
kafka
kafka为什么采用消费者主动拉的模式:
kafka的性能非常高(qps10-20万(QPS:全名 Queries Per Second,意思是“每秒查询率”,是一台服务器每秒能够响应的查询次数,TPS 即 Transactions Per Second 的缩写,每秒处理的事务数目)
但凡下游消费者的能力达不到这个程度,就很容易把消费者打挂,也很容易导致消费者的消息堆积,严重的话会影响业务,消费者可以定制消费速率
Kafka 是⼀个分布式的基于发布/订阅模式的消息引擎系统
两种消费模式
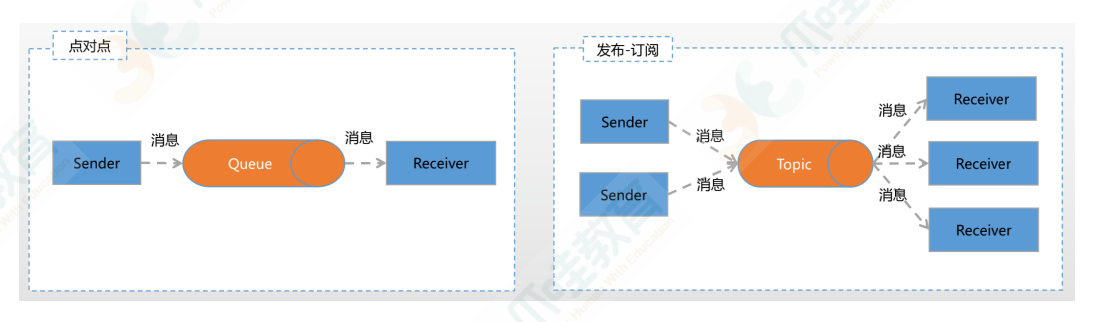
架构图

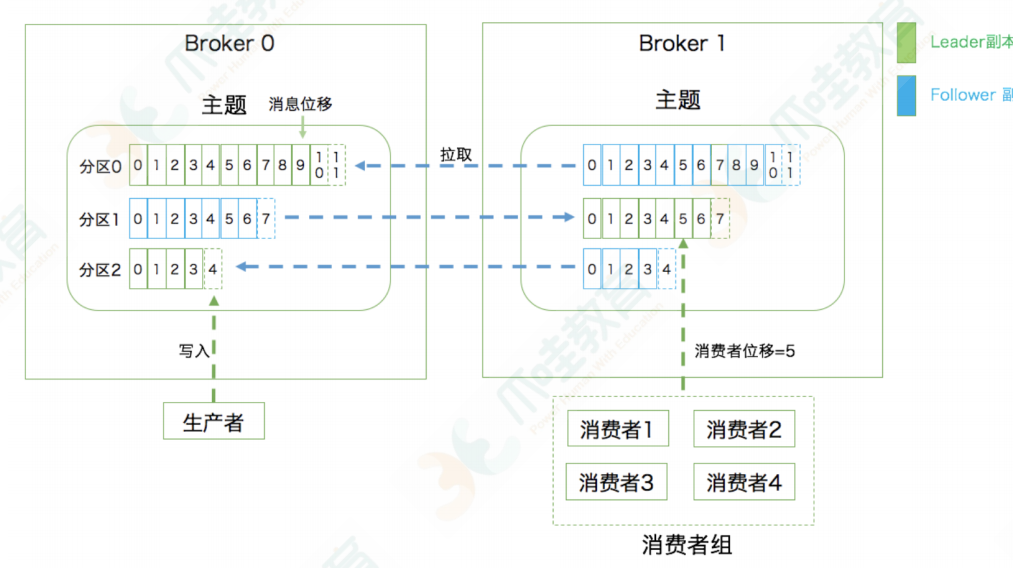
⽣产者:Producer。向主题发布新消息的应⽤程序。消息有存储时间,默认是7天,仍在磁盘中
消费者:Consumer。从主题订阅新消息的应⽤程序。 一个partition只会给一个consumer消费,Consumer可以消费一个broker里的多个partition
消息:Record。Kafka是消息引擎嘛,这⾥的消息就是指Kafka处理的主要对象。
主题:Topic。主题是承载消息的逻辑容器,在实际使⽤中多⽤来区分具体的业务。
分区:Partition。⼀个有序不变的消息序列。每个主题下可以有多个分区。(每一个topic都有多个partition,每个partition有2-3个副本,每一个副本分布在不同的broker上)
消息位移:Offset。表示分区中每条消息的位置信息,是⼀个单调递增且不变的值。这个位置记录在broker的一个topic里面,专门用来存储offset
副本:Replica。Kafka中同⼀条消息能够被拷⻉到多个地⽅以提供数据冗余,这些地⽅就是所谓的副
本。副本还分为领导者副本和追随者副本,各⾃有不同的⻆⾊划分。副本是在分区层级下的,即每个分
区可配置多个副本实现⾼可⽤。
消费者位移:Consumer Offset。表征消费者消费进度,每个消费者都有⾃⼰的消费者位移。
消费者组:Consumer Group。多个消费者实例共同组成的⼀个组,同时消费多个分区以实现⾼吞吐。
重平衡:Rebalance。消费者组内某个消费者实例挂掉后,其他消费者实例⾃动重新分配订阅主题分区
的过程。Rebalance是Kafka消费者端实现⾼可⽤的重要⼿段。
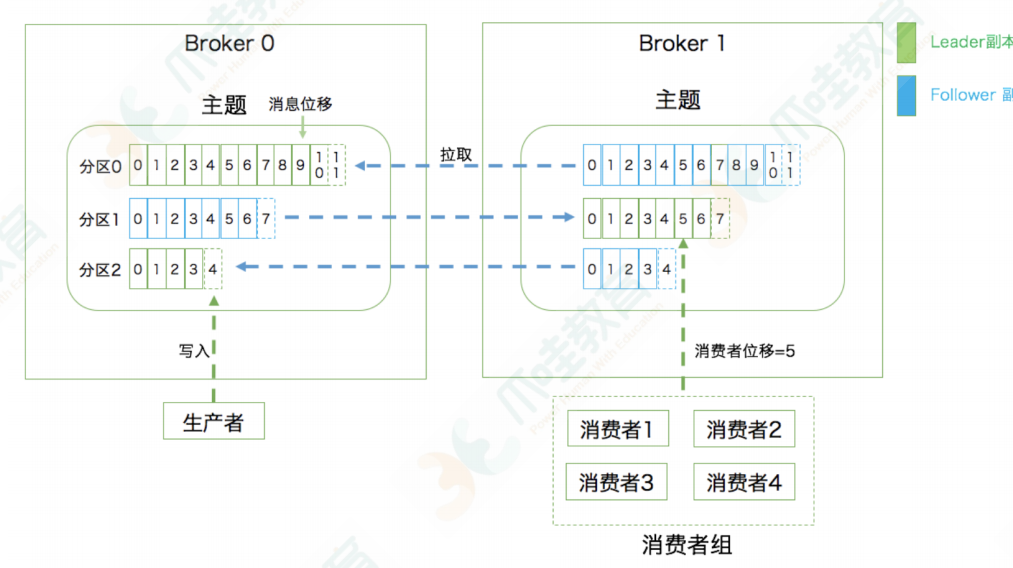
如果要保证kafka的全局有序,可在一个topic下只挂一个分区,单分区是数据有序的
高性能:建立的分区多,是为了提高kafka的并行度
kafka特性深⼊剖析
#⽇志存储
Kafka 中的消息是以主题为基本单位进⾏归类的,各个主题在逻辑上相互独⽴。每个主题⼜可以分为⼀
个或多个分区,分区的数量可以在主题创建的时候指定,也可以在之后修改。每条消息在发送的时候会
根据分区规则被追加到指定的分区中,分区中的每条消息都会被分配⼀个唯⼀的序列号,也就是通常所
说的偏移量(offset)。
不考虑多副本的情况,⼀个分区对应⼀个⽇志(Log)。为了防⽌ Log 过⼤,Kafka ⼜引⼊了⽇志分段
(LogSegment)的概念,将 Log 切分为多个 LogSegment,相当于⼀个巨型⽂件被平均分配为多个相
对较⼩的⽂件,这样也便于消息的维护和清理。
cd log/tmp/kafka-logs 查看日志

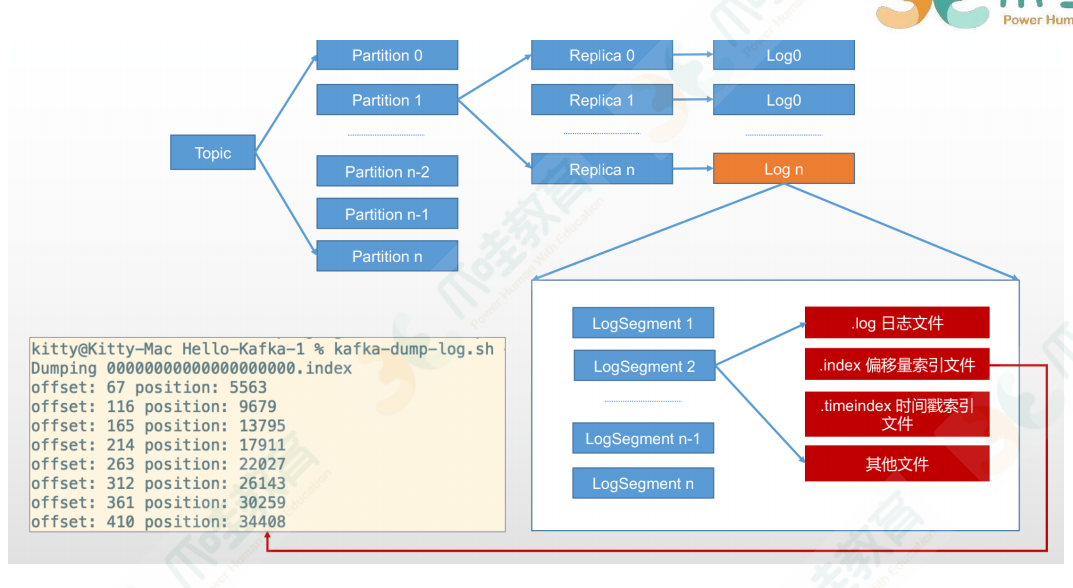
#分区副本剖析
Kafka 通过多副本机制实现故障⾃动转移,在 Kafka 集群中某个 broker 节点失效的情况下仍然保证服
务可⽤。
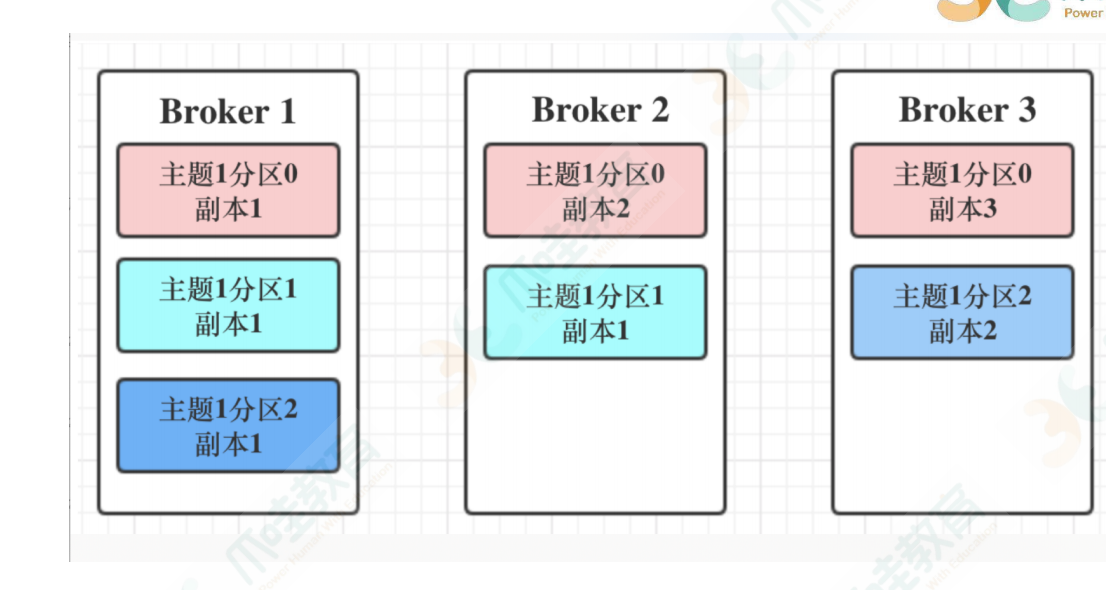
我们该如何确保副本中所有的数据都是⼀致的呢?副本放在不同的broker中,request.required.acks=all或-1
第⼀,副本分成两类:领导者副本(Leader Replica)和追随者副本(Follower Replica)。
第⼆,Follower副本是不对外提供服务的。这就是说,任何⼀个追随者副本都不能响应消费者和⽣产者
的读写请求。所有的请求都必须由领导者副本来处理,或者说,所有的读写请求都必须发往领导者副本
所在的Broker,由该Broker负责处理。
第三,当领导者副本挂掉了,或者说领导者副本所在的Broker宕机时,Kafka依托于ZooKeeper提供的
监控功能能够实时感知到,并⽴即开启新⼀轮的领导者选举,从追随者副本中选⼀个作为新的领导者。(拿到isr副本,按顺序选出新的leader,如果isr中没有副本,则设置unclean.leader.election.enable=true,从ar中选取leader)
⽼Leader副本重启回来后,只能作为追随者副本加⼊到集群中。
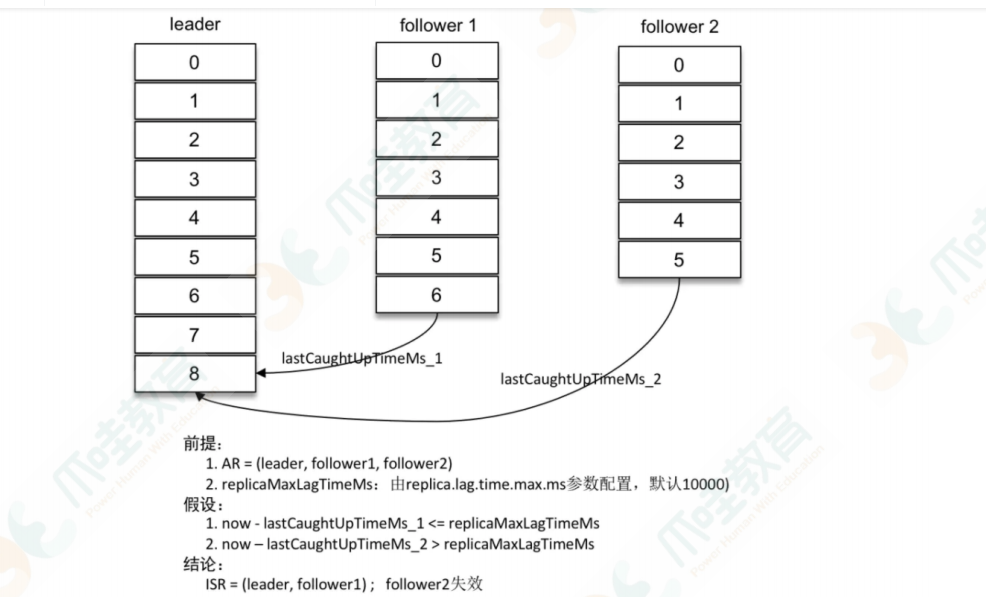
ISR AR
分区中的所有副本统称为 AR,⽽ ISR 是指与 leader 副本保持同步状态的副本集合,当然 leader
副本本身也是这个集合中的⼀员。
失效副本
正常情况下,分区的所有副本都处于 ISR 集合中,但是难免会有异常情况发⽣,从⽽某些副本被剥离出
ISR 集合中。在 ISR 集合之外,也就是处于同步失效或功能失效(⽐如副本处于⾮存活状态)的副本统
称为失效副本,失效副本对应的分区也就称为同步失效分区,即 under-replicated 分区
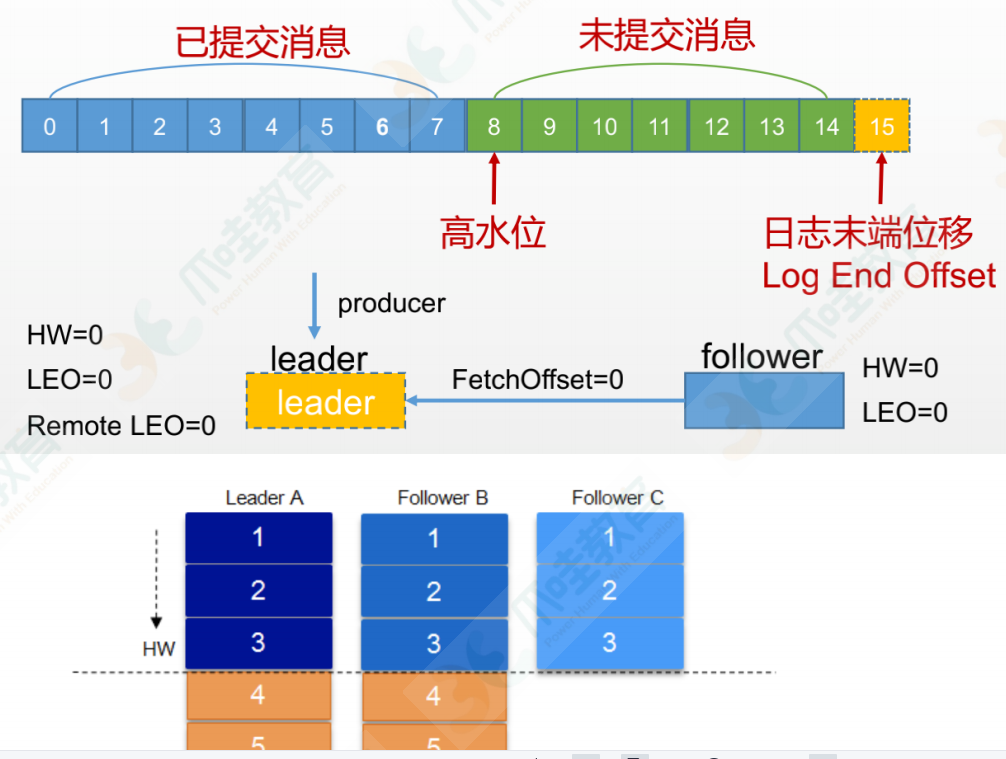
LEO与HW
LEO 标识每个分区中最后⼀条消息的下⼀个位置,分区的每个副本都有⾃⼰的 LEO,ISR 中最⼩的 LEO
即为 HW(所有follower能同步的消息的位置),俗称⾼⽔位,消费者只能拉取到 HW 之前的消息,这样可以保证isr数据一致性。
如果副本有网络问题,则leader会把这条副本踢掉,当副本的数据同步之后leader才会把副本重新加进来
如果副本在被踢掉以后同步的速度很慢,可以配置副本同步leader的线程数,提高性能
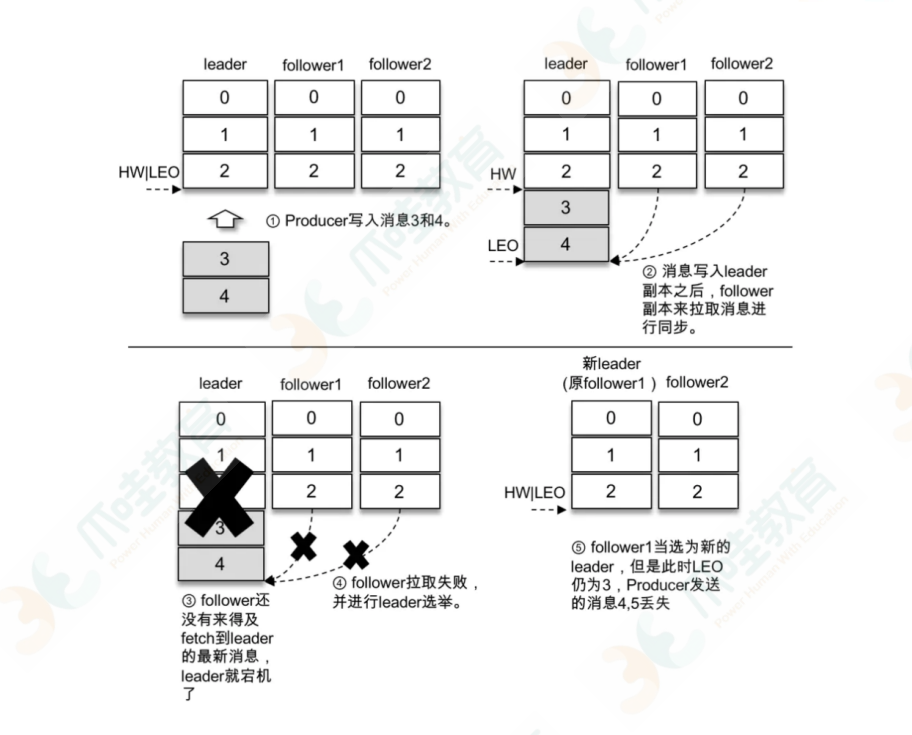
下图4和5在高水位之上,在leader重新被选举的时候才会被重新写进来,因为只有leader能读写数据
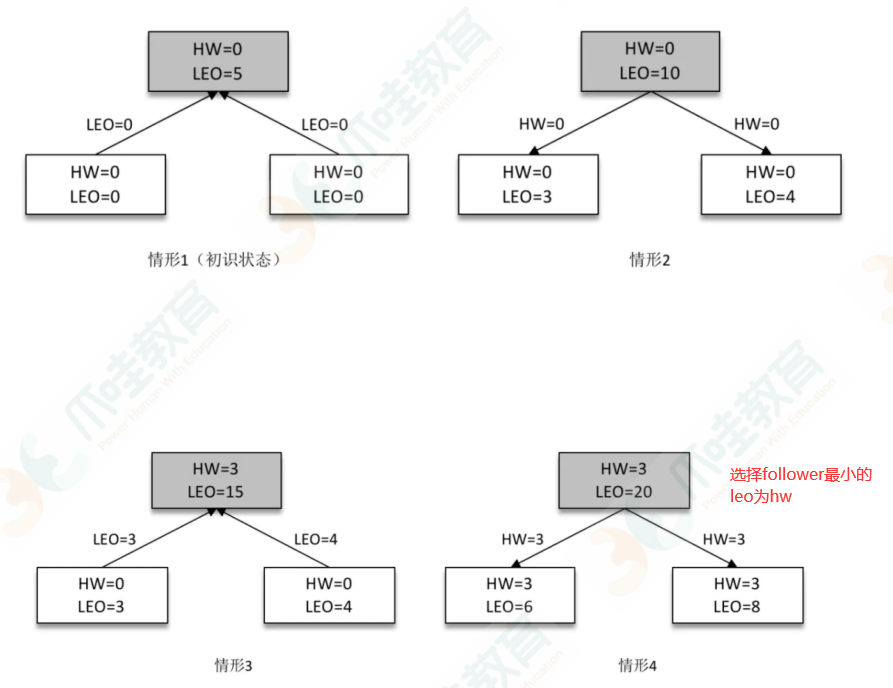
分析在拉去数据过程中各个副本 LEO 和 HW 的变化情况
#可靠性ack分析
仅依靠副本数来⽀撑可靠性是远远不够的,⼤多数⼈还会想到⽣产者客户端参数
request.required.acks。
对于 acks = 1 的配置,⽣产者将消息发送到 leader 副本,leader 副本在成功写⼊本地⽇志之后会
告知⽣产者已经成功提交,如下图所示。如果此时 ISR 集合的 follower 副本还没来得及拉取到
leader 中新写⼊的消息,leader 就宕机了,那么此次发送的消息就会丢失。
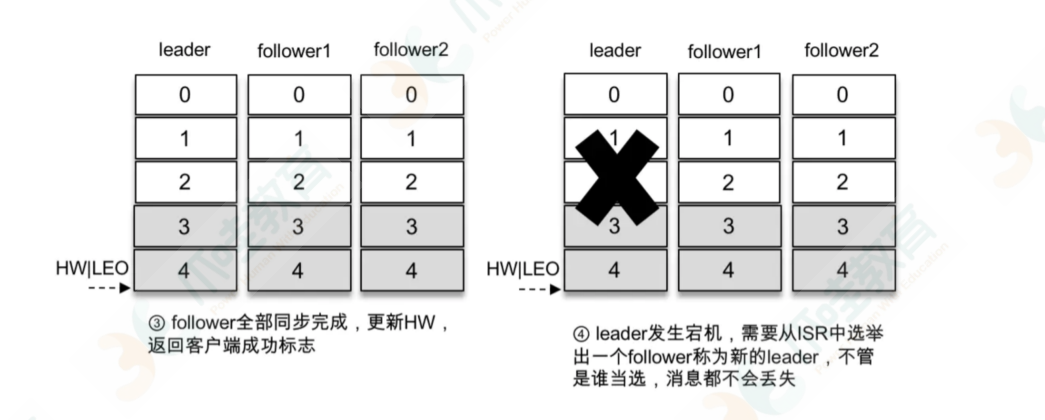
对于 ack = -1 的配置,⽣产者将消息发送到 leader 副本,leader 副本在成功写⼊本地⽇志之后还
要等待 ISR 中的 follower 副本全部同步完成才能够告知⽣产者已经成功提交,即使此时 leader 副
本宕机,消息也不会丢失。
对于 ack = -1 的配置这意味着producer⽆需等待来⾃broker的确认⽽继续发送下⼀批消息。这种
情况下数据传输效率最⾼,但是数据可靠性确是最低的。
#磁盘顺序读写
kafak采⽤的是磁盘顺序读写⽅式,极⼤提升了读写性能。
#⾼性能⻚缓存
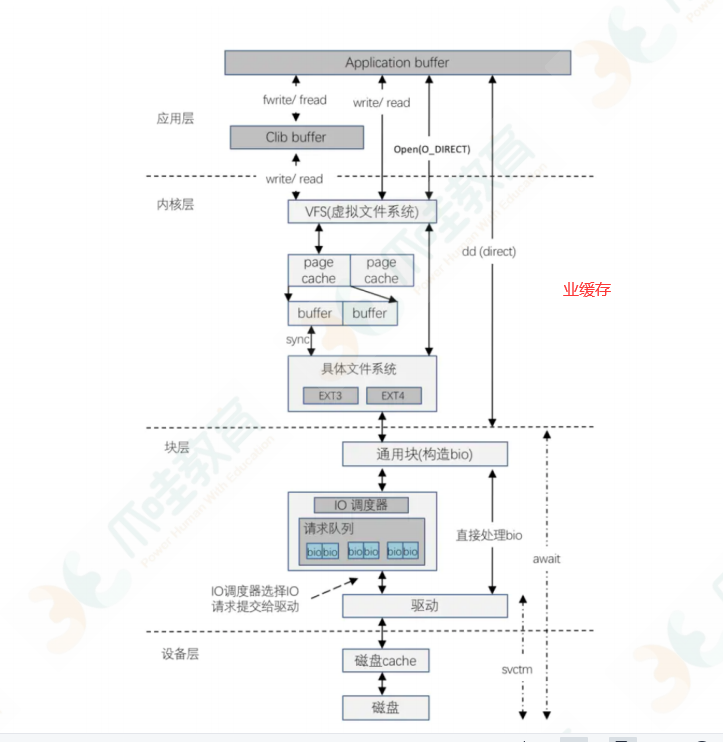
⼀般磁盘 I/O 的场景有以下四种:
1. ⽤户调⽤标准 C 库进⾏ I/O 操作,数据流为:应⽤程序 buffer→C 库标准 IObuffer→⽂件系统⻚
缓存→通过具体⽂件系统到磁盘。
2. ⽤户调⽤⽂件 I/O,数据流为:应⽤程序 buffer→⽂件系统⻚缓存→通过具体⽂件系统到磁盘。
3. ⽤户打开⽂件时使⽤ O_DIRECT,绕过⻚缓存直接读写磁盘。
4. ⽤户使⽤类似 dd ⼯具,并使⽤ direct 参数,绕过系统 cache与⽂件系统直接写磁盘
#零拷⻉
所谓的零拷⻉是指将数据直接从磁盘⽂件复制到⽹卡设备中,⽽不需要经由应⽤程序之⼿。零拷⻉⼤⼤
提⾼了应⽤程序的性能,减少了内核和⽤户模式之间的上下⽂切换。
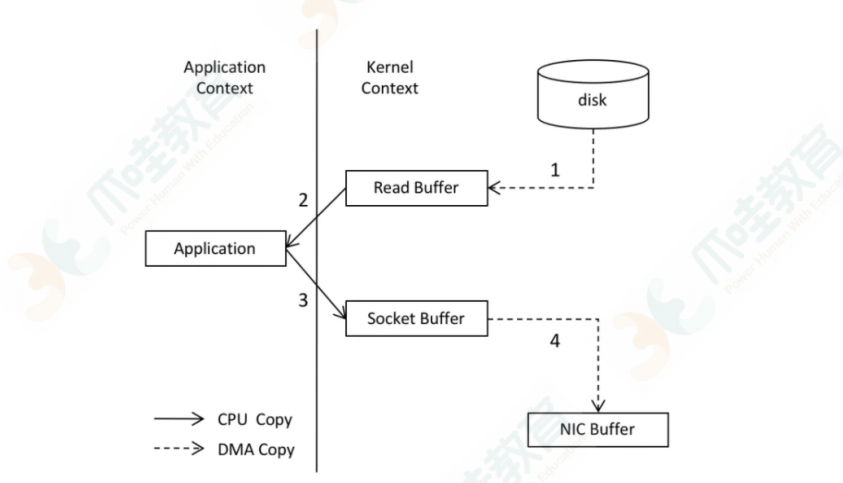
1. 调⽤ read() 时,⽂件 A 中的内容被复制到了内核模式下的 Read Buffer 中。
2. CPU 控制将内核模式数据复制到⽤户模式下。
3. 调⽤ write() 时,将⽤户模式下的内容复制到内核模式下的 Socket Buffer 中。
4. 将内核模式下的 Socket Buffer 的数据复制到⽹卡设备中传送。
零拷⻉
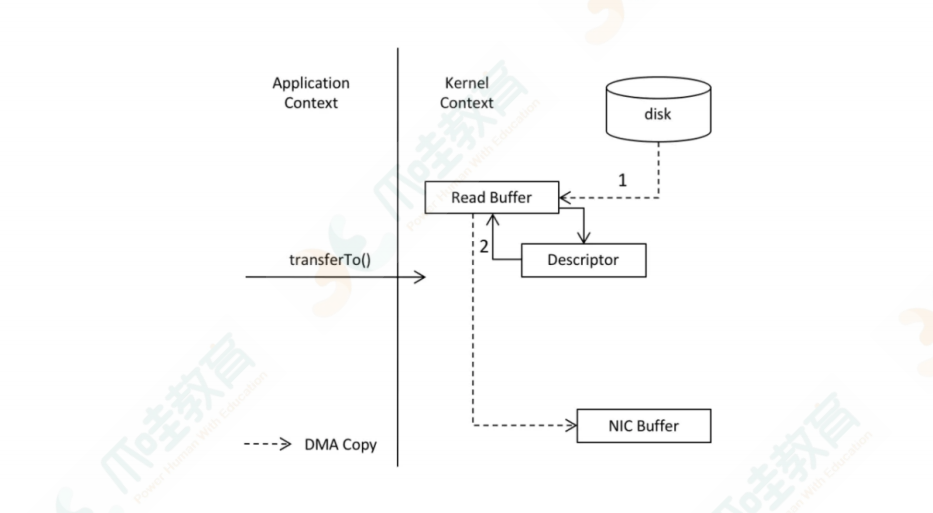
kafka高性能:磁盘顺序读写、零拷贝、页缓存,异步发送acks设置为0
高可用:副本isr acks=-1 选举机制、基于磁盘存储
zk
zk的数据结构是以树形结构存储的

读写数据规则:zab协议
所有的写请求都由leader处理,当超过半数的follower向leader发送ack确认消息之后,leader收到ack以后再发送commits让follower提交本地事务,做到数据同步
读可以从leader读也可以从follower读
Zk不能用来处理大数据,可以用来处理kafka 的broker的元数据,包括数据迁移
kafka常⽤命令
cd /Users/vking/tools/kafka_2.11-1.0.1/bin
./kafka-server-start.sh ../config/server.properties
log /tmp/kafka-logs 查看日志
#创建topic
# 查看topic 列表
# ⽣产
./kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 1
--partitions 1 --topic test_1
./kafka-topics.sh --zookeeper 127.0.0.1:2181 --list#消费
#查看kafka配置
./kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic test_1
./kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic test_1
--group group_1 --from-beginning

