线程池
使用线程池的好处:1降低资源的消耗(降低线程 2.提高响应速度 3提高线程的可管理性

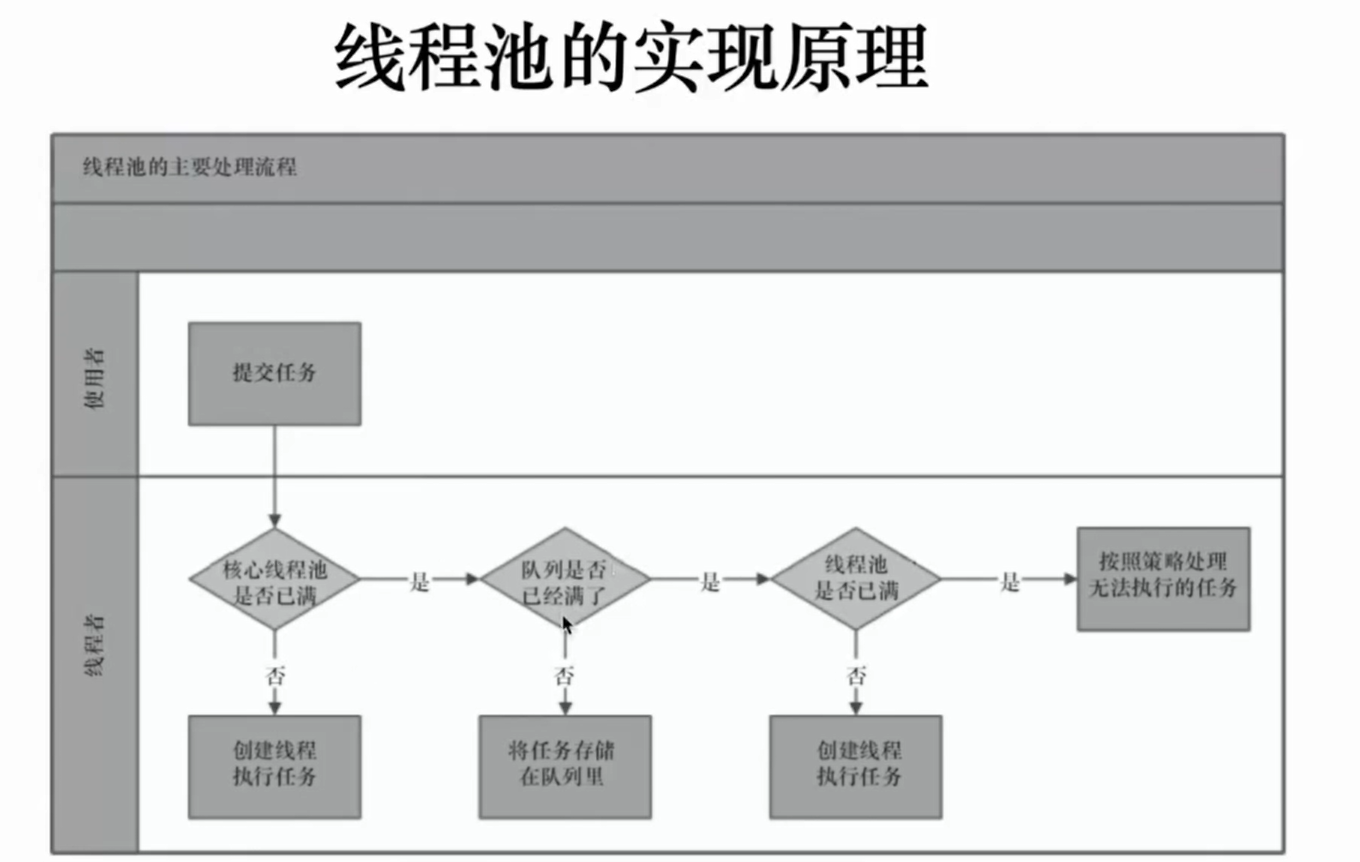
1.基本大小,没达到基本大小会继续创建线程
2.已达到基本大小,放入到等待队列
3、阻塞队列已满,未达到最大线程数,继续创建线程,如果用了无界的队列,则此参数没有用,因为无界队列没有限制
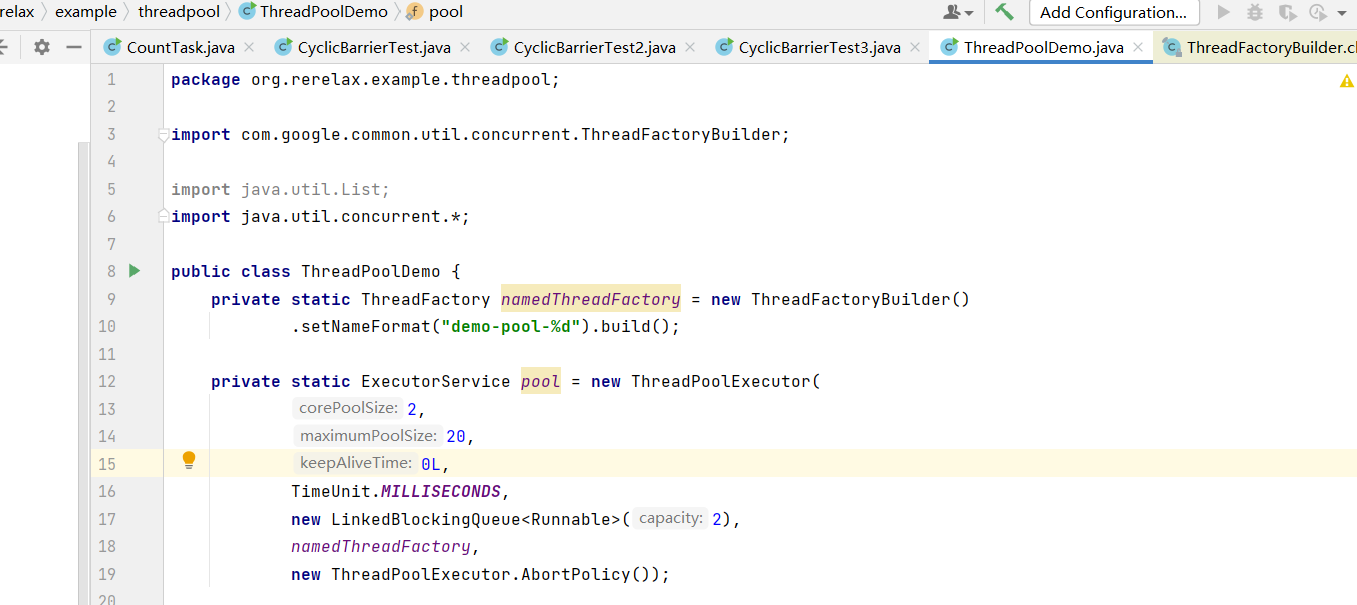
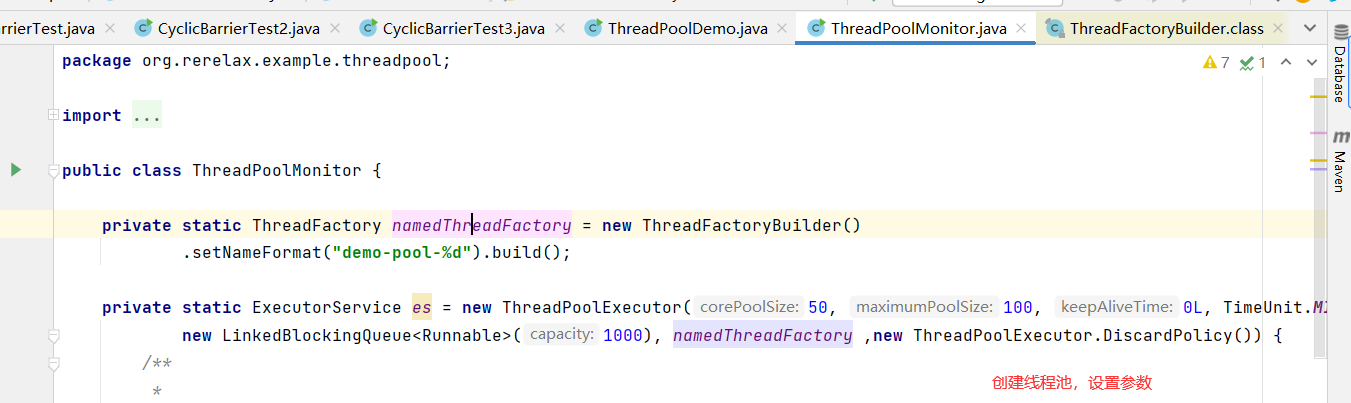
4.通过这个工厂为每一个线程设置一个更有意义的名字,方便监控和管理(如gruva的threadFactoryBuilder)
5.达到最大线程数,使用饱和策略
6.达到阻塞队列还没有到达最大线程数的线程,达到存活时间后工作线程会被销毁
7.单位,always等 ,minisecond
threadpolldemo

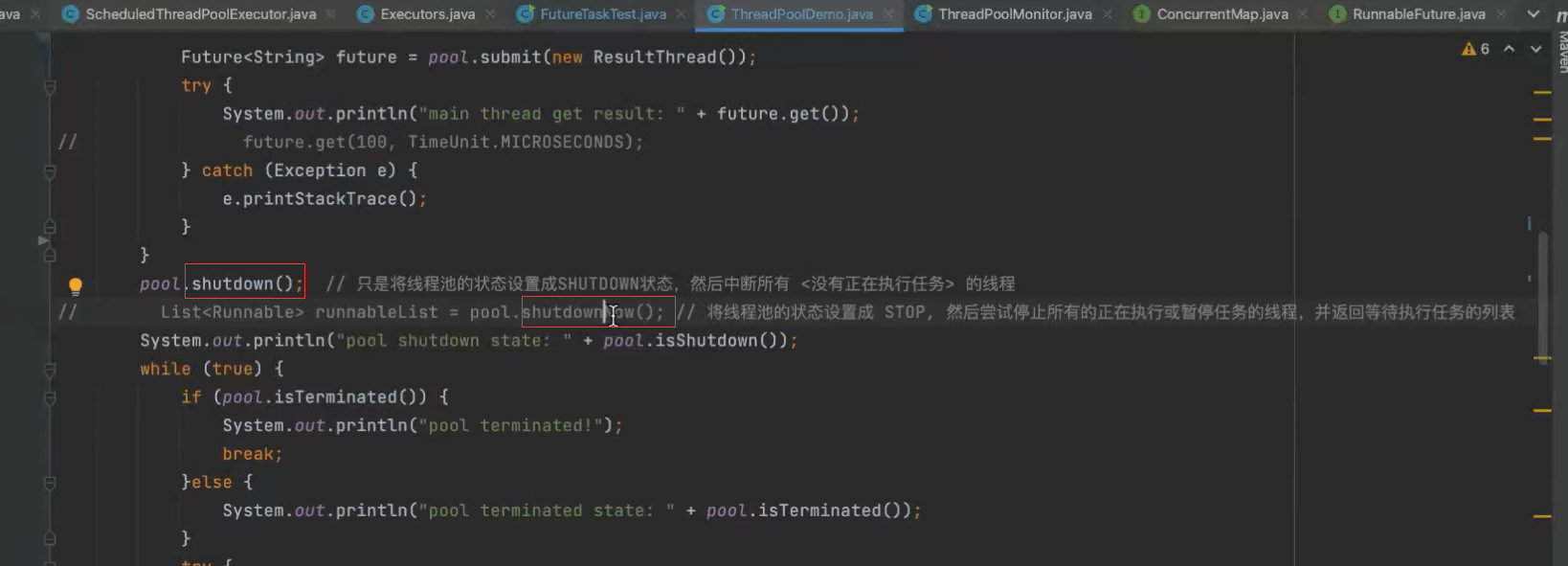
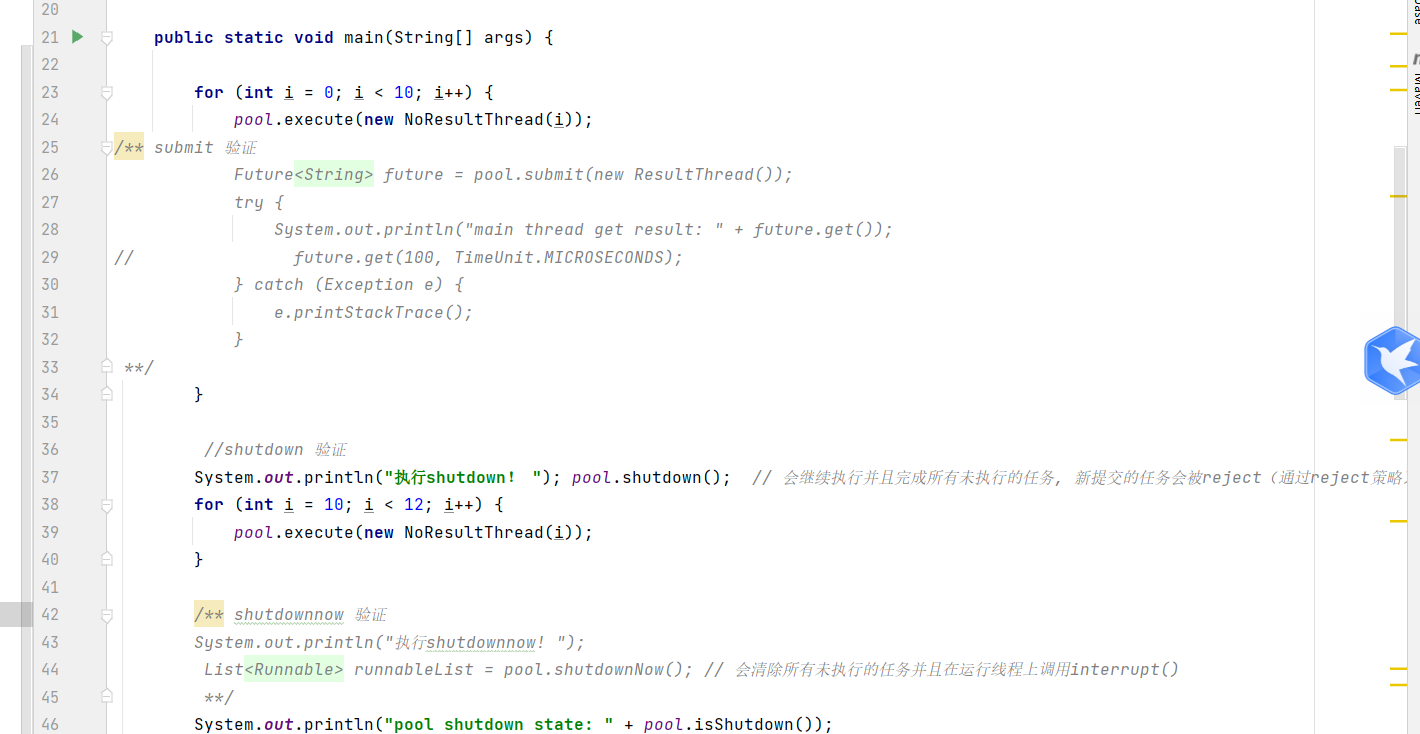

调用shutdown或shutdownnow方法,pool。isShutdown方法为TRUE,但isTerminatedt方法不一定 所有线程关闭后isTerminated方法才为TRUE
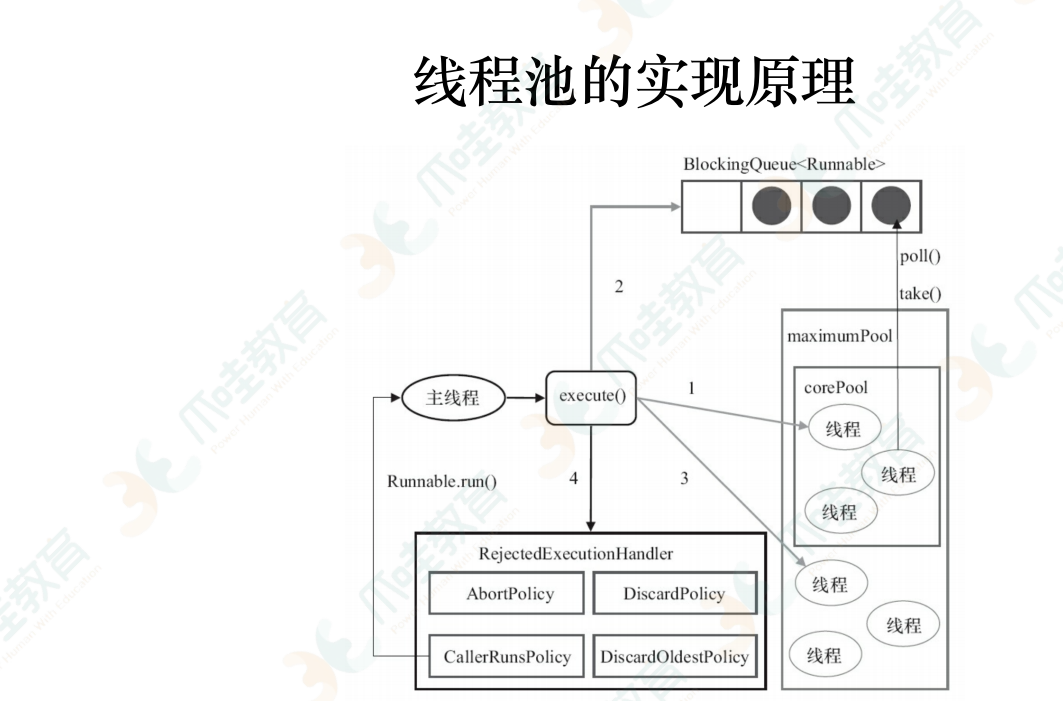
尽可能避免全局锁 ,提高性能
源码
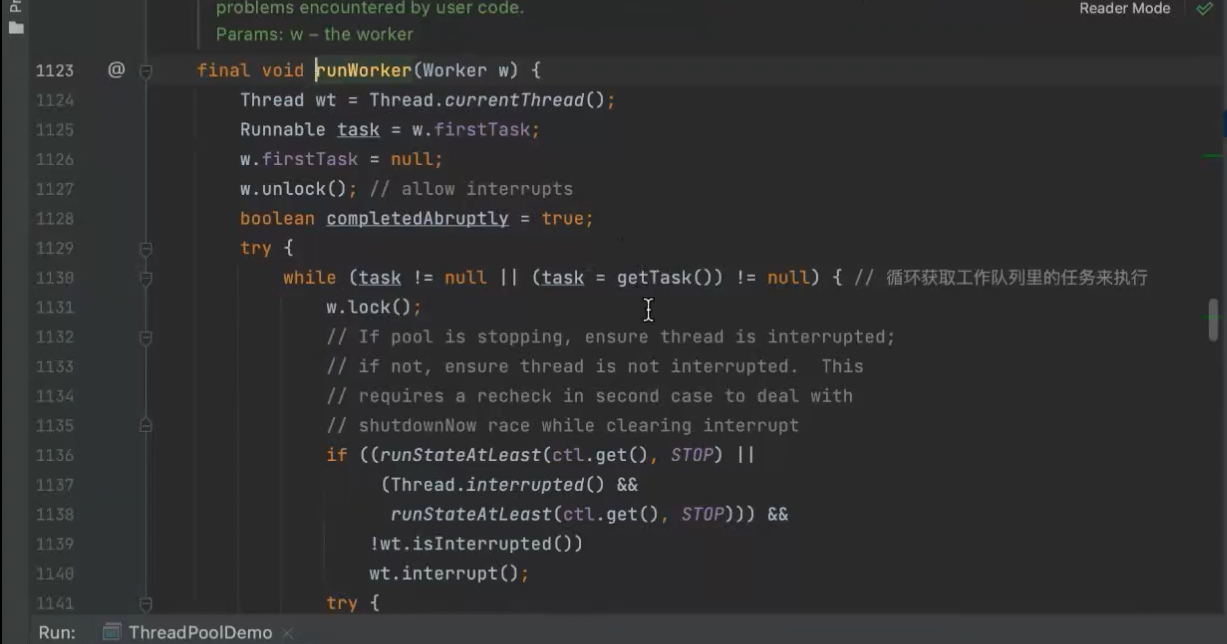
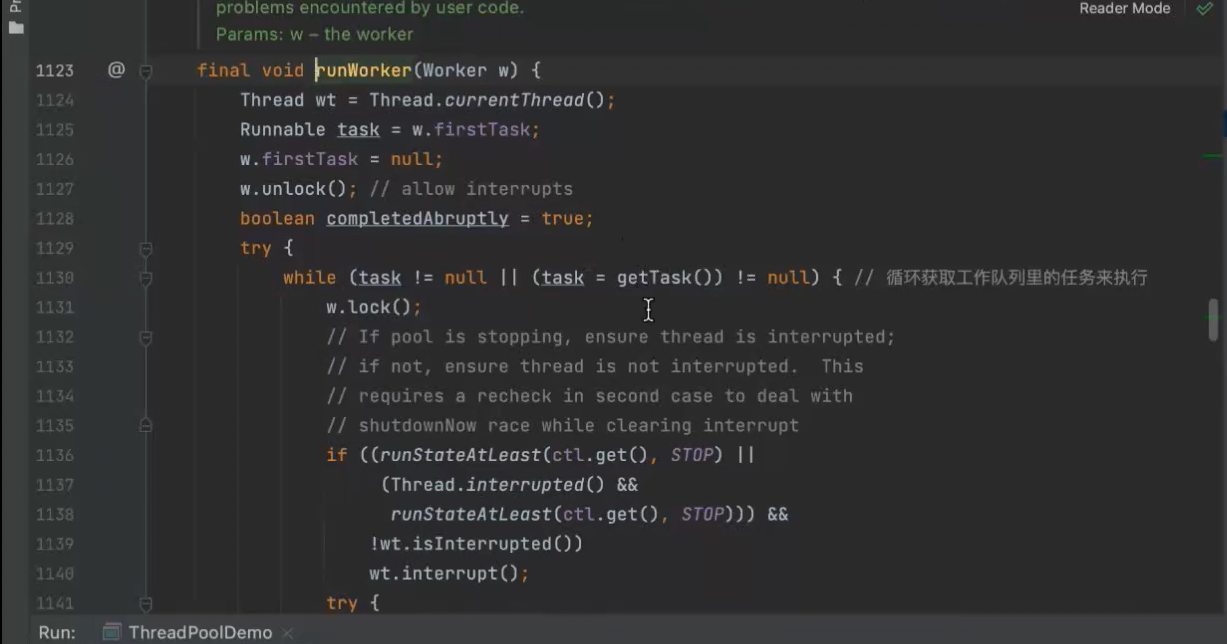
run方法 里面的runworker方法 不断获取工作队列里面的任务而执行


cpu密集型 配置比较小的线程 n cpu+
io密集型 线程不一定在执行任务 尽可能多的配置线程
混合型 拆分需要分解之后两个任务执行时间相差不是特别大 ,比串行的执行效率高
获取cpu的数量 N
执行时间:priortityBlockingqueue 执行时间短的任务先执行
如果任务有依赖性,比如依赖项目web资源 数据库的连接 线程提交sql之后需要等待sql返回的结果 等待的时间越长,cpu的空暇时间就越长 和io密集型类似,这时候线程的数量应该设置的更大一点,这样才能更好的利用cpu
如果需要依赖web资源 使用有界队列 因为有界队列增加队列的稳定性 ,可以根据需要设置的大一点
队列和线程池都满了 抛出异常 排查问题是数据库出了问题 查询sql特别慢 因为这些线程都是需要向数据库查询和插入数据的 就导致线程池里的线程全部被阻塞了 任务全都被积压在线程池里了 如果用无界队列,会把整个内存撑满

taskCount 线程池需要执行的任务数量
completedTaskCount 线程池运行过程中已完成的用户数量 <=taskCount
3曾经创建过的最大数量 如果这个值等于线程池的最大数量 说明线程池曾经满过 可以进行调优
4 线程池的线程数量 如果线程池不销毁的话 这个大小会不断增加
5处于活跃的线程数
6扩展线程池 继承ThreadPoolExcuter方法自定义线程池 在线程执行前后用代码监控 相当于对线程里的任务做了切面 比如监控任务的平均执行时间 最大执行时间



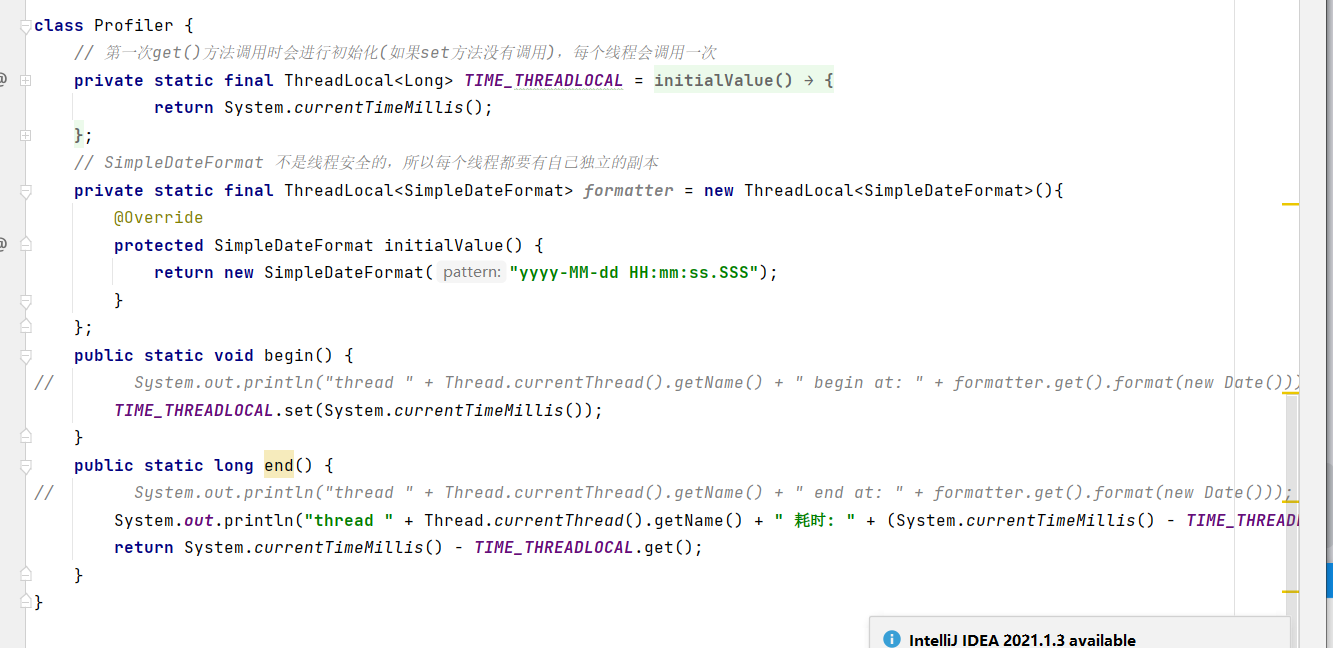
获取时间的线程安全的类

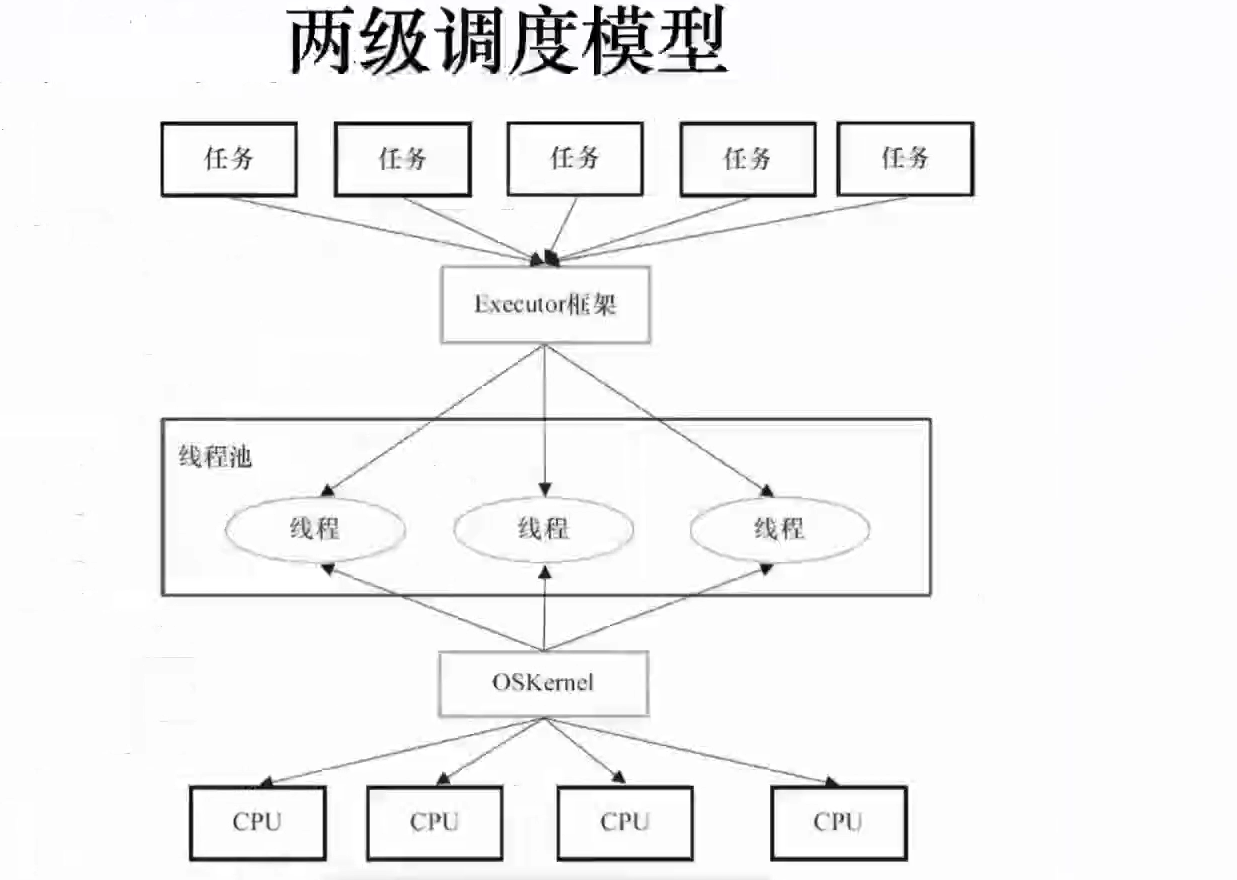
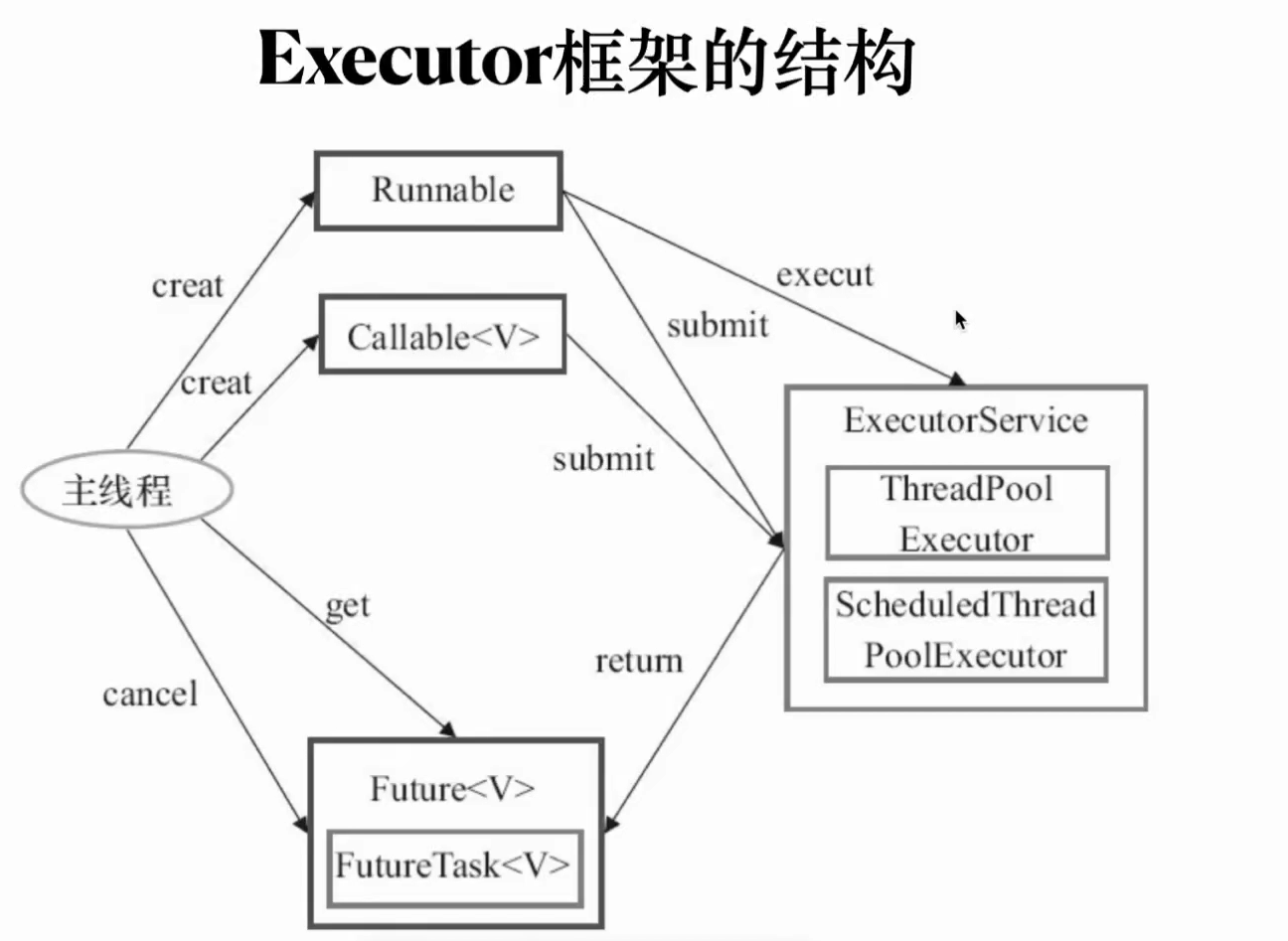
1任务 runnable和callable接口 2.任务的执行 excutor接口 ThreadPoolExcutor 线程池 定时或周期性的执行任务 3结果 FutrueTask
ThreadPoolExecutor 继承AbstractExecutorService implements ExecutorService extends Executor
java线程和本地操作系统的线程是一一映射的,java线程启动的时候会创建一个本地操作系统的线程 java线程终止,本地。。。操作系统的线程也会终止
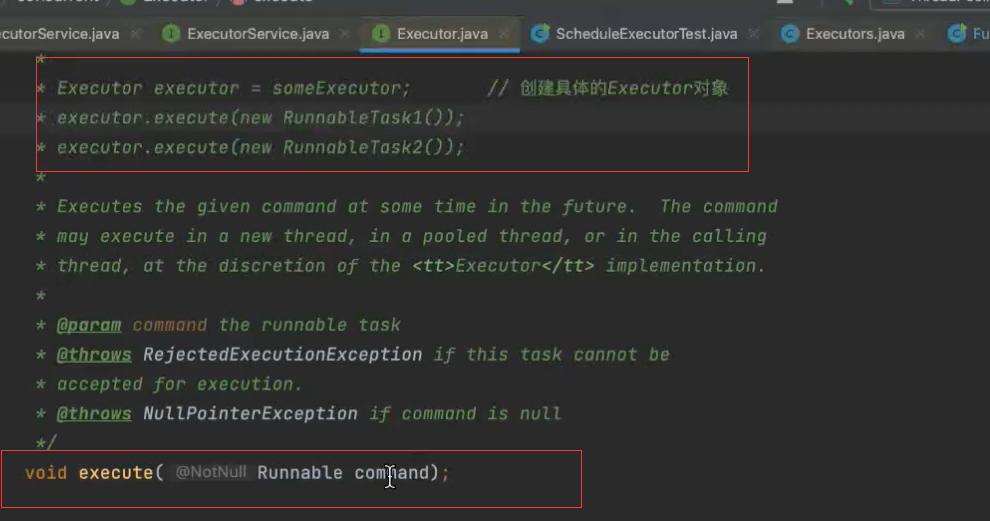
excutor方法 设计思想 解耦了任务和任务的执行 入参是待执行的任务

excutorService在1.5的时候随juc引入 对excutor的扩展,丰富了excutor方法的功能 submit isShutdown shutdown shutdownnow
增强了对任务的控制 和自身生命周期的管理

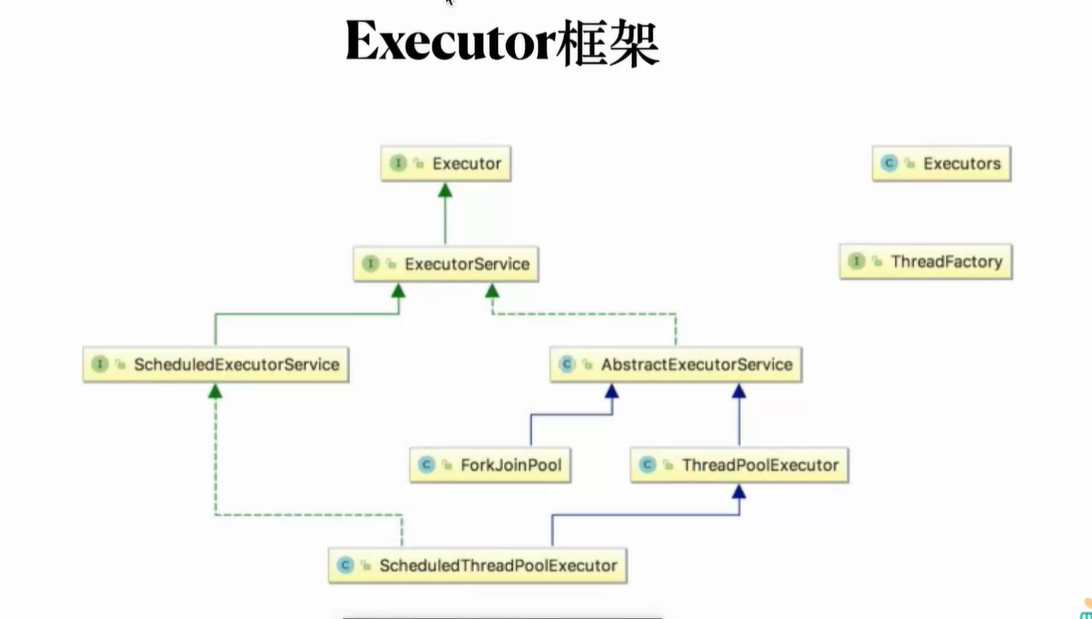


不建议使用EXCUTORS创建线程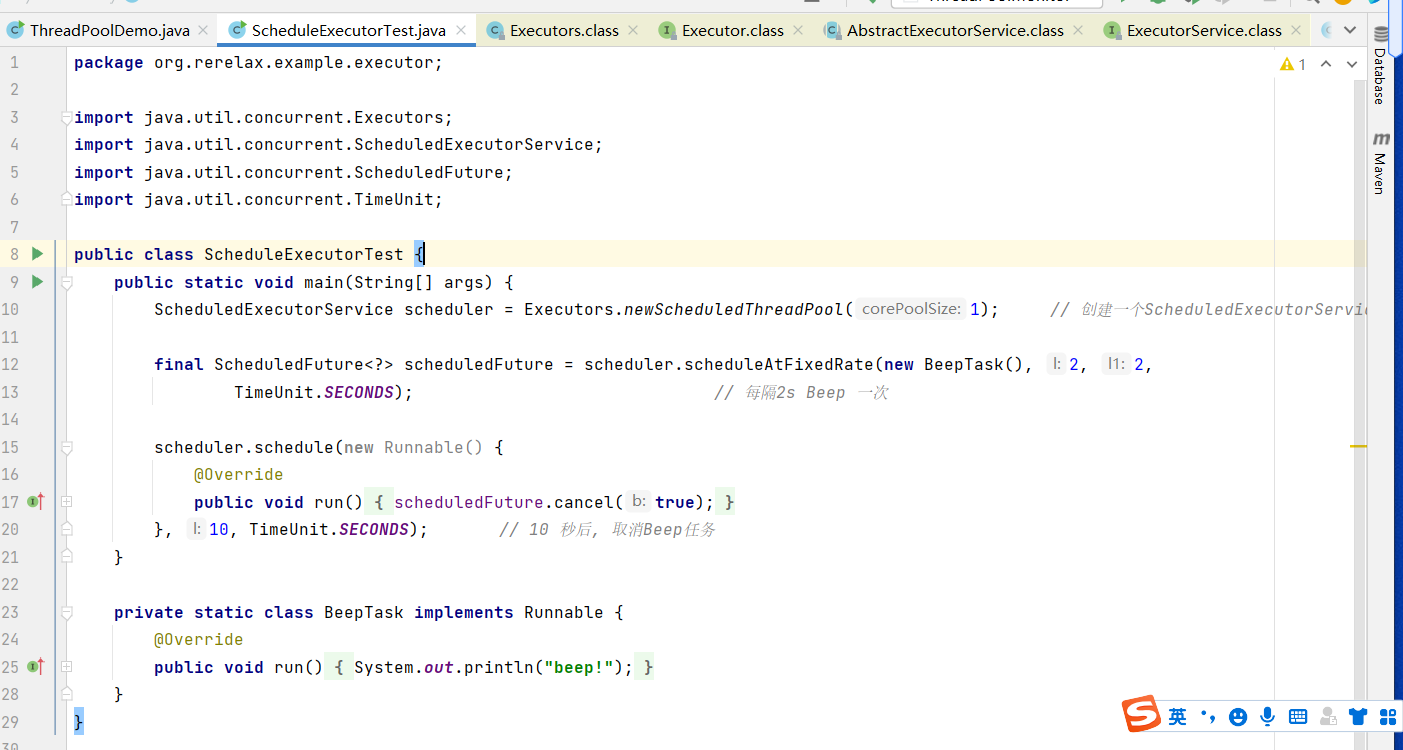
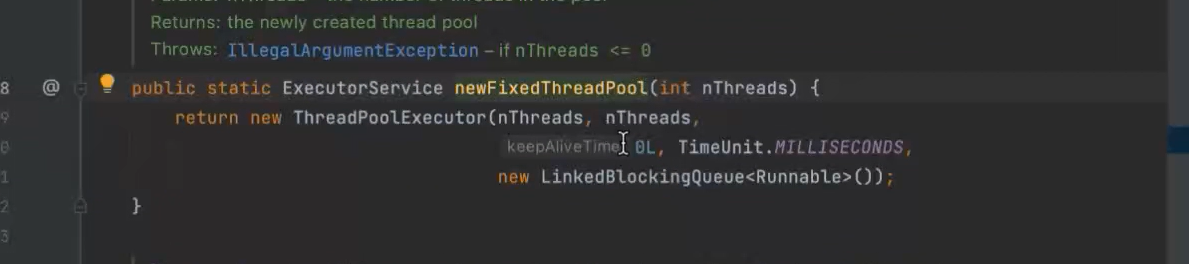
应用场景:限制线程池数量,满足资源管理的需求
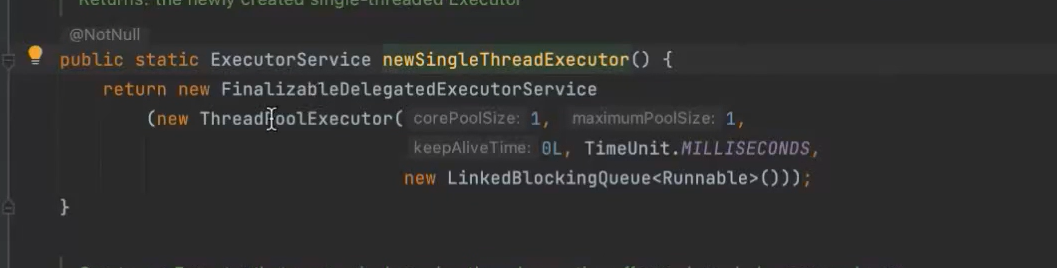
应用场景:保证顺序的执行各个任务,
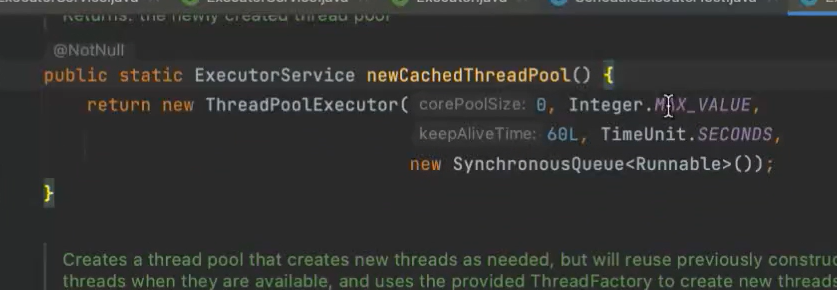
执行时间比较短,任务量较大的情况

多个线程执行周期性的执行任务 同时满足资源管理的需求 (限制线程的数量,不让负载过大)
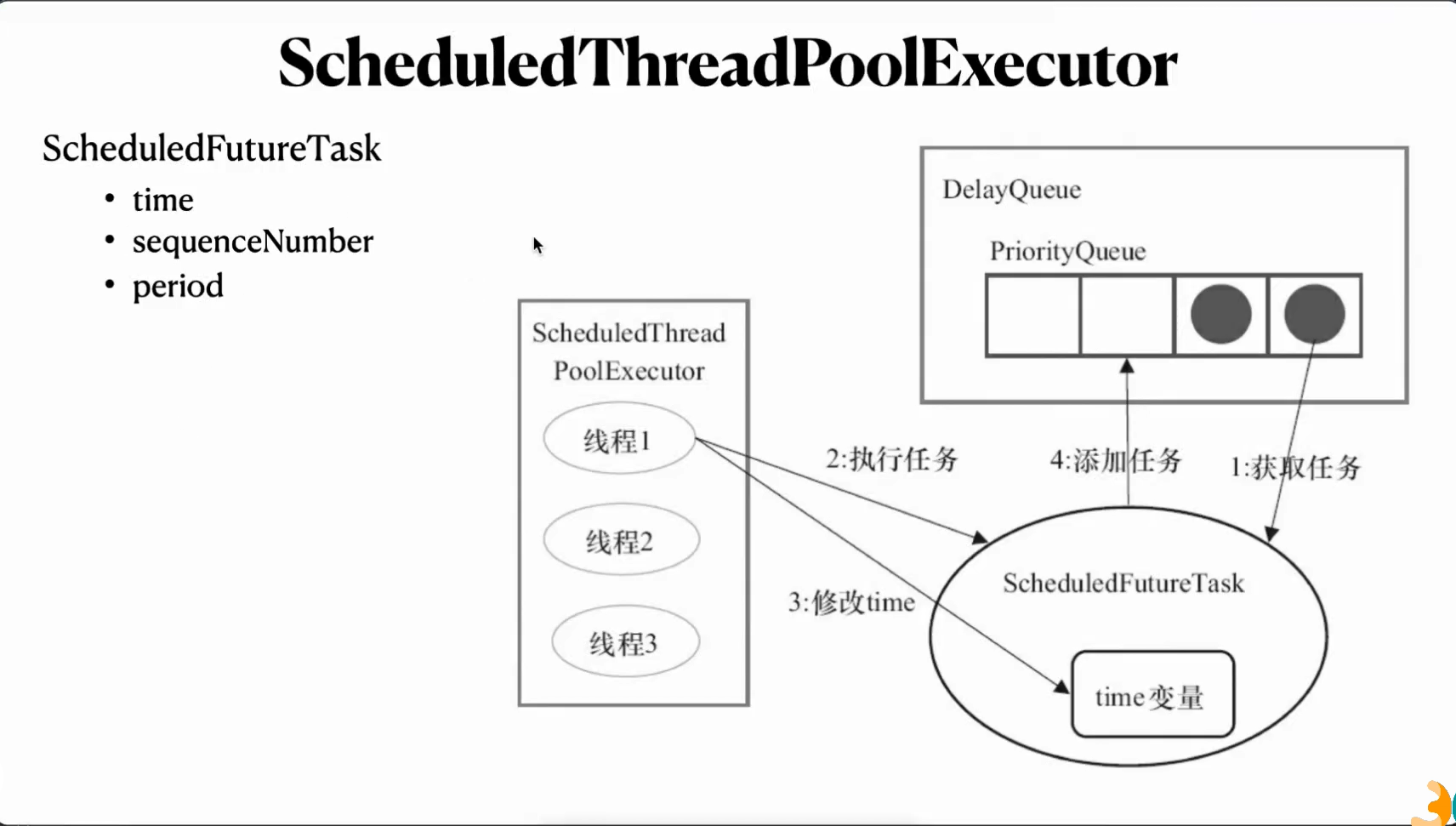
三个参数 time long型变量 任务将要被执行的具体时间
sequenceNumber 任务被加入到queue的序号,每次提交都会加
period 每次执行的周期
delayqueue封装了priorityqueue time小的任务会排在priorityqueue的前面,time相同会比较sequenumber
执行任务步骤:首先通过deleyqueue的take方法,priorityqueue会获取scheduledfutureTask time大于等于当前时间的,拿到时间后会执行schedulefutureTask,修改time,改成下一次需要执行的时间,修改完时间后再添加回queue队列
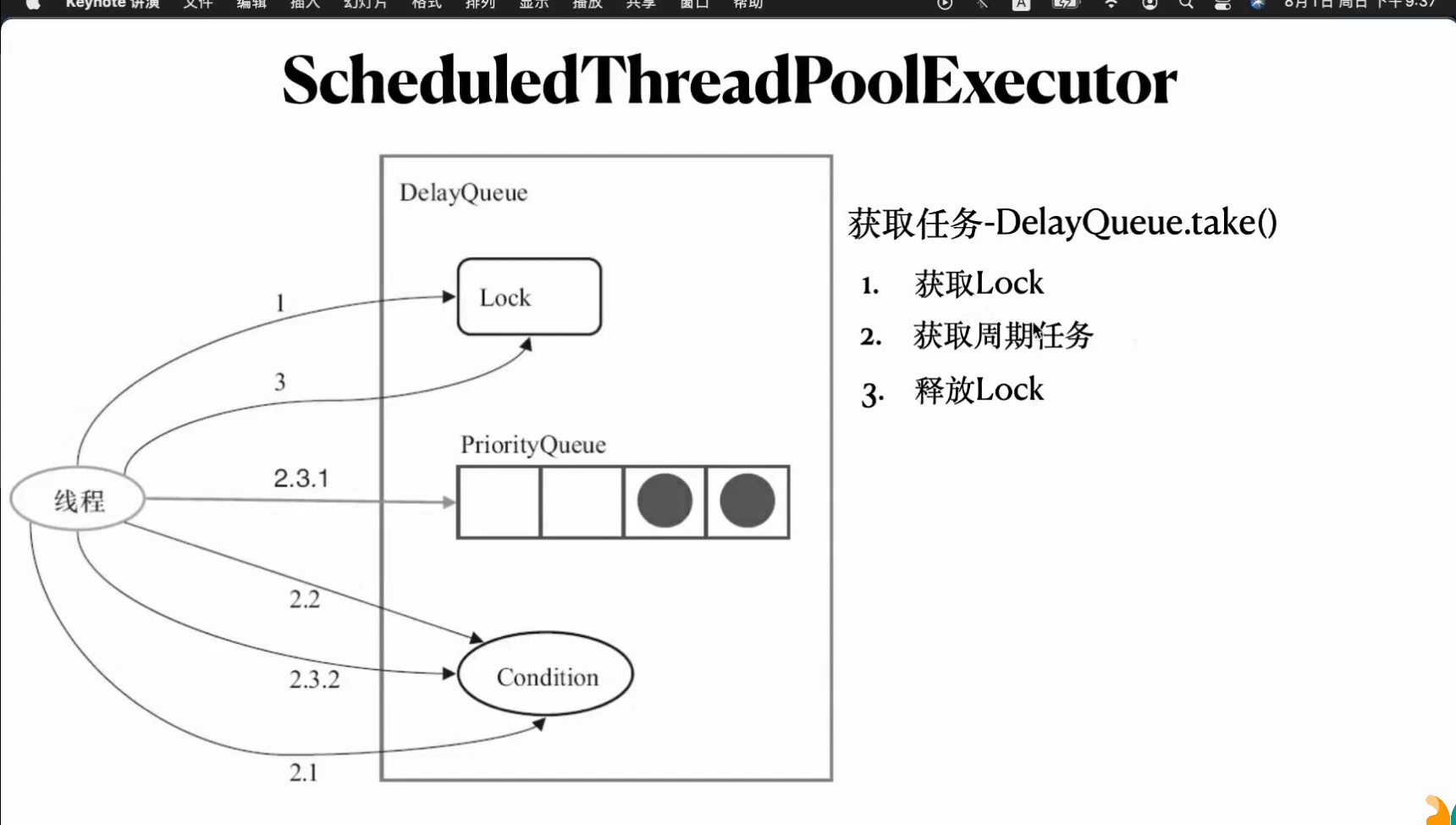
2.1 priority是空的,线程会被阻塞在condition中 2.2如果priority里非空,要等待time过期才会执行,所以还被阻塞在condition中 吧2.3.1time到期会去拿头元素,再判断prioritty是否为空,非空则唤醒condition里面的线程
第二步在循环里获取任务
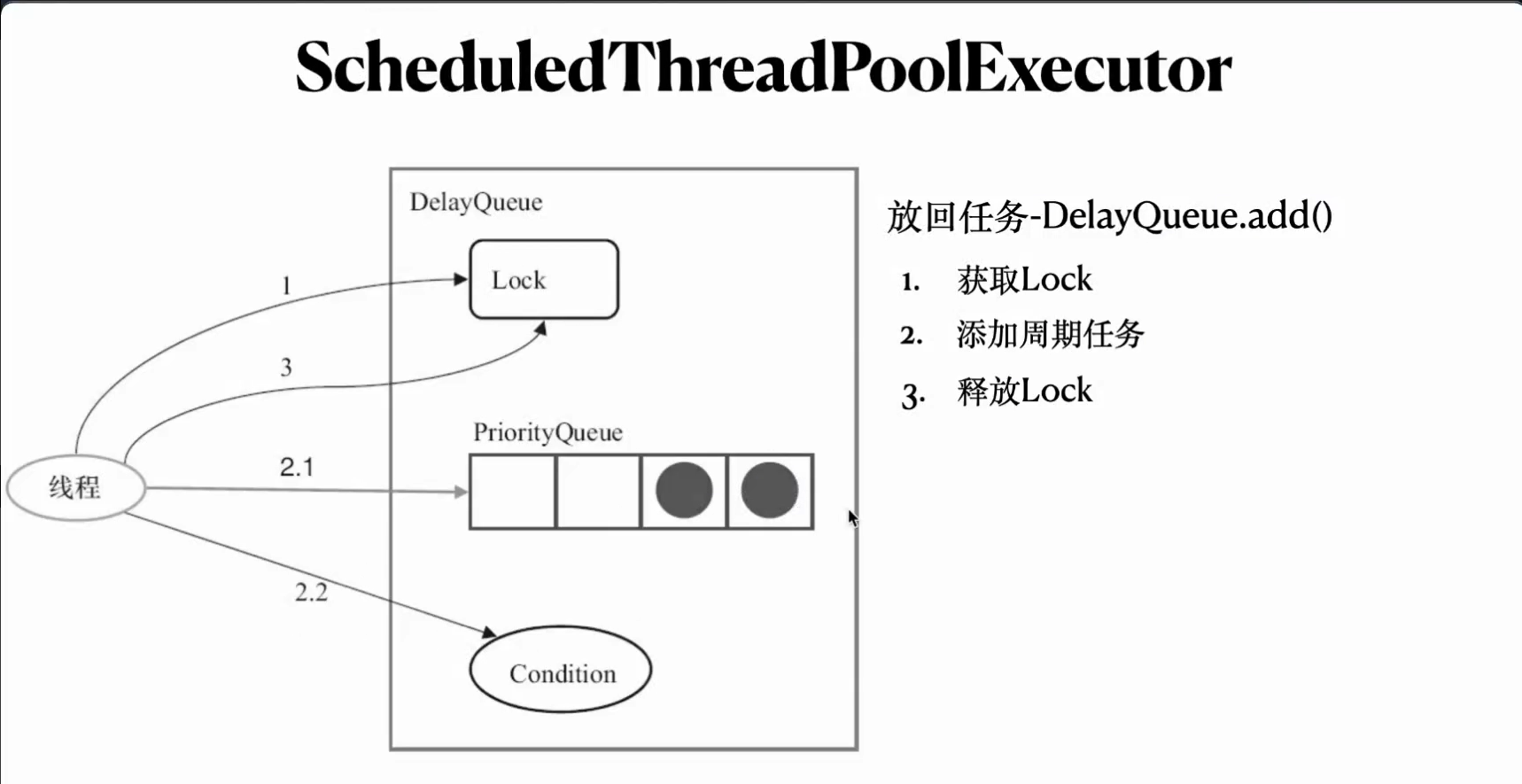
2.如果是头元素的话,去condition唤醒线程再添加

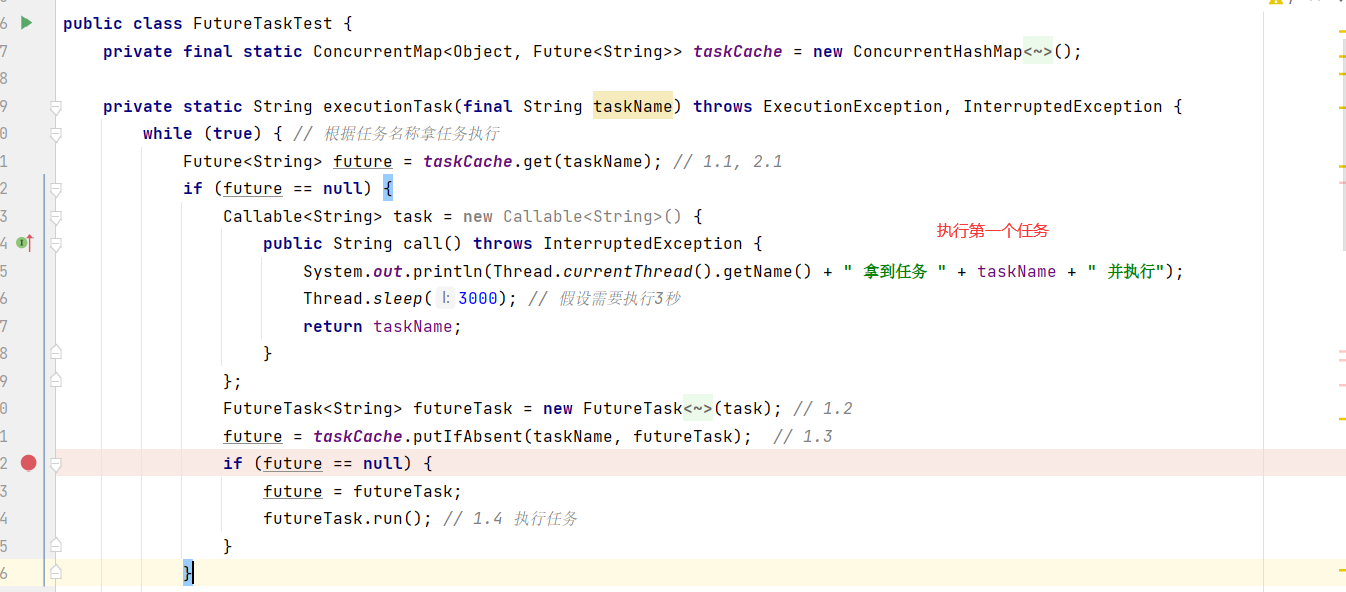
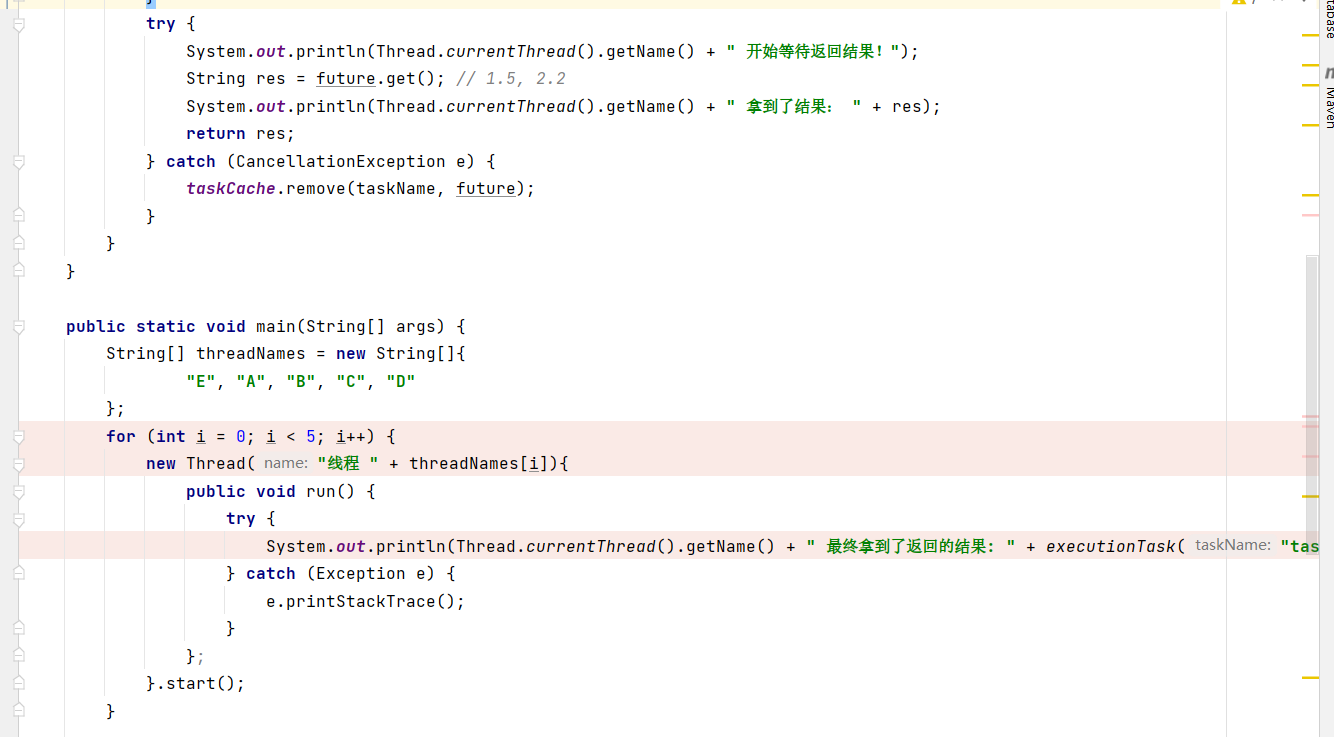
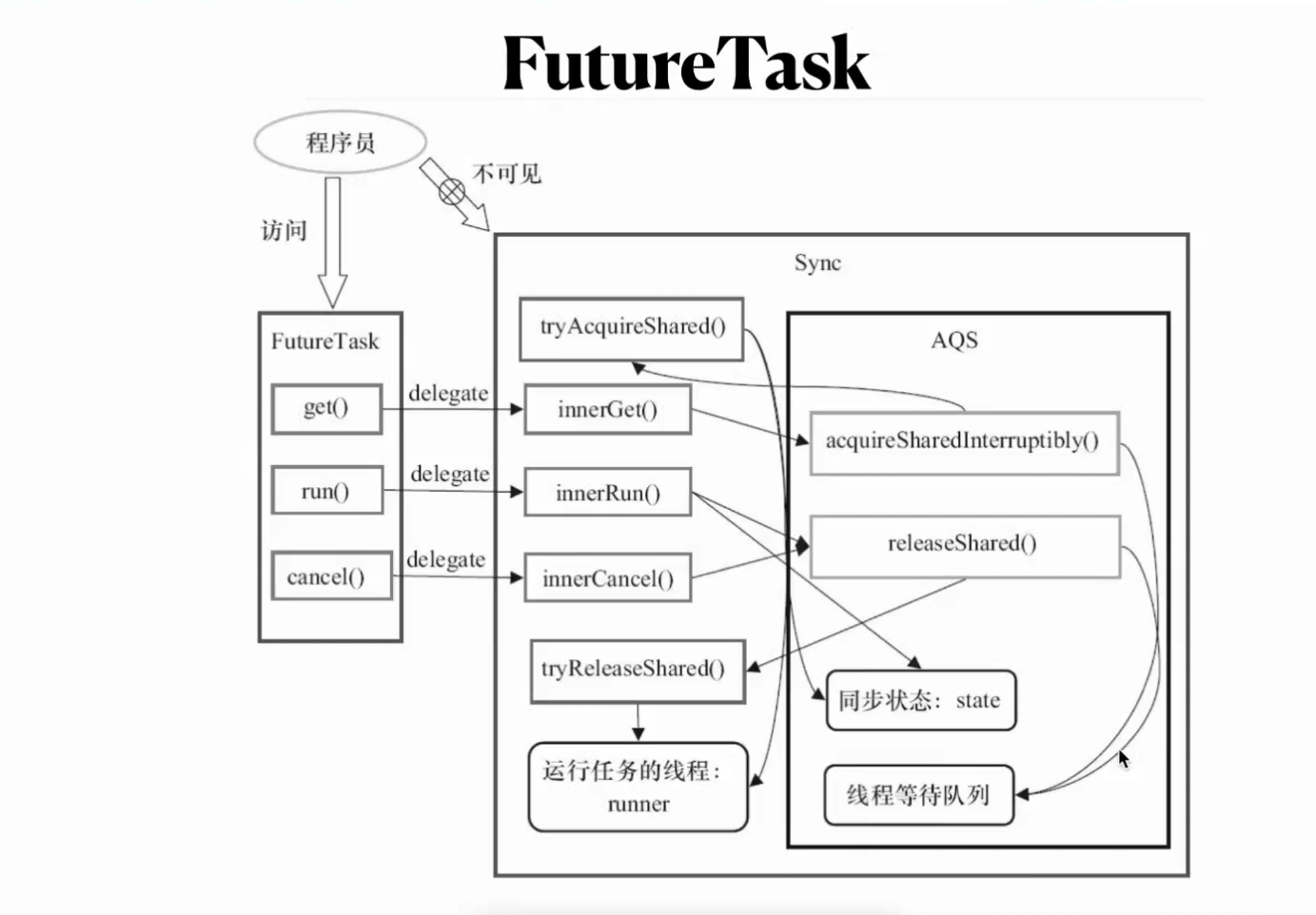
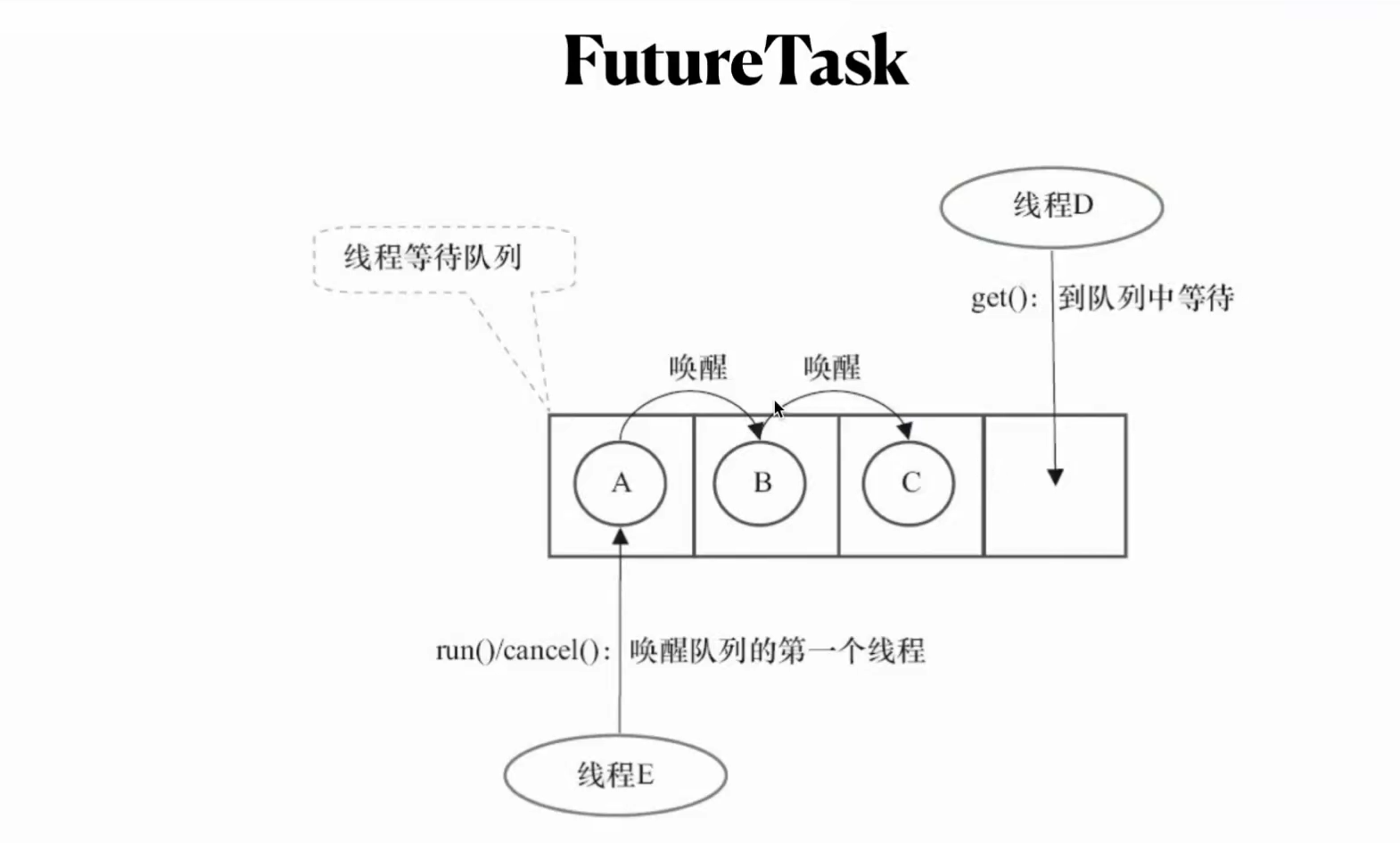
FUTUREtask implements runnableTask extends Future,Runnable
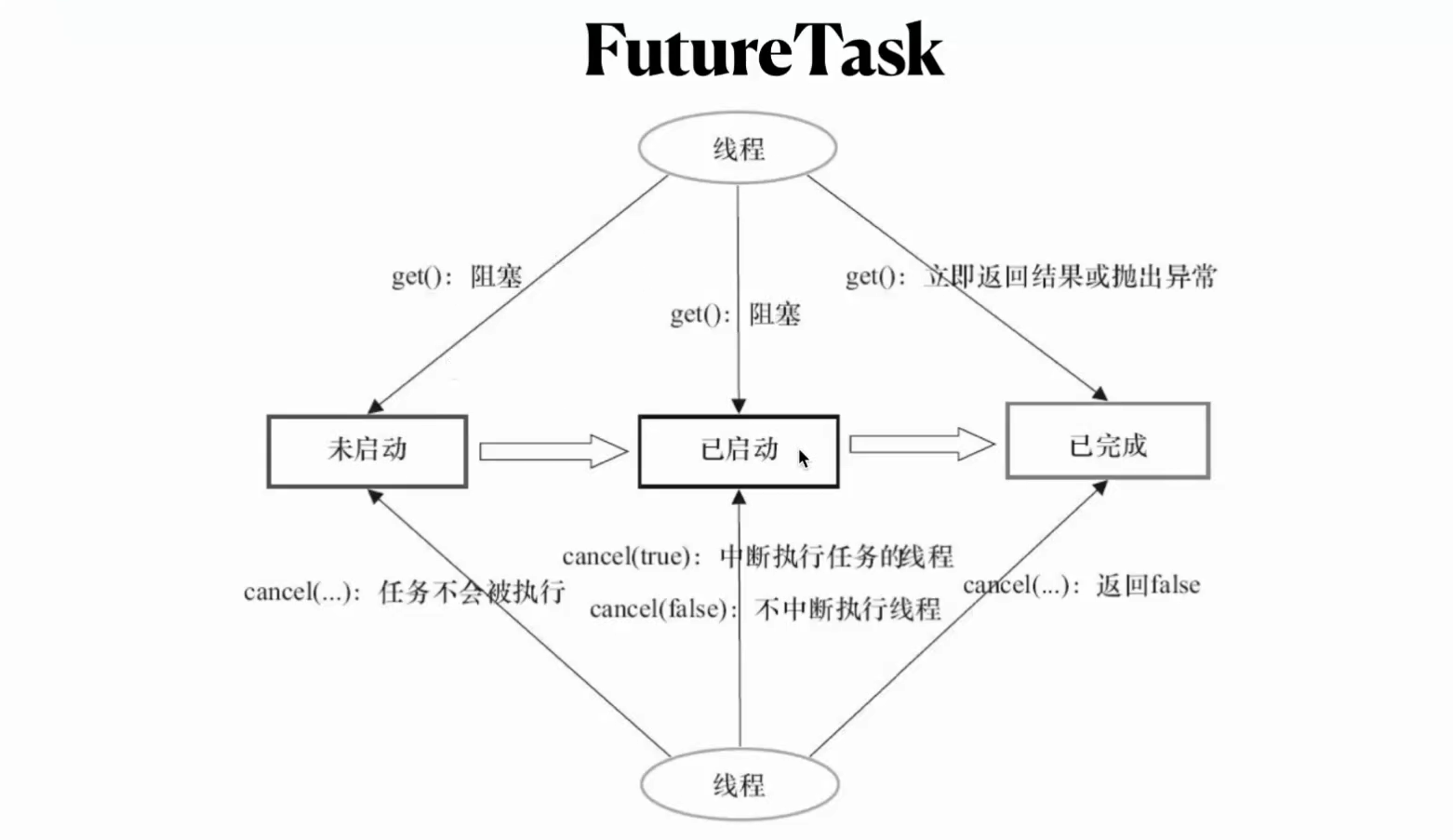
可以直接用pool.submit返回future 一个任务在等待另一个任务执行结束的时候可以用FutureTask,类似于join方法

、、、、、