
RocketMq
1.MQ背景&选型
消息队列作为⾼并发系统的核⼼组件之⼀,能够帮助业务系统解构提升开发效率和系统稳定性。主要具
有以下优势:
削峰填⾕(主要解决瞬时写压⼒⼤于应⽤服务能⼒导致消息丢失、系统奔溃等问题)
系统解耦(解决不同重要程度、不同能⼒级别系统之间依赖导致⼀死全死)
提升性能(当存在⼀对多调⽤时,可以发⼀条消息给消息系统,让消息系统通知相关系统,把非关键业务剥离主流程,比如把邮件短信业务与订单、库存的主业务分开)
蓄流压测(线上有些链路不好压测,可以通过堆积⼀定量消息再放开来压测)
⽬前主流的MQ主要是Rocketmq、kafka、Rabbitmq,Rocketmq相⽐于Rabbitmq、kafka具有主要优
势特性有:
• ⽀持事务型消息(消息发送和DB操作保持两⽅的最终⼀致性,rabbitmq和kafka不⽀持)
• ⽀持结合rocketmq的多个系统之间数据最终⼀致性(多⽅事务,⼆⽅事务是前提)
• ⽀持延迟消息(rabbitmq和kafka不⽀持)
• ⽀持指定次数和时间间隔的失败消息重发(kafka不⽀持,rabbitmq需要⼿动确认)
• ⽀持consumer端tag过滤,减少不必要的⽹络传输(rabbitmq和kafka不⽀持)
• ⽀持重复消费(rabbitmq不⽀持,kafka⽀持)
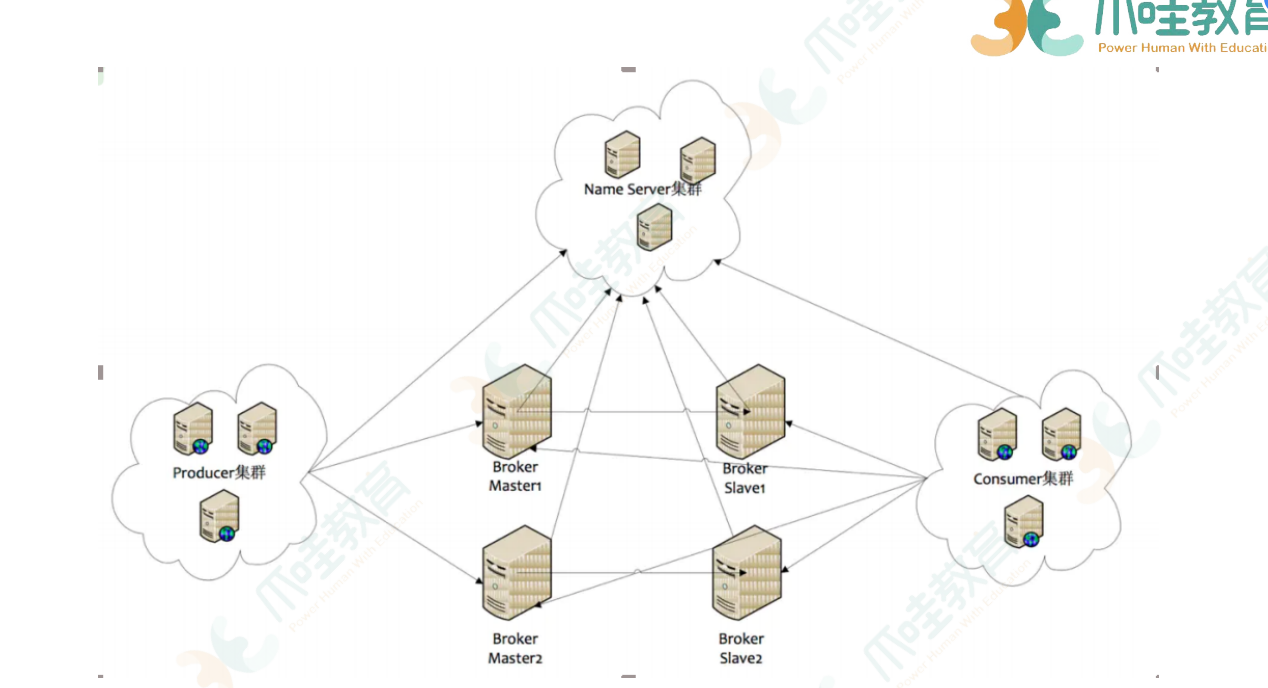
1) Name Server
Name Server是⼀个⼏乎⽆状态节点,可集群部署,节点之间⽆任何信息同步。
作用:管理集群中的元数据,查看producer、broker、consumer是否存活
2) Broker 收发消息
Broker部署相对复杂,Broker分为Master与Slave(作用:读写分离,如果读写都在master上,则master扛不住),⼀个Master可以对应多个Slave,但是⼀个Slave只
能对应⼀个Master,Master与Slave的对应关系通过指定相同的Broker id,不同的Broker Id来定
义,BrokerId为0表示Master,⾮0表示Slave。
每个Broker与Name Server集群中的所有节点建⽴⻓连接,定时(每隔30s)注册Topic信息到所有Name
Server。Name Server定时(每隔10s)扫描所有存活broker的连接,如果Name Server超过2分钟没有收
到⼼跳,则Name Server断开与Broker的连接。
3) Producer
Producer与Name Server集群中的其中⼀个节点(随机选择)建⽴⻓连接,定期从Name Server取Topic
路由信息,并向提供Topic服务的Master建⽴⻓连接,且定时向Master发送⼼跳。Producer完全⽆状
态,可集群部署。
Producer每隔30s(由ClientConfifig的pollNameServerInterval)从Name server获取所有topic队列
的
最新情况,这意味着如果Broker不可⽤,Producer最多30s能够感知,在此期间内发往Broker的所有消
息都会失败。
Producer每隔30s(由ClientConfifig中heartbeatBrokerInterval决定)向所有关联的broker发送⼼
跳,
Broker每隔10s中扫描所有存活的连接,如果Broker在2分钟内没有收到⼼跳数据,则关闭与Producer的连接。
4) Consumer
Consumer与Name Server集群中的其中⼀个节点(随机选择)建⽴⻓连接,定期从Name Server取Topic
路由信息,并向提供Topic服务的Master、Slave建⽴⻓连接,且定时向Master、Slave发送⼼跳。
Consumer既可以从Master订阅消息,也可以从Slave订阅消息,订阅规则由Broker配置决定。
Consumer每隔30s从Name server获取topic的最新队列情况,这意味着Broker不可⽤时,Consumer
最多最需要30s才能感知。
Consumer每隔30s(由ClientConfifig中heartbeatBrokerInterval决定)向所有关联的broker发送⼼
跳,Broker每隔10s扫描所有存活的连接,若某个连接2分钟内没有发送⼼跳数据,则关闭连接;并向该
Consumer Group的所有Consumer发出通知,Group内的Consumer重新分配队列,然后继续消费。
当Consumer得到master宕机通知后,转向slave消费,slave不能保证master的消息100%都同步过来
了,因此会有少量的消息丢失。但是⼀旦master恢复,未同步过去的消息会被最终消费掉。
顺序消费
1.严格实现顺序消费,简单可⾏的办法就是:
保证 ⽣产者—MQServer—消费者 是“⼀对⼀对⼀”的关系。
注意 这样的设计⽅案问题:
1.并⾏度会成为消息系统的瓶颈(吞吐量不够)
2.产⽣更多的异常处理。⽐如:只要消费端出现问题,就会导致整个处理流程阻塞,我们不得不花费更多的
精 ⼒来解决阻塞的问题。
2.通过合理的设计保证局部有序:
从业务层⾯来保证消息的顺序,⽽不仅仅是依赖于消息系统
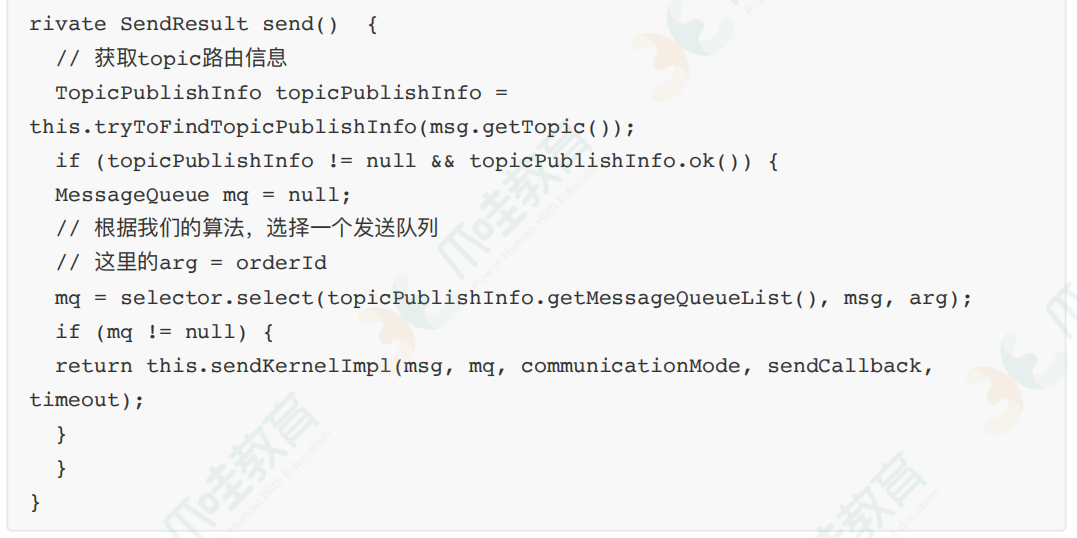
最后从源码⻆度分析RocketMQ怎么实现发送顺序消息。
RocketMQ通过轮询所有队列的⽅式来确定消息被发送到哪⼀个队列(负载均衡策略)。
⽐如下⾯的

在获取到路由信息以后,会根据MessageQueueSelector实现的算法来选择⼀个队列,同⼀个OrderId
获取到的肯定是同⼀个队列。
消息重复
造成消息重复的根本原因是:⽹络不可达。
只要通过⽹络交换数据,就⽆法避免这个问题。所以解决这个问题的办法是绕过这个问题。
那么问题就变成了:如果消费端收到两条⼀样的消息,应该怎样处理?
1.消费端处理消息的业务逻辑要保持幂等性。
2.保证每条数据都有唯⼀编号,且保证消息处理成功与去重表的⽇志同时出现。
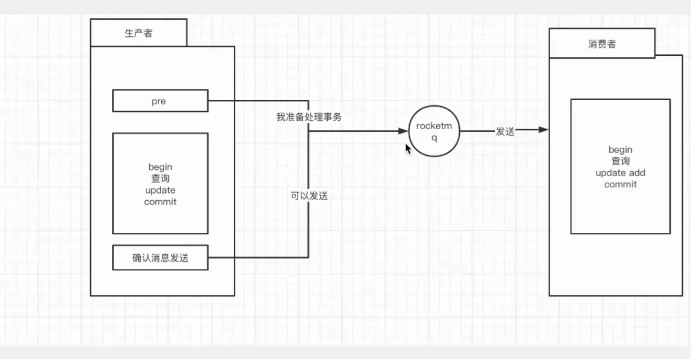
事务消息
RocketMQ⽀持事务消息,下⾯来看看RocketMQ是怎样来实现发送事务消息的:
rocketMQ分三个阶段:
第⼀阶段发送Prepared消息时,会拿到消息的地址。
第⼆阶段执⾏本地事务。
第三阶段通过第⼀阶段拿到的地址去访问消息,并修改消息的状态。
消费失败:
消费方由于网络延迟导致ack未返回或没有接收到消息,失败可以
1.人工处理
2.绕过mq,在消费端接收来自生产者的接口,开一个定时任务,轮询所有的订单id,和已经消费的数据做一个对比
Producer如何发送消息
Producer轮询某Topic下所有队列的⽅式来实现发送⽅的负载均衡,如下图所示:

RocketMQ的客户端发送消息的源码:

消息存储
RocketMQ的消息存储是由comsume queue 和 cimmit log配合完成的。
consume queue是消息的逻辑队列,相当于字典的⽬录,⽤来指定消息在物理⽂件commit log上的位
置。
CommitLog
要想知道RocketMQ如何存储消息,我们先看看CommitLog。在RocketMQ中,所有topic的消息都存储
在⼀个称为CommitLog的⽂件中,该⽂件默认最⼤为1GB,超过1GB后会轮到下⼀个CommitLog⽂
件。通过CommitLog,RocketMQ将所有消息存储在⼀起,以顺序IO的⽅式写⼊磁盘,充分利⽤了磁盘
顺序写减少了IO争⽤提⾼数据存储的性能,
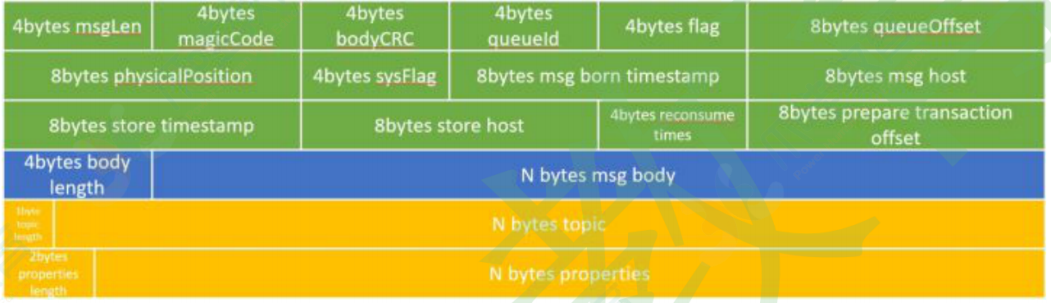
消息在CommitLog中的存储格式如下:
ConsumeQueue
⼀个ConsumeQueue表示⼀个topic的⼀个queue,类似于kafka的⼀个partition,但是rocketmq在消
息存储上与kafka有着⾮常⼤的不同,RocketMQ的ConsumeQueue中不存储具体的消息,具体的消息
由CommitLog存储,ConsumeQueue中只存储路由到该queue中的消息在CommitLog中的offffset,
消息的⼤⼩以及消息所属的tag的hash(tagCode),⼀共只占20个字节,整个数据包如下:

消息存储⽅式
前⽂已经描述过,RocketMQ的消息存储由CommitLog和ConsumeQueue两部分组成,其中
CommitLog⽤于存储原始的消息,⽽ConsumeQueue⽤于存储投递到某⼀个queue中的消息的位置信
息,消息的存储如下图所示:

消费者在读取消息时,先读取ConsumeQueue,再通过ConsumeQueue中的位置信息读取
CommitLog,得到原始的消息。
消息订阅
RocketMQ消息订阅有两种模式:
⼀种是push模式,即MQServer主动向消费端推送。
另⼀种是Pull模式,即消费端在需要时,主动到MQServer拉取。
但是再具体实现时,Push和Pull模式都是采⽤消费端主动拉取的⽅式。
⾸先看下消费端的负载均衡
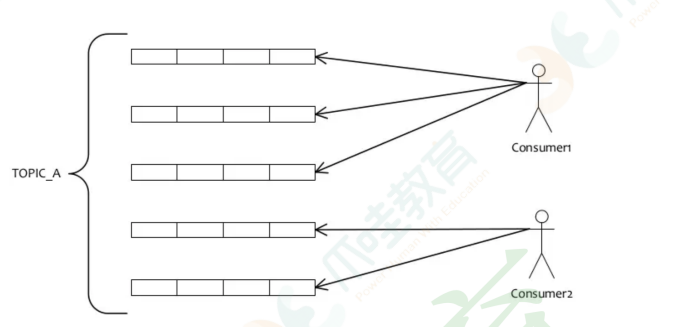
消费端会通过RebalanceService线程,10s做⼀次基于Topic下的所有队列负载:
1.遍历Consumer下所有的Topic,然后根据Topic订阅所有的消息
2.获取同⼀Topic和Consume Group下的所有Consumer
3.然后根据具体的分配策略来分配消费队列,分配的策略包含:平均分配、消费端配置等
如上图所示,如果有5个队列,2个Consumer,那么第⼀个Consumer消费3个队列,第⼆个Consumer
消费2个队列。这⾥采⽤的就是平均分配策略。它类似于分⻚的过程,Topic下⾯所有的Queue就是记
录,Consumer的个数就相当于总的⻚数,那么每⻚有多少条记录,就类似于Consumer会消费哪些队
列。
通过这样的策略来达到⼤体上的平均消费,这样的设计也可以很⽅便地⽔平扩展来提⾼Consumer的消
费能⼒。
消费端的Push模式是通过⻓轮询的模式来实现的,就如同下图:(Pull模式示意图)
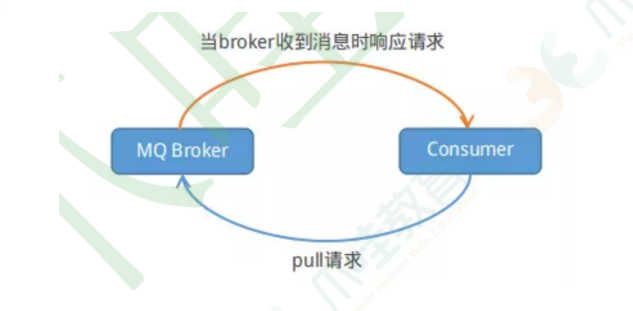
Consumer端每隔⼀段时间主动向broker发送拉消息请求,broker在收到Pull请求后,如果有消息就⽴
即返回数据,Consumer端收到返回的消息后,再回调消费者设置的Listener⽅法。如果broker在收到
Pull请求时,消息队列⾥没有数据,broker端会阻塞请求直到有数据传递或超时才返回。
RocketMQ的最佳实践
Producer最佳最佳实践
1.遍历Consumer下所有的Topic,然后根据Topic订阅所有的消息
2.获取同⼀Topic和Consume Group下的所有Consumer
3.然后根据具体的分配策略来分配消费队列,分配的策略包含:平均分配、消费端配置等1.⼀个应⽤尽可能⽤⼀个Topic,消息⼦类型⽤tags来标识,tags可以由应⽤⾃由设置。只有发送
消息设
置了tags,消费⽅在订阅消息时,才可以利⽤tags在broker做消息过滤。
2.每个消息在业务层⾯的唯⼀标识码,要设置到keys字段,⽅便将来定位消息丢失问题。
3.消息发送成功或者失败,要打印消息⽇志,务必打印sendResult和key字段
4.对于消息不可丢失应⽤,务必要有消息重发机制。例如:消息发送失败,存储到数据库,能有定
时程
序尝试重发或者⼈⼯触发重发。
5.某些应⽤如果不关注消息是否发送成功,请直接使⽤sendOneWay⽅法发送消息。
Consumer最佳实践
1.消费过程要做到幂等
2.尽量使⽤批量⽅式消费,可以很⼤程度上提⾼消费吞吐量。
3.优化每条消息的消费过程
其他配置
线上应该关闭autoCreateTopicEnable,即在配置⽂件中将其设置为false。
RocketMQ在发送消息时,会⾸先获取路由信息。如果是新的消息,由于MQServer上⾯还没有创建对
应的Topic,这个时候,如果上⾯的配置打开的话(autoCreateTopicEnable=true),会返回默认Topic
的路由信息(RocketMQ会在每台Broker上⾯创建名为TBW102的Topic),然后Producer会选择⼀台
Broker发送消息,选中的Broker在存储消息时,发现消息的Topic还没有创建,就会⾃动创建Topic。后
果就是:以后所有该Topic的消息,都将发送到这台Broker上,达不到负载均衡的⽬的。
所以基于⽬前RocketMQ的设计,建议关闭⾃动创建Topic的功能,然后根据消息量的⼤⼩,⼿动创建
Topic
------------恢复内容开始------------
1.MQ背景&选型
消息队列作为⾼并发系统的核⼼组件之⼀,能够帮助业务系统解构提升开发效率和系统稳定性。主要具
有以下优势:
削峰填⾕(主要解决瞬时写压⼒⼤于应⽤服务能⼒导致消息丢失、系统奔溃等问题)
系统解耦(解决不同重要程度、不同能⼒级别系统之间依赖导致⼀死全死)
提升性能(当存在⼀对多调⽤时,可以发⼀条消息给消息系统,让消息系统通知相关系统,把非关键业务剥离主流程,比如把邮件短信业务与订单、库存的主业务分开)
蓄流压测(线上有些链路不好压测,可以通过堆积⼀定量消息再放开来压测)
⽬前主流的MQ主要是Rocketmq、kafka、Rabbitmq,Rocketmq相⽐于Rabbitmq、kafka具有主要优
势特性有:
• ⽀持事务型消息(消息发送和DB操作保持两⽅的最终⼀致性,rabbitmq和kafka不⽀持)
• ⽀持结合rocketmq的多个系统之间数据最终⼀致性(多⽅事务,⼆⽅事务是前提)
• ⽀持延迟消息(rabbitmq和kafka不⽀持)
• ⽀持指定次数和时间间隔的失败消息重发(kafka不⽀持,rabbitmq需要⼿动确认)
• ⽀持consumer端tag过滤,减少不必要的⽹络传输(rabbitmq和kafka不⽀持)
• ⽀持重复消费(rabbitmq不⽀持,kafka⽀持)
1) Name Server
Name Server是⼀个⼏乎⽆状态节点,可集群部署,节点之间⽆任何信息同步。
作用:管理集群中的元数据,查看producer、broker、consumer是否存活
2) Broker 收发消息
Broker部署相对复杂,Broker分为Master与Slave(作用:读写分离,如果读写都在master上,则master扛不住),⼀个Master可以对应多个Slave,但是⼀个Slave只
能对应⼀个Master,Master与Slave的对应关系通过指定相同的Broker id,不同的Broker Id来定
义,BrokerId为0表示Master,⾮0表示Slave。
每个Broker与Name Server集群中的所有节点建⽴⻓连接,定时(每隔30s)注册Topic信息到所有Name
Server。Name Server定时(每隔10s)扫描所有存活broker的连接,如果Name Server超过2分钟没有收
到⼼跳,则Name Server断开与Broker的连接。
3) Producer
Producer与Name Server集群中的其中⼀个节点(随机选择)建⽴⻓连接,定期从Name Server取Topic
路由信息,并向提供Topic服务的Master建⽴⻓连接,且定时向Master发送⼼跳。Producer完全⽆状
态,可集群部署。
Producer每隔30s(由ClientConfifig的pollNameServerInterval)从Name server获取所有topic队列
的
最新情况,这意味着如果Broker不可⽤,Producer最多30s能够感知,在此期间内发往Broker的所有消
息都会失败。
Producer每隔30s(由ClientConfifig中heartbeatBrokerInterval决定)向所有关联的broker发送⼼
跳,
Broker每隔10s中扫描所有存活的连接,如果Broker在2分钟内没有收到⼼跳数据,则关闭与Producer的连接。
4) Consumer
Consumer与Name Server集群中的其中⼀个节点(随机选择)建⽴⻓连接,定期从Name Server取Topic
路由信息,并向提供Topic服务的Master、Slave建⽴⻓连接,且定时向Master、Slave发送⼼跳。
Consumer既可以从Master订阅消息,也可以从Slave订阅消息,订阅规则由Broker配置决定。
Consumer每隔30s从Name server获取topic的最新队列情况,这意味着Broker不可⽤时,Consumer
最多最需要30s才能感知。
Consumer每隔30s(由ClientConfifig中heartbeatBrokerInterval决定)向所有关联的broker发送⼼
跳,Broker每隔10s扫描所有存活的连接,若某个连接2分钟内没有发送⼼跳数据,则关闭连接;并向该
Consumer Group的所有Consumer发出通知,Group内的Consumer重新分配队列,然后继续消费。
当Consumer得到master宕机通知后,转向slave消费,slave不能保证master的消息100%都同步过来
了,因此会有少量的消息丢失。但是⼀旦master恢复,未同步过去的消息会被最终消费掉。
顺序消费
1.严格实现顺序消费,简单可⾏的办法就是:
保证 ⽣产者—MQServer—消费者 是“⼀对⼀对⼀”的关系。
注意 这样的设计⽅案问题:
1.并⾏度会成为消息系统的瓶颈(吞吐量不够)
2.产⽣更多的异常处理。⽐如:只要消费端出现问题,就会导致整个处理流程阻塞,我们不得不花费更多的
精 ⼒来解决阻塞的问题。
2.通过合理的设计保证局部有序:
从业务层⾯来保证消息的顺序,⽽不仅仅是依赖于消息系统
最后从源码⻆度分析RocketMQ怎么实现发送顺序消息。
RocketMQ通过轮询所有队列的⽅式来确定消息被发送到哪⼀个队列(负载均衡策略)。
⽐如下⾯的
在获取到路由信息以后,会根据MessageQueueSelector实现的算法来选择⼀个队列,同⼀个OrderId
获取到的肯定是同⼀个队列。
消息重复
造成消息重复的根本原因是:⽹络不可达。
只要通过⽹络交换数据,就⽆法避免这个问题。所以解决这个问题的办法是绕过这个问题。
那么问题就变成了:如果消费端收到两条⼀样的消息,应该怎样处理?
1.消费端处理消息的业务逻辑要保持幂等性。
2.保证每条数据都有唯⼀编号,且保证消息处理成功与去重表的⽇志同时出现。
事务消息
RocketMQ⽀持事务消息,下⾯来看看RocketMQ是怎样来实现发送事务消息的:
rocketMQ分三个阶段:
第⼀阶段发送Prepared消息时,会拿到消息的地址。
第⼆阶段执⾏本地事务。
第三阶段通过第⼀阶段拿到的地址去访问消息,并修改消息的状态。
消费失败:
消费方由于网络延迟导致ack未返回或没有接收到消息,失败可以
1.人工处理
2.绕过mq,在消费端接收来自生产者的接口,开一个定时任务,轮询所有的订单id,和已经消费的数据做一个对比
Producer如何发送消息
Producer轮询某Topic下所有队列的⽅式来实现发送⽅的负载均衡,如下图所示:
RocketMQ的客户端发送消息的源码:
消息存储
RocketMQ的消息存储是由comsume queue 和 cimmit log配合完成的。
consume queue是消息的逻辑队列,相当于字典的⽬录,⽤来指定消息在物理⽂件commit log上的位
置。
CommitLog
要想知道RocketMQ如何存储消息,我们先看看CommitLog。在RocketMQ中,所有topic的消息都存储
在⼀个称为CommitLog的⽂件中,该⽂件默认最⼤为1GB,超过1GB后会轮到下⼀个CommitLog⽂
件。通过CommitLog,RocketMQ将所有消息存储在⼀起,以顺序IO的⽅式写⼊磁盘,充分利⽤了磁盘
顺序写减少了IO争⽤提⾼数据存储的性能,
消息在CommitLog中的存储格式如下:
ConsumeQueue
⼀个ConsumeQueue表示⼀个topic的⼀个queue,类似于kafka的⼀个partition,但是rocketmq在消
息存储上与kafka有着⾮常⼤的不同,RocketMQ的ConsumeQueue中不存储具体的消息,具体的消息
由CommitLog存储,ConsumeQueue中只存储路由到该queue中的消息在CommitLog中的offffset,
消息的⼤⼩以及消息所属的tag的hash(tagCode),⼀共只占20个字节,整个数据包如下:
消息存储⽅式
前⽂已经描述过,RocketMQ的消息存储由CommitLog和ConsumeQueue两部分组成,其中
CommitLog⽤于存储原始的消息,⽽ConsumeQueue⽤于存储投递到某⼀个queue中的消息的位置信
息,消息的存储如下图所示:
消费者在读取消息时,先读取ConsumeQueue,再通过ConsumeQueue中的位置信息读取
CommitLog,得到原始的消息。
消息订阅
RocketMQ消息订阅有两种模式:
⼀种是push模式,即MQServer主动向消费端推送。
另⼀种是Pull模式,即消费端在需要时,主动到MQServer拉取。
但是再具体实现时,Push和Pull模式都是采⽤消费端主动拉取的⽅式。
⾸先看下消费端的负载均衡
消费端会通过RebalanceService线程,10s做⼀次基于Topic下的所有队列负载:
1.遍历Consumer下所有的Topic,然后根据Topic订阅所有的消息
2.获取同⼀Topic和Consume Group下的所有Consumer
3.然后根据具体的分配策略来分配消费队列,分配的策略包含:平均分配、消费端配置等
如上图所示,如果有5个队列,2个Consumer,那么第⼀个Consumer消费3个队列,第⼆个Consumer
消费2个队列。这⾥采⽤的就是平均分配策略。它类似于分⻚的过程,Topic下⾯所有的Queue就是记
录,Consumer的个数就相当于总的⻚数,那么每⻚有多少条记录,就类似于Consumer会消费哪些队
列。
通过这样的策略来达到⼤体上的平均消费,这样的设计也可以很⽅便地⽔平扩展来提⾼Consumer的消
费能⼒。
消费端的Push模式是通过⻓轮询的模式来实现的,就如同下图:(Pull模式示意图)
Consumer端每隔⼀段时间主动向broker发送拉消息请求,broker在收到Pull请求后,如果有消息就⽴
即返回数据,Consumer端收到返回的消息后,再回调消费者设置的Listener⽅法。如果broker在收到
Pull请求时,消息队列⾥没有数据,broker端会阻塞请求直到有数据传递或超时才返回。
RocketMQ的最佳实践
Producer最佳最佳实践
1.遍历Consumer下所有的Topic,然后根据Topic订阅所有的消息
2.获取同⼀Topic和Consume Group下的所有Consumer
3.然后根据具体的分配策略来分配消费队列,分配的策略包含:平均分配、消费端配置等1.⼀个应⽤尽可能⽤⼀个Topic,消息⼦类型⽤tags来标识,tags可以由应⽤⾃由设置。只有发送
消息设
置了tags,消费⽅在订阅消息时,才可以利⽤tags在broker做消息过滤。
2.每个消息在业务层⾯的唯⼀标识码,要设置到keys字段,⽅便将来定位消息丢失问题。
3.消息发送成功或者失败,要打印消息⽇志,务必打印sendResult和key字段
4.对于消息不可丢失应⽤,务必要有消息重发机制。例如:消息发送失败,存储到数据库,能有定
时程
序尝试重发或者⼈⼯触发重发。
5.某些应⽤如果不关注消息是否发送成功,请直接使⽤sendOneWay⽅法发送消息。
Consumer最佳实践
1.消费过程要做到幂等
2.尽量使⽤批量⽅式消费,可以很⼤程度上提⾼消费吞吐量。
3.优化每条消息的消费过程
其他配置
线上应该关闭autoCreateTopicEnable,即在配置⽂件中将其设置为false。
RocketMQ在发送消息时,会⾸先获取路由信息。如果是新的消息,由于MQServer上⾯还没有创建对
应的Topic,这个时候,如果上⾯的配置打开的话(autoCreateTopicEnable=true),会返回默认Topic
的路由信息(RocketMQ会在每台Broker上⾯创建名为TBW102的Topic),然后Producer会选择⼀台
Broker发送消息,选中的Broker在存储消息时,发现消息的Topic还没有创建,就会⾃动创建Topic。后
果就是:以后所有该Topic的消息,都将发送到这台Broker上,达不到负载均衡的⽬的。
所以基于⽬前RocketMQ的设计,建议关闭⾃动创建Topic的功能,然后根据消息量的⼤⼩,⼿动创建
Topic
------------恢复内容结束------------

