAS算法 把入队节点设置成尾结点的next节点,如果不成功,就不断重试 p=succ(p)
hops变量减少tail节点的更新频率,提高入队效率 tail节点与尾结点距离越长,则cas使用越少 每次循环很长时间才能定位到尾结点
增加tail变量的读操作 减少写操作,因为volatile写操作的开销远远大于读操作
出队列:从队列中返回一个节点元素并且清空节点对元素的引用
当head节点有元素,直接弹出head中的元素,而不会去更新head节点
阻塞队列 condition实现
队列满的时候,生产者线程put元素,队列会一直阻塞生产者的线程 ,直到队列可用或响应中断退出了
队列空的时候,消费者线程从队列take元素,队列会阻塞消费者线程,直到队列不为空
超时退出 阻塞队列满的时候,生产者线程往队列插入元素,队列会阻塞生产者一段时间,过了这段时间,生产者线程会退出
无界阻塞队列 用 put offer方法 永远不会被阻塞
公平:阻塞的线程可以按照阻塞的先后顺序访问队列
delayqueue proirity 延迟期满的时候才能从队列获取元素
保存缓存元素的有效期 使用一个线程循环查询delayqueue,一旦能从delayqueue获取元素说明缓存期到了
syncronazedqueue 默认情况下非公平,支持公平访问队列 不存储元素的阻塞队列 每一个put操作必须要等一个take操作,否则就不能添加元素
直接把生产者线程的数据传给消费者线程 不存储元素,吞吐量比其他阻塞队列大
linkedtransferqueue 链表组成的无界阻塞队列 比其他阻塞队列多了transfer方法 有消费者正在等待元素,比如说消费者使用take方法或者是带时间限制的poll方法的时候,transfer会将生产者的元素立刻传递给消费者
如果消费者没有等待元素,transfer方法会将元素储存到tail节点上,等这个元素被消费者消费了才会返回

linkedBlockingqueue 链表组成的双向阻塞 队列 从队列的两端插入或移除元素 多了几个操作队列的入口 多线程同时入队列的时候能减少一半的竞争 用的时候初始化的时候最好设置一下容量
为什么阻塞队列能知道队列是否已满 通知模式 队列已满,生产者队列被阻塞,消费者消费了一个线程,就会通知生产者
用了condition方法
put方法,当队列已满,调用await方法

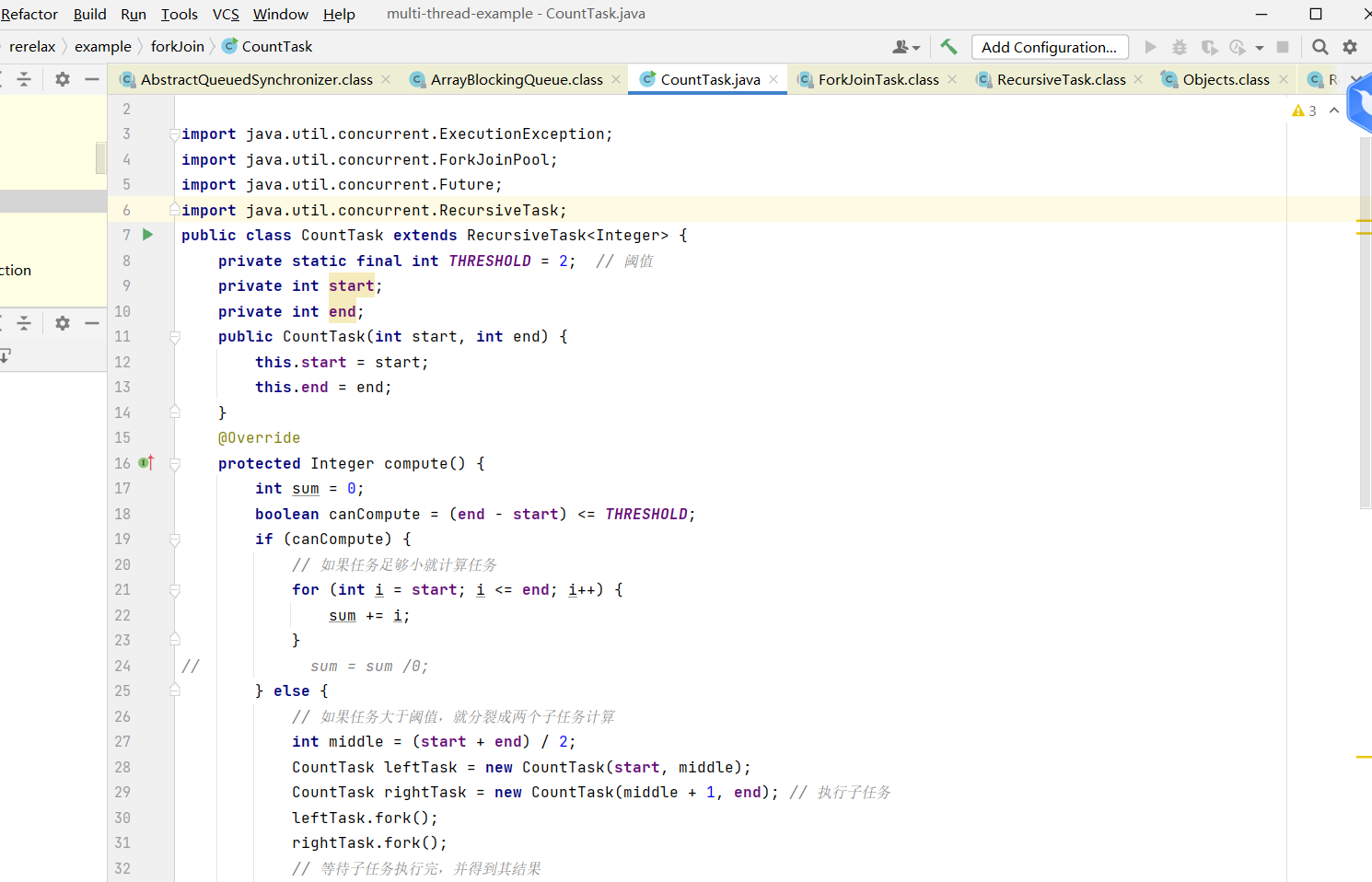
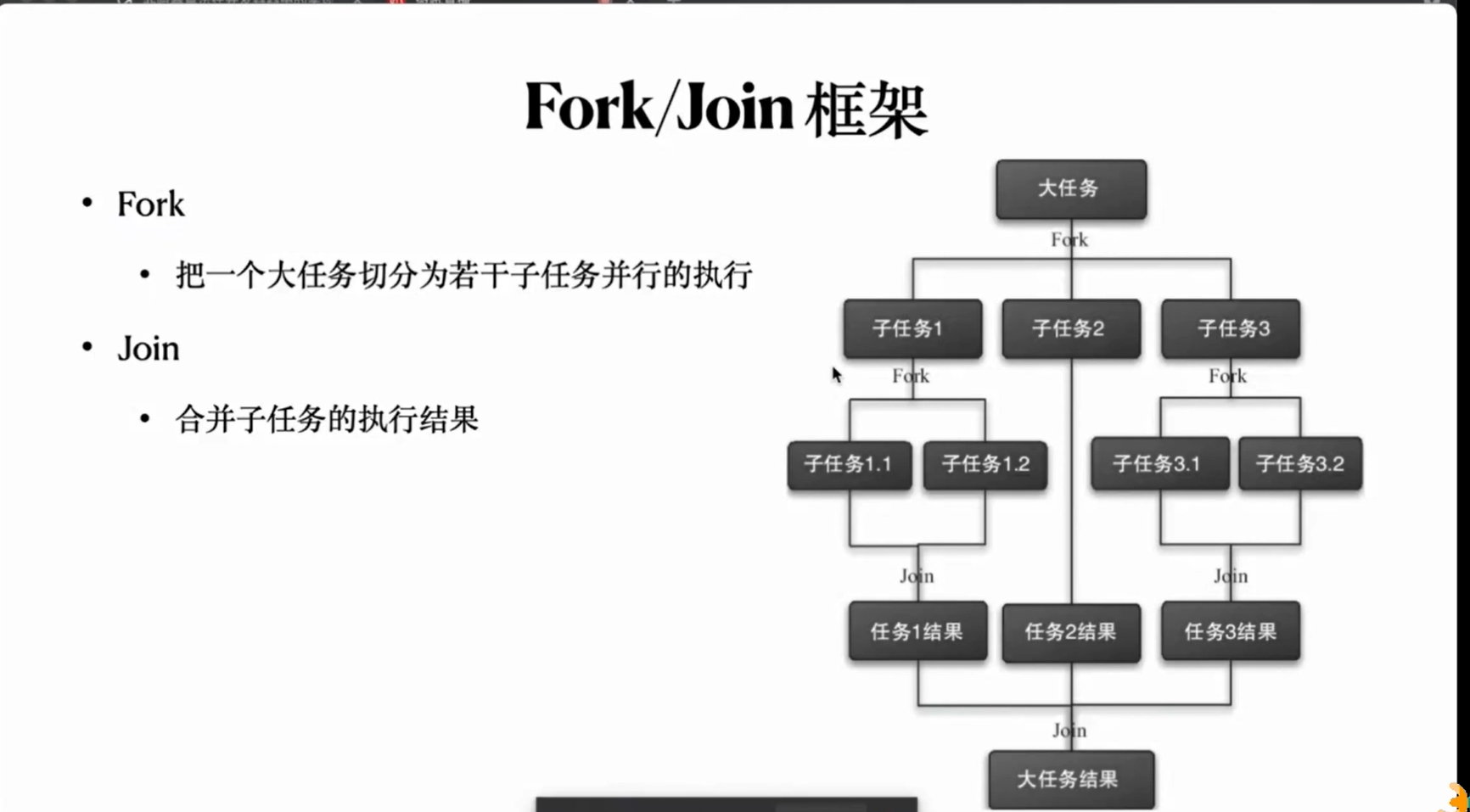
fork、join框架
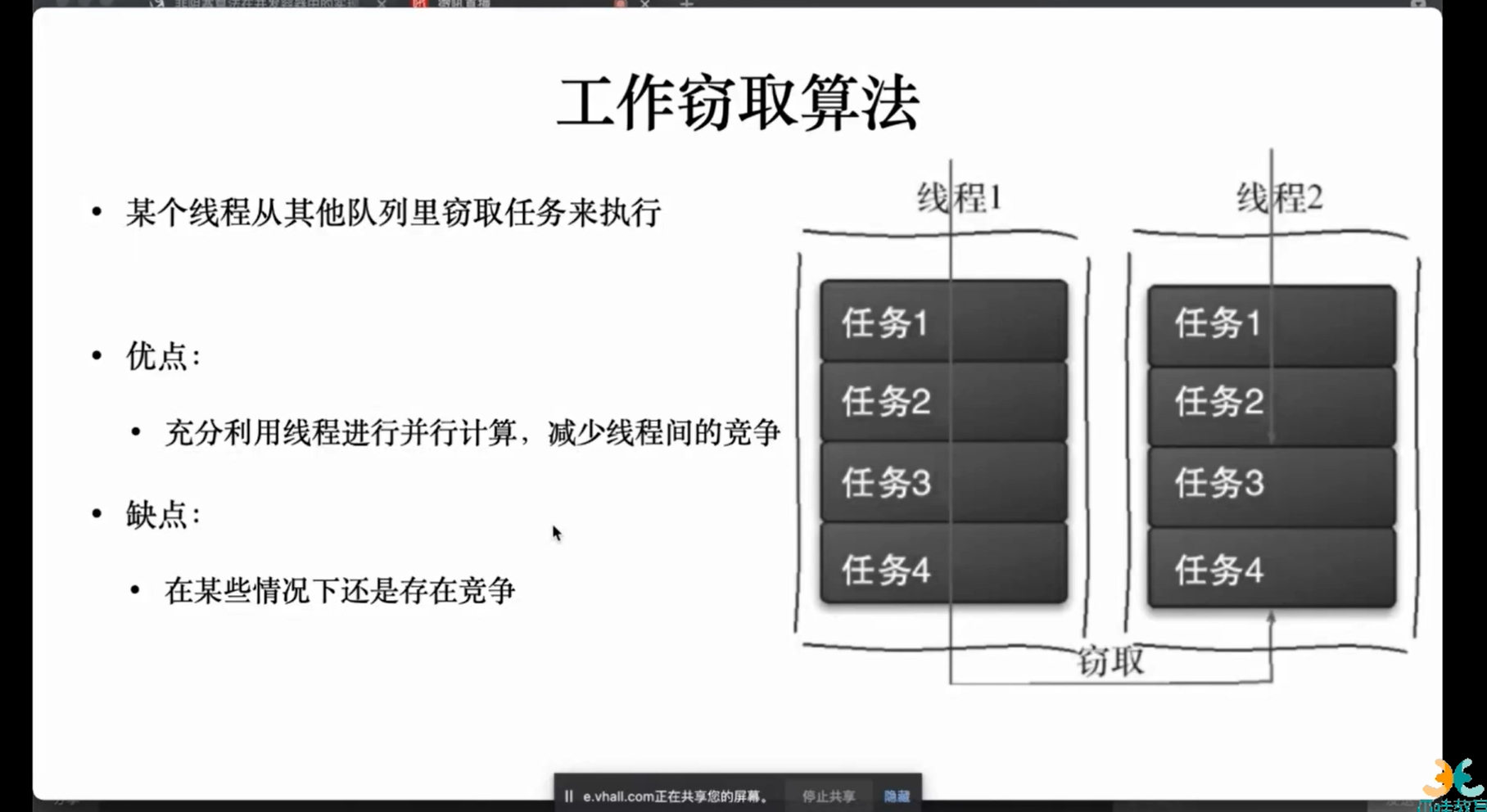

如果没有任务,会从其他线程的尾部随机拿任务